
- 1建网站并不难,只需6个步骤,就能做出一个网站_网站制作教程
- 2各国程序员年薪中位数对比_世界各国工资中位数
- 3【STM32F407开发板用户手册】第11章 STM32F407移植SEGGER的硬件异常分析_stm32f407 freertos 开发手册
- 4让你的python程序开机自启动_python寫的小程序開機自啟動
- 5python开机自动运行_python 设置开机启动脚本
- 6scanf_scanf格式语言没有逗号,输入却有逗号
- 7MongoDB安装出现Verify that you have sufficient privileges to start system services的解决办法
- 8vue3 之 组合式API - setup选项
- 9【STM32】HAL库 STM32CubeMX教程十四---SPI_cubemx spi
- 10八个前端开发必备的面试刷题网站_前端面试网站
用PySpark开发时的调优思路(下)
赞
踩

上期回顾:用PySpark开发时的调优思路(上)
2. 资源参数调优
如果要进行资源调优,我们就必须先知道Spark运行的机制与流程。
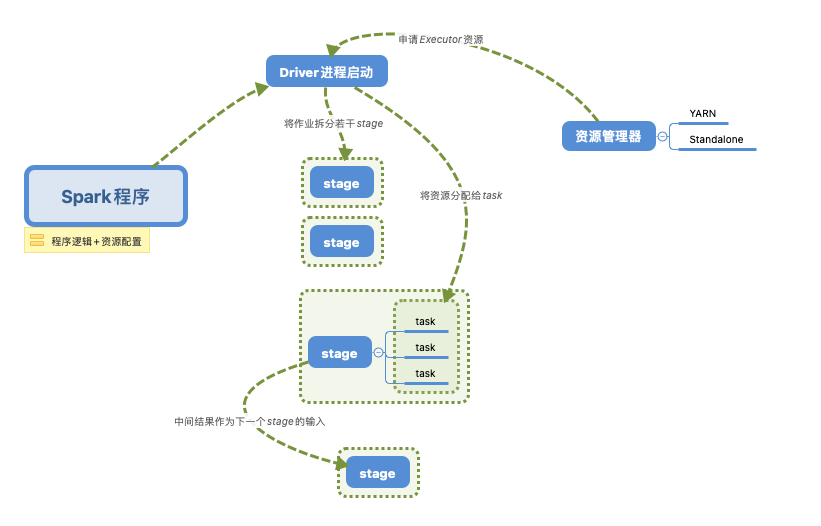
下面我们就来讲解一些常用的Spark资源配置的参数吧,了解其参数原理便于我们依据实际的数据情况进行配置。
1)num-executors
指的是执行器的数量,数量的多少代表了并行的stage数量(假如executor是单核的话),但也并不是越多越快,受你集群资源的限制,所以一般设置50-100左右吧。
2)executor-memory
这里指的是每一个执行器的内存大小,内存越大当然对于程序运行是很好的了,但是也不是无节制地大下去,同样受我们集群资源的限制。假设我们集群资源为500core,一般1core配置4G内存,所以集群最大的内存资源只有2000G左右。num-executors x executor-memory 是不能超过2000G的,但是也不要太接近这个值,不然的话集群其他同事就没法正常跑数据了,一般我们设置4G-8G。
3)executor-cores
这里设置的是executor的CPU core数量,决定了executor进程并行处理task的能力。
4)driver-memory
设置driver的内存,一般设置2G就好了。但如果想要做一些Python的DataFrame操作可以适当地把这个值设大一些。
5)driver-cores
与executor-cores类似的功能。
6)spark.default.parallelism
设置每个stage的task数量。一般Spark任务我们设置task数量在500-1000左右比较合适,如果不去设置的话,Spark会根据底层HDFS的block数量来自行设置task数量。有的时候会设置得偏少,这样子程序就会跑得很慢,即便你设置了很多的executor,但也没有用。
下面说一个基本的参数设置的shell脚本,一般我们都是通过一个shell脚本来设置资源参数配置,接着就去调用我们的主函数。
- #!/bin/bash
- basePath=$(cd "$(dirname )"$(cd "$(dirname "$0"): pwd)")": pwd)
- spark-submit \
- --master yarn \
- --queue samshare \
- --deploy-mode client \
- --num-executors 100 \
- --executor-memory 4G \
- --executor-cores 4 \
- --driver-memory 2G \
- --driver-cores 2 \
- --conf spark.default.parallelism=1000 \
- --conf spark.yarn.executor.memoryOverhead=8G \
- --conf spark.sql.shuffle.partitions=1000 \
- --conf spark.network.timeout=1200 \
- --conf spark.python.worker.memory=64m \
