
- 1小红书xs-xt解密
- 22024给刚入门网络安全人推荐一下网安入门级别的书籍_web渗透测试相关书籍推荐 知乎
- 3考研系列-数据结构第七章:查找(上)_折半查找的平均查找长度
- 4【网络安全】零日漏洞(0day)是什么?如何防范零日攻击?
- 5pytorchOCR之DBnet(多类别文本检测1)_pytorch文本检测
- 6obsidian 多设备文件同步配置,不需要 iCloud,使用 webdav_obisidian 手机端设置webdav
- 7streamlit入门_stremlit 安装成功 无法运行命令
- 8MySQL连接详解:从基础到进阶策略【含代码示例】
- 9baichuan-7B-chat微调报错及解决记录 使用的仓库:LLaMA-Factory 2023年11月27日_automodel got an unexpected keyword argument 'enab
- 10数据结构(线性表:顺序表详解)_顺序表只能包含一个表头元素
Flink源码-StreamGraph的生成_flink streamgraph构建源码
赞
踩
上个帖子我们分析到了我们代码中算子最终会通过transformation的add方法将自身的血缘依赖添加到一个transformations这个list中,接下来我们看一下transforamtions是如何把血缘依赖放进streamgraph中.
1.StreamGraph的结构
StreamGraph我们可能比较熟悉,如下图所示,主要包含两部分streamNode和StreamEdge,StreamNode也就是,每个算子直接转换过来的,一个算子会转换成一个streamNode,streamEdge是指连接两个streamNode的边,由于中间的streamNode前后都有streamNode,所以中间的streamNode有两条边,既InputEdge和OutputEdge。
例如下图中StreamGraph共有四个StreamNode,对应flatMap的那个StreamNode就有两个StreamEdge,既InputEdge和OutputEdge。处于两头的source和sink StreamNode只有一个streamEdge.source有一个OutputEdge,而sink有一个inputEdge。

2.StreamGraph的生成
我们都知道flink代码的执行都是从env.execute方法开始的,那我们就顺着这个方法往下看

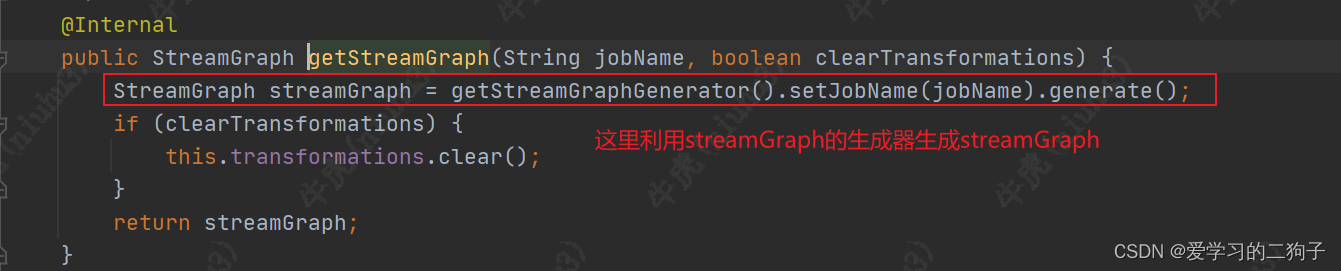
 getStreamGraph方法用来获取streamGraph,这下flink第一个关键执行图出来了,证明我们的方向是没有错的,我们继续往下看
getStreamGraph方法用来获取streamGraph,这下flink第一个关键执行图出来了,证明我们的方向是没有错的,我们继续往下看

通过getStreamGraphGenerator方法创建一个streamGraphGenerator实例,然后调用generate方法生成streamGraph,这里如果clearTransformations为true会调用transformations.clear方法清空transformation
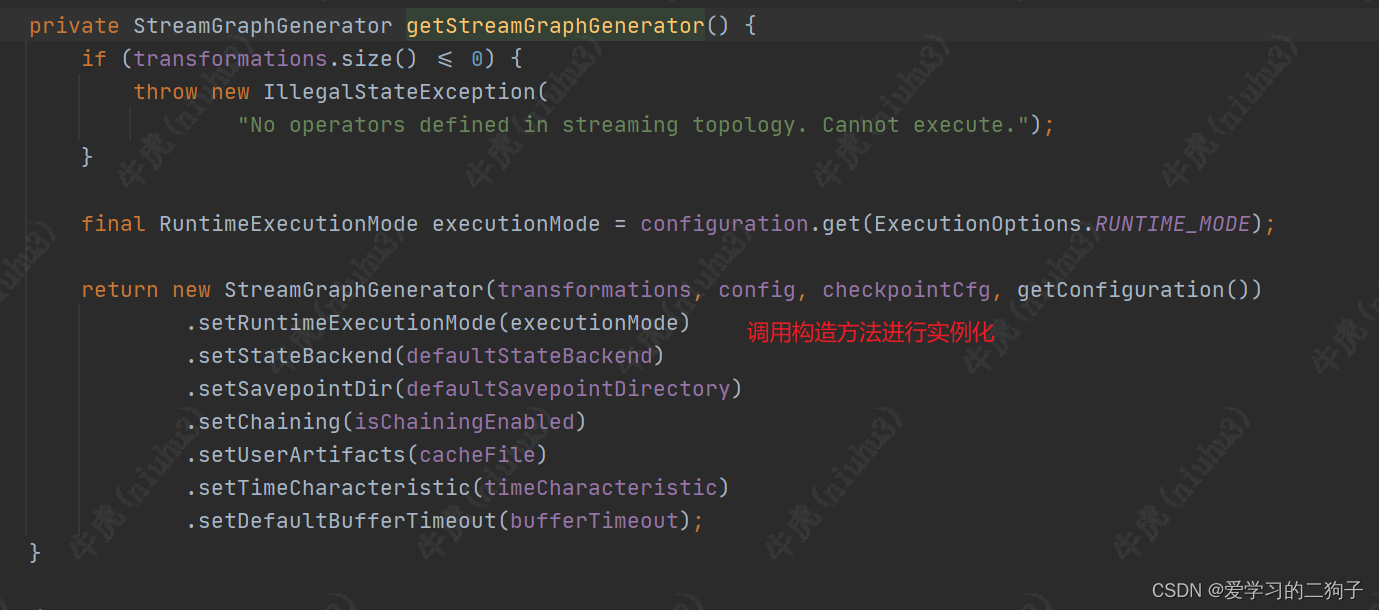
接下来到关键方法:generate方法,这个方法比较长,我们分步来看里面总共做了以下操作:
1.根据传入的执行参数,checkpoint配置参数,savepoint重启参数创建streamgraph
2.判断当前的作业是批式作业还是流式作业
3.配置streamGraph的job name,checkpoint设置和savepoint等设置
4.循环遍历transforamtions,将transformation转换成streamNode和streamEdge
