- 1pyspark使用说明_pyspark svm教材
- 2Amazon Titan 图像生成器和水印检测 API 现已在 Amazon Bedrock 上推出
- 3前端常见安全问题及解决方法_前端安全问题及防范
- 4git pull的时候报错:git did not exit cleanly (exit code 1)_tortoisegit拉代码报 git did not exit cleanly exit code
- 5基础-循环输出_请从键盘读入一个整数n,输出1~n中所有是2的倍数,但非3的倍数的数,每行1个。 比如,
- 6智能车摄像头算法_智能车图像处理算法代码放在哪里
- 7【保驾护航】HarmonyOS应用开发者基础认证-题库-2024_鸿蒙基础认证答案2024
- 8❤️创意网页:迎接高考的倒计时网页(❤️好看好用❤️)HTML+CSS+JS
- 9Java桥接模式
- 10显示连接同步服务器失败怎么办,help me,wsus 服务器连接失败,一直显示 上次目录尝试同步失败...
Python——数据分析入门学习_python数据分析入门
赞
踩
1. python基础函数
1.1 数据类型
1.1.1 Numbers(数字)
1.int型
- #在python中可以直接键入值整数
-
- 123
2.float型
- #在python中可以直接键入值小数
-
- 23.3
3.bool型

- #在python中可以直接键入比较的表达式
-
- 15>21
1.1.2 string(字符串)
文本通常使用该格式存储
1.1.3 list(列表)
它能够将相同或不同类型的数据组合到一起。
![]()
列表的合并:extend()
例如将history列表和ad_list列表合并:
history.extend(ad_list)
1.1.4 dict(字典)
它的结构,是一种映射结构。

{'a': 123, 'b': 456, 'c': 777}
1.多列字典组成多行多列表格
字典中key不可以重复,想表示多列需修改key:

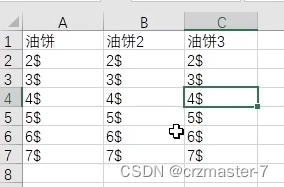
右图为对应的excel表
2..多行字典组成多行多列表格
外层套列表

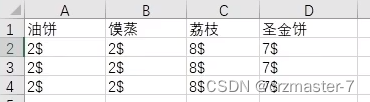
1.1.5 变量

1.2数据的检索与查询
1.2.1 list检索
list是一个有序列表,python的一切都是从0开始

检索方式:方括号+具体数值
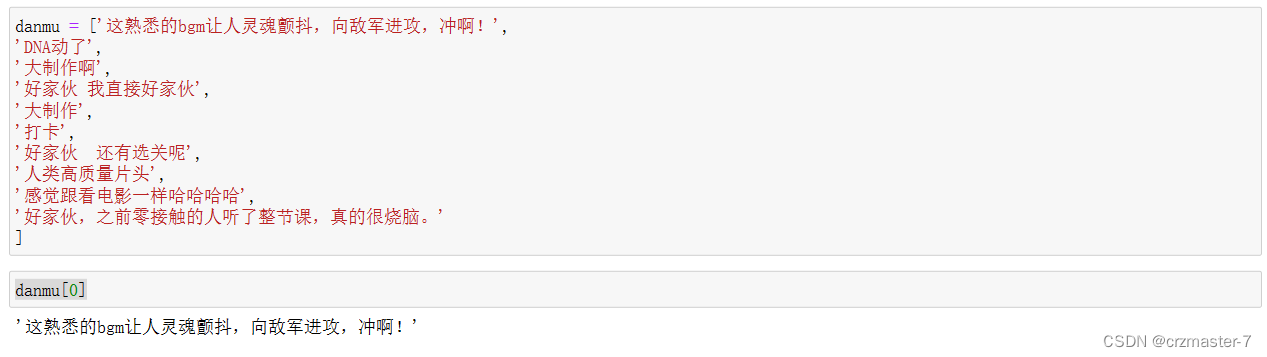
用变量名给列表命名检索,简化操作。
 [0:3]表示0到3,左闭右开区间
[0:3]表示0到3,左闭右开区间
2.2dict的查询
由于dict是一种映射结构,输入key,程序会返回对应的value
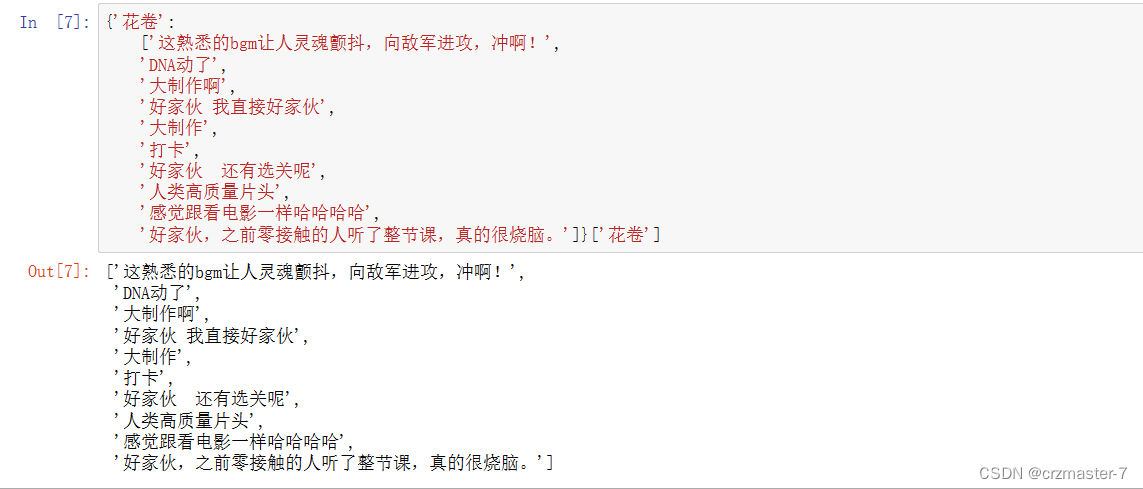
通过方括号[] + 具体字段名 的方式,能够得到字段对应的内容,同时,让我们用变量给这个字典赋一个别名,会更加方便我们的操作

