
- 1【视频异常检测】Attribute-based Representations for Accurate and Interpretable Video Anomaly Detection 论文阅读
- 2【氮化镓】位错对氮化镓(GaN)电子能量损失谱(EEL)的影响
- 3如何更换pycharm默认的terminal_pycharm的terminal默认环境
- 4你也想要用免费ai写作生成器吗?三个生成器的使用方法分享
- 5区块链实验室(33) - 用Geth+Prysm创建一个Ethereum私链_geth prysm
- 6射频识别(RFID)技术的基本原理、特性、发展和应用_了解附近超市或商场是否使用电子标签(rfid),观察了解射频识别技术系统的硬件
- 7网站内部优化-怎么做好网站内部SEO优化-网站内部SEO优化方案_147seo的文章只能一半
- 8JavaScript高级面试题_js高级面试
- 9生成式AI:革新软件开发流程与工具的未来趋势
- 10XMC4800/4300入门:(1)常见问题汇总_英飞凌xmc4编程手册
业界分布式训练框架学习笔记1_分布式训练 num_worker
赞
踩
分布式训练框架的实现逻辑学习笔记
1、Why?
深度学习模型尺寸逐渐扩大,训练数据量显著上升。为了更好利用训练资源,提高效率。
2、 分布式训练原理
主要两种思路:一是模型并行,另一个是数据并行。
(1) 模型并行
即将一个模型分拆为多个小模型,分别放在不同设备上,每个设备可跑模型的一部分(例如,UNet网络就是将模型拆为两部分,分别在两块卡上训练)。
存在的问题:模型在训练时需要更新梯度等,使得模型各部分之间关联性较大,因此这种方式效率较低,需要分散在不同设备之间的频繁通信,一般少用。
(2) 数据并行
即将数据切块分在不同设备上,但每个设备上都具有完整的模型,每个模型输入不同的数据进行训练。这种方式是目前最常用的分布式实现方法。
3、Parameter Server 分布式架构-Tensorflow采用
简称PS架构,主要包括1到多个server节点和多个worker节点。其中server节点用于保存模型参数,若有多个server节点,模型参数会保存多份至多个server上,而worker节点根据server上的模型参数以及worker本地上的数据计算梯度。
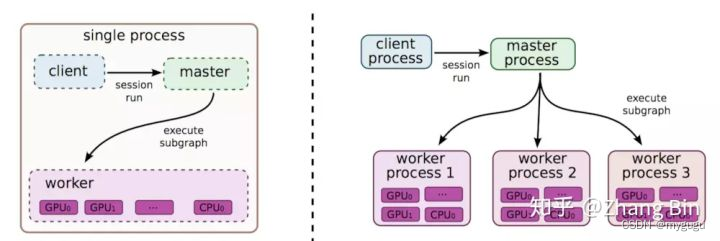
每个step的训练过程主要分为3个步骤:
- 每个worker从server上拷贝完整的模型参数;
- 用每个worker上的数据基于拷贝的参数计算梯度;
