
- 1AI聊天伴侣的语料采集大揭秘:OpenCV如何轻松识别聊天图片?_图像识别聊天框
- 2开源项目——ROSECHO 中文ROS语音交互模块(一)_ros语音控制命令前往指定地点
- 3体感游戏开发:体感游戏常用技术
- 4Edge-TTS 语音朗读
- 5国考【行测】类比推理真题分析——2023.12.27更新_显示屏计算机手机类比
- 6【华为机试】2024年真题C卷(c++)-机器人搬砖_华为od 机器人搬砖,一共有n堆砖存放在n个不同的仓库中,第i堆砖中有bricks[i]块砖
- 7【EduCoder答案】git相关实训答案_#请在下面的begin/end内填写语句以将远程版本库clone到本地 #********** be
- 8【前沿技术杂谈:NLP技术的发展与应用】探索自然语言处理的未来
- 9正样本和无标签学习(PU Learning):使用机器学习恢复数据的标签
- 10VRRP实验(eNSP)_ensp vrrp
在Atlas 200 DK(Soc=Ascend 310)快速上手自定义模型训练、部署与推理_aclliteresource
赞
踩
前言
鉴于目前Atlas200DK自带的说明书内容非常繁多复杂(《Atlas 200 DK V100R020C10 应用开发指南(Python)》;《Atlas 200 DK V100R020C10 IR 模型构建指南》;《TBE 自定义算子开发指导_C75 TBE 自定义算子开发指导_C75》;《Atlas 200 DK V100R020C10 开发辅助工具使用指南》;《CANN 5.0.4 应用软件开发指南 (Python, 推理)》....,最搞笑的是前面几本参考资料目前华为云还删掉找不到了,还好我提前下载了pdf),这篇文章给大家分享一下,如何在Atlas200DK上快速上手训练自己的模型并通过ACT工具和ACL实现NPU调用并推理。
1.模型的训练
在Atlas200DK上训练模型主要是3个方法:1.TBE DSL训练;2.TIK训练;3.通过tensorflow与caffe训练。那么简单的来说关于前2种方法,这个TBE DSL相较于TIK要容易上手一点,因为TIK需要手动控制数据搬运的参数和Schedule。而TBE DSL的编码风格和Tensorflow1*很像,如果对于Tensorflow比较熟悉的很容易上手,比如它在定义数据输入的示例代码如下所示:
- //初始化输入tensor,为输入tensor进行占位
- data_x = tvm.placeholder(shape_x, name="data_1", dtype=input_data_type)
- data_y = tvm.placeholder(shape_y, name="data_2", dtype=input_data_type)
- //调用计算接口实现data_x + data_y
- res = te.lang.cce.vadd(data_x, data_y)
- //调用auto_schedule接口实现自动调度
- with tvm.target.cce():
- schedule = topi.generic.auto_schedule(res)
- //配置编译参数并进行编译
- config = {"print_ir": False,
- "name": kernel_name,
- "tensor_list": (data_x, data_y, res)}
- te.lang.cce.cce_build_code(schedule, config)
- x = tvm.placeholder((512, 1024), "float")
- exp_x = te.lang.cce.vexp(x)
- reduce_exp_x = te.lang.cce.sum(exp_x, axis = 0)
- res = te.lang.cce.vrec(reduce_exp_x)
- with tvm.target.cce():
- sch = topi.generic.auto_schedule(res)

而TIK在定义数据时与TBE不同,除了定义输入数据的大小,形状,类型以外还需要定义如何将外部存储中的数据搬入、搬出AI Core内部存储中等操作,示例代码如下所示:
- data_A = tik_intance.Tensor("float16",(128,), name="data_A", scope=tik.scope_gm)
- data_B = tik_intance.Tensor("float16", (128,), name="data_B", scope=tik.scope_gm)
- data_C = tik_intance.Tensor("float16", (128,), name="data_C", scope=tik.scope_gm)
- data_A_ub = tik_intance.Tensor("float16", (128,), name="data_A_ub", scope=tik.scope_ubuf)
- data_B_ub = tik_intance.Tensor("float16", (128,), name="data_B_ub", scope=tik.scope_ubuf)
- data_C_ub = tik_intance.Tensor("float16", (128,), name="data_C_ub", scope=tik.scope_ubuf)
-
- tik_instance.data_move(data_A_ub, data_A, 0, 1, 128 //16, 0, 0)