我们会发现danmu['花卷']输出的是一个列表,那么danmu['花卷']可以直接采用上面学到的列表有序访问,输出具体的某一个弹幕

1.3简单的数据处理
1.取出数据
赋值给一个变量 ad_1=ad_list[0]
2.处理重复字段
删除函数:del ad_1[‘成交金额’]
3.处理异常值
我们若要使字典中的一个值更改应重新赋值次值
ad_1['gmv']=ad_1['gmv']/100
4.增加值
若增加一个指标roi:
ad_1['roi']=ad_1['gmv']/ad_1['消耗']
保留小数函数:round(值,保留位数)
ad_1['roi']=round(ad_1['gmv']/ad_1['消耗'],2) 此操作使roi保留两位小数
5.分割字符串
字符串后跟.split('分割依据')
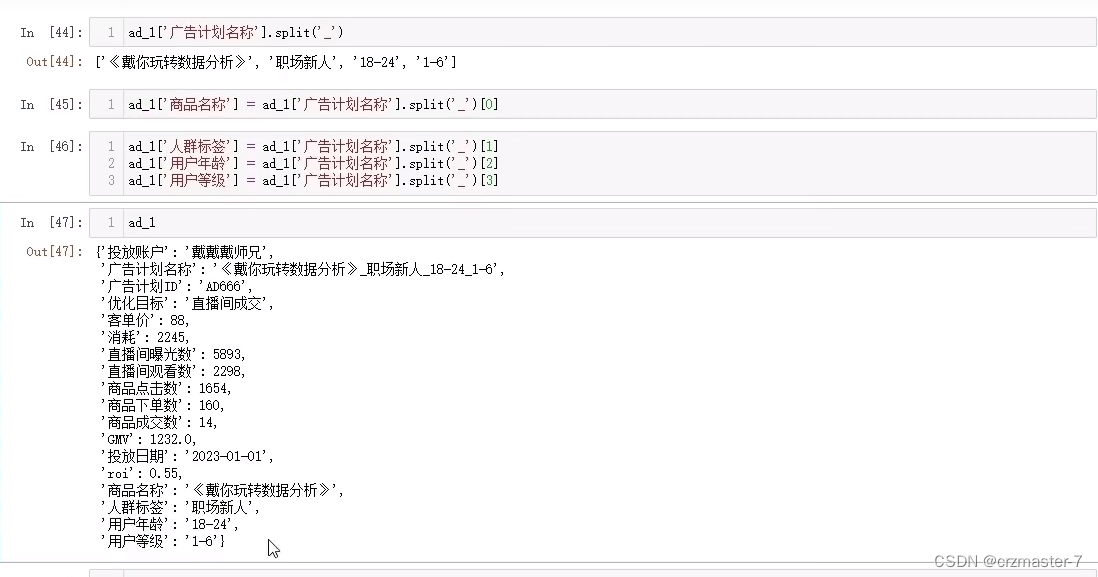
如图,以‘_’为分割依据进行分割,分割后返回的结果是一个列表。
1.4 for循环

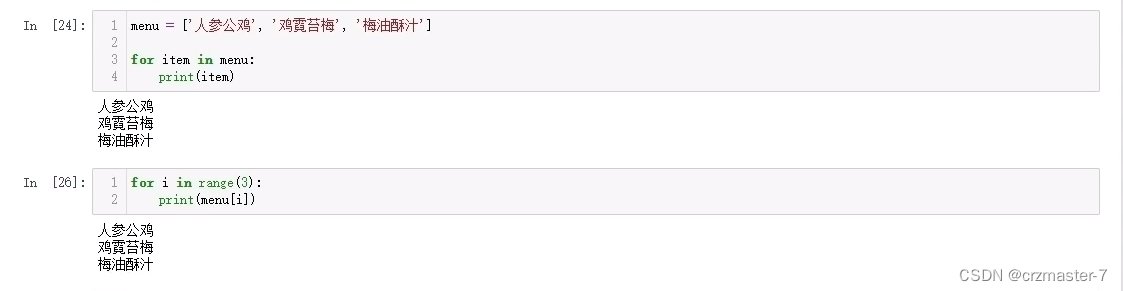
两种for循环
range()函数:
表示一个范围,左闭右开
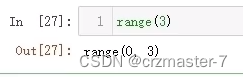

