
热门标签
热门文章
- 1单目图像深度估计 - 迁移篇:Depth Extraction from Video Using Non-parametric Sampling_depth transfer: depth extraction from video using
- 2LORA技术学习 一_lora 空中波特率
- 3机器学习:matlab和python实现SVD(奇异值分解)算法_奇异值分解降维示例matlab
- 4关于Arduino、STM32、树莓派的介绍与区别_arduino和stm32的区别
- 5【教程】安卓7.0-11.0高版本 fiddler抓包失败的解决方案_安卓11配置fd证书
- 6Rtthread学习笔记(十三)RT-Thread Studio开启硬件看门狗Watchdog_rt thread 硬件看门狗
- 7C#项目发布,离线部署Linux项目后台导出报错 libgdiplus
- 8DevOps怎么部署?众安助力解决难题_devops部署
- 9使用Python实现一个简单的垃圾邮件分类器_基于python的邮件分类系统
- 10Stable Diffusion 5款最佳电商必备模型、Lora推荐_stablediffusion 商品模型
当前位置: article > 正文
YOLOv8改进 更换旋转目标检测的主干网络LSKNet_yolov8修改主干网络代码
作者:运维做开发 | 2024-07-08 18:11:40
赞
踩
yolov8修改主干网络代码

一、旋转目标检测主干网络LSKNet论文

论文地址:2303.09030.pdf (arxiv.org)
二、Large Selective Kernel Network 的结构
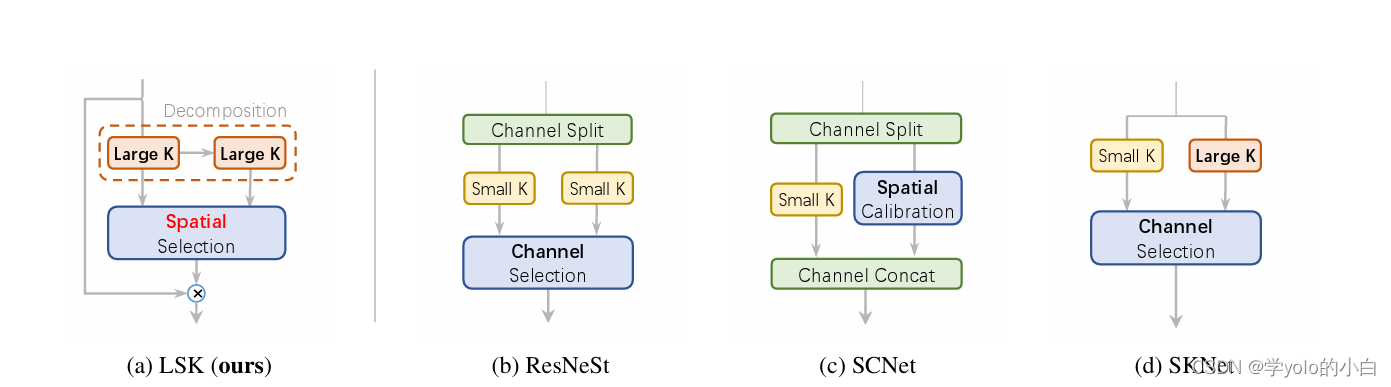
LSK明确地产生了具有各种大感受野的多个特征,使后来的内核选择更加容易且顺序分解比简单地应用一个较大的核更有效更高效。为了提高网络关注检测目标的最相关的空间背景区域的能力,LSK使用了一种空间选择机制,从不同尺度的大卷积核中空间选择特征图。
三、代码实现
1、在ultralytics\ultralytics\nn路径下新建一个文件夹命名为backbone,用于存放网络结构修改的代码。
并在该 backbone文件夹路径下新建py文件lsknet.py,并在该文件里添加lsknet网络结构的代码:
- import torch
- import torch.nn as nn
- from torch.nn.modules.utils import _pair as to_2tuple
- from timm.layers import DropPath, to_2tuple
- from functools import partial
- import numpy as np
-
- __all__ = 'lsknet_t', 'lsknet_s'
-
- class Mlp(nn.Module):
- def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
- super().__init__()
- out_features = out_features or in_features
- hidden_features = hidden_features or in_features
- self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
- self.dwconv = DWConv(hidden_features)
- self.act = act_layer()
- self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
- self.drop = nn.Dropout(drop)
-
- def forward(self, x):
- x = self.fc1(x)
- x = self.dwconv(x)
- x = self.act(x)
- x = self.drop(x)
- x = self.fc2(x)
- x = self.drop(x)
- return x
-
-
- class LSKblock(nn.Module):
- def __init__(self, dim):
- super().__init__()
- self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
- self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
- self.conv1 = nn.Conv2d(dim, dim//2, 1)
- self.conv2 = nn.Conv2d(dim, dim//2, 1)
- self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
- self.conv = nn.Conv2d(dim//2, dim, 1)
-
- def forward(self, x):
- attn1 = self.conv0(x)
- attn2 = self.conv_spatial(attn1)
-
- attn1 = self.conv1(attn1)
- attn2 = self.conv2(attn2)
-
- attn = torch.cat([attn1, attn2], dim=1)
- avg_attn = torch.mean(attn, dim=1, keepdim=True)
- max_attn, _ = torch.max(attn, dim=1, keepdim=True)
- agg = torch.cat([avg_attn, max_attn], dim=1)
- sig = self.conv_squeeze(agg).sigmoid()
- attn = attn1 * sig[:,0,:,:].unsqueeze(1) + attn2 * sig[:,1,:,:].unsqueeze(1)
- attn = self.conv(attn)
- return x * attn
-
-
-
- class Attention(nn.Module):
- def __init__(self, d_model):
- super().__init__()
-
- self.proj_1 = nn.Conv2d(d_model, d_model, 1)
- self.activation = nn.GELU()
- self.spatial_gating_unit = LSKblock(d_model)
- self.proj_2 = nn.Conv2d(d_model, d_model, 1)
-
- def forward(self, x):
- shorcut = x.clone()
- x = self.proj_1(x)
- x = self.activation(x)
- x = self.spatial_gating_unit(x)
- x = self.proj_2(x)
- x = x + shorcut
- return x
-
-
- class Block(nn.Module):
- def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU, norm_cfg=None):
- super().__init__()
- self.norm1 = nn.BatchNorm2d(dim)
- self.norm2 = nn.BatchNorm2d(dim)
- self.attn = Attention(dim)
- self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
- layer_scale_init_value = 1e-2
- self.layer_scale_1 = nn.Parameter(
- layer_scale_init_value * torch.ones((dim)), requires_grad=True)
- self.layer_scale_2 = nn.Parameter(
