
- 1Verilog实现序列信号发生器_序列信号发生器verilog
- 2DB-GPT、ChatGLM3-6B全精度部署
- 3uniapp微信小程序动态更新scroll-view标签的高度_uniapp 获取组件scrollheight
- 4千言数据集:文本相似度—— 训练中文词向量_中文词向量数据集
- 5基于WSL2+Docker+VScode搭建机器学习(深度学习)开发环境_wsl docker
- 6机器学习人工智能算法——支持向量机(Support Vector Machine, SVM)_人工智能负荷预测支持向量机法属于什么类型
- 7HarmonyOs开发之———容器组件使用
- 8python实现自顶向下的句法分析和基于CYK算法的句法分析_cyk算法python实现
- 9rabbitmq 报错解决_org.springframework.amqp.rabbit.support.listenerex
- 10【无监控,不运维】监控之Prometheus_prometheus 监控pod流量
Amazon Aurora PostgreSQL 长运行时间查询管理
赞
踩


点击上方入口立即【自由构建 探索无限】
一起共赴年度科技盛宴!
前言
Amazon Aurora PostgreSQL 兼容版
(https://aws.amazon.com/cn/rds/aurora/features/) 集群由一个主/写入器节点和一个区域中多达15个读取器节点组成。您可以将只读工作负载卸载到读取器节点以进行横向扩展读取。如果读取器节点正在访问主节点上具有大量事务活动的表,则在读取器节点上长时间运行的查询可能会导致冲突,并导致不良影响。
本篇文章中,我们将探讨潜在的冲突,并分享在 Aurora PostgreSQL 上管理长时间运行的读取查询的最佳实践。
Amazon RDS 和 Aurora
之间的存储区别
在 Amazon Relational Database Service(Amazon RDS)for PostgreSQL
(https://aws.amazon.com/cn/rds/postgresql/) 中,每个只读副本实例都有自己的独立数据库副本,通过从主节点进行物理复制来保持同步。相比之下,Aurora PostgreSQL 中有一个由分布式存储引擎管理的单一共享数据库,该引擎冗余地存储在每个数据库计算实例所连接的六个存储节点上。下图显示了这两种方法的根本区别。
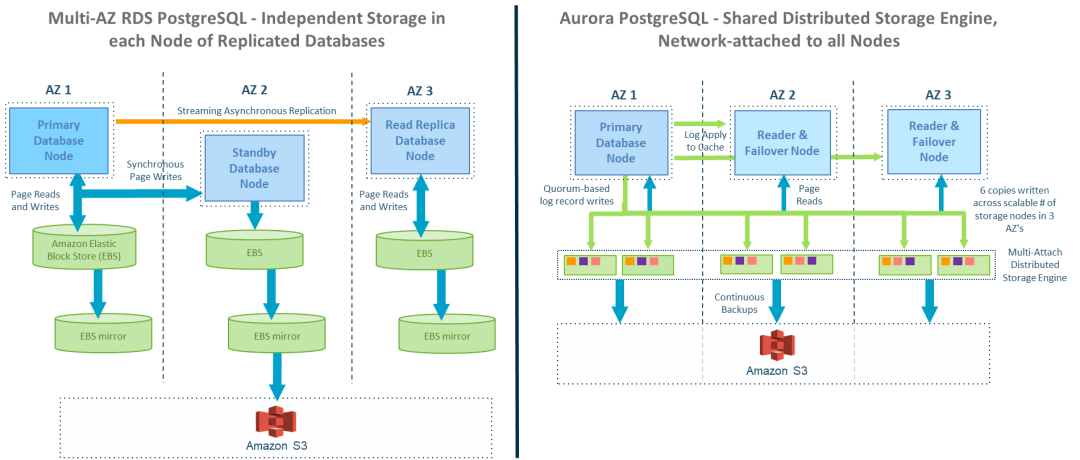
Aurora 的共享存储模型具有许多优点,例如启动新读取器节点的时间极短,因为新实例只需通过网络连接到现有存储节点。但是,使用这种方法,与 Amazon RDS for PostgreSQL 相比,Aurora PostgreSQL 必须使同一页面的不同读取器节点的缓存副本更紧密地保持同步,因为 Aurora PostgreSQL 集群的所有节点只共享数据库的一个物理副本。
长时间运行的查询
对 Aurora 读取器节点的影响
Aurora 主节点上的正常 DML 操作(如插入、更新和删除)会生成事务日志记录,这些记录除了发送到所有 Aurora 存储节点外,还会发送到集群中的所有 Aurora 读取器节点,以防任何读取器节点在其自己的缓冲区中拥有同一页面的副本缓存。在上图中,这些是从主节点到读取器节点的缓存更新数据流。如果读取器节点在内存中没有页面缓冲区,则会忽略这些日志记录;否则,一旦提交,就会按事务顺序处理这些日志记录。无论是在主节点还是读取器节点上处理查询,有时都需要在内存中的页面缓冲区上持有内部锁,以确保页面缓冲区内容在其下不会发生变化。这些内部锁通常称为缓冲区引脚,尽管它们是非事务性的,但会影响并发性。