-1表示倒数第一个,因此range(-1,0)表示执行倒数第一个,0是开区间
len()函数:
计算出一个序列的长度
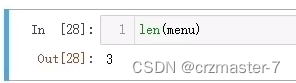
range()和len()通常搭配使用,对第二种for循环的修改版:
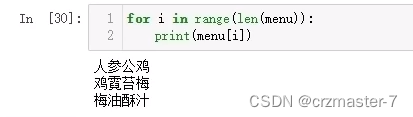
过大数据的打开方法:
先存入txt中
输入以下代码:
with open('数据.txt','r',encoding='utf-8') as f:
history = f.readline()
这里history是变量名,打开是字符串类型,不能进行数据处理
history=eval(history)
用eval()将字符串转换成列表类型
1.5 if语句

if :
else:
或
if:
elif:
else:
1.6自定义函数
1.有参数输入,有返回值输出
- def noddle_machine(water,mianfen):
- print('豁楞豁楞..豁楞豁楞..')
- print(f'{water}和{mainfen}已经变成了面团')
- print('正在挤压面团')
- return f'由{water}和{mainfen}制作而成的面条ok了'
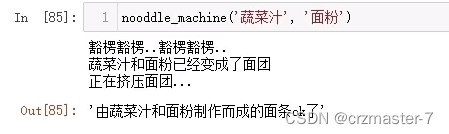
f字符串:
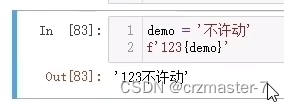
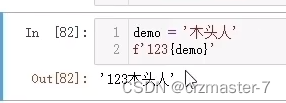
只需在变量上更改,方便操作
2.没有输入参数,有返回值
- import datetime
- def yesterday():
- date=datetime.datetime.now()-date.timedelta(days=1)
- return date.date()
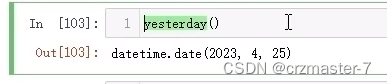
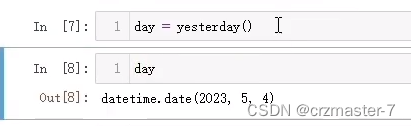
有返回值的函数通常用一个变量存储起来:
3.有参数输入,无返回值
- def uploda_data(date)
- print(f'已经将{date}的数据,上传至数据库')

4.无参数输入,无返回值
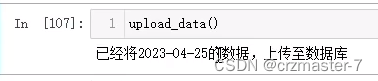
- def upload_data()
- date=yesterday()
- print(f'已经将{date}的数据,上传至数据库')
2. python小进阶
2.1 模块/包
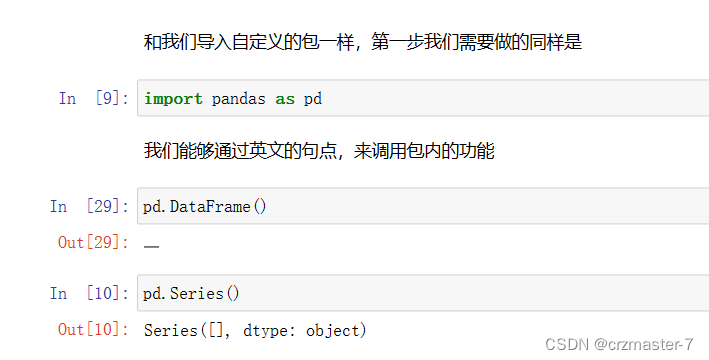
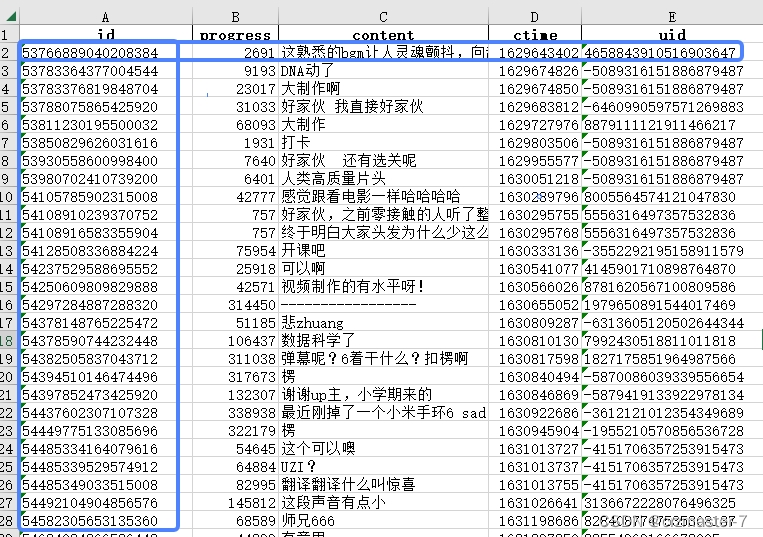
2.2 DataFrame与Series
Series,仅表现为单独的一列内容 或者 一行内容(图中蓝色部分)
DataFrame,不仅可以表现为单独的一列/一行内容,还能表现为多列/行内容,或者是一整张表格
2.3 数据的读取与导出
- import pandas as pd
- data=pd.read_excel(r'路径',
- converters={'uid':str} #此函数将uid以字符串类型读取,若不执行以数值读取
- )

data.info()会检测data中的数据类型
在修改数据类型时可以在上面读取时converters中修改,也可以使用satype()修改:

导出操作:
- data.to_excel('test excel.xlsx,index=False) #index=False的作用是去掉导出后表格里的索引
- data.to_csv('test excel.csv,encoding='GB18030')
直接导出成csv格式数据类型可能会乱码,通常先导成txt后用csv打开:
![]()
在用csv打开时,在数据类型处进行正确的选取
2.4访问与筛选

访问列:
单列

多列:双方括号

切片去出的仍是dataframe ,仍可再次基础上取列: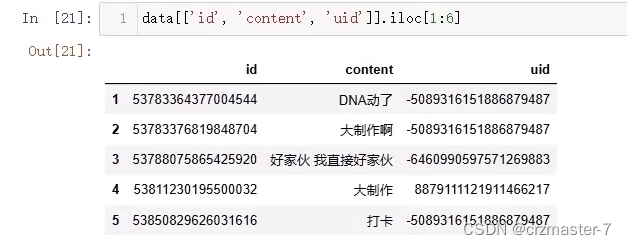
访问行:
使用iloc[]
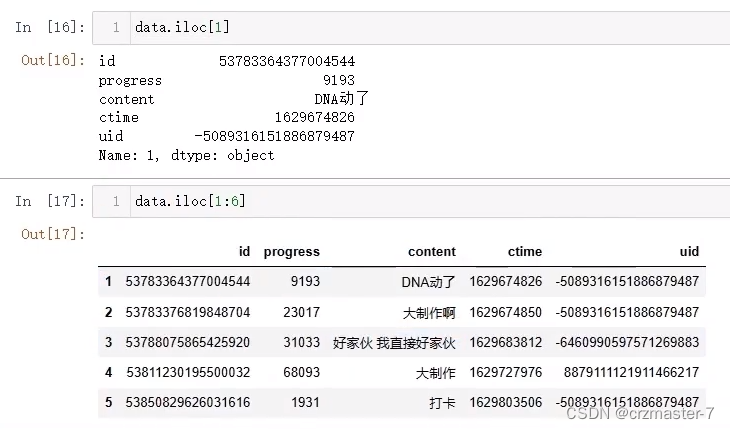
切片去出的仍是dataframe ,仍可再次基础上取列:
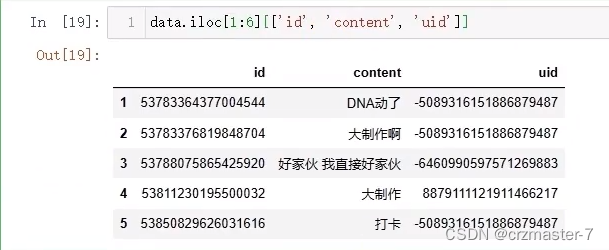
具体访问:
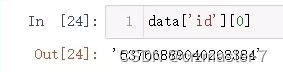
筛选:
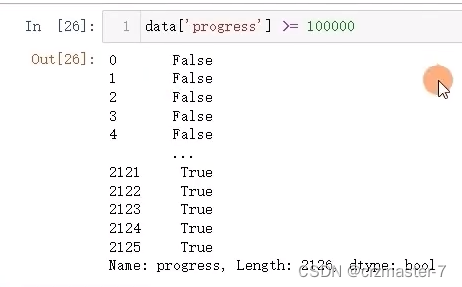
再外套一层data的访问可返回所有结果为true的信息:
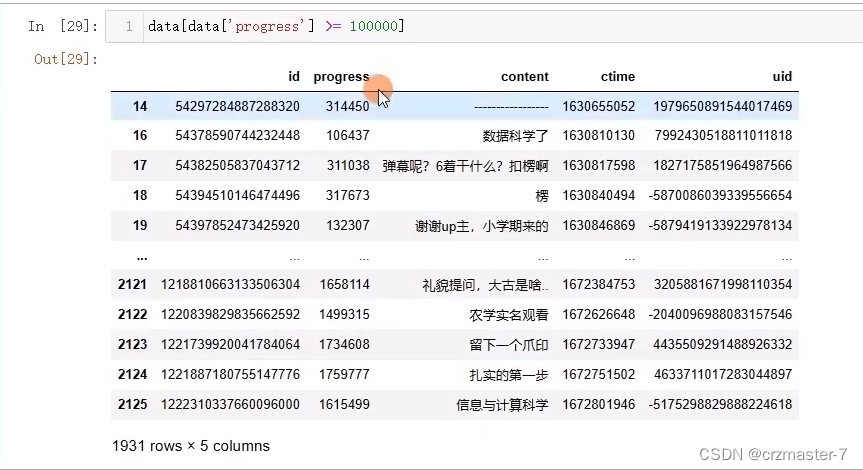
数据去重:
- data.drop_duplicates(subset='uid',keep='last',inpalce=True)
- #subset 表示对uid重复的进行去重
- #keep表示保留什么,first保留第一次出现的,last保留最后一次出现的
- #inplace 为true即对原表进行更改
2.5 轴/合并/连接
轴:
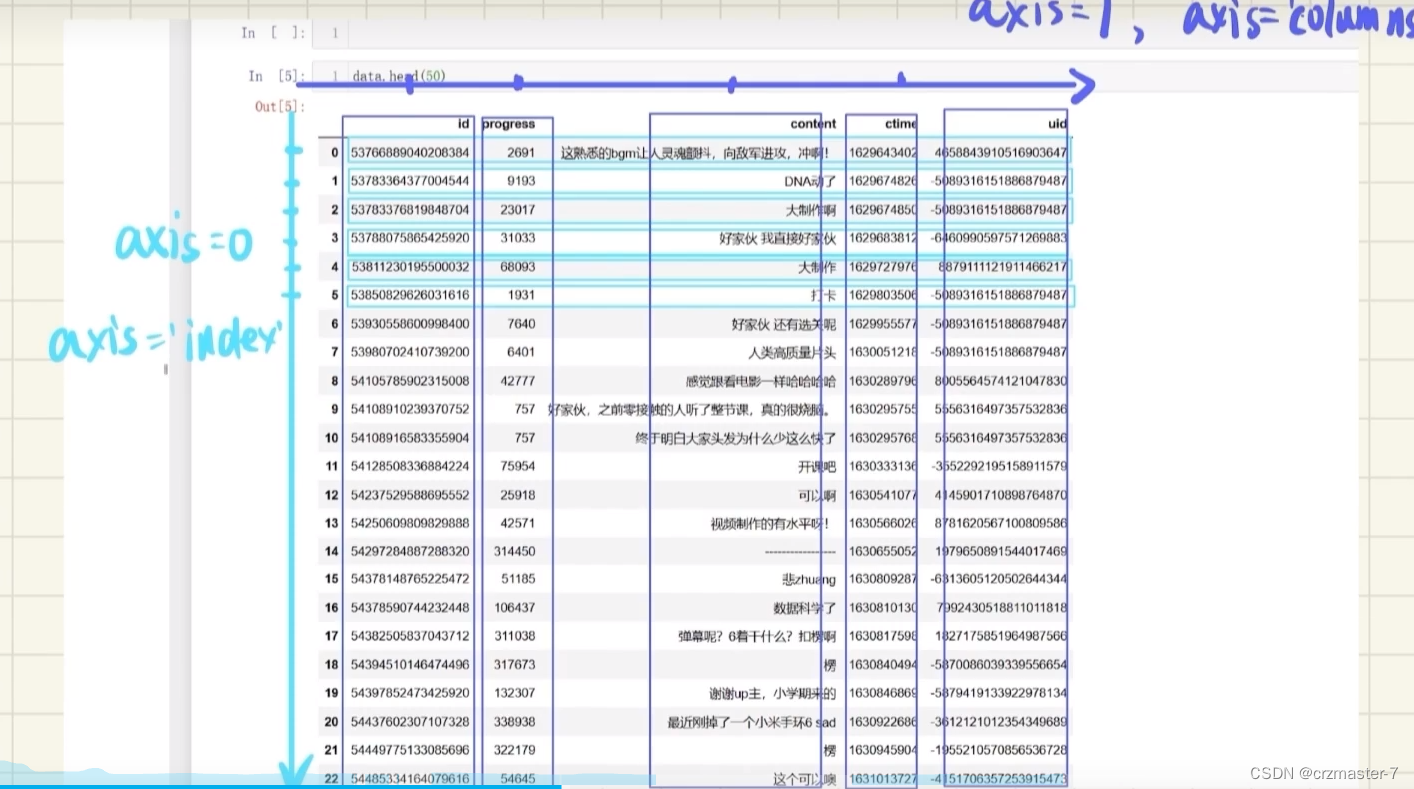