- layer_scale_init_value * torch.ones((dim)), requires_grad=True)
-
- def forward(self, x):
- x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
- x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
- return x
-
-
- class OverlapPatchEmbed(nn.Module):
- """ Image to Patch Embedding
- """
-
- def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768, norm_cfg=None):
- super().__init__()
- patch_size = to_2tuple(patch_size)
- self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
- padding=(patch_size[0] // 2, patch_size[1] // 2))
- self.norm = nn.BatchNorm2d(embed_dim)
-
-
- def forward(self, x):
- x = self.proj(x)
- _, _, H, W = x.shape
- x = self.norm(x)
- return x, H, W
-
- class LSKNet(nn.Module):
- def __init__(self, img_size=224, in_chans=3, embed_dims=[64, 128, 256, 512],
- mlp_ratios=[8, 8, 4, 4], drop_rate=0., drop_path_rate=0., norm_layer=partial(nn.LayerNorm, eps=1e-6),
- depths=[3, 4, 6, 3], num_stages=4,
- norm_cfg=None):
- super().__init__()
-
- self.depths = depths
- self.num_stages = num_stages
-
- dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
- cur = 0
-
- for i in range(num_stages):
- patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
- patch_size=7 if i == 0 else 3,
- stride=4 if i == 0 else 2,
- in_chans=in_chans if i == 0 else embed_dims[i - 1],
- embed_dim=embed_dims[i], norm_cfg=norm_cfg)
-
- block = nn.ModuleList([Block(
- dim=embed_dims[i], mlp_ratio=mlp_ratios[i], drop=drop_rate, drop_path=dpr[cur + j],norm_cfg=norm_cfg)
- for j in range(depths[i])])
- norm = norm_layer(embed_dims[i])
- cur += depths[i]
-
- setattr(self, f"patch_embed{i + 1}", patch_embed)
- setattr(self, f"block{i + 1}", block)
- setattr(self, f"norm{i + 1}", norm)
-
- self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
-
- def forward(self, x):
- B = x.shape[0]
- outs = []
- for i in range(self.num_stages):
- patch_embed = getattr(self, f"patch_embed{i + 1}")
- block = getattr(self, f"block{i + 1}")
- norm = getattr(self, f"norm{i + 1}")
- x, H, W = patch_embed(x)
- for blk in block:
- x = blk(x)
- x = x.flatten(2).transpose(1, 2)
- x = norm(x)
- x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
- outs.append(x)
- return outs
-
-
- class DWConv(nn.Module):
- def __init__(self, dim=768):
- super(DWConv, self).__init__()
- self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
-
- def forward(self, x):
- x = self.dwconv(x)
- return x
-
- def update_weight(model_dict, weight_dict):
- idx, temp_dict = 0, {}
- for k, v in weight_dict.items():
- if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
- temp_dict[k] = v
- idx += 1
- model_dict.update(temp_dict)
- print(f'loading weights... {idx}/{len(model_dict)} items')
- return model_dict
-
- def lsknet_t(weights=''):
- model = LSKNet(embed_dims=[32, 64, 160, 256], depths=[3, 3, 5, 2], drop_rate=0.1, drop_path_rate=0.1)
- if weights:
- model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['state_dict']))
- return model
-
- def lsknet_s(weights=''):
- model = LSKNet(embed_dims=[64, 128, 256, 512], depths=[2, 2, 4, 2], drop_rate=0.1, drop_path_rate=0.1)
- if weights:
- model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['state_dict']))
- return model
-
- if __name__ == '__main__':
- model = lsknet_t('lsk_t_backbone-2ef8a593.pth')
- inputs = torch.randn((1, 3, 640, 640))
- for i in model(inputs):
- print(i.size())
2、在ultralytics\ultralytics\nn\tasks.py文件中加入lsknet模块
开头先从新建的文件夹引入lsknet的包:
from ultralytics.nn.backbone.lsknet import *并且文件的def _predict_once函数模块要替换为更换网络结构后的预测模块:

替换为:
- def _predict_once(self, x, profile=False, visualize=False):
- """
- Perform a forward pass through the network.