- --conf spark.sql.catalogImplementation=hive \
- --conf spark.sql.crossJoin.enabled=True \
- --conf spark.dynamicAllocation.enabled=True \
- --conf spark.shuffle.service.enabled=True \
- --conf spark.scheduler.listenerbus.eventqueue.size=100000 \
- --conf spark.pyspark.driver.python=python3 \
- --conf spark.pyspark.python=python3 \
- --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=python3 \
- --conf spark.sql.pivotMaxValues=500000 \
- --conf spark.hadoop.hive.exec.dynamic.partition=True \
- --conf spark.hadoop.hive.exec.dynamic.partition.mode=nonstrict \
- --conf spark.hadoop.hive.exec.max.dynamic.partitions.pernode=100000 \
- --conf spark.hadoop.hive.exec.max.dynamic.partitions=100000 \
- --conf spark.hadoop.hive.exec.max.created.files=100000 \
- ${bashPath}/project_name/main.py $v_var1 $v_var2

3. 数据倾斜调优
相信我们对于数据倾斜并不陌生了,很多时间数据跑不出来有很大的概率就是出现了数据倾斜,在Spark开发中无法避免的也会遇到这类问题,而这不是一个崭新的问题,成熟的解决方案也是有蛮多的,今天来简单介绍一些比较常用并且有效的方案。
首先我们要知道,在Spark中比较容易出现倾斜的操作,主要集中在distinct、groupByKey、reduceByKey、aggregateByKey、join、repartition等,可以优先看这些操作的前后代码。而为什么使用了这些操作就容易导致数据倾斜呢?大多数情况就是进行操作的key分布不均,然后使得大量的数据集中在同一个处理节点上,从而发生了数据倾斜。
查看Key 分布
- # 针对Spark SQL
- hc.sql("select key, count(0) nums from table_name group by key")
-
- # 针对RDD
- RDD.countByKey()
Plan A: 过滤掉导致倾斜的key
这个方案并不是所有场景都可以使用的,需要结合业务逻辑来分析这个key到底还需要不需要,大多数情况可能就是一些异常值或者空串,这种就直接进行过滤就好了。
Plan B: 提前处理聚合
如果有些Spark应用场景需要频繁聚合数据,而数据key又少的,那么我们可以把这些存量数据先用hive算好(每天算一次),然后落到中间表,后续Spark应用直接用聚合好的表+新的数据进行二度聚合,效率会有很高的提升。
Plan C:调高shuffle并行度
- # 针对Spark SQL
- --conf spark.sql.shuffle.partitions=1000 # 在配置信息中设置参数
- # 针对RDD
- rdd.reduceByKey(1000) # 默认是200
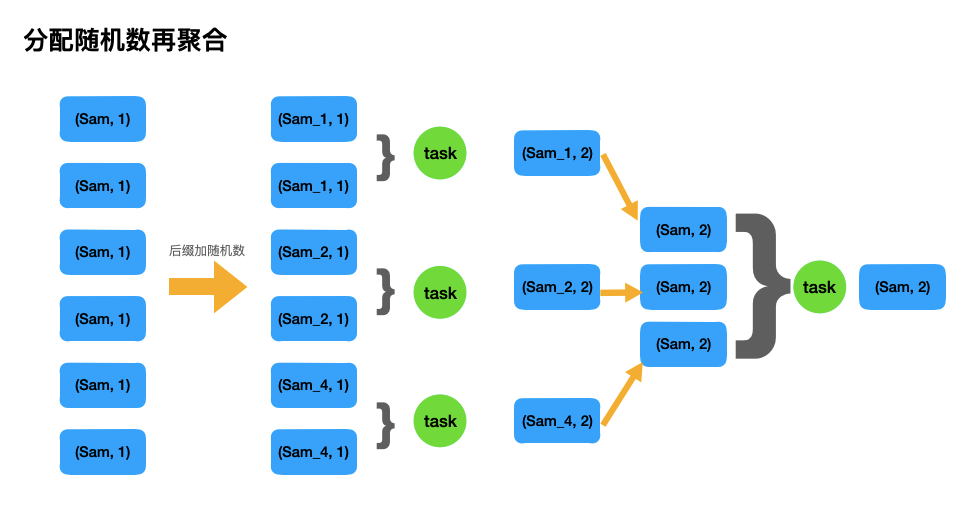
Plan D:分配随机数再聚合
大概的思路就是对一些大量出现的key,人工打散,从而可以利用多个task来增加任务并行度,以达到效率提升的目的,下面是代码demo,分别从RDD 和 SparkSQL来实现。
- # Way1: PySpark RDD实现
- import pyspark
- from pyspark import SparkContext, SparkConf, HiveContext
