
热门标签
热门文章
- 1Android 连接USB设备(主机模式)_android.hardware.usb.action.usb_device_attached
- 2我的创作纪念日——创作历程,机缘,与成就_csdn机缘
- 3[组图]Ubuntu 8.10使用CrossOver Linux Pro运行Windows程序_linux中利用crossover运行软件产生的文件保存在哪 site:blog.csdn.net
- 4GB28181 —— 5、C++编写GB28181设备端,完成将USB摄像头视频实时转发至GB28181服务并可播放(附源码)_usb摄像头转gb28181
- 5关于android stuido 与 Eclipse 的android项目结构对比_deveco与android studio项目文件对比
- 6Python数据系列(三)- 元组Tuple:Python的“不可变序列”_python tuple 不可变
- 7gradle-generator自动生成代码的两种方式_gradle 集成 generator
- 8SVR的简单实例应用_svr模型实例
- 9PyTorch CUDA error: an illegal memory access was encountered_torch cuda synchronize illegal memory access
- 10ztree构造树状结构表格_ztree 树状表格
当前位置: article > 正文
jieba分词_jieba.cut()方法返回的类型
作者:菜鸟追梦旅行 | 2024-04-01 10:25:12
赞
踩
jieba.cut()方法返回的类型
1. jieba.cut():返回的是一个迭代器。参数cut_all是bool类型,默认为False,即精确模式,当为True时,则为全模式
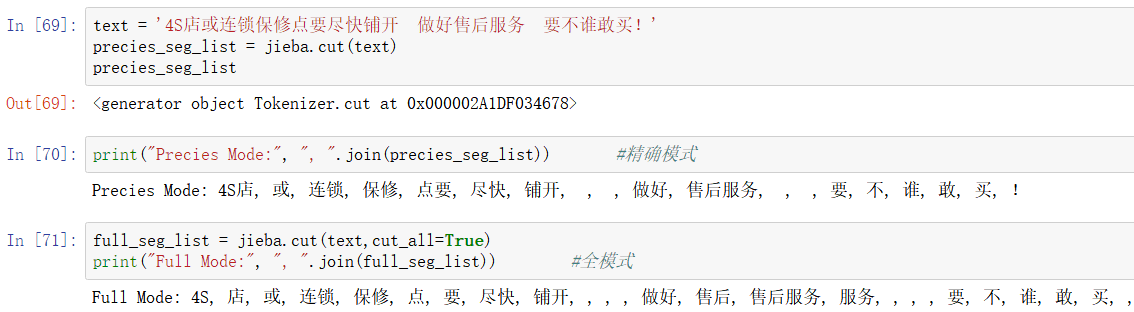
2. jieba.lcut(): 返回的是列表。
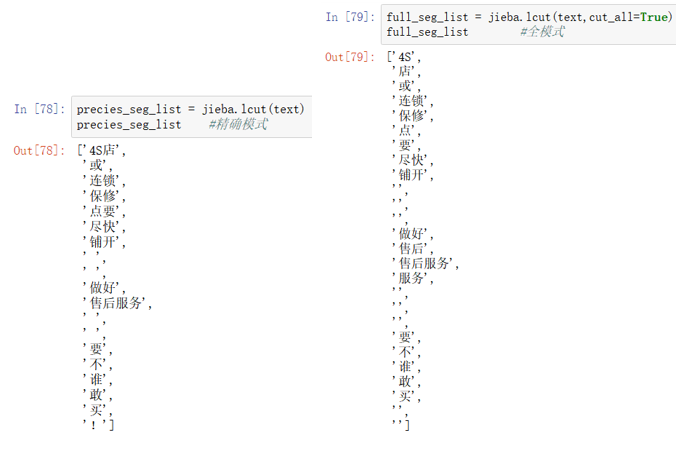
3. jieba.cut_for_search()是搜索引擎模式

4. 添加自定义词典
使用默认字典时,一些新的词汇无法正确分词
- #添加自定义词典
- text1 = '无妻徒刑,厉害炸了,卷积神经网络'
- seg_list1 = jieba.cut(text1, cut_all=False)
- print("/ ".join(seg_list1))
- 无妻/ 徒刑/ ,/ 厉害/ 炸/ 了/ ,/ 卷积/ 神经网络
将这三个新词加入字典后
- jieba.load_userdict('myDict.txt') # file_name为自定义词典的路径
- seg_list1 = jieba.cut(text1, cut_all=False)
- print("/ ".join(seg_list1))
- 无妻徒刑/ ,/ 厉害炸了/ ,/ 卷积神经网络
5. jieba.tokenize(): 返回词在原文的位置,下例中的result是一个迭代器。
- result = jieba.tokenize(u'永和服装饰品有限公司')
- for tk in result:
- print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
-
- word 永和 start: 0 end:2
- word 服装 start: 2 end:4
- word 饰品 start: 4 end:6
- word 有限公司 start: 6 end:10
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/348426?site
推荐阅读
相关标签

