- 1Gitee使用_idea拉取gitee代码
- 2Alpha论文系列笔记(一)AlphaGo_apalphago论文
- 3基于大模型的知识问答系统全面总结(附Python完整代码)_问答模型 及用户
- 4Vivado使用_vivado用什么语言
- 5SQL Server如何设置账号密码_安装sqlserver时没有设置用户名和密码
- 6Javaweb学生信息管理系统(Mysql+JSP+MVC+CSS)_jsp学生管理系统代码
- 7采用WPF技术,开发OFD电子文档阅读器
- 8Elasticsearch中的post_filter后置过滤器技术_elasticsearch postfilter
- 9Java项目:图书管理系统(java+SpringBoot+html+ThymeLeaf+Bootstrap+maven+mysql)_对于商品的增删改查的前端代码及后端代码idea要前端好看的javaweb项目
- 10SQL语言的分类(DQL、DML、DDL、DCL的概念与区别)_dml和sql的区别
人工智能学习6(贝叶斯实现简单的评论情感分析)_贝叶斯做情感分析
赞
踩
编译工具PyCharm
文本分析与表示
文本分析基于深度学习和自然语言处理的原则工作。
实现方式:
正则表达式REGEX:指作为需提取内容的前提条件的特定格式化符号数组
条件随机场CRFs:之通过评估特定模式或短语提取文本的机器学习方法,更加精细和灵活。
文本表示方法
one-hot是指在一个向量中,只有一个位置上的值是1,其他位置都是0.缺点:无法表现词与词之间的语义关系,当数据量大的时候,维数也会变得很大。
Bag of Words(词袋表示):也成为Count Vectors,每个文档的字词可以使用其出现次数来进行表示。缺点:会忽略文本的表达顺序,如我爱你和你爱我,表示都一样。
N-gram:与Count Vectors类似,不过加入了相邻单词组合成新的单词,并且进行计数。
TF-IDF关键词提取:两部分组成,词频TF和逆文档概率IDF
TF=某个词在文中出现的次数/文本中一共包含多少个词
IDF=log(语料库的文档总数/包含该词的文档数)
文本相似度计算
余弦相似度
LDA主题模型
LDA主题模型不关心词的顺序,用bag of words词袋表示。
朴素贝叶斯算法