- from random import randint
- import pandas as pd
-
- # SparkSQL的许多功能封装在SparkSession的方法接口中, SparkContext则不行的。
- from pyspark.sql import SparkSession
- spark = SparkSession.builder \
- .appName("sam_SamShare") \
- .config("master", "local[4]") \
- .enableHiveSupport() \
- .getOrCreate()
-
- conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]")
- sc = SparkContext(conf=conf)
- hc = HiveContext(sc)
-
- # 分配随机数再聚合
- rdd1 = sc.parallelize([('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1)])
-
- # 给key分配随机数后缀
- rdd2 = rdd1.map(lambda x: (x[0] + "_" + str(randint(1,5)), x[1]))
- print(rdd.take(10))
- # [('sam_5', 1), ('sam_5', 1), ('sam_3', 1), ('sam_5', 1), ('sam_5', 1), ('sam_3', 1)]
-
- # 局部聚合
- rdd3 = rdd2.reduceByKey(lambda x,y : (x+y))
- print(rdd3.take(10))
- # [('sam_5', 4), ('sam_3', 2)]
-
- # 去除后缀
- rdd4 = rdd3.map(lambda x: (x[0][:-2], x[1]))
- print(rdd4.take(10))
- # [('sam', 4), ('sam', 2)]
-
- # 全局聚合
- rdd5 = rdd4.reduceByKey(lambda x,y : (x+y))
- print(rdd5.take(10))
- # [('sam', 6)]
-
-
- # Way2: PySpark SparkSQL实现
- df = pd.DataFrame(5*[['Sam', 1],['Flora', 1]],
- columns=['name', 'nums'])
- Spark_df = spark.createDataFrame(df)
- print(Spark_df.show(10))
-
- Spark_df.createOrReplaceTempView("tmp_table") # 注册为视图供SparkSQl使用
-
- sql = """
- with t1 as (
- select concat(name,"_",int(10*rand())) as new_name, name, nums
- from tmp_table
- ),
- t2 as (
- select new_name, sum(nums) as n
- from t1
- group by new_name
- ),
- t3 as (
- select substr(new_name,0,length(new_name) -2) as name, sum(n) as nums_sum
- from t2
- group by substr(new_name,0,length(new_name) -2)
- )
- select *
- from t3
- """
- tt = hc.sql(sql).toPandas()
- tt
下面是原理图。
All Done!
????学习资源推荐:
1)《Spark性能优化指南——基础篇》
https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
2)《Spark性能优化指南——高级篇》
https://tech.meituan.com/2016/05/12/spark-tuning-pro.html

