
- 1机器学习常用性能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什么东西?...
- 2特征选择方法之TF-IDF、DF_tf-idf特征词
- 3EMNLP -- Call for Main Conference Papers_emnlp2023
- 4HTML5+CSS3实现小米商城(有源码)_小米商城菜单html代码
- 5【Python】通过第三方库wxauto自动化操作微信电脑客户端
- 6cnn和transformer区别_transformer和cnn的区别
- 7人工智能&统计&大数据带动数据时代_大数据与人工智能时代的统计研究
- 8SIM7600CE-CNSE 4G模块 树莓派/Windows连网指南_at+cnmp
- 9Java优先队列/堆(PriorityQueue)中3种重写compare的方法_prorityqueue compare
- 10OpenCV联通组件扫描
基于前馈网络的手写数字识别系统_基于前馈神经网络的数字识别
赞
踩
先看效果:
手写数字9识别测试
手写数字6识别测试
这个项目建立了一个含一个隐藏层(50个神经元)的前馈网络。对数字采用One-hot编码,因此输出层设置10个神经元;又因为mnist数据集中图像大小为28*28,故输入层设置784个神经元。将输入层到隐藏层、隐藏层到输出层的偏置整合到前一层的输出矩阵和两层间的权重矩阵上,则得到矩阵:
输入层:
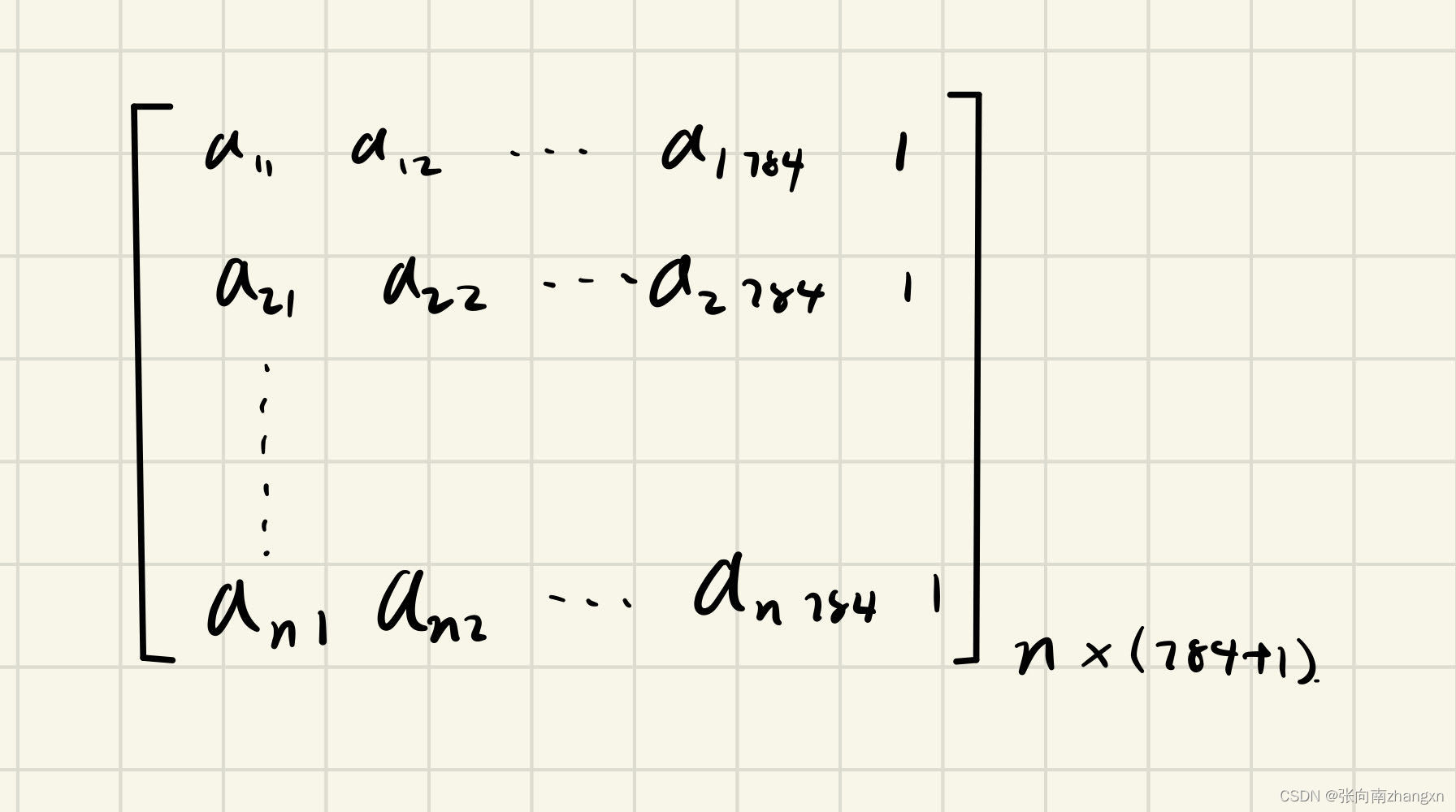
其中n是训练集数据条数。采用批量梯度下降算法,则使用训练集全部六万条数据进行训练,n=60000。
第1,2层间权重矩阵:
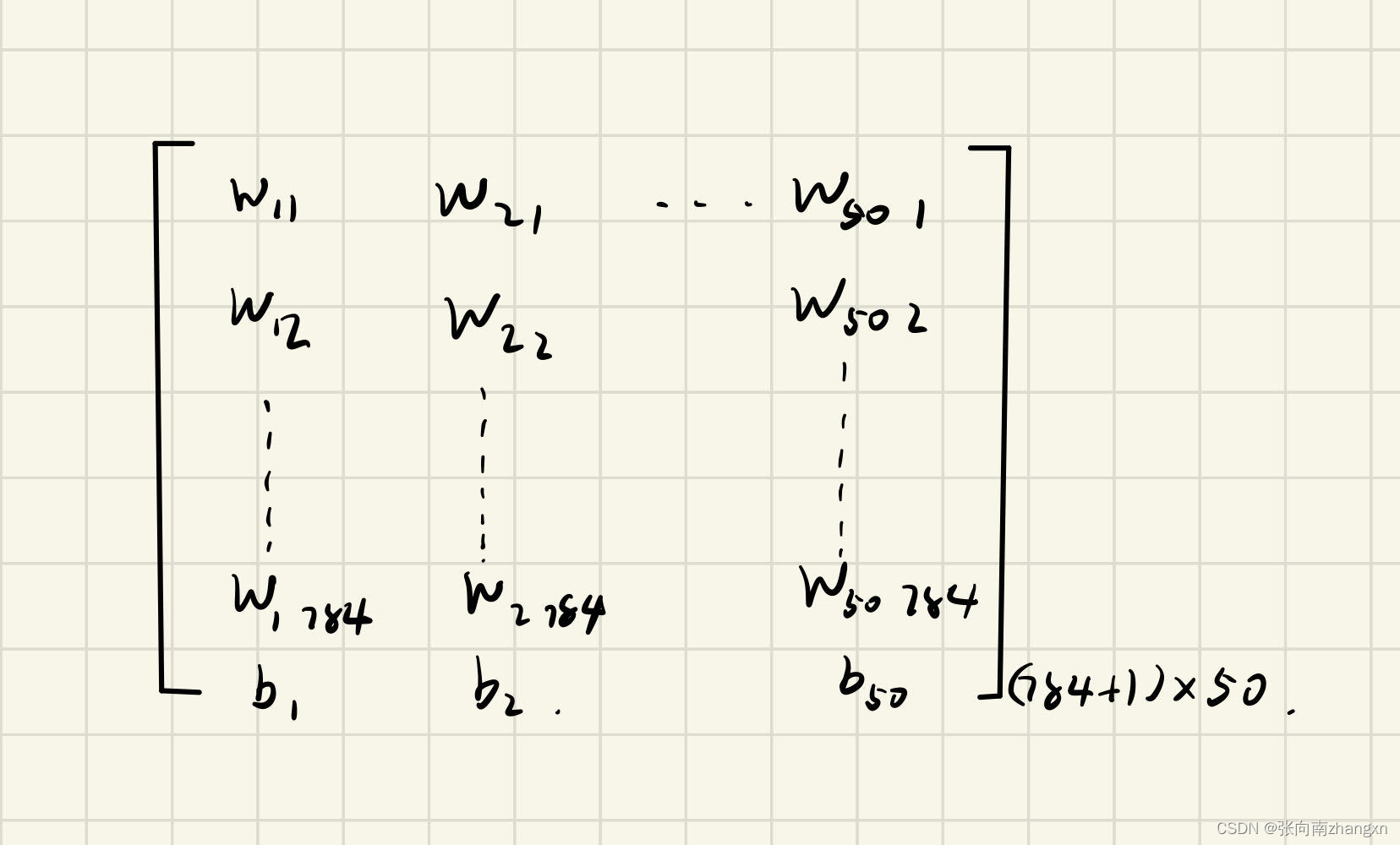
两个矩阵做矩阵乘法并经sigmoid激活,得到n*50的矩阵,这是隐藏层的输出。随后在隐藏层最右侧一列追加全一列向量作为下一层偏置的系数,得到n*(50+1)的矩阵,作为输出层的输入。
第2层和第3层间的权值矩阵:
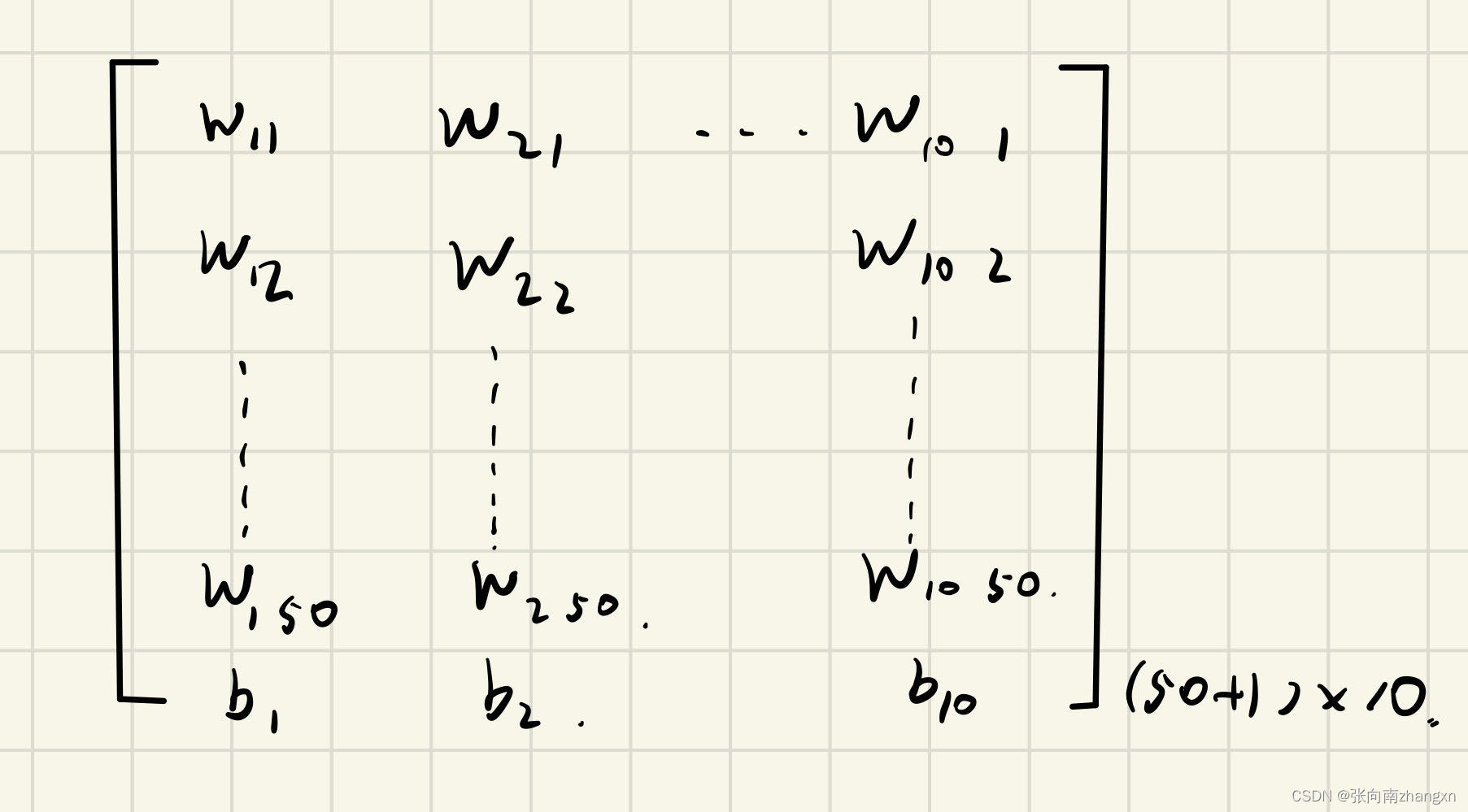
再做矩阵乘法,并经softmax沿1轴方向激活,得到n*10的矩阵。再对每个数以0.5为阈值转换成0和1,就可以得到预测出的One-hot编码,进行解码后即得到最终结果。
程序有train和test两个模式。在train模式中,每迭代100次,对权值矩阵进行一次存档。程序每次运行时都检查是否存在已经存档的权值矩阵和标签经one-hot编码后的矩阵,从而实现对每一次训练结果的保存。测试时为了速度只加载了前40个样本,这是可调的。在test模式中设置了一个加载图片的接口,配合windows自带的画图软件等,可以实现对自己手写的数字的识别。代码如下:
- import tensorflow as tf
- import numpy as np
- from scipy.io import savemat,loadmat
- import matplotlib.pyplot as plt
- import PIL.Image as img
-
- mnist=tf.keras.datasets.mnist
-
- print("data is loading...")