朴素贝叶斯假定特征与特征相互独立

但是如果词频列表里有很多出现的次数为0,是计算结果可能为0;
解决方法:拉普拉斯平滑系数

例如:特征词个数为6

应用:评论情感分析,工具评论分析是好评还是差评
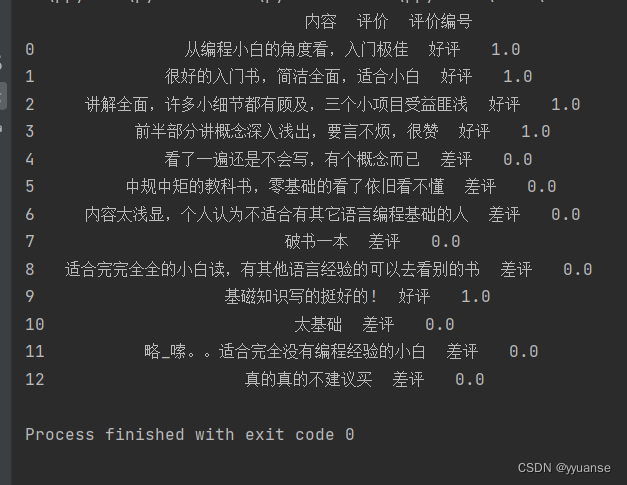
data.csv数据如下
内容,评价
从编程小白的角度看,入门极佳,好评
很好的入门书,简洁全面,适合小白,好评
讲解全面,许多小细节都有顾及,三个小项目受益匪浅,好评
前半部分讲概念深入浅出,要言不烦,很赞,好评
看了一遍还是不会写,有个概念而已,差评
中规中矩的教科书,零基础的看了依旧看不懂,差评
内容太浅显,个人认为不适合有其它语言编程基础的人,差评
破书一本,差评
适合完完全全的小白读,有其他语言经验的可以去看别的书,差评
基磁知识写的挺好的!,好评
太基础,差评
略_嗦。。适合完全没有编程经验的小白,差评
真的真的不建议买,差评
stopwords.csv上网找一个中文禁用词表即可,我用的是这一篇博客提供的。
https://blog.csdn.net/dilifish/article/details/117885706
获取数据
import pandas as pd
# 获取数据
data = pd.read_csv("./data/data.csv")
# 数据基本处理
content = data['内容']
# print(content)
# 将评价中的好差评转换为数字
# 添加一列为评价编号,如果是好评评价编号为1,差评为0
data.loc[data.loc[:,'评价']=="好评","评价编号"]=1
data.loc[data.loc[:,'评价']=="差评","评价编号"]=0
print(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
加载停用词
# 加载停用词
stopwords = []
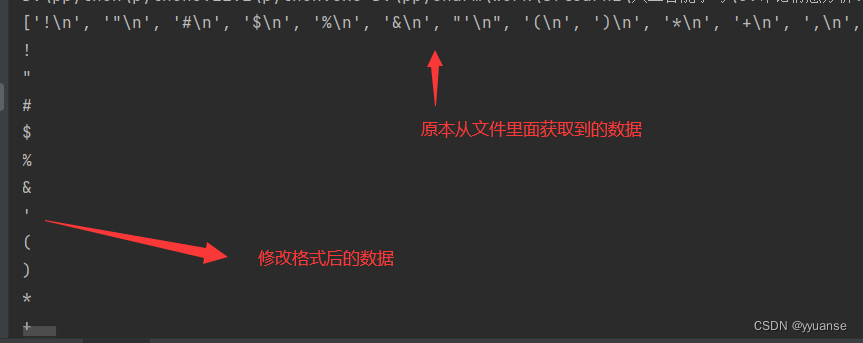
with open("./data/stopwords.csv","r",encoding="utf-8") as f:
lines=f.readlines()
print(lines)
# 有些数据并不是按照一行一行排序的,而是很乱,一个数据里面含\n进行换行
# 通过下面的方法可以将其变成一行一行排列的
for tmp in lines:
line = tmp.strip()
print(line)
stopwords.append(line)
# 去重
stopwords = list(set(stopwords))
print(stopwords)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
去重后的数据

内容标准化(将每一句话划分成一个个的词)
# 内容标准化
# 将每一句话划分成词
comment_list=[]
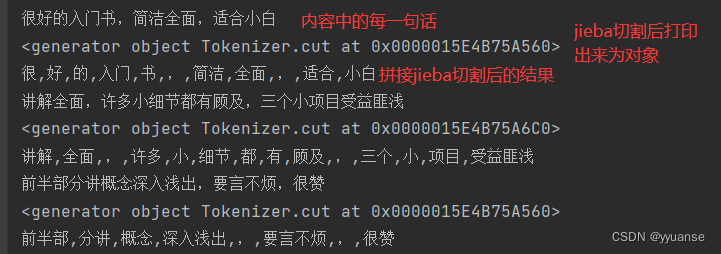
for tmp in content:
print(tmp)
# 对文本进行切割
seg_list=jieba.cut(tmp,cut_all=False)
print(seg_list) # 这个只能打印出对象
# 拼接字符串
seg_str = ','.join(seg_list)
print(seg_str)
comment_list.append(seg_str)
print(comment_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
comment_list打印出来

统计词的个数
# 统计词的个数
# from sklearn.feature_extraction.text import CountVectorizer
con = CountVectorizer(stop_words=stopwords)
X = con.fit_transform(comment_list)
name = con.get_feature_names_out()
print(X.toarray())
print(name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
打印出来的矩阵

矩阵分别对应的字词

模型训练及预测
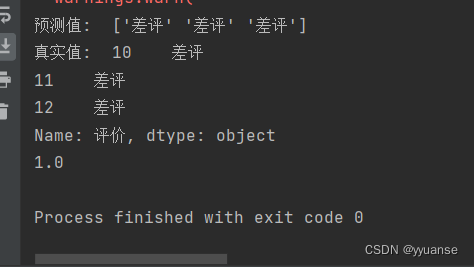
# 准备训练集和测试集 # 训练集 x_train = X.toarray()[:10,:] y_train = data["评价"][:10] # 测试集 x_test = X.toarray()[10:,:] y_test = data["评价"][10:] # 模型训练 # from sklearn.naive_bayes import MultinomialNB # alpha=1即拉普拉斯平滑系数为1 mb = MultinomialNB(alpha=1) mb.fit(x_train,y_train) y_pre = mb.predict(x_test) print("预测值: ",y_pre) print("真实值: ",y_test) # 模型评估 print(mb.score(x_test, y_test))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17