
热门标签
热门文章
- 1深度学习(11)之Anchor-Free详解
- 2算法训练营第六十九天 | 并查集理论基础、寻找存在的路径、冗余连接、冗余连接II_卡码网
- 3Git常用命令大全_git rename
- 4弹出框 custombox.min.js 使用时候由于滚动条隐藏造成网页抖动变形的解决办法
- 5【前端系列】20种 Button 样式_前端按钮
- 6uniapp:完成商品分类页面(scroll-view),左侧导航,右侧商品_uniapp左侧导航右侧内容
- 7深度学习实战—基于TensorFlow 2.0的人工智能开发应用_深度学习实战:基于tensorflow
- 8QT网络编程之实现TCP客户端和服务端_qt tcp客户端
- 9哈工大(HIT)计算机网络 翻转课堂 实验 mooc答案 总结_哈工大计网mooc答案
- 10Stable Diffusion学习笔记_马尔科夫链的反向过程是
当前位置: article > 正文
Spark3.x-实战之双流join(窗口和redis实现方式和模板代码)_spark range join
作者:运维做开发 | 2024-06-30 08:11:50
赞
踩
spark range join
简介
在spark实时项目的时候难免会遇到双流join的情况,这里我们根据它的一些实现和代码做简单的说明
join的前提知识
- object Test {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("join").setMaster("local[*]")
- val sc = new SparkContext(conf)
- val rdd1 = sc.makeRDD(List((1, "a"), (2, "b"), (3, "c")))
- val rdd2 = sc.makeRDD(List((1, "a1"), (1, "a2"), (4, "d1")))
- println("join: " + rdd1.join(rdd2).collect().toList)
- println("leftOuterJoin: " + rdd1.leftOuterJoin(rdd2).collect().toList)
- println("rightOuterJoin: " + rdd1.rightOuterJoin(rdd2).collect().toList)
- println("fullOuterJoin: " + rdd1.fullOuterJoin(rdd2).collect().toList)
- }
- }
结果
- join: List((1,(a,a1)), (1,(a,a2)))
- leftOuterJoin: List((1,(a,Some(a1))), (1,(a,Some(a2))), (2,(b,None)), (3,(c,None)))
- rightOuterJoin: List((1,(Some(a),a1)), (1,(Some(a),a2)), (4,(None,d1)))
- fullOuterJoin: List((1,(Some(a),Some(a1))), (1,(Some(a),Some(a2))), (2,(Some(b),None)), (3,(Some(c),None)), (4,(None,Some(d1))))
方式一(窗口实现)
简介
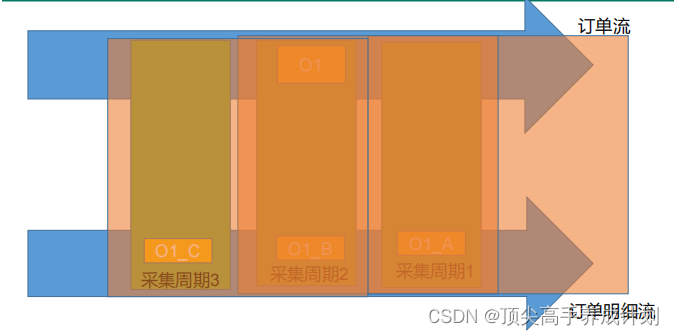
- 这里的思想主要是滑动窗口的原理,但是就是如果数据不在同一批次,那么可以把划窗尽量的调大一点,尽量让他们在同一批次,那么就可以进行join操作了,但是这种方法会有数据丢失的情况
具体代码例子
核心代码
- //开窗 指定窗口大小和滑动步长
- val orderInfoWindowDstream: DStream[OrderInfo] =
- orderInfoDstream.window(Seconds(50), Seconds(5))
- val orderDetailWindowDstream: DStream[OrderDetail] =
- orderDetailDstream.window(Seconds(50), Seconds(5))
- // join
- val orderInfoWithKeyDstream: DStream[(Long, OrderInfo)] =
- orderInfoWindowDstream.map(
- orderInfo=>{
- (orderInfo.id,orderInfo)
- }
- )
- val orderDetailWithKeyDstream: DStream[(Long, OrderDetail)] =
- orderDetailWindowDstream.map(
- orderDetail=>{
- (orderDetail.order_id,orderDetail)
- }
- )
- val joinedDstream: DStream[(Long, (OrderInfo, OrderDetail))] =
- orderInfoWithKeyDstream.join(orderDetailWithKeyDstream,4)

方式二(redis缓存的方式实现)
简介
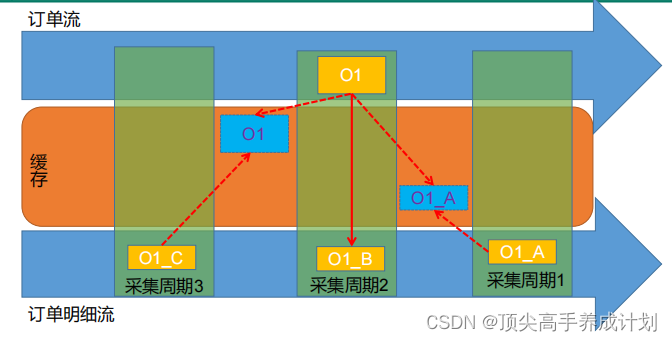
这种方式就是数据来的时候有三种情况,由于不想消息丢失使用的join是fulljoin
- 订单表到了,订单明细也到了
- 订单表到了,订单明细表没有到
- 订单表没有到,订单明细表到了的情况
如果是订单表到了,订单明细也到了,那么这个时候就是join成功,但是为了处理后面还有没有到的数据,那么想处理的话,就把订单表缓存到redis里面
如果订单明细表先到,就保存到redis里面等待订单表的到来,如果订单表到了,就join然后在redis里面删除自己
模板代码示例
前提实现kafka精准一次消费
redis里面保存的数据例子

代码实现
- object DwsStuScoreJoin {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- //这里的partition的数目要和kafka的分区数一致
- conf.setAppName(this.getClass.getSimpleName).setMaster("local[4]")
- val ssc = new StreamingContext(conf, Seconds(1))
-
- // 分别读取两条流
- val stuCourseTopicName = "dwd_tb_stu_course"
- val stuCourseGroupName = "dwd_tb_stu_course"
