
热门标签
热门文章
- 1Ubuntu18.04 Realsense D435i驱动安装与配置_源码安装udevadm
- 2字节跳动岗位薪酬体系曝光,看完才知道:自己差这么多..._字节3-1月薪
- 3SpringBoot使用poi将word转换为PDF并且展示
- 42023年云计算的发展趋势如何?还值得学习就业吗?_2023云计算,大数据,人工智能学那个
- 5C语言之指针基础_c语言中ardd0的意思
- 6整理jdk几个版本的新特性_jdk版本
- 7【VScode】安装配置、插件及远程SSH连接_vscode ssh
- 8PyTorch快速入门教程【小土堆】-神经网络-完整的模型训练套路_with torch.no_grad():小土堆
- 9如何用 Python 发送通知到微信?
- 10Stable Diffusion完整入门指南,保姆级教程!干货满满,建议收藏!
当前位置: article > 正文
机器学习——随机森林特征选择及周期性分析_随机森林特征提取
作者:花生_TL007 | 2024-02-16 05:39:28
赞
踩
随机森林特征提取
一、随机森林
随机森林由LeoBreiman提出,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。
其实质是对决策树算法的一种改进,对于决策树算法只是一棵树,而随机森林因为”森林“我们一可以看出如其名,是将多棵决策树合并一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。
二、随机森林在回归问题和分类问题上的应用
在随机森林中,我们将生成很多的决策树,并不像在 CART模型里一样只生成唯一的树。当在对一个新的对象 进行分类判别时,随机森林中的每一棵树都会给出自己的 分类选择,并由此进行“投票”,森林整体的输出结果将 会是票数最多的分类选项;而在回归问题中,随机森林的 输出将会是所有决策树输出的平均。
三、特征提取(降维)
前面的文章有写过PCA降维,虽然随机森林和它都是横向的降维,但是呢PCA降维之后是生成了新的特征(新的特征是原来特征的线性组合,但是呢这个新的特征没有赋给现实的含义);而随机森林是从中挑选出更有价值的特征。
(一)首先再进行随机森林的时候,我们可以考虑一下用几棵树参数选择问题:
利用交叉折:
(1) ShuffleSplit:多次划分(训练集和测试集)
(2)GridSearchCV:网格搜索
- from sklearn.model_selection import ShuffleSplit
- from sklearn.model_selection import GridSearchCV
- from sklearn.ensemble import RandomForestClassifier
- rf_param={'n_estimators':range(1,11)}
- cv=ShuffleSplit(n_splits=10,test_size=0.3)
- model=RandomForestClassifier()
- rf_grid=GridSearchCV(model,rf_param,cv=cv)
- rf_grid.fit(X_array,y)
- print('随机森林中包含树的最优个数:',rf_grid.best_params_)
- print('验证集的准确率', rf_grid.best_score_)
结果:

(二)创建新的模型并且显示特征的特征的重要系数
- model=rf_grid.best_estimator_
- #1.显示特征的重要性系数
- features = X.columns
- feature_importances = model.feature_importances_ #随机森林训练好的模型包含各特征的重要性这个指标