- (train_x,train_y),(test_x,test_y)=mnist.load_data()
-
- print("data loading finished.")
- r=tf.constant([[0,0,0,0,0,0,0,0,0,1],
- [1,0,0,0,0,0,0,0,0,0],
- [0,1,0,0,0,0,0,0,0,0],
- [0,0,1,0,0,0,0,0,0,0],
- [0,0,0,1,0,0,0,0,0,0],
- [0,0,0,0,1,0,0,0,0,0],
- [0,0,0,0,0,1,0,0,0,0],
- [0,0,0,0,0,0,1,0,0,0],
- [0,0,0,0,0,0,0,1,0,0],
- [0,0,0,0,0,0,0,0,1,0]])
-
- #编码和解码函数
- def one_hot(t_y):
- print("encoding...")
- for i in range(len(t_y)):
- if i==0:
- num=t_y[i]
- y=r[num,:]
- elif i==1:
- y=tf.stack([y,r[t_y[i],:]],axis=0)
- else:
- y=tf.concat([y,tf.reshape(r[t_y[i],:],[1,-1])],axis=0)
- print("encoding finished.")
- return y
-
- def decod(res):
- final=[]
- num=res.shape[0]
- for i in range(num):
- if all(res[i]==[0,0,0,0,0,0,0,0,0,1]):
- final.append(0)
- elif all(res[i]==[1,0,0,0,0,0,0,0,0,0]):
- final.append(1)
- elif all(res[i]==[0,1,0,0,0,0,0,0,0,0]):
- final.append(2)
- elif all(res[i]==[0,0,1,0,0,0,0,0,0,0]):
- final.append(3)
- elif all(res[i]==[0,0,0,1,0,0,0,0,0,0]):
- final.append(4)
- elif all(res[i]==[0,0,0,0,1,0,0,0,0,0]):
- final.append(5)
- elif all(res[i]==[0,0,0,0,0,1,0,0,0,0]):
- final.append(6)
- elif all(res[i]==[0,0,0,0,0,0,1,0,0,0]):
- final.append(7)
- elif all(res[i]==[0,0,0,0,0,0,0,1,0,0]):
- final.append(8)
- elif all(res[i]==[0,0,0,0,0,0,0,0,1,0]):
- final.append(9)
- else:
- final.append(-1) #太抽象以至于识别不出来的被标记为-1
- print("decoding finished.")
- return final
-
- try:
- open("C:\prog\matrix\y.mat")
- sv=loadmat("C:\prog\matrix\y.mat")
- y=tf.constant(sv["data"],dtype=tf.float32)
- except FileNotFoundError:
- y=one_hot(train_y)
- save_dict2={"name":"y","data":y}
- savemat("C:\prog\matrix\y.mat",save_dict2)
-
- first=len(train_y)
-
- x=tf.reshape(train_x,[first,-1])
- x=tf.cast(x,dtype=tf.float32)
- x=tf.concat([x,tf.ones([first,1],dtype=tf.float32)],axis=1)
- x=x-tf.reduce_mean(x)
- y=tf.cast(y,dtype=tf.float32)
-
- try:
- open("C:\prog\matrix\w12.mat")
- mid12=loadmat("C:\prog\matrix\w12.mat")
- w12=tf.constant(mid12["data"],dtype=tf.float32)
- print("w12 is loaded")
- except FileNotFoundError:
- w12=tf.random.uniform([28*28+1,50],dtype=tf.float32)
- print("w12 initialization finished")
-
- try:
- open("C:\prog\matrix\w23.mat")
- mid23=loadmat("C:\prog\matrix\w23.mat")
- w23=tf.constant(mid23["data"],dtype=tf.float32)
- print("w23 is loaded")
- except FileNotFoundError:
- w23=tf.random.uniform([50+1,10],dtype=tf.float32)
- print("w23 initialization finished")
-
- print("Train or test?")
- a=input()
- if a=="train":
- w12=tf.Variable(w12)
- w23=tf.Variable(w23)
-
- n=int(input("迭代次数:"))
- a=float(input("学习速率:"))
-
- ce=[]
-
- percentage=0
- counter=0
-
- print("processing...")
