
- 1《Python编程 从入门到实践》第十四章练习题14-2答案_python人马大战csdn
- 2《Graph Neural Networks: A Review of Methods and Applications》图网络综述 -- 解析笔记_jie zhougraph neural networks: a review of methods
- 320个OpenCV案例,让你了解计算机视觉的广泛应用!
- 4C#Windows窗体设计之ContextMenuStrip(鼠标右击菜单)的用法_c# contextmenustrip
- 5【AI视野·今日CV 计算机视觉论文速览 第292期】Thu, 18 Jan 2024_change detection between optical remote sensing im
- 6(五)比赛中的CV算法(下)目标检测终章:Vision Transformer_为什么不用vision transformer 做bacbone 进行目标检测
- 7Python 使用TF-IDF_python tf-idf向量化模型代码 import tfidfvectorizer as tfi
- 8树莓集团副总裁吴晓平参与2024云南生活方式医学健康管理启动大会
- 9树莓派中SIM7600G-H 4G DONGLE模块使用记录(一)PPP拨号上网/4G上网
- 10python gensim[word2vec & doc2vec]基本操作_"model.train([[\"hello\", \"world\"]], total_examp
paddleocr - 模型效果对比与推理_paddleocr推理模型和训练模型区别
赞
踩
模型效果对比
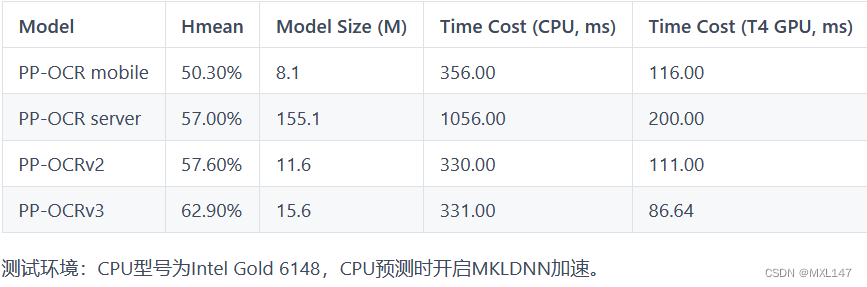
(1)PP-OCR
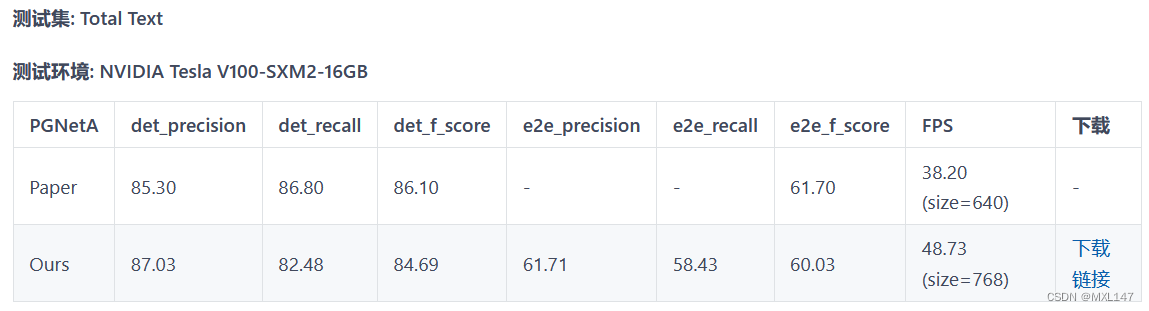
(2)端对端-PGNet
模型思路对比
1、PP-OCR
参考:doc/doc_ch/PP-OCRv3_introduction.md · PaddlePaddle/PaddleOCR - Gitee.com
(1)PP-OCR:两阶段的OCR系统,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器.