合并:
- #合并两份数据
- data_demo=pd.contact([data1,data2],axis=0)
- #axis=0表示上下合并
连接:
- #连接两份数据
- pd.merge(concat_demo,user_level,how='inner',on='uid')
- #左表为concat_demo,右表为user_level,连接方式为内连接,连接依据是uid
当连接依据名字不一样时候:
- user_level.rename(columns={'uid':'user_id'},inplace=True)
- #将user_level表列名uid更名为user_id
- pd.merge(concat_demo,user_level,how='inner',left_on='uid',right_on='user_id')
2.6 排序与匿名函数
排序:
- data.sort_values(['uid','ctime'],ascending=[True,False])
- #uid按升序,ctime按降序排序
匿名函数:
- def add(x,y):
- return x+y
-
- add2=lambda x,y:x+y #lambda创建匿名函数
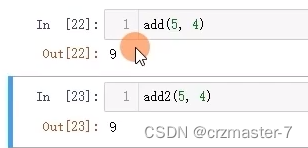
2.7 分组,聚合,转换
分组:
- #若将表user_level以level分组
- level_manager=user_level.groupby('level')
level_manager.count()
可计算出分组后不同等级各有多少人
- #若想查看分组后的情况,可用for循环
- for name,df in level_manager:
- print(name)
- print(df)
聚合:
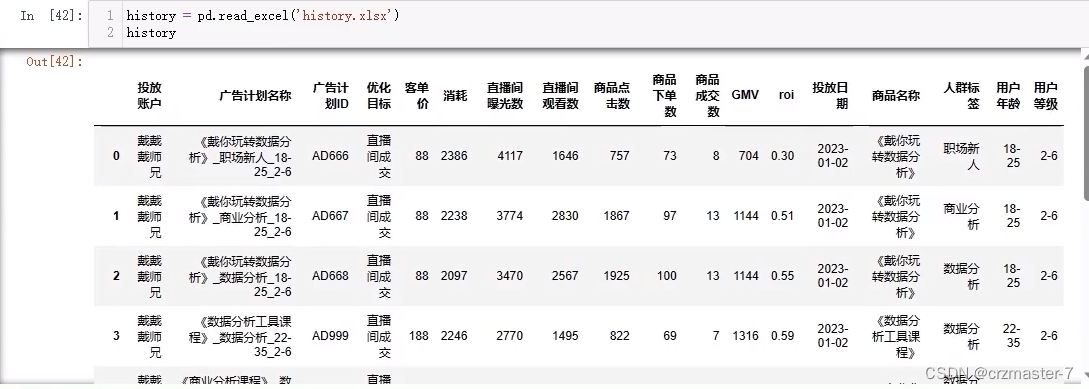
以上为读取的dataframe history
- #若以商品名称分组,计算消耗的总和
- product_gp=history.groupby('商品名称')
- product_gp['消耗'].sum()
 此时类型为series
此时类型为series
- #若想美化返回值,加两个方括号
- product_gp=history.groupby('商品名称')
- product_gp[['消耗']].sum()
 此时类型为dataframe
此时类型为dataframe
- product_gp=history.groupby('商品名称')
- product_gp[['消耗','GMV']].sum()