- Args:
- x (torch.Tensor): The input tensor to the model.
- profile (bool): Print the computation time of each layer if True, defaults to False.
- visualize (bool): Save the feature maps of the model if True, defaults to False.
- Returns:
- (torch.Tensor): The last output of the model.
- """
- y, dt = [], [] # outputs
- for m in self.model:
- if m.f != -1: # if not from previous layer
- x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
- if profile:
- self._profile_one_layer(m, x, dt)
- if hasattr(m, 'backbone'):
- x = m(x)
- for _ in range(5 - len(x)):
- x.insert(0, None)
- for i_idx, i in enumerate(x):
- if i_idx in self.save:
- y.append(i)
- else:
- y.append(None)
- # for i in x:
- # if i is not None:
- # print(i.size())
- x = x[-1]
- else:
- x = m(x) # run
- y.append(x if m.i in self.save else None) # save output
- if visualize:
- feature_visualization(x, m.type, m.i, save_dir=visualize)
- return x
然后在def parse_model函数模块中进行修改:
由于是更换yolov8原始的网路结构,所以需要在该parse_model函数模块中加入更改网络模块的代码,更改后完整的def parse_model模块代码为:
- def parse_model(d, ch, verbose=True, warehouse_manager=None): # model_dict, input_channels(3)
- """Parse a YOLO model.yaml dictionary into a PyTorch model."""
- import ast
-
- # Args
- max_channels = float('inf')
- nc, act, scales = (d.get(x) for x in ('nc', 'activation', 'scales'))
- depth, width, kpt_shape = (d.get(x, 1.0) for x in ('depth_multiple', 'width_multiple', 'kpt_shape'))
- if scales:
- scale = d.get('scale')
- if not scale:
- scale = tuple(scales.keys())[0]
- LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
- depth, width, max_channels = scales[scale]
-
- if act:
- Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
- if verbose:
- LOGGER.info(f"{colorstr('activation:')} {act}") # print
-
- if verbose:
- LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
- ch = [ch]
- layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
- is_backbone = False
- for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
- try:
- if m == 'node_mode':
- m = d[m]
- if len(args) > 0:
- if args[0] == 'head_channel':
- args[0] = int(d[args[0]])
- t = m
- m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
- except:
- pass
- for j, a in enumerate(args):
- if isinstance(a, str):
- with contextlib.suppress(ValueError):
- try:
- args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
- except:
- args[j] = a
-
- n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
- if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
- BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3):
- if args[0] == 'head_channel':
- args[0] = d[args[0]]
- c1, c2 = ch[f], args[0]
- if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
- c2 = make_divisible(min(c2, max_channels) * width, 8)
-
- args = [c1, c2, *args[1:]]
-
- if m in (
- BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3):
- args.insert(2, n) # number of repeats
- n = 1
- elif m is AIFI:
- args = [ch[f], *args]
- ##### 更换网络lsknet ####
- elif m in {lsknet_s, lsknet_t}:
- m = m(*args)
- c2 = m.channel
- elif m in (HGStem, HGBlock):
- c1, cm, c2 = ch[f], args[0], args[1]
- args = [c1, cm, c2, *args[2:]]
- if m is HGBlock:
- args.insert(4, n) # number of repeats
- n = 1
-
-
- elif m in (
- Detect, Pose):
- args.append([ch[x] for x in f])
-
- elif m is nn.BatchNorm2d:
- args = [ch[f]]
- elif m is Concat:
- c2 = sum(ch[x] for x in f)
- elif m in (Detect, Segment, Pose):
- args.append([ch[x] for x in f])
- if m is Segment:
- args[2] = make_divisible(min(args[2], max_channels) * width, 8)
- elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
- args.insert(1, [ch[x] for x in f])
- else:
- c2 = ch[f]
-
- if isinstance(c2, list):
- is_backbone = True
- m_ = m
- m_.backbone = True
- else:
- m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
- t = str(m)[8:-2].replace('__main__.', '') # module type
-
- m.np = sum(x.numel() for x in m_.parameters()) # number params
- m_.i, m_.f, m_.type = i + 4 if is_backbone else i, f, t # attach index, 'from' index, type
- if verbose:
- LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
- save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if
- x != -1) # append to savelist
- layers.append(m_)
- if i == 0:
- ch = []
- if isinstance(c2, list):
- ch.extend(c2)
- for _ in range(5 - len(ch)):
- ch.insert(0, 0)
- else:
- ch.append(c2)
- return nn.Sequential(*layers), sorted(save)
3、创建yolov8+LSKNet.yaml文件:
- # Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/799672推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

