
- 1hadoopdataplatform_hadoop大数据平台安全基础知识入门
- 2Qt中出现中文乱码的原因以及解决方法_qt中文乱码解决方法
- 3git submodule命令_.git文件 submodule
- 4学习Spring Cloud第六课(将微服务注册到Eureka Server上)_微服务192.168.153.1
- 5处理3D数据的强大工具 CloudCompare (多平台兼容)_cloud compare 出图
- 6详情!安全运维工程师怎么考?报考难度大吗?证书含金量高吗?_安全运维工程师证书
- 7数据结构—树(自学笔记)(郝斌)_树的每个结点有且仅有一个父节
- 8python 文件读写操作总结_python文件读写实验总结
- 9Unity C# 之 使用 HttpWebRequest 基础知识/HttpWebRequest 进行异步Post 网络访问/数据流形式获取数据(Task/async/await)的代码简单实现_unitywebrequest 异步
- 10微信小程序开发 json配置文件详解导航栏设置 tabbar设置,主题颜色设置_在index.json中如何设置导航条
【Hive】云任务大量卡住故障分析_hive metastore卡住
赞
踩
项目场景:
上一章节我们简单介绍到了JVM调优相关的知识,本章节结合日常故障处理进一步说明相关的使用
问题描述
在云上,hive任务出现大面积卡住的现象,但并无任何报错信息,具体如下:

原因分析:
- 考虑hivemetastore故障:
经过很多元数据操作测试,并未发现异常,予以排除。
- 考虑hiveserver2连接数超限问题:
经排查hiveserver2虽然有189个连接数,但并未超过设置的hive.server2.thrift.max.worker.threads上限,予以排除。
- 考虑hiveserver2的JVM问题:
经观察资源使用正常,并没有触发该问题的可能,予以排除,当时的jvm使用情况如下:

- 考虑锁机制相关问题:
经过抓取多时段堆栈信息,发现任务运行过程中,产生了许多
BLOCKED以及WAITING,予以高度关注。
首先无论一个APP产生多少个JOB执行,这些JOB都会被分配到同一个线程中串行执行,直至任务结束。
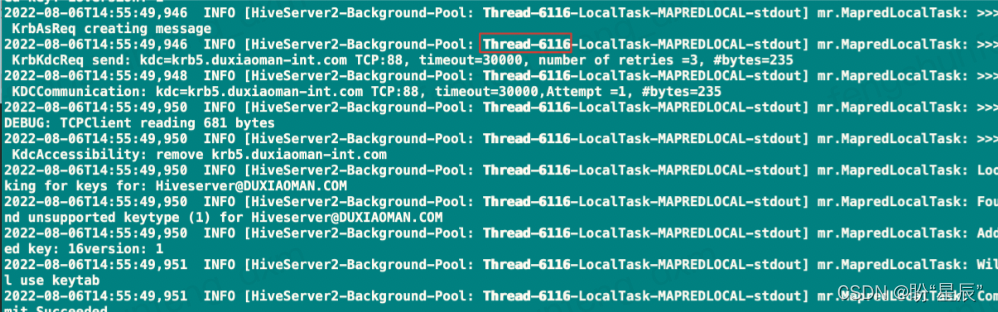
堆栈信息中显示,该线程由于一直在等待<0x0000000788597b0>锁,处于边界,导致死锁。
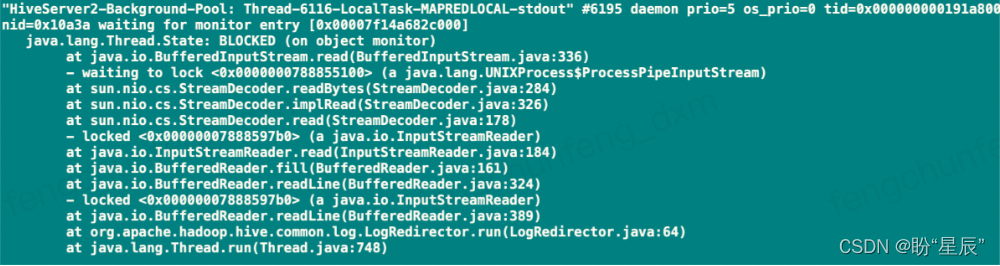
再继续查找持有<0x0000000788597b0>锁的线程,经过多次采集信息发现,该持有锁的线程,一直持有,不释放。

根据该线程相关信息,DEBUG追踪相关代码,发现该while循环一直不结束,永远跳不出来,处于死循环状态。
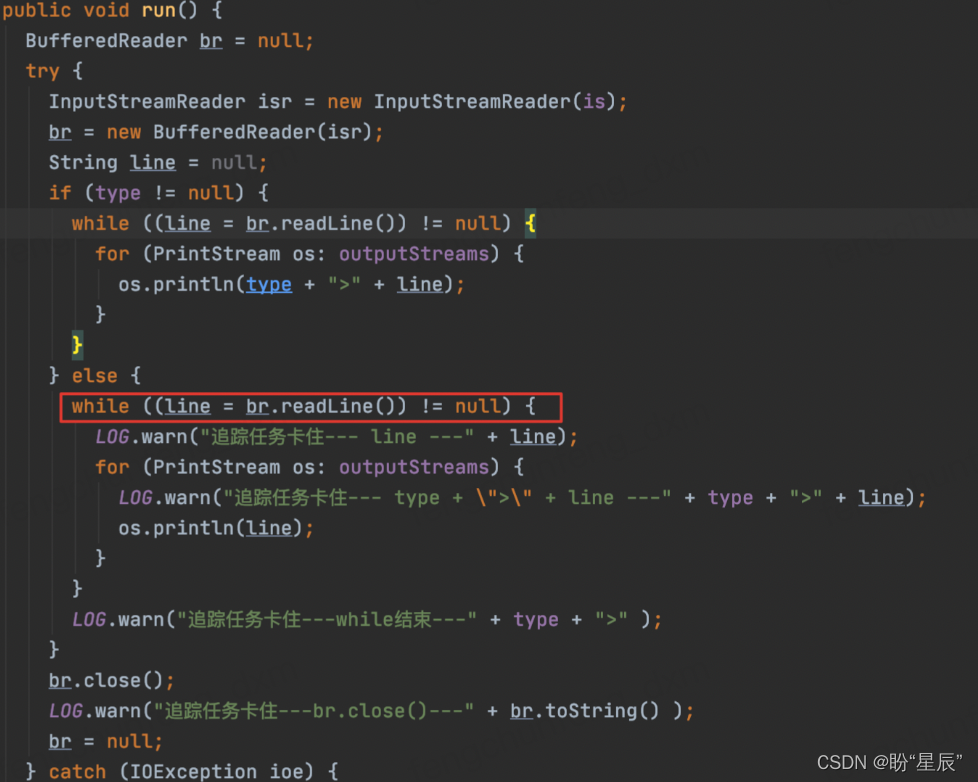
根据该线索,进一步排查到底哪里使用了该方法,启动了线程呢?根据测试的SQL特点和不同任务对比,定位到MapredLocalTask这个class类。


根据MapredLocalTask的具体执行逻辑,主要涉及到mapjoin的问题,尝试关闭mapjoin功能(set hive.auto.convert.join=false;),再次运行任务,奇迹发生了,任务可以执行成功。

总结:
结合原理可知,Map Join的适用大表Join小表及不等值的链接操作。
关于小表的大小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。实际中此参数允许的最大值可以修改,但是一般最大不能超过1GB
Hive0.7之前,需要使用hint提示/+mapjoin(table)/才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true。