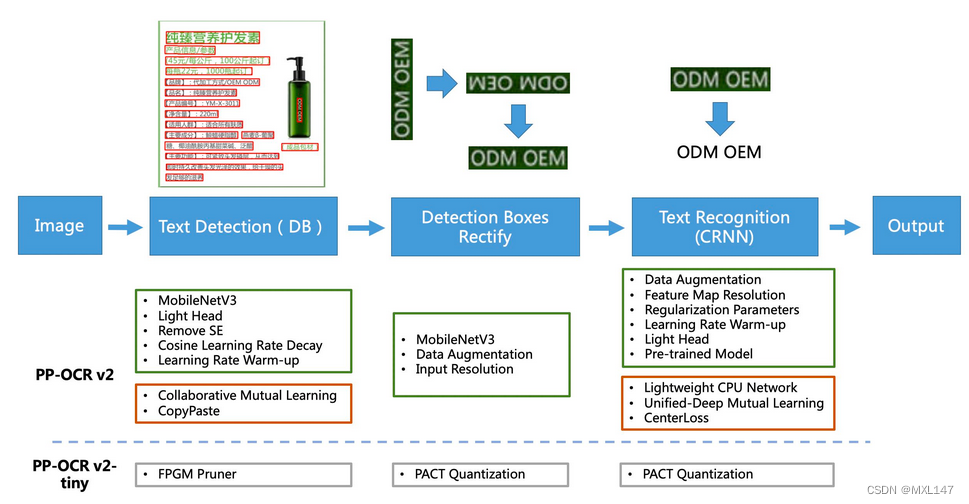
(2)PP-OCRv2:基于PP-OCR在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。
(3)PP-OCRv3:基于PP-OCRv2在9个方面进行升级。

2、PGNet
参考:doc/doc_ch/algorithm_e2e_pgnet.md · PaddlePaddle/PaddleOCR - Gitee.com
端对端OCR算法包括MaskTextSpotter系列、TextSnake、TextDragon、PGNet系列等。在这些算法中,PGNet算法具备其他算法不具备的优势,包括:
(1)设计PGNet loss指导训练,不需要字符级别的标注
(2)不需要NMS和ROI相关操作,加速预测
(3)提出预测文本行内的阅读顺序模块;
(4)提出基于图的修正模块(GRM)来进一步提高模型识别性能
(5)精度更高,预测速度更快
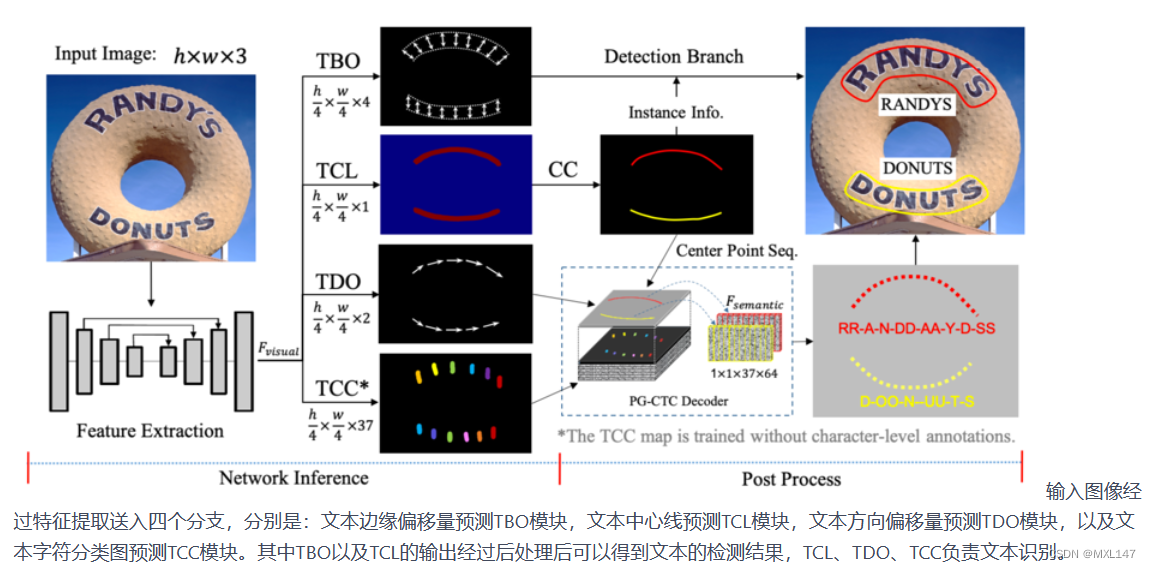
模型下载地址与配置文件
1、PP-OCR
doc/doc_ch/models_list.md · PaddlePaddle/PaddleOCR - Gitee.com

训练模型:可作为预训练模型在自己的数据集上训练新模型
推理模型:直接进行推理,观察识别效果
2、PGNet
预训练模型下载:
- cd PaddleOCR/
- 下载step1 预训练模型
- wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/train_step1.tar
- 可以得到以下的文件格式
- ./pretrain_models/train_step1/
- └─ best_accuracy.pdopt
- └─ best_accuracy.states
- └─ best_accuracy.pdparams
推理模型下载:
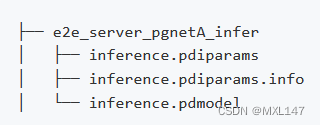
- mkdir inference && cd inference
- # 下载英文端到端模型并解压
- wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/e2e_server_pgnetA_infer.tar && tar xf e2e_server_pgnetA_infer.tar
配置文件:configs/e2e/e2e_r50_vd_pg.yml
配置文件的参数介绍:doc/doc_ch/config.md · PaddlePaddle/PaddleOCR - Gitee.com
推理模型使用
1、PP-OCR
命令行使用参考:doc/doc_ch/quickstart.md · PaddlePaddle/PaddleOCR - Gitee.com
源码使用参考:PaddleOCR/quickstart.md at static · PaddlePaddle/PaddleOCR · GitHub
git clone https://github.com/PaddlePaddle/PaddleOCR.git新建inference文件夹,将下载的推理模型放进来并解压:

(1)测试下det推理模型的效果:
python tools/infer/predict_det.py --image_dir doc/imgs/00111002.jpg --det_model_dir inference/ch_ppocr_server_v2.0_det_infer结果存储在inference_results下:det_res_00111002.jpg和det_results.txt