- #当想看到不同的聚合指标时,用agg()函数
- #.agg([fun1,fun2...])
- #如下显示消耗和GMV各自的最大最小值
- product_gp=history.groupby('商品名称')
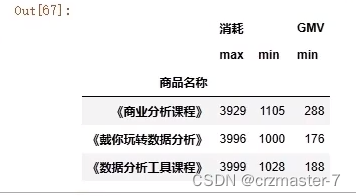
- product_gp[['消耗','GMV']].agg(['max','min'])

- #若要多个字段各自不同的聚合
- #.agg({col1:fun1,col2:fun2...})
- #如下显示消耗的最大和GMV最小值
- product_gp=history.groupby('商品名称')
- product_gp.agg({'消耗:'max','GMV':'min'})

- #.agg({col1:[fun1,fun2...],col2:fun2...})
- #如下显示消耗的最大值和最小值,GMV最小值
- product_gp=history.groupby('商品名称')
- product_gp.agg({'消耗:['max','min'],'GMV':'min'})
自定义函数与聚合的使用:
- #计算依照商品名称分组的消耗,gmv最大值和最小值的差值
- #def 方法:
- def diff(x):
- return x.max()-x.min()
- product_gp[['消耗','GMV']].agg(diff)

- #计算依照商品名称分组的消耗,gmv最大值和最小值的差值
- #lambda 方法:
- product_gp[['消耗','GMV']].agg(lambda x:x.max()-x.min())
当需求很复杂时def方法相对好用,反之lambda好用
转换:
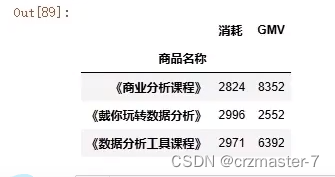
product_gp['GMV'].transform(func='sum')
这里是将分组后GMV各组总值计算出来,又加入未分组前的表格后
将转换后的数据以gmv总和为列名加入history中如图所示:
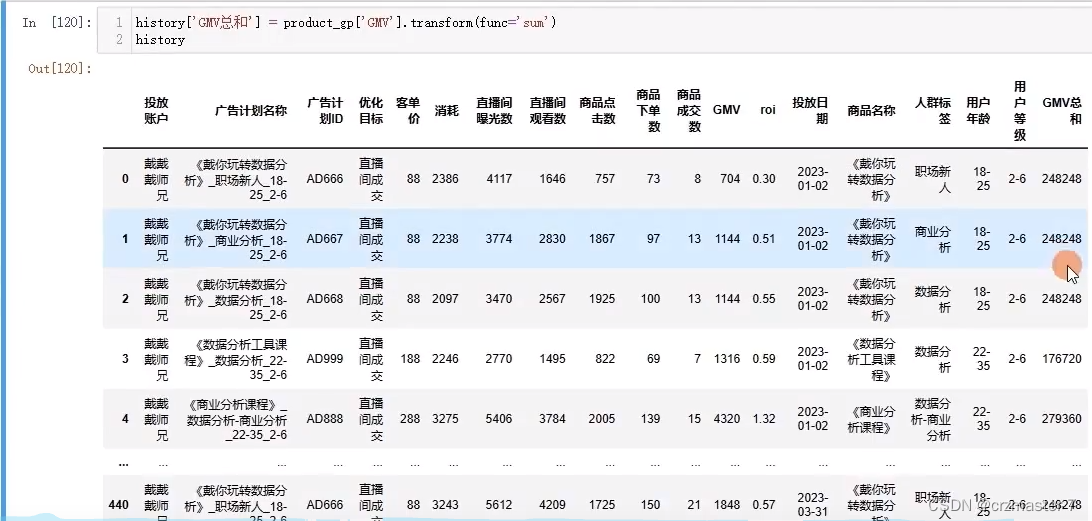
逻辑如图所示:

分组排名:
- #每个投放日期,广告计划id的gmv排名
- history.grouby('投放日期')['GMV'].rank()

发现排名有x.5的情况出现,这里有平均的操作,因此要修改:
- #引入method=
- history.grouby('投放日期')['GMV'].rank(method='dense')