PostgreSQL 在处理主节点本身上的冲突方面往往比较明智,因为它可以理解当时在其上运行的所有查询。例如,如果不同的读取会话在页面缓冲区上持有缓冲区引脚,则主节点上的 PostgreSQL 引擎可以选择跳过页面缓冲区的 autovacuum。但是,主节点忽略了读取器节点中的工作负载和缓冲区缓存内容,因此 Aurora 读取器节点中的一个常见难题是可能会发生冲突,从而阻止及时应用影响内存中页面缓冲区的日志记录。
发生冲突时,如果冲突查询很短,则最好通过延迟在读取器节点上应用日志记录来允许冲突完成。但是,对于读取器节点上长时间运行的查询,允许事务日志应用进程无限期等待将导致读取器节点越来越落后于主节点。为了在运行的查询和高可用性之间取得平衡,当读取器节点上出现阻止应用日志记录的冲突时,Aurora PostgreSQL 会采取以下操作:
延迟在读取器节点上应用日志记录,让读取器节点上的冲突查询完成,然后再应用日志记录。延迟时间量由配置的max_standby_streaming_delay参数值决定。Aurora PostgreSQL 允许将max_standby_streaming_delay配置为长达30秒。如果您正在运行混合的 OLTP 和 OLAP 工作负载,则 OLAP 查询的运行时间可能会超过30秒。这篇博文的目标之一是分享最佳实践,以管理长时间运行的查询并缓解这种情况下的冲突。
如果冲突持续时间超过 max_standby_streaming_delay(最长 30 秒),则取消读取器节点上的冲突查询。这不同于 Amazon RDS 或自我管理的 PostgreSQL。对于 Amazon RDS 或自我管理的 PostgreSQL,实例拥有自己的数据库物理副本,您可以将参数max_standby_streaming_delay设置得尽可能高,以防止查询被取消。
如果无法及时取消冲突查询,或者如果多个长时间运行的查询导致复制延迟超过60秒,Aurora 将重新启动读取器节点,以确保其不会远远落后于主节点。
Aurora 读取器节点中
发生冲突的常见原因
在读取器节点上应用日志记录时,有几种常见情况可能会导致冲突:
快照冲突 — 如果 vacuum 进程删除了主节点上的死元组,并且读取器节点上长时间运行的查询在 vacuum 之前启动并具有较旧的快照,则会发生冲突。
锁定冲突 — 使用 PostgreSQL 的 MVCC 协议,便无需在执行正常的 DML 命令期间锁定内存中的整个页面缓冲区。但是,仍然存在一些影响物理页的较繁重操作,例如 DDL (ALTER TABLE 和 DROP TABLE) , VACUUM FULL, LOCK TABLE, 从关系中截断页面,以及一些 autovacuum 操作(其中,操作必须获取Access Exclusive锁)。该锁随后会生成一个XLOG_STANDBY_LOCK日志记录,这会导致读取器节点获取Access Exclusive锁,从而使其缓冲区缓存中的内存结构失效。
缓冲区引脚冲突 — 当您在主节点上有独占页锁定,而读取器节点上长时间运行的读取查询已固定该页时,就会发生此冲突。
您可以按照这篇文章中的步骤重现锁定冲突场景。
先决条件
在开始操作之前,请务必满足以下先决条件:
一个亚马逊云科技账户。
一个 Aurora PostgreSQL 集群,其中包含一个读取器节点
(https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_GettingStartedAurora.CreatingConnecting.AuroraPostgreSQL.html)。本文中的示例在运行 PostgreSQL v13.6 的 db.r6g.large
(https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.DBInstanceClass.html#Concepts.DBInstanceClass.Types) 上同时部署主节点和读取器节点。
