
热门标签
热门文章
- 1vue项目中各文件说明_vue2 public中都有什么文件
- 2python可视化编程(pyQT designer)安装及入门教程
- 3Electron自定义协议Protocol对web网站做数据交互,使用SSE实时数据推送到网站_electron 自定义协议
- 4js、vue和小程序阻止事件冒泡_vue stoppropagation
- 5Bootstrap之模态框(提示框)_模态提示框完成
- 6构建异步高并发服务器:Netty与Spring Boot的完美结合_springboot netty 服务端
- 7HTML2023新年源代码(炫酷动态烟花)_新年快乐html
- 8【ASP.NET 6 Web Api 全栈开发实战】--前言
- 9报工提示错误:“没有内部作业价格可被确认”的解决方法_没有内部作业的价格可被确定
- 10Unity 2022 + Android 接入微信登录_unity 微信登陆
当前位置: article > 正文
Spark大数据分析实战-公司销售数据分析_基于spark的航空公司销售数据分析源代码
作者:花生_TL007 | 2024-02-13 13:59:25
赞
踩
基于spark的航空公司销售数据分析源代码
需求
假设某公司为你提供以下数据,改数据包括3个.txt文档数据,分别为日期数据、订单头数据、订单明细数据。让你根据公司所提供的的数据进行如下的需求分析。
1.计算所有订单中每年的销售单数、销售总额。
2.计算所有订单每年最大金额订单的销售额。
3.计算所有订单中每年最畅销的货品。
一、数据字段说明
1.1 日期数据
字段分别对应:日期、年月、年、月、日、周几、第几周、季度、旬、半月。

1.2 订单头数据
字段分别对应:订单号、交易位置、交易日期。
1.3 订单明细数据
字段分别对应:订单号、行号、货品、数量、单价、总额。

二、分析步骤
2.1 计算所有订单中每年的销售单数、销售总额。
思路:读取数据为df格式,注册临时表,进行三表的join操作进行查询。
代码:
/** * 计算所有订单中每年的销售单数,销售总额 * @param session */ def calculate_salesCountByYear_salesMoneyByYear(session:SparkSession)={ //日期数据读取为df val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) //订单头数据读取为df val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) //订单明细数据读取为df val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) //分别创建临时表 frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock") frame_detail.createOrReplaceTempView("detail") //执行分析 三个表join查询信息 session.sql("select sum(de.Qty) as sales_count," + "sum(de.Amount) as sales_amount," + "substring(da.Dateid,1,4) as date_Time " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid " + "group by substring(da.Dateid,1,4)").show() }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
结果:

2.2 计算所有订单中每年的最大金额订单的销售额。
思路:首先求出每份订单的销售额以及其发生时间,然后以其结果和日期数据进行表join,求得每年最大金额的订单的销售额。
代码:
/** * 计算所有订单每年最大金额订单的销售额 * @param session */ def salesMoneyOfMaxByYear(session:SparkSession)={ //分别读取数据文件转为df val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) //分别创建需要用到的临时表 frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock") frame_detail.createOrReplaceTempView("detail") //先求出每份订单的销售额以及其对应的时间 val money_date = session.sql("select (de.Qty*de.Price) as sales_money,da.Dateid " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid") //注册为临时表 money_date.createOrReplaceTempView("money_date") //将上一步分析的结果与日期数据进行表连接,从而求出每年最大金额订单的销售额 session.sql("select max(md.sales_money) as max_money," + "substring(da.Dateid,1,4) as year " + "from money_date as md " + "inner join date as da " + "on md.Dateid=da.Dateid " + "group by substring(da.Dateid,1,4) order by year").show() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
结果:
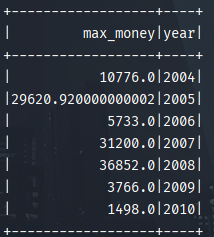
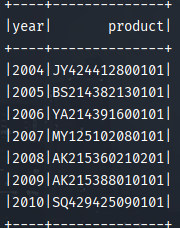
2.3 计算所有订单中每年最畅销的货品。
思路:首先求出每年每个货品的销售金额,然后求出每年单品销售的最大金额,最后进行表连接求得每年与销售额最大相符的货品就是最畅销的货品。
代码:
/** * 计算所有订单中每年最畅销的货品 * @param session */ def popular_product(session:SparkSession)={ val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock") frame_detail.createOrReplaceTempView("detail") //求每年每个货品的销售金额 val year_product_money_per = session.sql("select substring(da.Dateid,1,4) as year," + "de.Itemid as product," + "(de.Qty*de.Price) as money " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid") //求每年单品销售的最大金额 val year_money_max = session.sql("select substring(da.Dateid,1,4) as year," + "max(de.Qty*de.Price) as max_money " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid " + "group by year") year_product_money_per.createOrReplaceTempView("year_product_money_per") year_money_max.createOrReplaceTempView("year_money_max") //表连接求得最畅销货品 session.sql("select ypmp.year,ypmp.product " + "from year_product_money_per as ypmp " + "inner join year_money_max as ymm " + "on ypmp.year=ymm.year " + "where ypmp.money=ymm.max_money " + "order by ypmp.year").show() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
结果:
2.4 全部代码
代码:
package training.sectionC import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName:company_data_analyse * @author:Architect_王伯文 * @date: 2021/10/6 12:01 */ object company_data_analyse { val tbDatePath="日期数据的路径" val toStockPath="订单头数据路径" val toStockDetailPath="订单明细数据 路径 " //定义数据写入数据库的方法 def mysql_Position(frame:DataFrame, tbName:String)={ frame.write.format("jdbc") .option("url","jdbc:mysql://IP地址:3306/数据库名") .option("user","用户名") .option("password","密码") .option("dbtable",tbName) .save() } //执行数据写入数据库 def moveToMysql(session:SparkSession)={ val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) mysql_Position(frame_date,"date") mysql_Position(frame_stock,"stock") mysql_Position(frame_detail,"stockDetail") } /** * 计算所有订单中每年的销售单数,销售总额 * @param session */ def calculate_salesCountByYear_salesMoneyByYear(session:SparkSession)={ val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock") frame_detail.createOrReplaceTempView("detail") session.sql("select sum(de.Qty) as sales_count," + "sum(de.Amount) as sales_amount," + "substring(da.Dateid,1,4) as date_Time " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid " + "group by substring(da.Dateid,1,4)").show() } /** * 计算所有订单每年最大金额订单的销售额 * @param session */ def salesMoneyOfMaxByYear(session:SparkSession)={ //分别读取数据文件转为df val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) //分别创建需要用到的临时表 frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock") frame_detail.createOrReplaceTempView("detail") //先求出每份订单的销售额以及其对应的时间 val money_date = session.sql("select (de.Qty*de.Price) as sales_money,da.Dateid " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid") //注册为临时表 money_date.createOrReplaceTempView("money_date") //将上一步分析的结果与日期数据进行表连接,从而求出每年最大金额订单的销售额 session.sql("select max(md.sales_money) as max_money," + "substring(da.Dateid,1,4) as year " + "from money_date as md " + "inner join date as da " + "on md.Dateid=da.Dateid " + "group by substring(da.Dateid,1,4) order by year").show() } /** * 计算所有订单中每年最畅销的货品 * @param session */ def popular_product(session:SparkSession)={ val frame_date = session.read.format("csv").option("header", true).load(tbDatePath) val frame_stock = session.read.format("csv").option("header", true).load(toStockPath) val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath) frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock") frame_detail.createOrReplaceTempView("detail") val year_product_money_per = session.sql("select substring(da.Dateid,1,4) as year," + "de.Itemid as product," + "(de.Qty*de.Price) as money " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid") val year_money_max = session.sql("select substring(da.Dateid,1,4) as year," + "max(de.Qty*de.Price) as max_money " + "from stock as st " + "inner join detail as de " + "on st.Ordernumber=de.Ordernumber " + "inner join date as da " + "on st.Dateid=da.Dateid " + "group by year") year_product_money_per.createOrReplaceTempView("year_product_money_per") year_money_max.createOrReplaceTempView("year_money_max") session.sql("select ypmp.year,ypmp.product " + "from year_product_money_per as ypmp " + "inner join year_money_max as ymm " + "on ypmp.year=ymm.year " + "where ypmp.money=ymm.max_money " + "order by ypmp.year").show() } def main(args: Array[String]): Unit = { val session = SparkSession.builder().master("local[*]").appName("company").getOrCreate() calculate_salesCountByYear_salesMoneyByYear(session) salesMoneyOfMaxByYear(session) popular_product(session) moveToMysql(session) session.stop() } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
三、总结
以上就是我对公司销售数据的处理和分析过程,我们面对实际的需求时,的确在不熟悉业务的情况下,问题会很棘手,我的建议是要先熟悉业务,想好你要做的事情是什么,接下来在考虑好内容的划分和部分与部分之间的关系。作为一名大数据开发者来说,代码就像写字,人人都会 ,但是程序功能就像是一篇优美的文章。只要熟悉业务,我相信一切问题都可以迎刃而解!加油!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/80228
推荐阅读
相关标签