- #再加入倒序排序,大的GMV排在前面,加入history中
- history['每日GMV排名']=history.groupby('投放日期')['GMV'].rank(method='dense',ascending=False)
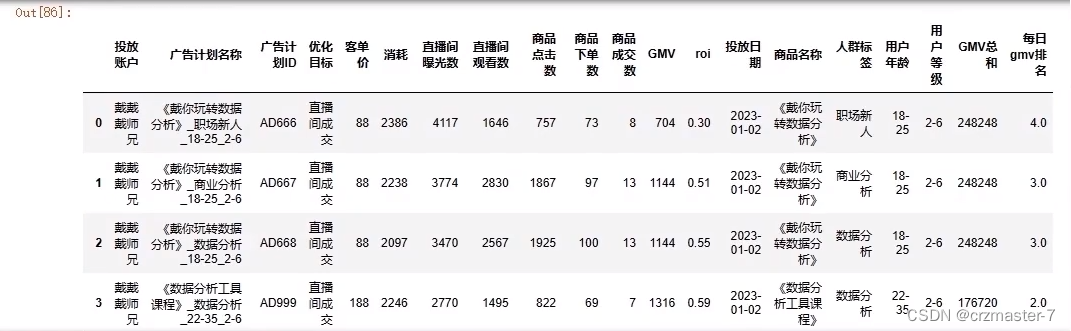
将排名的浮点型转化为整型:
history['每日GMV排名']=history['每日GMV排名'].astype(int)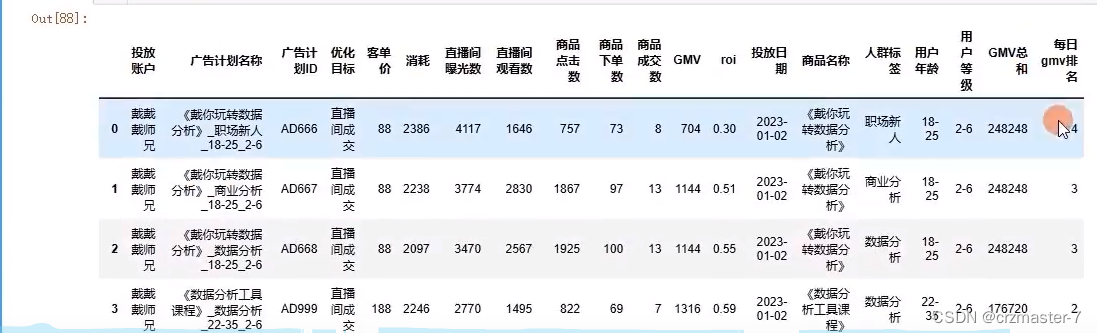
2.8 字符串方法
split

history['广告计划名称'].str.split('_')
若要使返回值成为dataframe类型
history['广告计划名称'].str.split('_'.expand=True)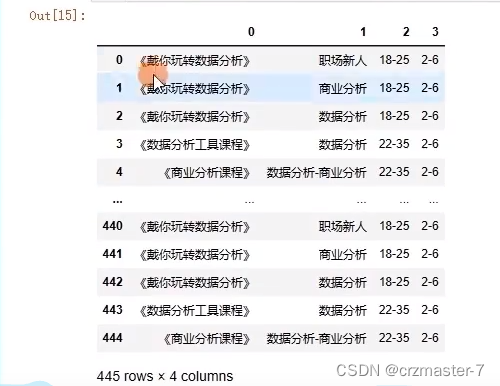
contains
进行一个数据的筛选
history['商品名称'].str.contains('玩转')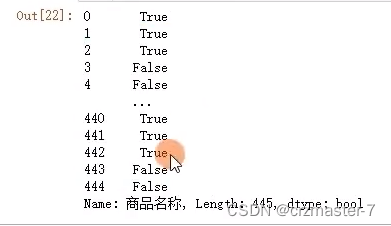
布尔索引:
- history[history['商品名称'].str.contains('玩转')].reset_index(drop=True)
- #reset_index新建索引标签,drop=True删除旧标签
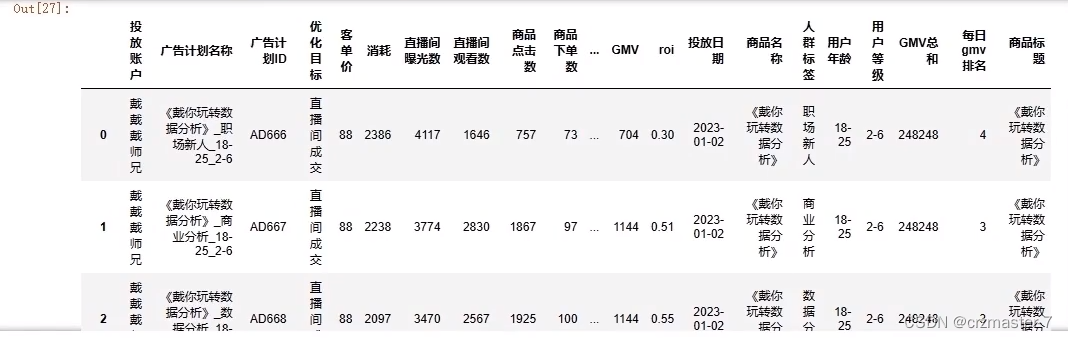
replace
- history['商品名称'].str.replace('《','【').str.replace('》','】')
- #将商品名称中的书名号替换掉
- history['商品名称'].str.replace(r'《(.*?)》',r'【\1】',regex=True)
- #正则表达式相关知识
extract
提取符合正则表达式的内容