一个客户端环境,设置了与 Aurora 集群的连接。本文中的示例使用 psql 作为客户端工具。
我们假设您熟悉使用 Aurora PostgreSQL 和 PostgreSQL 客户端环境。
生成测试数据
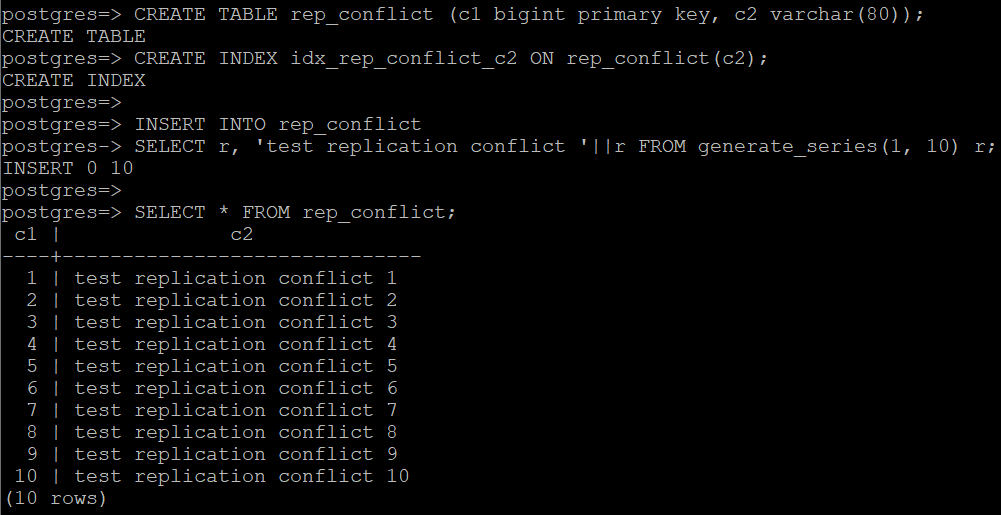
打开与主节点的新 psql 连接,并运行以下代码来创建示例测试数据:
- CREATE TABLE rep_conflict (c1 bigint primary key, c2 varchar(80));
- CREATE INDEX idx_rep_conflict_c2 ON rep_conflict(c2);
-
- INSERT INTO rep_conflict
- SELECT r, 'test replication conflict '||r FROM generate_series(1, 10) r;
-
- SELECT * FROM rep_conflict;
左滑查看更多
以下屏幕截图显示了我们的输出。
验证读取器节点上的
max_standby_streaming_delay
设置
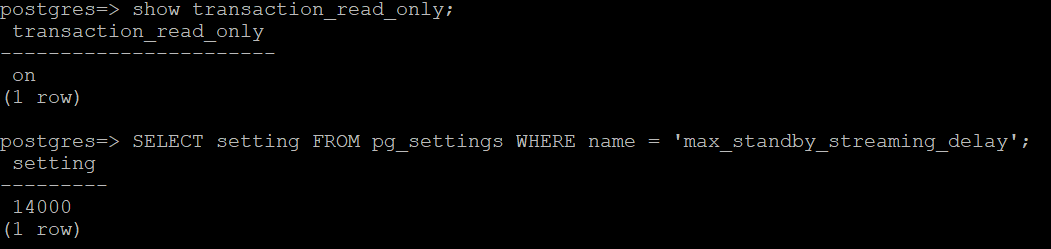
打开与读取器节点的新 psql 连接,然后检查 max_standby_streaming_delay参数设置。不同 Aurora PostgreSQL 版本中的默认值可能有所不同。Aurora PostgreSQL 现在允许您使用自定义的参数组 (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithParamGroups.html)更改默认值。您可以在集群参数组或数据库实例参数组级别上将max_standby_streaming_delay设置为介于 1,000–30,000 毫秒之间的任何值。如果这两个位置均已设置,则集群级别的配置设置优先。
使用以下代码检查参数:
- show transaction_read_only;
- SELECT setting FROM pg_settings WHERE name = 'max_standby_streaming_delay';
左滑查看更多
在此测试中,max_standby_streaming_delay设置为 14,000 毫秒(14 秒)。
运行长时间运行的查询
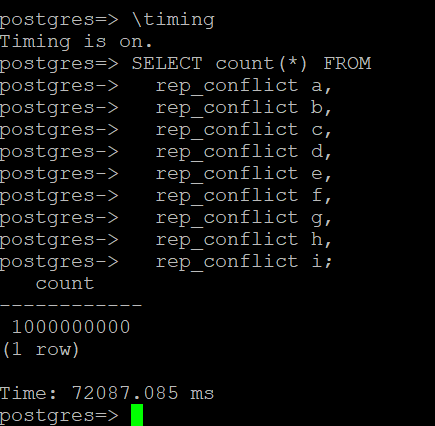
在与 Aurora 读取器节点的现有连接上,启用计时,运行长时间运行的查询,并在没有复制冲突时捕获查询运行时:
- \timing
- SELECT count(*) FROM
- rep_conflict a,
- rep_conflict b,
- rep_conflict c,
- rep_conflict d,
- rep_conflict e,
- rep_conflict f,
- rep_conflict g,
- rep_conflict h,
- rep_conflict i;
在我的带有 db.r6.large 数据库实例的环境中,长时间运行的查询运行了大约 72 秒。
重新运行存在冲突的
长时间运行的查询
在与 Aurora 读取器节点的现有连接上,重新运行上一步中长时间运行的查询。这次,我们从 Aurora 主节点手动生成冲突的 DDL 操作。
- SELECT count(*) FROM
- rep_conflict a,
- rep_conflict b,
- rep_conflict c,
- rep_conflict d,
- rep_conflict e,
- rep_conflict f,
- rep_conflict g,
- rep_conflict h,