- tik_instance.data_move(data_B_ub, data_B, 0, 1, 128 //16, 0, 0)
-
- repeat = tik_instance.Scalar('int32')
- repeat.set_as(1)
- tik_instance.vec_abs(128, data_C_ub[0], data_A_ub[0], data_B_ub[0], repeat, 8, 8, 8)
-
- tik_instance.data_move(data_C, data_C_ub, 0, 1, 128 //16, 0, 0)
- tik_instance.BuildCCE(kernel_name="simple_add",inputs=[data_A,data_B],outputs=[data_C])
-
关于以上2种自定义算子来训练模型的许多具体方法可见《TBE 自定义算子开发指导_C75》。由于作者本人对于这本资料目前也是云里雾里,暂时没法吃透给大家通俗的讲解,只能说暂时写一点简单的代码让大家理解其大概的工作原理。其中如果你想通过tensorflow1*的逻辑直接用TBE上训练模型也还是会有很多陌生的报错,然后越查越深很难做到快速上手。
因此在我本人学习了相关知识后认为,要想在短时间利用这两种方法按照自己的意愿在Atlas200DK训练模型做项目或者实验的话比较困难,并且Atlas 200DK本身的定位就是端设备,不具备高效训练模型的能力,只能胜任推理相关的工作。于是本文推荐第三种方法:通过tensorflow训练模型然后用ACT转化为Atlas200DK能够解析的.om文件,最后通过ACL调用.om文件进行模型的适配与推理工作。
1.1 tensorflow2*生成的模型并编译成.om文件
至于为什么用tensorflow2*,主要原因是tensorflow2*是趋势并且对比1*而言更容易上手,比如去掉了tf.placeholder,tf.Variable,feed={}等等,直接用tf.keras.Input(),keras.model()一步到位。
因此在这个章节中,我们首先通过Tensorflow2*首先训练一个CNN模型并保存为.H5格式(tf2.model.save()默认格式),示例代码如下所示(当然不同于TBE于TIK,这里各位就可以自行发挥训练出各种复杂的模型了,我这里就简单的训练一个CNN模型作为例子):
- import tensorflow as tf
- import input_data
- from tensorflow.keras.layers import Dense, Flatten,Conv2D,MaxPooling2D,AlphaDropout
- from tensorflow.keras import Model
- from tensorflow.keras import models
- import os
- import matplotlib.pyplot as plt
- import numpy as np
- import random
- import copy
- import time
- import math
- import keras.backend as K
- from tensorflow.python.tools import freeze_graph
- from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
- import sys
-
- # 加载数据
- mnist = input_data.read_data_sets('Mnist_data', one_hot=True)
- print(mnist.train.images.shape)
- print(mnist.test.images.shape)
- mnist.train.images.resize([55000,28,28])
- mnist.test.images.resize([10000,28,28])
-
- x_train=np.array(mnist.train.images)
- x_test= np.array(mnist.test.images)
- x_test= np.array(mnist.test.images)
- y_train=np.argmax(mnist.train.labels,1)
- y_test= np.argmax(mnist.test.labels,1)
- x_train = np.expand_dims(x_train, axis=3)
- x_test = np.expand_dims(x_test, axis=3)
-
- class testmodel(Model):
- def __init__(self):
- super(testmodel,self).__init__()
- self.conv1=Conv2D(filters=32,kernel_size=3,activation='relu')
- self.flatten=Flatten()
- self.d1 = Dense(units=128,activation='relu')
- self.d2 = Dense(units=10, activation='softmax')
- def call(self,x):
- x=self.conv1(x)
- x=self.flatten(x)
- x=self.d1(x)
- return self.d2(x)
- M=testmodel()
- M.build(input_shape=(1,28,28,1))
- M.compile(optimizer=tf.keras.optimizers.Adam(
