
热门标签
热门文章
- 1【生产力】Mac 窗口布局工具 Magnet
- 2Python flask request
- 3关于DATA段,BSS以及堆和栈_data bss 什么意思
- 4Windows如何登录linux?_windows怎么进入linux环境
- 5文件的安全上下文 ---- SEAndroid in Android 5.x_u:object_r:root_file:s0
- 6【Android】客户端连接阿里云服务器MySQL数据库实现登录功能(代码配置流程详解)_java安卓程序读取阿里云平台数据
- 7Android与鸿蒙系统安全(一)_android pki
- 83天没合眼,爆肝整理-性能测试常见问题(汇总)一篇全覆盖..._软件测试性能测试压测常见问题
- 9第七章:多模态大模型实战7.3 视频理解与处理7.3.3 实战案例与挑战
- 10getParentalNodePaths、osg::NodePathList、osg::NodePath详解_osg nodepath
当前位置: article > 正文
python——第三方库之 “jieba” 库_python jieba库作用
作者:从前慢现在也慢 | 2024-03-31 08:56:20
赞
踩
python jieba库作用
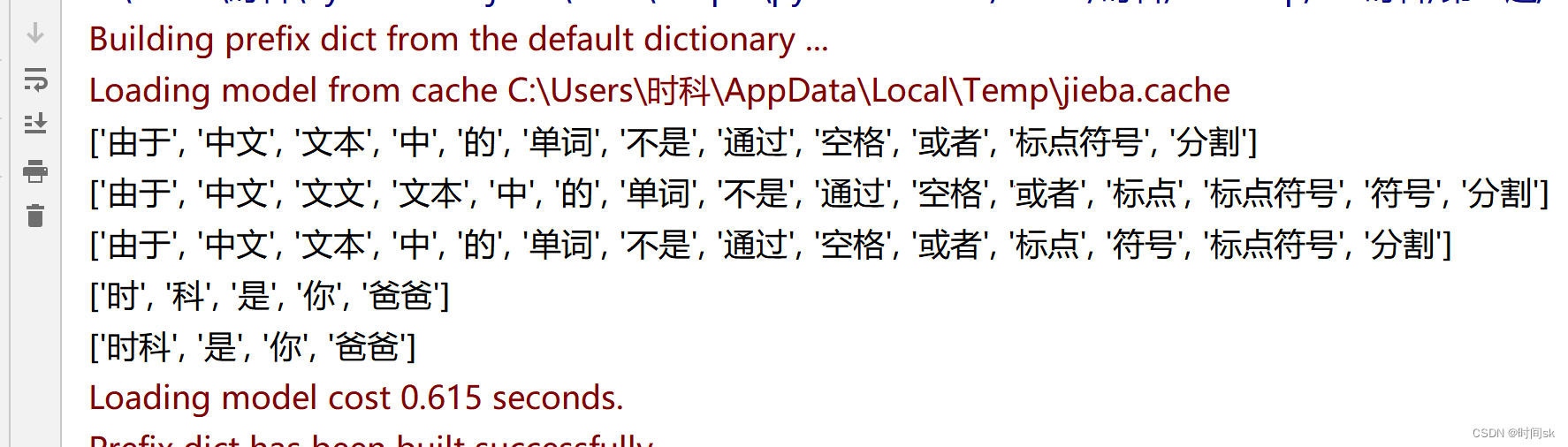
jieba库: 由于中文文本中的单词不是通过空格或者标点符号分割, 中文及类似语言存在一个重要的“分词”问题(类似于我们初中学的文言文时分词断意) 分词原理: 利用一个中文词库,将待分的内容与分词词库进行比对, 通过"图结构和动态规划方法"找到最大概率的词组。 除了分词,jieba还提供"增加自定义中文单词的功能" 三种分词模式 1.精确模式(最常用):将句子最精确地切开,适合文本分析; 2.全模式 :把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义 3.搜索引擎模式:在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词 精确模式: jieba.lcut(s)是最常用的中文分词函数,用于精确模式,即将字符串分割成等量的中文词组,返回结果是列表类型 import jieba print(jieba.lcut("由于中文文本中的单词不是通过空格或者标点符号分割")) 根据该词在生活中出现的"概率"分割的。 分割结果:['由于', '中文', '文本', '中', '的', '单词', '不是', '通过', '空格', '或者', '标点符号', '分割'] 用于全模式: jieba.lcut(s,cut_all=True) "用于全模式",即将字符串的"所有分词可能均列出来","返回结果是列表类型","冗余性最大" print(jieba.lcut("由于中文文本中的单词不是通过空格或者标点符号分割",cut_all=True )) 逐词递增组合分组 (但凡可以组词的全组在一起), 结果是:['由于', '中文', '文文', '文本', '中', '的', '单词', '不是', '通过', '空格', '或者', '标点', '标点符号', '符号', '分割'] 返回搜索引擎模式: jieba.lcut_for_search(s) 返回搜索引擎模式,该模式首先"执行精确模式",然后再对其中"长词"进一步切分获得最终结果 print(jieba.lcut_for_search("由于中文文本中的单词不是通过空格或者标点符号分割")) 结果是:['由于', '中文', '文本', '中', '的', '单词', '不是', '通过', '空格', '或者', '标点', '符号', '标点符号', '分割'] jieba还提供"增加自定义中文单词的功能" 顾名思义用来向jieba词库增加新的单词(帮助算法无法划分的词,手动划分) print(jieba.lcut("时科是你爸爸",cut_all=True) ) "时科"是一个词,但它无法判别。 结果是:['时', '科', '是', '你', '爸爸'], jieba.add_word("时科") 添加手动分词 print(jieba.lcut("时科是你爸爸",cut_all=True) ) 结果是:['时科', '是', '你', '爸爸'] 帮助手动划分之后。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/344038
推荐阅读
相关标签