5.循环遍历每个streamEdge的inputEdge,判断是否支持异步checkpoint
6.清空已经转换的transforamtion集合,返回创建的streamGraph
- public StreamGraph generate() {
- //传入执行参数和checkpoint配置参数,savepoint重启设置创建streamgraph
- streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
- //判断执行模式是批次执行还是流式执行
- shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode);
- //配置streamGraph job名,checkpoint设置,savepoint等设置
- configureStreamGraph(streamGraph);
-
- alreadyTransformed = new HashMap<>();
- //循环遍历transformations,将transformation转换成streamNode和streamEdge
- for (Transformation<?> transformation : transformations) {
- transform(transformation);
- }
-
- //循环遍历每个streamEdge的入边,判断是否支持异步checkpoint
- for (StreamNode node : streamGraph.getStreamNodes()) {
- if (node.getInEdges().stream().anyMatch(this::shouldDisableUnalignedCheckpointing)) {
- for (StreamEdge edge : node.getInEdges()) {
- edge.setSupportsUnalignedCheckpoints(false);
- }
- }
- }
-
- final StreamGraph builtStreamGraph = streamGraph;
-
- alreadyTransformed.clear();
- alreadyTransformed = null;
- streamGraph = null;
-
- return builtStreamGraph;
- }

3.StreamNode和StreamEdge的生成
上一步我们看到了在transform方法中transformation变成了StreamNode和StreamEdge,下面我们深入进去看看他们是如何生成的
1.transform方法
该方法中经过各种判断,最终在translate方法中执行转换
- private Collection<Integer> transform(Transformation<?> transform) {
- //判断已经转换的transformation是否包含当前transformation
- if (alreadyTransformed.containsKey(transform)) {
- return alreadyTransformed.get(transform);
- }
-
- LOG.debug("Transforming " + transform);
-
- //设置transform的并行度
- if (transform.getMaxParallelism() <= 0) {
-
- // if the max parallelism hasn't been set, then first use the job wide max parallelism
- // from the ExecutionConfig.