- learning_rate=0.001, beta_1=0.9, beta_2=0.999 # 自定义动量,adam和学习率,也是为了提高准确率
- ),
- loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
- metrics=["sparse_categorical_accuracy"]
- )
- ########保存模型参数的路劲设置################
- # checkpoint_save = "./checkpoinCNNBase/Baseline.ckpt"
- # if os.path.exists(checkpoint_save + ".index"):
- # print("---------------load the model----------------------")
- # M.load_weights(checkpoint_save)
- # cp_callback = tf.keras.callbacks.ModelCheckpoint(
- # filepath=checkpoint_save,
- # save_weights_only=True,
- # save_best_only=True
- # )
- ########模型训练##################
- history = M.fit(
-
- x_train, y_train, batch_size=512, epochs=5, validation_data=(x_test, y_test),
-
- validation_freq=1
- )
- M.summary()
- M.save('test.h5')
- h5_to_pb('test.h5')
在训练完一个模型之后,这里会有一个问题:“Atlas200DK的ACT转化命令不认H5格式的模型,只认.pb格式的模型。”因此下一步需要将.h5格式的模型转化为.pb,此时需要用到这样一个函数(在其他博主那里找到的):
- def h5_to_pb(h5_save_path):
- model = tf.keras.models.load_model(h5_save_path, compile=False)
- model.summary()
- full_model = tf.function(lambda Input: model(Input))
- print(model.inputs[0].shape, model.inputs[0].dtype)
- full_model = full_model.get_concrete_function(tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype))
-
- # Get frozen ConcreteFunction
- frozen_func = convert_variables_to_constants_v2(full_model)
- frozen_func.graph.as_graph_def()
-
- layers = [op.name for op in frozen_func.graph.get_operations()]
- print("-" * 50)
- print("Frozen model layers: ")
- for layer in layers:
- print(layer)
-
- print("-" * 50)
- print("Frozen model inputs: ")
- print(frozen_func.inputs)
- print("Frozen model outputs: ")
- print(frozen_func.outputs)
-
- # Save frozen graph from frozen ConcreteFunction to hard drive
- tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
- logdir="./frozen_models",
- name="frozen_model.pb",
- as_text=False)
- ######################
此时就会将生成的.H5的模型转成.pb文件,然后将生成的.pb文件上传到Atlas200DK中,通过如下atc命令将.pb文件转化为.om文件。

这里有个大坑,就是官方文件的示例在这里写的非常的模糊: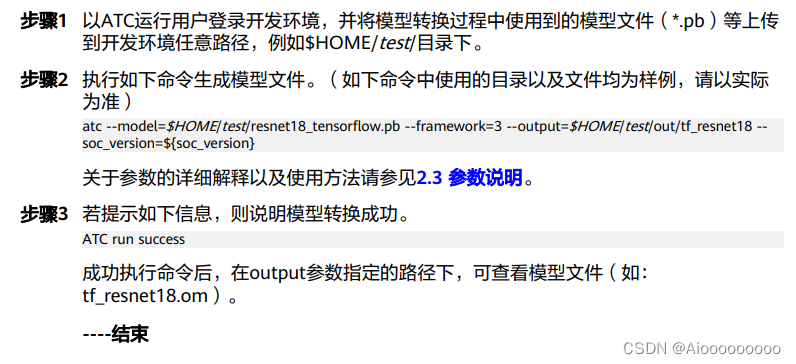
如果你直接按照它这个格式90%atc过不了,而报的错误报了等于没报,因为网上搜不到什么相关的资料,根本无从下手。我绕了一大圈,才发现其中致命的问题:就是需要规定输入的形状,也就是在命令后面要加上 --input_shape='name:X,X,X,X',如果有几个输入就是--input_shape='name1:X,X,X,X;name2:X,X,X,X'。而这个name可以从之前h5_to_pb中的输出可以找到:
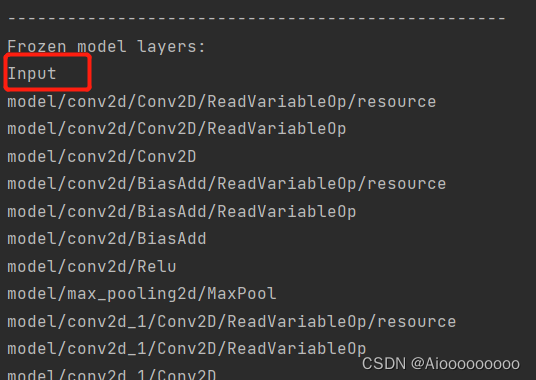
至于为什么会这么恶心,也可能是自己读手册不仔细吧。但是你瞅瞅这手册(《Atlas 200 DK 开发辅助工具使用指南》)是人读的吗?又臭又长还难找。通篇474页,逻辑混乱、超链接贼多(有不少链接华为云还给删了),这里不懂点一下,搜的一下给我转到100多页后,然后不懂的地方一点又给我传到40页前的地方,最后搞来搞去,我都TM找不到我一开始的问题是什么了,读的特别的累,就算想通过这个手册检索自己的问题也特别的困难,真的希望有v2版本更新的话,能够把逻辑这块好好的优化一下。