- 每个worker回传计算后的新梯度给server,server节点进行参数更新。
针对上述步骤,发现在步骤3中可以存在两种更新方式:异步更新和同步更新。
异步更新
在每个step中,每个worker计算梯度后直接回传给server,不需等待其他worker,server节点接收后直接根据新梯度更新模型参数。因此异步方式效率很高,随着设备数量的增加运行效率线性提升。
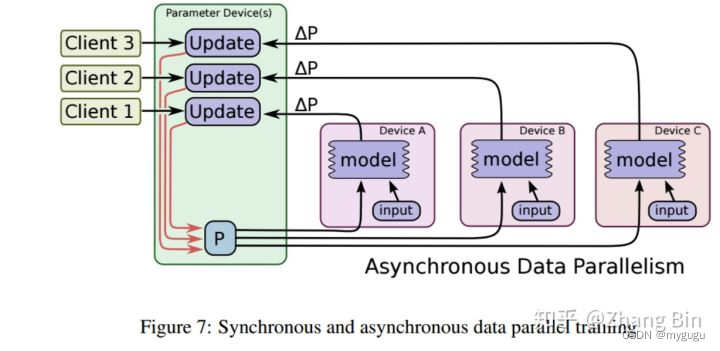
存在的缺点:
可能出现无效梯度导致训练效果不好。例如:两个worker节点a和b,二者最初拿到的参数相同,但a更新速度快,更新完成后回传新梯度到server,server也进行了参数更新,恰好此时b也运行完成了,但b的计算结果对于server而言已经没意义,因为server已经根据a的新梯度更新完参数了,此时b计算的梯度载回传到server,还是基于最原始的模型参数,就无效了。理论上正确的操作应该是a回传到server,server更新后b要用server更新后的参数再次进行计算。
同步更新
ps需要等待所有worker都回传梯度后,才进行参数更新,保障了各个worker计算梯度时参数的一致性,不会出现无效梯度问题。
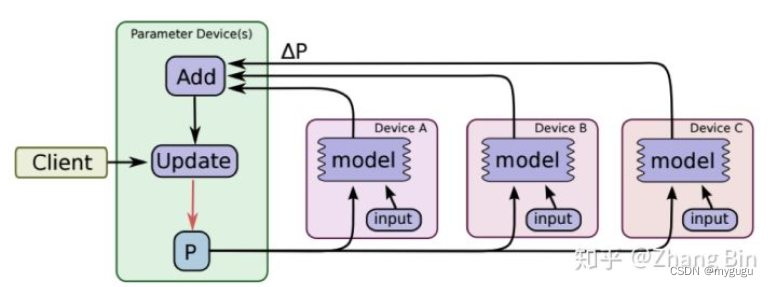
存在的缺点:
会出现同步阻塞问题,即只要有一个worker没有回传梯度,当前step就会一直等待。
同步更新和异步更新如何选择?
同步更新:精度好但效率可能慢;适用于模型对一致性敏感度较高的情况。
异步更新:速度快但精度差。适用于运行速度的情况。
二者是精度和运行效率之间的取舍。进行折中处理:在同步更新中设定最大等待步数N,N个steo内server上的参数必须更新一次。
PS架构小结
随着worker数量(GPU CPU)的增加,模型运行效率并不一直线性提升,要考虑server带宽问题,在一定带宽下,worker数量增加,会增加 worker与server之间的通信时长,至此带来的效率提升边际收益递减。
解决办法:增加server数量,提升server带宽。
4、Ring AllReduce架构–Pytorch
与PS结构不同之处:PS结构中,worker数量较多时,会因为网络带宽问题出现瓶颈。
特点:运行效率随着worker数量的增加是线性增加。
采用环形结构,没有中央节点server,都是worker节点,每个worker与相邻的两个worker连接,从上行的worker接收数据,并向下行的worker发送数据,因此可充分利用每个worker的上下行带宽。