- int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
- if (globalMaxParallelismFromConfig > 0) {
- transform.setMaxParallelism(globalMaxParallelismFromConfig);
- }
- }
-
- // call at least once to trigger exceptions about MissingTypeInfo
- transform.getOutputType();
-
- //获取该transformation的translator类型
- final TransformationTranslator<?, Transformation<?>> translator =
- (TransformationTranslator<?, Transformation<?>>)
- translatorMap.get(transform.getClass());
-
- Collection<Integer> transformedIds;
- //根据不同类型调用translate方法获取transformId
- if (translator != null) {
- transformedIds = translate(translator, transform);
- } else {
- transformedIds = legacyTransform(transform);
- }
-
- // need this check because the iterate transformation adds itself before
- // transforming the feedback edges
-
- //判断该transformation是否转换,该map中没有对应的key就加入map
- if (!alreadyTransformed.containsKey(transform)) {
- alreadyTransformed.put(transform, transformedIds);
- }
-
- return transformedIds;
- }
2.translate方法
在方法中可以看到最后会根据执行模式选择执行translateForBatch或者translateForStreaming方法
我们这里是流式执行,所以我们后面继续看translateForStreaming方法
- private Collection<Integer> translate(
- final TransformationTranslator<?, Transformation<?>> translator,
- final Transformation<?> transform) {
- checkNotNull(translator);
- checkNotNull(transform);
-
- //获取该tranformation的parentId