2.9 绘图
折线图
- history.groupby('投放日期')['GMV'].sum().plot(kind='line',x='投放日期',y='GMV')
- #kind=line表示是折线图
- #图表内不能直接显示中文因此要导入包
- import matplotlib.pyplot sa plt
- plt.rcParams['font.family']='SimHei'
柱状图
- history.groupby('投放日期')['GMV'].sum().plot(kind='bar',x='投放日期',y='GMV')
- #kind=bar表示是柱状图
水平柱状图
- history.groupby('投放日期')['GMV'].sum().plot(kind='barh',x='投放日期',y='GMV')
- #kind=barh表示是水平柱状图
直方图
- history.groupby('投放日期')['GMV'].sum().plot(kind='hist',x='投放日期',y='GMV')
- #kind=hist表示是直方图
散点图
- history.groupby('投放日期')['GMV'].sum().plot(kind='scatter',x='投放日期',y='GMV')
- #kind=scatter表示是散点图
饼图
- history.groupby('投放日期')['GMV'].sum().plot(kind='pie')
- #kind=pie表示是饼图
2.10 map/apply/applymap
map:
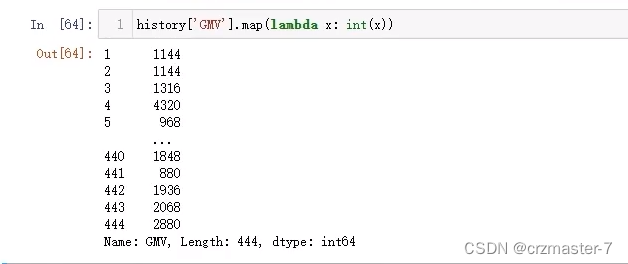
 map中加入字典替换操作,未规定的变成NaN
map中加入字典替换操作,未规定的变成NaN
apply:
axis=1表示行从左往右传数据,不填默认为0从上往下会报错
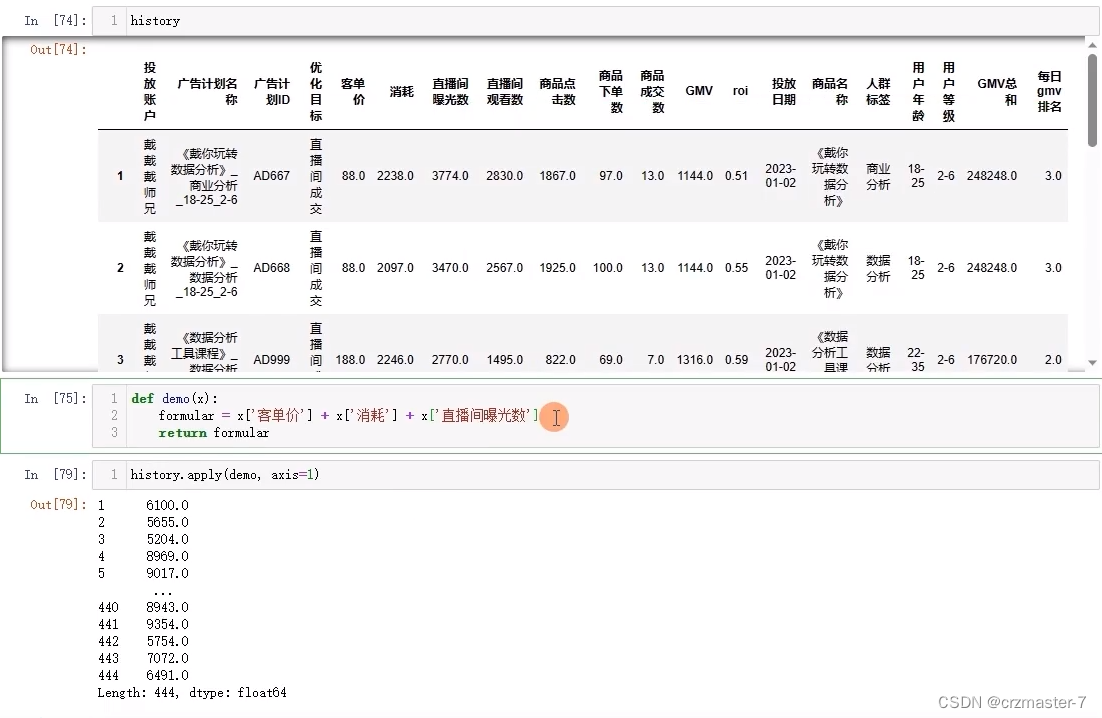
当返回值还需要和形参计算时如图:apply中加入args(,)

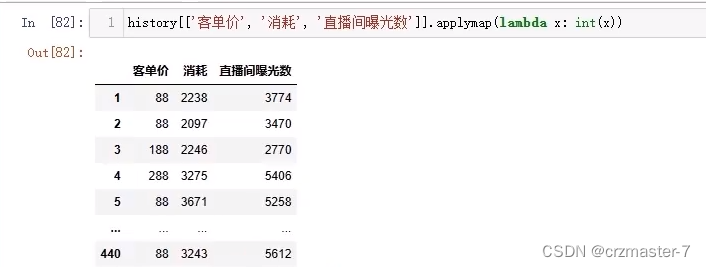
applymap:
一个一个的传入数据