
- 1CentOS7虚拟机中使用kolla-ansible部署all-in-one模式openstack详细步骤_openstack all in one
- 21.12 实例:猜数字小游戏_verilog猜数字游戏
- 3深度学习如何入门?_深度学习 入门
- 4python calendar模块常用方法_python calendar用法
- 5LeetCode:419. 甲板上的战舰————中等_甲板上的战舰 js
- 6python中的sorted怎么用_python sorted方法和列表使用解析
- 7MySQL知识总结一(MySQL常见术语)_mysql 术语解释
- 8FPGA 20个例程篇:20.USB2.0/RS232/LAN控制并行DAC输出任意频率正弦波、梯形波、三角波、方波(一)_用verilog控制dac产生波形
- 9新版onenet平台安全鉴权的确定与使用_新版onenet没有鉴权_onenet新版本的设备的鉴权信息是什么
- 10ARP解析_arp报文
Unified Named Entity Recognition as Word-Word Relation Classification
赞
踩
论文链接:Unified Named Entity Recognition as Word-Word Relation Classification
code链接: https://github.com/ljynlp/W2NER.git
NER任务根据实体的情况可以分为扁平实体(flat ner)、嵌套实体(nested ner)、不连续实体(discontinuous ner)。如果实际的实体抽取场景中同时包含了上述三种实体,那么就需要一种统一的NER框架来处理。
NER抽取的方法大致可以分为四种:
1.序列标注方法,比如常用的BIEOS, BIO;
2.超图的方法;
3.span的方法,指针网络或token 对的形式;
4.生成的方法。
序列标注方法可以很好解决扁平实体的问题,对于嵌套实体通过修改标注可以勉强解决,但是会增加模型复杂度;而面对不连续实体序列标注方法无法解决。所以在只存在扁平实体的情况下,可以选择序列标注的方法,这边推荐一下复旦邱锡鹏老师团队的tener方法,使用transofrmer改进结构的模型。
同样基于超图的方法则有结构歧义的问题。
span的方法仅仅聚焦于实体边界的识别,同时在实体长度太长也会有模型复杂度的问题。
生成的方法能很好的统一三种ner的任务,邱锡鹏老师团队同样有相关的研究。但是生成的方式存在exposure bias和解码效率的问题。
对于扁平型实体任务的关键在于边界的识别,但是统一的ner模型更加依赖于实体词之间关系(尤其是不连续实体的识别)。
本文采用一种新颖的词关系结构W2NER,同时对实体边界和实体词关系进行建模,充分考虑了实体边界和内部词的关系。使用多粒度的2维卷积重新定义词对表示,能有效捕捉近距离词对和远距离词对之间的交互作用。