- final List<Collection<Integer>> allInputIds = getParentInputIds(transform.getInputs());
-
- // the recursive call might have already transformed this
- //判断该transfomation是否在alreadyTransformed这个集合中
- if (alreadyTransformed.containsKey(transform)) {
- return alreadyTransformed.get(transform);
- }
-
- //获取该transformation的共享组
- final String slotSharingGroup =
- determineSlotSharingGroup(
- transform.getSlotSharingGroup(),
- allInputIds.stream()
- .flatMap(Collection::stream)
- .collect(Collectors.toList()));
-
- final TransformationTranslator.Context context =
- new ContextImpl(this, streamGraph, slotSharingGroup, configuration);
- //根据执行模式选择不同的方法进行转换
- return shouldExecuteInBatchMode
- ? translator.translateForBatch(transform, context)
- : translator.translateForStreaming(transform, context);
- }
3.translateForStreaming
这个方法在两个类中有两个实现方法,sink算子选择sinkTransformationTranslator,其他算子就选择 simpleTransformationTranslator,这里我们选择simpleTransformationTranslator.translateForStreaming作为例子讲解

- @Override
- public final Collection<Integer> translateForStreaming(
- final T transformation, final Context context) {
- checkNotNull(transformation);
- checkNotNull(context);
-
- //底层调用translateForStreamingInternal进行转换
- final Collection<Integer> transformedIds =
- translateForStreamingInternal(transformation, context);
- configure(transformation, context);