![]()
(2)测试下cls推理模型的效果:
python tools/infer/predict_cls.py --image_dir doc/imgs_words/ch/word_4.jpg --cls_model_dir inference/ch_ppocr_mobile_v2.0_cls_infer结果:Predicts of doc/imgs_words/ch/word_4.jpg:['0', 0.9999982]
第一个是角度,第二个是置信度
(3)测试下rec推理模型的效果:
python tools/infer/predict_rec.py --image_dir doc/imgs_words/ch/word_4.jpg --rec_model_dir inference/ch_ppocr_server_v2.0_rec_inferppocr INFO: Predicts of doc/imgs_words/ch/word_4.jpg:('交自活具', 0.2635100483894348)
第一个是文字结果,第二个是置信度
(4)综合起来
- python tools/infer/predict_system.py --image_dir doc/imgs/00111002.jpg \
- --det_model_dir inference/ch_ppocr_server_v2.0_det_infer/ \
- --rec_model_dir inference/ch_ppocr_server_v2.0_rec_infer/ \
- --cls_model_dir inference/ch_ppocr_mobile_v2.0_cls_infer/ \
- --use_angle_cls True \
- --use_space_char True
结果存储在inference_results下:00111002.jpg和system_results.txt
![]()
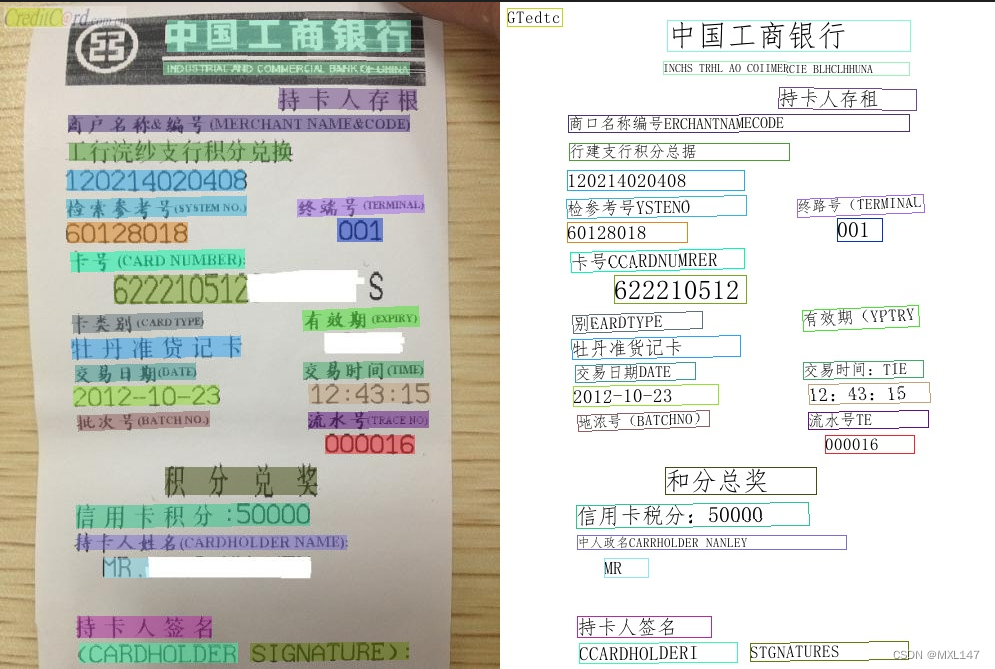
2、PGNet
- # 预测image_dir指定的单张图像
- python3 tools/infer/predict_e2e.py --e2e_algorithm="PGNet" --image_dir="./doc/imgs_en/img623.jpg" --e2e_model_dir="./inference/e2e_server_pgnetA_infer/" --e2e_pgnet_valid_set="totaltext"
-
- # 预测image_dir指定的图像集合
- python3 tools/infer/predict_e2e.py --e2e_algorithm="PGNet" --image_dir="./doc/imgs_en/" --e2e_model_dir="./inference/e2e_server_pgnetA_infer/" --e2e_pgnet_valid_set="totaltext"
-
- # 如果想使用CPU进行预测,需设置use_gpu参数为False
- python3 tools/infer/predict_e2e.py --e2e_algorithm="PGNet" --image_dir="./doc/imgs_en/img623.jpg" --e2e_model_dir="./inference/e2e_server_pgnetA_infer/" --e2e_pgnet_valid_set="totaltext" --use_gpu=False