这是本文主要的两个创新点。

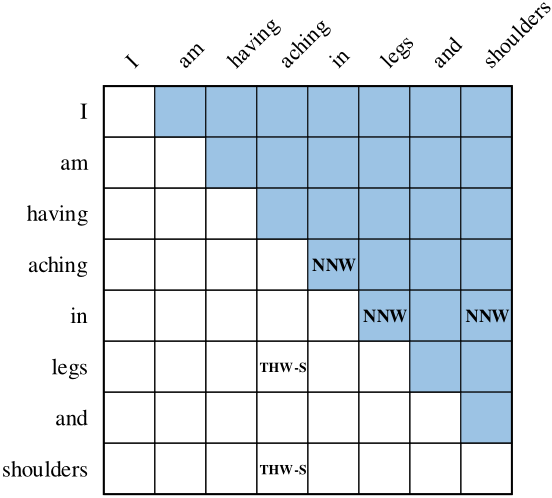
W2NER把实体的标签分类以词之间的关系标注在一个词对的网格中。如图,词对网格以对角线被分成两部分,右上的网格中表示当前词与后续词的连接关系,标有NNW的网格表示横向词与纵向词是同一实体,(aching,in)、(in,legs)、(in,shoulders)在同一实体中;右下角网格表示实体尾部和头部的连接关系,标有THW-S的网格表示横向词、纵向词分别为同一实体的结尾和开头,(shoulders,aching)、(legs,aching)分别为两个实体的结尾开头。网格中其他的值为None,表示无连接关系。所以根据图中可知,aching in legs 和 aching in shoulders 为句子中的两个实体。
统一ner框架
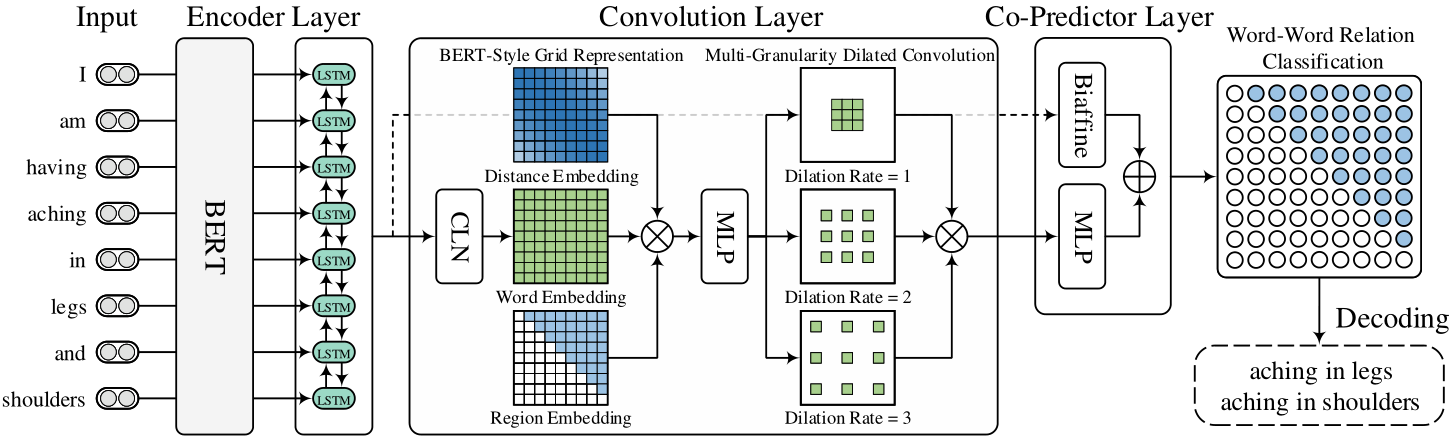
编码层
编码层由bert和bilstm组成,生成单词表示。
卷积层
Conditional Layer Normalization
编码层的输出维度是N*D,但是根据最后的标注看词对之间的关系是有方向的。所以通过该层将输入的表示维度变成N*N*D,具体的方法如下:

BERT-Style Grid Representation Build-Up
从名字可以看出是借鉴了bert的思想,bert的输入分别了词向量、位置向量和段向量三部分。本文类似地生成三种词对网格分别表示词信息、相对位置信息和网格中的区域信息。最后将三种信息进行concat后输入MLP中。输出特征大小为N*N*Dc。
Multi-Granularity Dilated Convolution
最后使用空洞卷积来获取不同距离词之间的交互信息。最后的输出特征表示大小为N*N*3Dc。
联合预测层
该层由MLP和Biaffine分类器共同组合而成。biaffine预测器的输入是encoder层的输出,所以可以看成是残差连接层。MLP的输入则是上一层卷积层的输出。最后两侧输出相加进行softmax层。
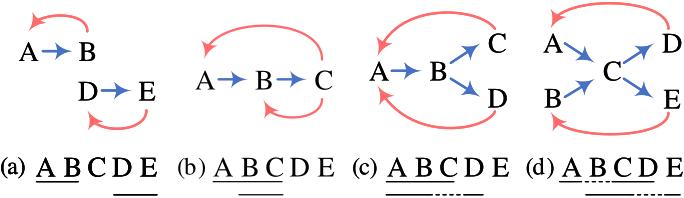
解码层
解码层就是通过最后词对关系找到一个词到另一词的特定路径,每条路径就是一个实体。图中就是几种解码的情况;
实验结果
在中英文数据集上都达到了SOTA,具体结果见论文。
消融实验
没有区域和距离向量,效果有轻微的下降,但是去除了所有的卷积层,效果下降明显,验证了多粒度空洞卷积的有效性。去除空洞卷积后的效果也有下降,尤其是空洞为2的卷积;
所以词之间的交互信息影响最后的抽取效果,尤其是较大距离的词。
在预测层,MLP则发挥了更大的作用。
结论
本文使用词对网络的标注方法(W2NER)同一了ner框架,并且使用多种卷积的结构抽取网格表示,并在多个中英文数据集上达到SOTA。