-
- return transformedIds;
- }
translateForStreamingInternal是一个抽象方法,他有很多的实现类:
这里我们就选择OneInputTransformationTranslator作为例子讲解,其实选择哪一个都可以,里面的主要代码都是一样的,大家有兴趣的可以自己下去看看这些到底有啥区别,顺便也可以自己学习一下现在transformation有哪些种类。话不多说我们继续往下看代码: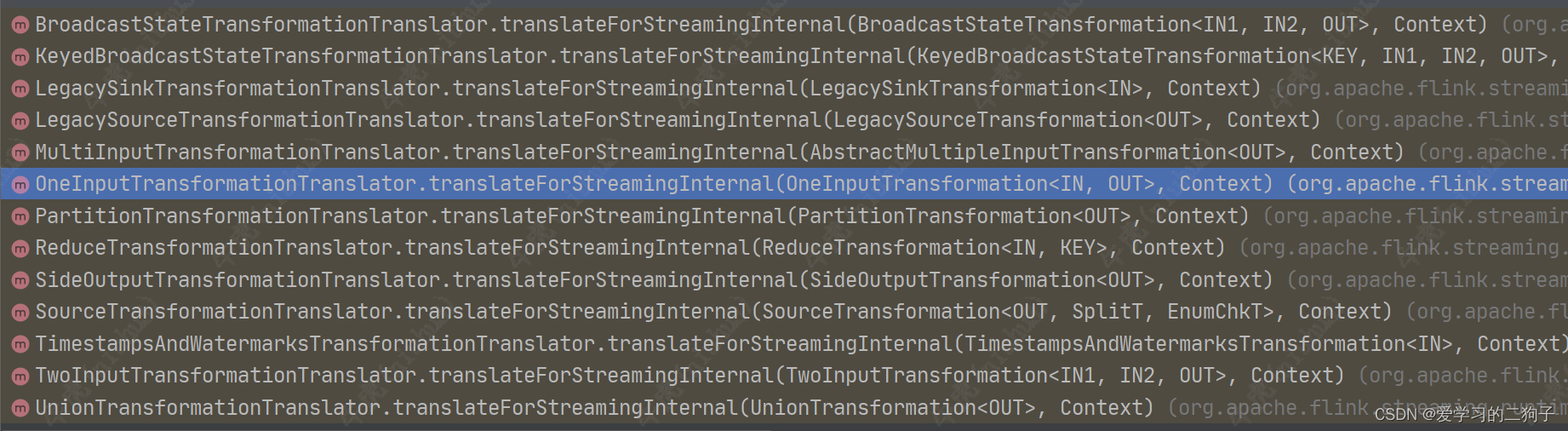 他有调用自己内部的方法 translateInternal
他有调用自己内部的方法 translateInternal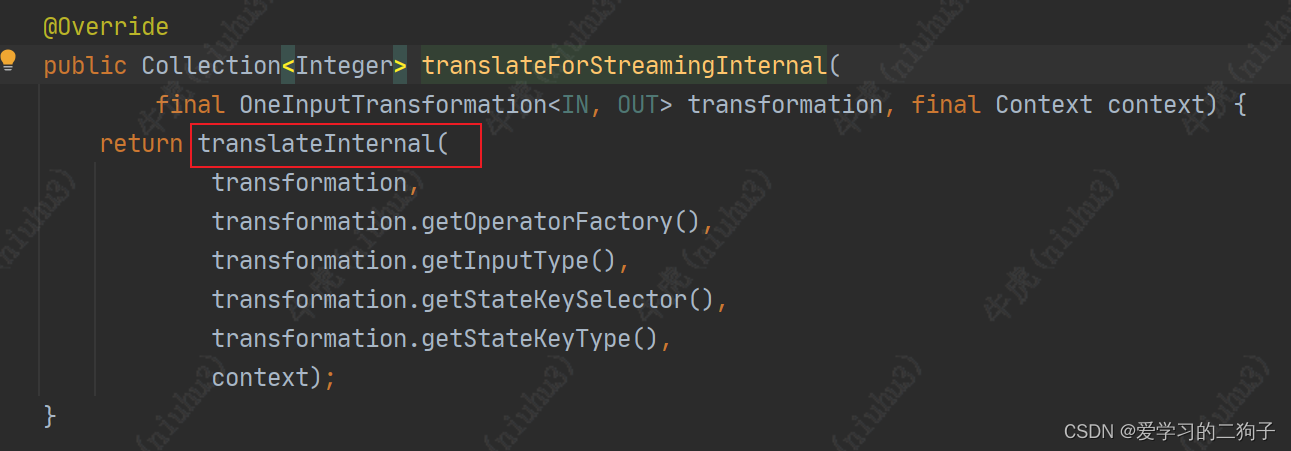 那我们就看看这个方法吧,看到了这个方法我们基本上也来到了终点站了,这个方法中总主要做了两件事:
那我们就看看这个方法吧,看到了这个方法我们基本上也来到了终点站了,这个方法中总主要做了两件事:
1.给streamGraph设置operator
2.给streamGraph设置edge
- protected Collection<Integer> translateInternal(
- final Transformation<OUT> transformation,
- final StreamOperatorFactory<OUT> operatorFactory,
- final TypeInformation<IN> inputType,
- @Nullable final KeySelector<IN, ?> stateKeySelector,
- @Nullable final TypeInformation<?> stateKeyType,
- final Context context) {
- checkNotNull(transformation);
- checkNotNull(operatorFactory);
- checkNotNull(inputType);
- checkNotNull(context);
-
- //获取streamGraph和transformaId
- final StreamGraph streamGraph = context.getStreamGraph();
- final String slotSharingGroup = context.getSlotSharingGroup();
- final int transformationId = transformation.getId();
- final ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
-
- //给streamGraph添加算子
- streamGraph.addOperator(
- transformationId,
- slotSharingGroup,
- transformation.getCoLocationGroupKey(),