每个worker都有一份完整的模型参数,并进行梯度计算和更新。
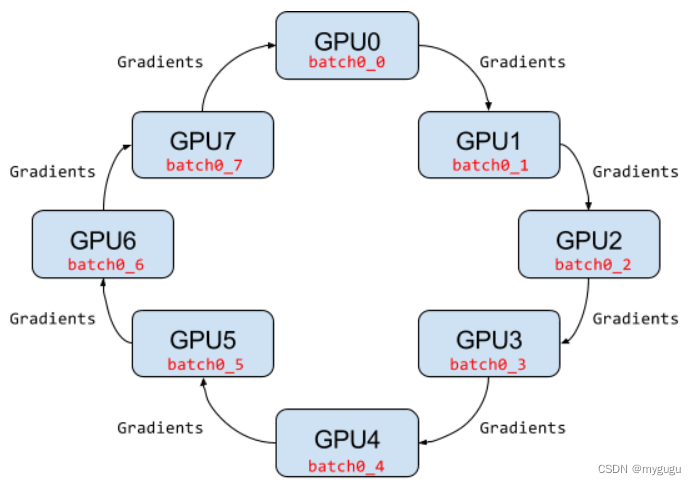
实现同步更新的时候Ring AllReduce架构主要分为scatter reduce和allgather两个步骤。
Ring AllReduce分布式训练基本过程

(假设有N个worker)
1、首先每个worker(设备)根据各自训练数据分别计算梯度;
2、每个worker计算的梯度N等分(每个worker的分割方法一致,分片数与worker数相等),
3、ScatterReduce 阶段:通过 N-1 轮梯度传输和梯度相加,在每个设备上的梯度向量都有一小部分为所有设备中该分片梯度之和 (图③)
4、AllGather 阶段:通过 N-1 轮梯度传输,将上个阶段计算出的每个梯度向量分片之和广播到其他设备(图④)
5、在每个设备上合并分片梯度,并根据梯度更新每个设备上的模型
该过程的目的:让每个worker都有一部分网络参数,能融合所有其他worker上的梯度,得到一份完整的梯度。
效率分析
Parameter-Server
假设模型的总参数量为X, server为1,worker数为N,设备间数据最大传输速度为B。
因为server要接收所有worker梯度,再将更新后的模型参数发送给所有worker,因此数据通信的耗时为2(X-N)/B, 从公式发现随着N线性增加,整体数值也是线性增加。
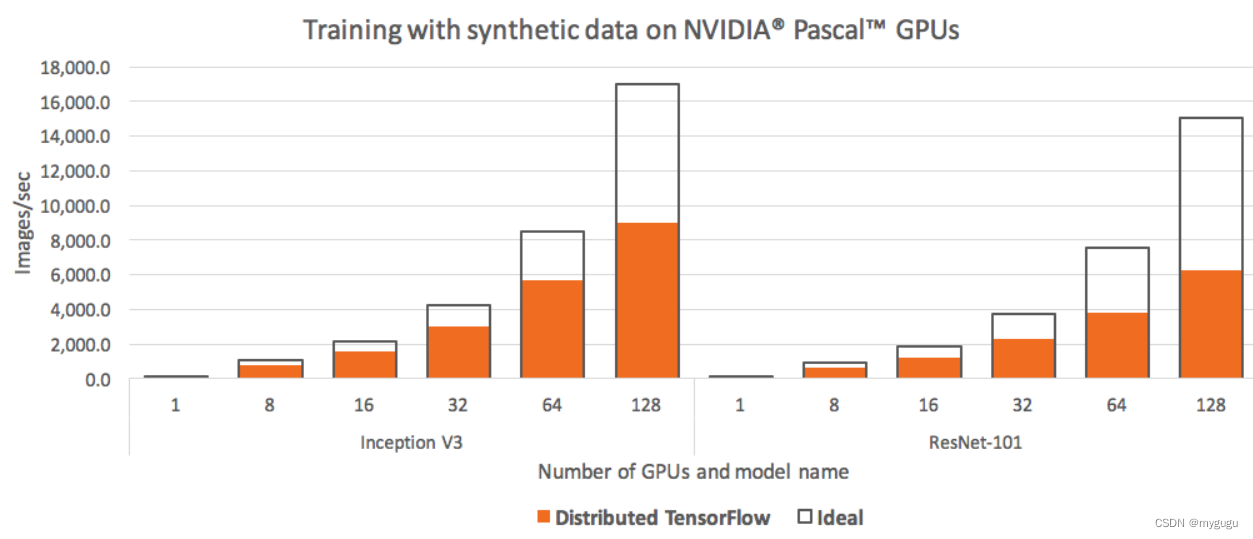
因此当GPU设备增加到一定规模时每个Batch的训练将耗费大量时间用于不同设备间的通信。
如图所示,GPU=64时,性能与理想性能差已经较大。
Ring AllReduce
一次Ring AllReduce过程总共要进行2*(worker_num-1)次信息提交,且每个worker的信息交互次数相同,因此平均到每个worker的通信量为2*(worker_num-1)/worker_num。当worker_num增加时,整体值不会增加,所以其运行效率会随着worker数量的增加呈线性增长。
此外,在训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于后面层,Ring-allreduce架构充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。
参考:
https://www.zhihu.com/question/473840666
https://zhuanlan.zhihu.com/p/70603273