- features_df = pd.DataFrame({'Features': features, 'Importance Score': feature_importances})
- features_df.sort_values('Importance Score' , inplace=True, ascending=False)
- features_df
结果:
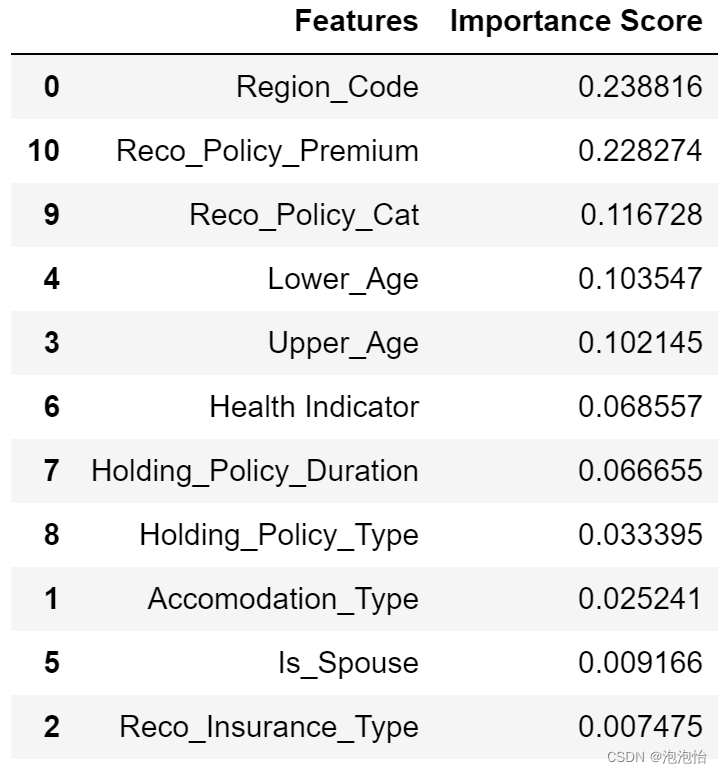
(三) 根据上边显示的特征重要性系数,确定选择前几个特征,从而完成特征选择
- feature_select_numbers=7
- importance_sum=features_df['Importance Score'][:feature_select_numbers].sum()
- print(importance_sum)
(四)生成新的X
- importance_features=list(features_df['Features'][:feature_select_numbers])
- X=X[importance_features]
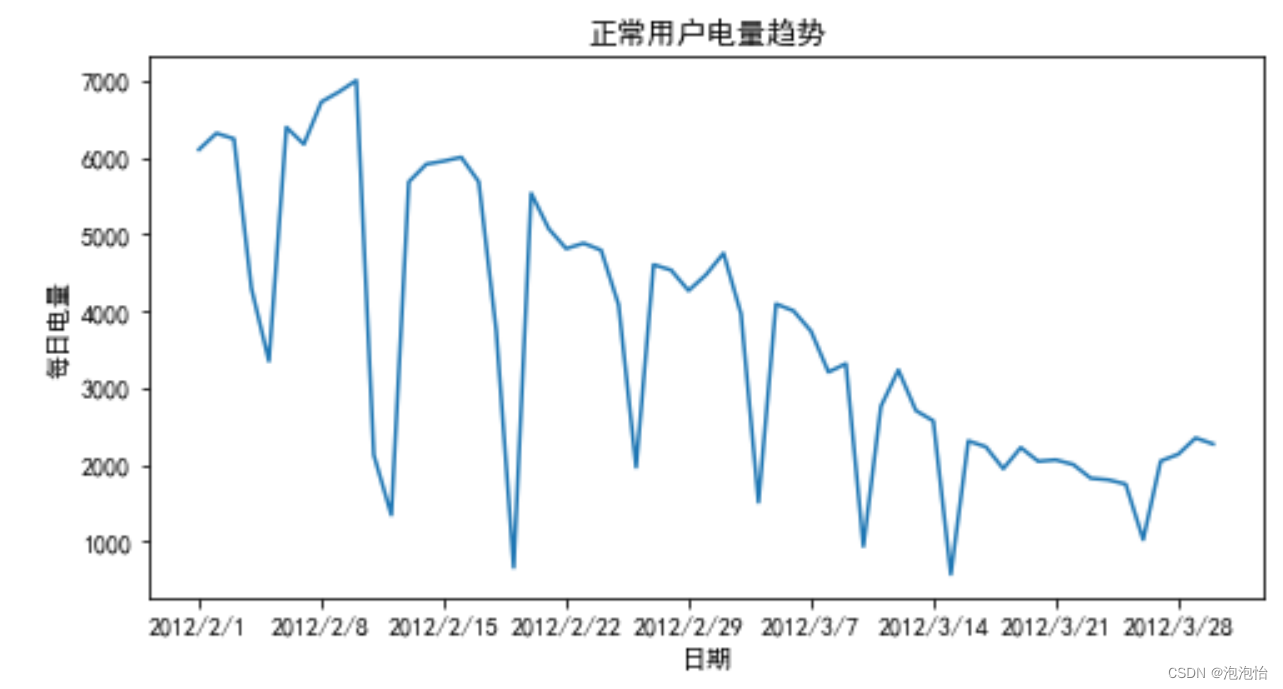
(五)周期性分析
周期性分析是探索某个变量是否随着时间变化而呈现出某种周期变化趋势。周 期性趋势相对较长的有年度周期性趋势、季节性周期趋势,相对较短的一般有 月度周期性趋势、周度周期性趋势,甚至更短的天、小时周期性趋势。
- import pandas as pd
- import matplotlib.pyplot as plt
- df_normal = pd.read_csv("./demo/data/Steal user.csv")
- plt.figure(figsize=(8,4))
- plt.plot(df_normal["Date"],df_normal["Eletricity"])
- plt.xlabel("日期")
- plt.ylabel("每日电量")
- # 设置x轴刻度间隔
- x_major_locator = plt.MultipleLocator(7)
- ax = plt.gca()
- ax.xaxis.set_major_locator(x_major_locator)
- plt.title("正常用户电量趋势")
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
- plt.show() # 展示图片
-
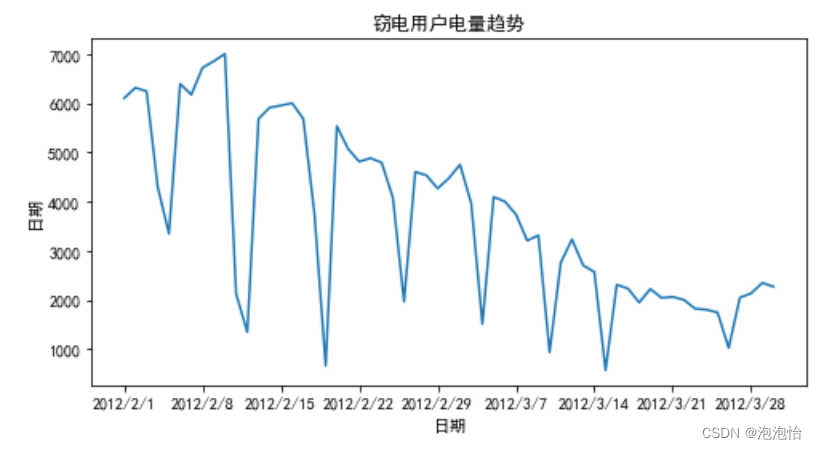
- # 窃电用户用电趋势分析
- #df_steal = pd.read_csv("../data/Steal user.csv")
- df_steal = pd.read_csv("./demo/data/Steal user.csv")
- plt.figure(figsize=(8, 4))
- plt.plot(df_steal["Date"],df_steal["Eletricity"])
- plt.xlabel("日期")
- plt.ylabel("日期")
- # 设置x轴刻度间隔
- x_major_locator = plt.MultipleLocator(7)
- ax = plt.gca()
- ax.xaxis.set_major_locator(x_major_locator)
- plt.title("窃电用户电量趋势")
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
- plt.show() # 展示图片
结果:
数据集看资源。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/91124
推荐阅读
相关标签