- val stuTopicName = "dwd_tb_stu"
- val stuGroupName = "dwd_tb_stu"
-
-
- //得到dwd_tb_stu_course的DStream
- val stuCourseOffset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(stuCourseTopicName, stuCourseGroupName)
- var stuCourseKafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
- if (stuCourseOffset != null && stuCourseOffset.size > 0) {
- stuCourseKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByMapTopicPartition(stuCourseTopicName, stuCourseOffset, ssc)
- } else {
- stuCourseKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByDefault(stuCourseTopicName, ssc)
- }
- var stuCourseOffsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
- val stuCourseTransformDStream: DStream[ConsumerRecord[String, String]] = stuCourseKafkaInputDStream.transform(
- rdd => {
- val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
- stuCourseOffsetRanges = ranges.offsetRanges
- rdd
- }
- )
- val stuCourseKafkaValue: DStream[String] = stuCourseTransformDStream.map(_.value())
-
-
- //得到dwd_tb_stu的DStream
- val stuOffset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(stuTopicName, stuGroupName)
- var stuKafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
- if (stuOffset != null && stuOffset.size > 0) {
- stuKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByMapTopicPartition(stuTopicName, stuOffset, ssc)
- } else {
- stuKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByDefault(stuTopicName, ssc)
- }
- var stuOffsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
- val stuTransformDStream: DStream[ConsumerRecord[String, String]] = stuKafkaInputDStream.transform(
- rdd => {
- val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
- stuOffsetRanges = ranges.offsetRanges
- rdd
- }
- )
- val stuKafkaValue: DStream[String] = stuTransformDStream.map(_.value())
-
-
- // stuCourseKafkaValue.foreachRDD(rdd => {
- // rdd.foreach(item => {
- // println(item)
- {"courseId":"1","courseName":"数学","id":"069428","score":"120","stuId":"6be3f5","tearchName":"小李老师"}
- // })
- // // 如果都操作完了这里就是保存偏移量
- // OffsetManagerUtil.saveOffset(stuCourseTopicName, stuCourseGroupName, stuCourseOffsetRanges)
- // // 手动提交kafka的偏移量
- // stuCourseKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuCourseOffsetRanges)
- //
- // })
- //
- // stuKafkaValue.foreachRDD(rdd => {
- // rdd.foreach(item => {
- // println(item)
- {"aearName":"华东地区","areaCode":"0001","id":"6be3f5","stuName":"小同学"}
- // })
- //
- // // 如果都操作完了这里就是保存偏移量
- // OffsetManagerUtil.saveOffset(stuTopicName, stuGroupName, stuOffsetRanges)
- // // 手动提交kafka的偏移量
- // stuKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuOffsetRanges)
- // })
- // 上面能够得到两条流的数据
- //第一条流是stuCourseKafkaValue:{"courseId":"1","courseName":"数学","id":"069428","score":"120","stuId":"6be3f5","tearchName":"小李老师"}
- //第二条是stuKafkaValue{"aearName":"华东地区","areaCode":"0001","id":"6be3f5","stuName":"小同学"}
-
- // 下面是使用双流join的操作
-
- // 这里有三种情况使用redis缓存join,假设学生一次可以输入多条成绩信息的情况
- // 1. 如果stu到了,stuCourse也到了
