
- 1hive中行转列,列转行的各种情况及解决方法_hive 行转列几种方法
- 25-1对抗生成神经网络(GAN)--Keras实现_对抗神经网络python keras
- 3设计模式-解释器模式(Interpreter)_设计模式 解释器模式
- 4网络安全技术入门到项目实战_微职位 网络安全技术入门到项目实战视频教程解压密码
- 5burp2023专业版,配置上游代理太难找_burpsuite2023
- 6大数据处理实验(三)HDFS基本操作实验_hdfs的基本操作大学实验
- 7VS Code工具将json数据格式化_vscode json格式化
- 8关于YOLOv5_deepsort训练自己的数据集_deepsort训练自己的特征权重文件
- 9unity android录制视频教程,Unity移动端视频录制,Android和IOS都支持
- 10优雅停机方案
python下进行lda主题挖掘(三)——计算困惑度perplexity_lda困惑度-6
赞
踩
到2018年3月7日为止,本系列三篇文章已写完,可能后续有新的内容的话会继续更新。
python下进行lda主题挖掘(一)——预处理(英文)
python下进行lda主题挖掘(二)——利用gensim训练LDA模型
python下进行lda主题挖掘(三)——计算困惑度perplexity
本篇是我的LDA主题挖掘系列的第三篇,专门来介绍如何对训练好的LDA模型进行评价。
训练好LDA主题模型后,如何评价模型的好坏?能否直接将训练好的模型拿去应用?这是一个比较重要的问题,在对模型精度要求比较高的项目或科研中,需要对模型进行评价。一般来说,LDA模型的主题数量都是需要需要根据具体任务进行调整的,即要评价不同主题数的模型的困惑度来选择最优的那个模型。
那么,困惑度是什么?
1.LDA主题模型困惑度
这部分参照:LDA主题模型评估方法–Perplexity,不过后面发现这篇文章Perplexity(困惑度)感觉写的更好一点,两篇都是翻译的维基百科。
perplexity是一种信息理论的测量方法,b的perplexity值定义为基于b的熵的能量(b可以是一个概率分布,或者概率模型),通常用于概率模型的比较
wiki上列举了三种perplexity的计算:
1.1 概率分布的perplexity
公式: 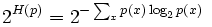
其中H§就是该概率分布的熵。当概率P的K平均分布的时候,带入上式可以得到P的perplexity值=K。
1.2 概率模型的perplexity
公式: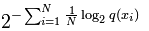
公式中的Xi为测试局,可以是句子或者文本,N是测试集的大小(用来归一化),对于未知分布q,perplexity的值越小,说明模型越好。
指数部分也可以用交叉熵来计算,略过不表。
1.3单词的perplexity
perplexity经常用于语言模型的评估,物理意义是单词的编码大小。例如,如果在某个测试语句上,语言模型的perplexity值为2^190,说明该句子的编码需要190bits
2.困惑度perplexity公式
p e r p l e x i t y = e − ∑ l o g ( p ( w ) ) N perplexity = e^ {\frac{ - ∑log(p(w))}{N}} perplexity=e