不管怎么样,至此就算训练模型完成了。
1.2 -通过ACL调用om模型进行推理
这地方是第二个巨坑:官方给的sample与网络分享的示例全是傻瓜式下载模型、图片+命令运行,或者是Mindspore流水线式开发(根本就没有涉及到ACL相关的代码),比如ACL是如何读取数据的,ACL是如何转换图片的,ACL是如何通过代码调用.om文件的,ACL是如何用.om文件推理的,输入输出的格式又是怎么样的等等等。
因此《CANN 5.0.4 应用软件开发指南 (Python, 推理)》这本书变得非常重要了(有趣的是这本书是2022.5月才有的第1版,也就是说在今年5月之前你要想快速上手简直是两眼一抹黑)。当然这本书和之前的那几本味道一样冲,不过这本书有很多acl函数与源码解释,很方便查阅。同时幸运的是Atlas200DK官方提供下载(http://git clone https://gitee.com/ascend/samples.git)的sample例子里面,也有像classfy.py文件可以方便借鉴。
有意思的是在官方自带sample中ACL源码(classfy.py)里调用的函数和手册里面介绍的函数都不太一样,比如om模型的加载,在手册中是:
- model_path = "./model/resnet50.om"
- model_id, ret = acl.modload_from_file(model_path)
而在classfy.py中是这样的:
- from constants import ACL_MEM_MALLOC_HUGE_FIRST, ACL_MEMCPY_DEVICE_TO_DEVICE, IMG_EXT
- from acllite_imageproc import AclLiteImageProc
- from acllite_model import AclLiteModel
- from acllite_image import AclLiteImage
- from acllite_resource import AclLiteResource
- from image_net_classes import get_image_net_class
-
- if __name__ == '__main__':
- acl_resource = AclLiteResource()
- acl_resource.init()
- #_model_path = model_path
- _model_width = MODEL_WIDTH
- _model_height = MODEL_HEIGHT
- _dvpp = AclLiteImageProc(acl_resource)
- _model = AclLiteModel("googlenet_yuv.om")
图片的转化、读取、模型推理,手册是这样的:
- ACL_MEMCPY_HOST_TO_DEVICE = 1
- ACL_MEMCPY_DEVICE_TO_HOST = 2
- NPY_BYTE = 1
- images_list = ["./data/dog1_1024_683.jpg", "./data/dog2_1024_683.jpg"]
- for image in images_list:
- # 1.自定义函数transfer_pic,使用Python库读取图片文件,并对图片进行缩放、剪裁等操作,
- # transfer_pic函数的实现请参考样例中源代码
- img = transfer_pic(image)
-
- # 2.准备模型推理的输入数据,运行模式默认为运行模式为ACL_HOST,当前实例代码中模型只有一个输入
- np_ptr = acl.util.numpy_to_ptr(img)
- # 将图片数据从Host传输到Device
- ret = acl.rt.memcpy(self.input_data[0]["buffer"],self.input_data[0]["size"], np_ptr,
- self.input_data[0]["size"], ACL_MEMCPY_HOST_TO_DEVICE)
- # 3.执行模型推理
- # self.model_id表示模型ID,在模型加载成功后,会返回标识模型的ID
- ret = acl.mdl.execute(self.model_id, self.load_input_dataset, self.load_output_dataset)
而在classfy.py中是这样的:
- for image_file in x_test:
- #read the picture
- image = AclLiteImage(image_file)
- image_dvpp = image.copy_to_dvpp()
- #preprocess image
- #resized_image = classify.pre_process(image_dvpp)
- #print("pre process end")
- #inference
- result=_model.execute([image_dvpp, ])
- #post process
- print(result)
我个人认为,这2种写法都是对的,而第二种应该是将一些acl细的写法包装成函数进行调用了。因此作者这边就模仿了classify.py的想法进行推理。
由于我最近广州疫情暂时接触不到实验室的atlas200DK设备,后续运行结果和我会的一点点的acl相关知识(内存分配这个地方真的和C好像啊)之后有机会回去了再更新。
待续........