- operatorFactory,
- inputType,
- transformation.getOutputType(),
- transformation.getName());
-
- if (stateKeySelector != null) {
- TypeSerializer<?> keySerializer = stateKeyType.createSerializer(executionConfig);
- streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer);
- }
-
- int parallelism =
- transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT
- ? transformation.getParallelism()
- : executionConfig.getParallelism();
- streamGraph.setParallelism(transformationId, parallelism);
- streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism());
-
- //获取该transformation的父transformation
- final List<Transformation<?>> parentTransformations = transformation.getInputs();
- checkState(
- parentTransformations.size() == 1,
- "Expected exactly one input transformation but found "
- + parentTransformations.size());
-
- //给streamGraph设置streamEdge
- for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) {
- streamGraph.addEdge(inputId, transformationId, 0);
- }
-
- return Collections.singleton(transformationId);
- }
可能有的小伙伴就问了前面不是说streamGraph是streamNodeheStreamEdge组成的,这里是设置operator和streamEdge,没有看见streamNode啊,别急咱们再往下看:
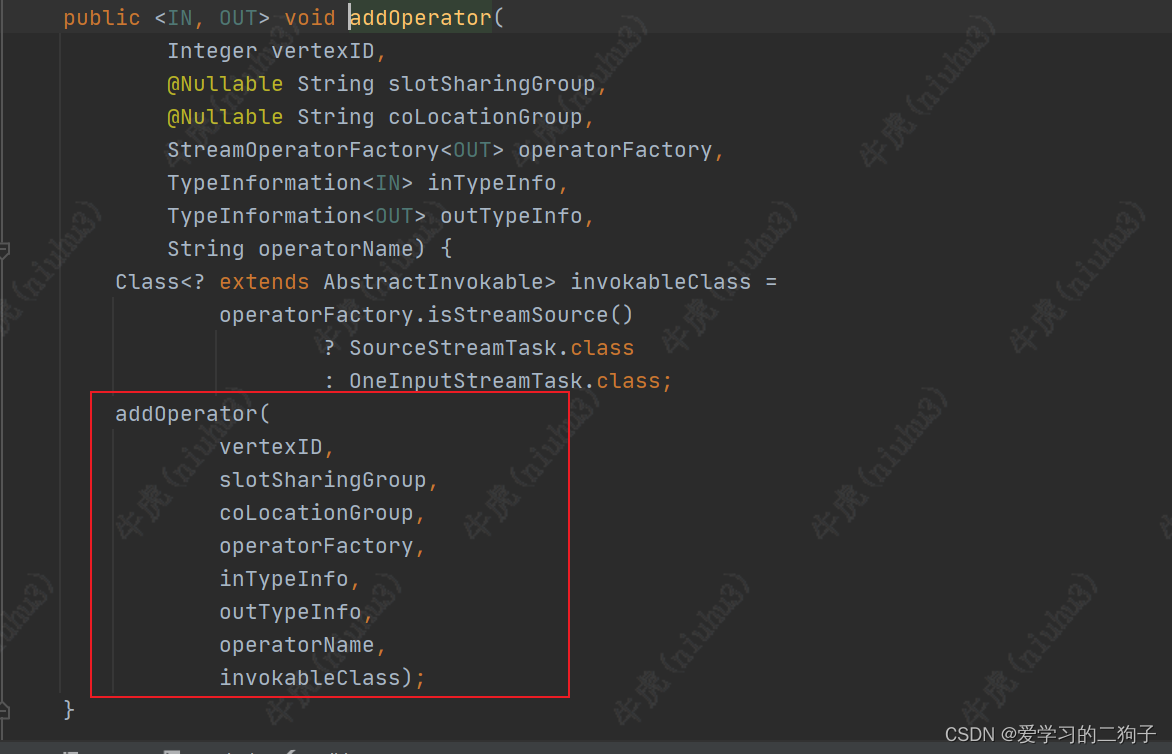
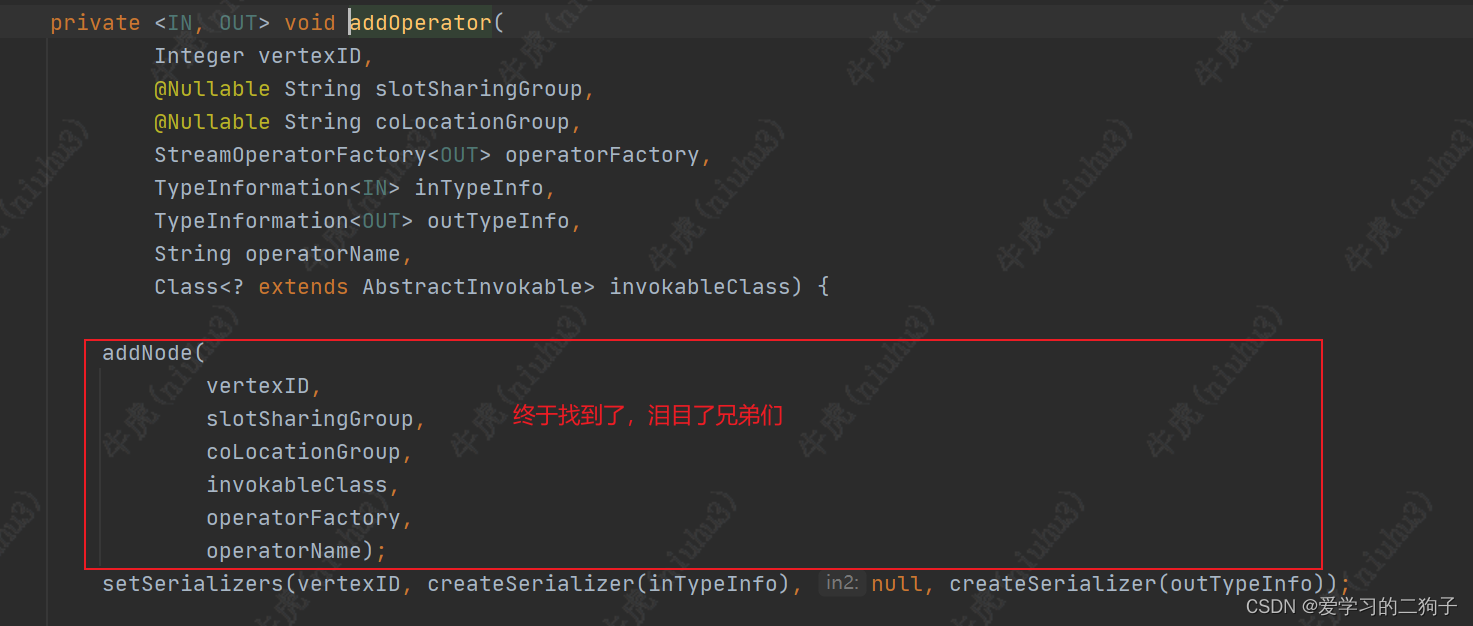
这里transformation也就转换成streamGraph了,离我们的目标物理执行图更进了一步,下次我们在讲streamGraph怎么转换成JobGraph。(都看到这了,还不点赞,白嫖可耻啊)