- for i in range(n):
- with tf.GradientTape(persistent=True) as tape:
- x2=tf.nn.sigmoid(tf.matmul(x,w12))
- x2=tf.concat([x2,tf.ones([first,1],dtype=tf.float32)],axis=1)
- logits=tf.matmul(x2,w23)
- Loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y,logits))
- ce.append(Loss)
-
- grad23=tape.gradient(Loss,w23)
- grad12=tape.gradient(Loss,w12) #这里偷了个懒,没有按权值分配Loss,但应该也可以达到目的
- w23.assign_sub(a*grad23)
- w12.assign_sub(a*grad12)
- del tape
- counter=counter+1
- if counter%100==0:
- dict_save_w12={"name":"w12","data":w12}
- savemat("C:\prog\matrix\w12.mat",dict_save_w12)
- dict_save_w23={"name":"w23","data":w23}
- savemat("C:\prog\matrix\w23.mat",dict_save_w23)
- if (counter/n*100)%5==0:
- percentage+=5
- print("proceeding:%%%d" %(percentage))
- print(Loss)
-
- #测试
- print("Training finished, testing started")
- tfirst=len(test_y[0:40])
- t_x=tf.reshape(test_x[0:40],[tfirst,-1])
- t_x=tf.cast(t_x,dtype=tf.float32)
- t_x=tf.concat([t_x,tf.ones([tfirst,1],dtype=tf.float32)],axis=1)
- t_x=t_x-tf.reduce_mean(t_x)
-
- tlog=tf.nn.sigmoid(tf.matmul(t_x,w12))
- tlog=tf.concat([tlog,tf.ones([tfirst,1],dtype=tf.float32)],axis=1)
- res=tf.nn.softmax(tf.matmul(tlog,w23),axis=1)
- print("decoding...")
- res=tf.where(res<0.5,0,1)
-
- final=np.array(decod(res))
-
- cor=final-test_y[0:40]
- coun=0
- for i in range(len(test_y[0:40])):
- if cor[i]==0:
- coun+=1
- rate=coun/len(test_y[0:40])
- print("Accuracy:%%%f" %(100*rate))
- print("Loss:%f" %Loss)
-
- print("Graph is loaded...")
-
- plt.rcParams["font.sans-serif"]="Microsoft Yahei"
-
- plt.figure()
-
- plt.subplot(1,2,1)
- plt.plot(ce)
- plt.title("平均交叉熵损失")
- plt.xlabel("迭代次数")
- plt.ylabel("Loss")
-
- plt.subplot(1,2,2)
- plt.plot(final,color="blue",label="识别结果")
- plt.plot(test_y,color="red",label="正确结果")
- plt.xlabel("测试样例序号")
- plt.xlim(0,30)
- plt.ylabel("数字")
- plt.title("测试结果")
-
- plt.suptitle("手写数字识别系统")
-
- plt.legend()
- plt.show()
-
- else:
- image=img.open("C:\prog\graph\g.png").convert("L")
- im=tf.constant(image,dtype=tf.float32)
- im=tf.reshape(im,[1,-1])
- im=tf.concat([im,tf.ones([1,1],dtype=tf.float32)],axis=1)
- lg=tf.nn.sigmoid(tf.matmul(im,w12))
- lg=tf.concat([lg,tf.ones([len(lg),1],dtype=tf.float32)],axis=1)
- res=tf.nn.softmax(tf.matmul(lg,w23))
- res=tf.where(res<0.5,0,1)
- finalres=decod(res)
- print(finalres)

经过了两天的花式调参,终于能够把Loss控制在0.23左右,训练好的权值矩阵放到了本文资源中。这个过程让我颇为感慨。多层神经网络的Loss不一定是凸函数,所以按梯度下降法进行权值修正的时候,Loss经常陷入局部极小值。在没有使用优化器的前提下,必须大胆把学习速率调大而不减小,试图让Loss从局部极小值里冲出来,当然成功与否取决于运气。这样反复了很多次,才最终把Loss下降到可观的范围。现在这个模型在测试集中的准确率可以达到92.5%。
ps:这个小项目是在不了解tensorflow自带的one-hot等函数的情况下写的,所以代码显得迂回冗长了很多,相较于用自带函数,做了一些更底层的实现。至于为什么没用小批量梯度下降,是因为一开始想先做批量梯度下降试试算法是否可行,后面懒得改了。此外,也没有用优化器,没有用sequential模型……要啥没啥。要啥没啥,但是能用。