- // 2. 如果stu到了,stuCourse没有到
- // 3. 如果stu没到 ,stuCourse 到了
- // 注意由于用学生关联成绩那么不管stuCourse到了,还是没有到都会在redis缓存防止有晚到的数据
- // 如果stuCourse缓存在redis里面,如果stu到了那么就把他删除
-
- // 1.先把数据变成key,value结构才能join
- val stuIdAndStu: DStream[(String, TbStu)] = stuKafkaValue.map(item => {
- val stu: TbStu = JSON.toJavaObject(JSON.parseObject(item), classOf[TbStu])
- (stu.id, stu)
- })
-
- val stuIdAndCourse: DStream[(String, TbStuCourse)] = stuCourseKafkaValue.map(item => {
- val course: TbStuCourse = JSON.toJavaObject(JSON.parseObject(item), classOf[TbStuCourse])
- (course.stuId, course)
- })
-
- //这里得到的是fullJoin的结果
- val fullJoin: DStream[(String, (Option[TbStu], Option[TbStuCourse]))] = stuIdAndStu.fullOuterJoin(stuIdAndCourse)
-
- val resStuWide: DStream[StuWide] = fullJoin.mapPartitions(iter => {
-
- val jedis: Jedis = OffsetManagerUtil.jedisPool.getResource
- val res: ListBuffer[StuWide] = ListBuffer[StuWide]()
- for ((stuId, (stu, course)) <- iter) {
- if (stu.isDefined) {
- //stu来了
- if (course.isDefined) {
- //如果course来了
- val resItem: StuWide = StuAndStuScore.getStuWide(stu.get, course.get)
- res.append(resItem)
- }
-
- //由于course来还是没有来stu保存在redis里面,目的就是等待晚来的数据
- //这里选用存储stu的数据格式为string,keuy=FullJoin:Stu:stuid
- val stuKey = s"FullJoin:Stu:${stu.get.id}"
- //把json数据传入进去,默认保存一天,根据自己的情况来定
- val stuJsonCache: String = JSON.toJSONString(stu.get, JSON.DEFAULT_GENERATE_FEATURE)
- jedis.setex(stuKey, 3600 * 24, stuJsonCache)
-
- //stu先到还要看下缓存里面有没有之前到的course
- val couKey = s"FullJoin:Course:${stu.get.id}"
- val courseCacheDatas: util.Set[String] = jedis.smembers(couKey)
-
- val scala: mutable.Set[String] = courseCacheDatas.asScala
- for (elem <- scala) {
- val courseItem: TbStuCourse = JSON.toJavaObject(JSON.parseObject(elem), classOf[TbStuCourse])
- //这里在把数据加入进去
- val stuRes: TbStu = stu.get
- val wide: StuWide = StuAndStuScore.getStuWide(stuRes, courseItem)
- res.append(wide)
- }
-
- //删除掉处理完的course数据
- jedis.del(couKey)
- } else {
- //如果stu没有来,我们选用set存储分数
- val courseKey = s"FullJoin:Course:${course.get.stuId}"
- val courseJsonCache: String = JSON.toJSONString(course.get, JSON.DEFAULT_GENERATE_FEATURE)
- jedis.sadd(courseKey, courseJsonCache)
- }
- }
-
- //关闭资源
- jedis.close()
- res.iterator
- })
-
- resStuWide.foreachRDD(rdd => {
- rdd.foreach(item=>{
- println("===========")
- println(item)
- val stuWide: String = JSON.toJSONString(item, JSON.DEFAULT_GENERATE_FEATURE)
- MyKafkaSinkUtil.send("dws_tb_stuwide",stuWide)
- })
-
-
- // 如果都操作完了这里就是保存偏移量
- OffsetManagerUtil.saveOffset(stuCourseTopicName, stuCourseGroupName, stuCourseOffsetRanges)
- // 手动提交kafka的偏移量
- stuCourseKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuCourseOffsetRanges)
-
- // 如果都操作完了这里就是保存偏移量
- OffsetManagerUtil.saveOffset(stuTopicName, stuGroupName, stuOffsetRanges)
- // 手动提交kafka的偏移量
- stuKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuOffsetRanges)
-
- })
-
- ssc.start()
- ssc.awaitTermination()
- }
-
- }
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/771936
推荐阅读
相关标签