- rep_conflict i;
观察主节点上的冲突
在读取器节点上运行长时间运行的查询时,切换到已与 Aurora 主节点建立了连接的会话。运行以下 DROP INDEX 语句并观察读取器节点上的查询会发生什么情况:
DROP INDEX idx_rep_conflict_c2;
查看读取器节点上的错误消息
切换到 Aurora 读取器会话。如果稍等片刻,您应该会看到一条类似于以下屏幕截图的错误消息。
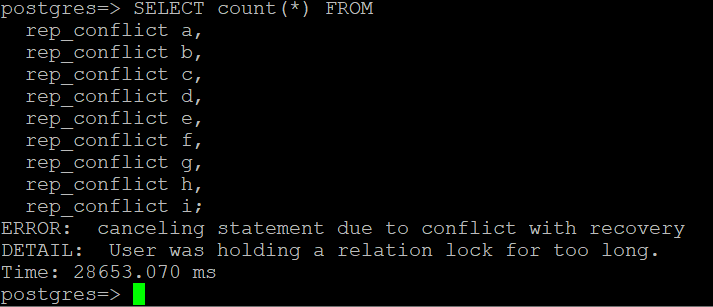
主节点上的 DROP INDEX 操作影响了 Aurora 共享存储上的物理页。当事务日志记录应用于读取器节点时,它会导致读取器节点获取Access Exclusive锁,从而使其缓冲区缓存中的内存结构失效。但是,现有的长时间运行的查询已固定内存页。DROP INDEX 操作已导致锁定冲突。在该场景中,Aurora PostgreSQL 在取消查询之前等待了 14 秒(配置了max_standby_streaming_delay值)才完成查询。
注意事项和最佳实践
现在,您已对 Aurora 共享存储架构和导致冲突的场景有了更好的了解,可以采取措施来管理长时间运行的查询,以避免或主动处理冲突情况。以下是可供考虑的选项:
查询调优 – 调整读取器节点上的查询,使其在达到 max_standby_streaming_delay之前完成。在 OLTP 系统上,查询通常会在短时间内返回结果。缺少索引可能会导致意外的长时间运行的查询。如果您不希望查询运行超过30秒,则应在读取器节点上将 statement_timeout (https://postgresqlco.nf/doc/en/param/statement_timeout/) 和 log_min_error_statement (https://postgresqlco.nf/doc/en/param/log_min_error_statement/) 的数据库参数设置为 ERROR 或更低,以便主动取消任何失控的查询,并将查询语句记录在 PostgreSQL 日志中以便后期调优。
实施表分区 – 如果表较大,可以考虑使用表分区 (https://aws.amazon.com/cn/blogs/database/improve-performance-and-manageability-of-large-postgresql-tables-by-migrating-to-partitioned-tables-on-amazon-aurora-and-amazon-rds/)来缩短查询运行时间。分区查询修剪可以减少 Aurora PostgreSQL 需要为查询处理的数据量,并提高查询性能。
实施手动 vacuum – 如果您正在运行混合的 OLTP 和 OLAP 工作负载(包括在读取器节点上长时间运行的查询),则考虑关闭 autovacuum 并设置操作方法(如 pg_cron),以便在一天中的适当时间或周末手动运行 vacuum(当工作负载量允许时)。
在应用程序中实施重试逻辑 – 复制冲突的发生取决于主节点上发生的操作的性质,以及读取器节点上正在运行的内容。被取消的查询如果再次提交,则很可能会成功运行。您应在应用程序中实施重试逻辑 (https://aws.amazon.com/cn/builders-library/timeouts-retries-and-backoff-with-jitter/),以捕获正被取消的查询并重新提交该查询。您还应具备应用程序逻辑,以便在连接失败时重新连接并重新提交查询。
将查询重定向到 Aurora 主节点 – 为避免长时间运行的读取查询被强制取消或导致 Aurora 读取器意外重启,您可以将查询重定向到主节点。当查询在主节点上运行并长时间持有资源时,其他会话可能会导致等待。但是,除非您采取措施取消查询,否则查询将完成。
将查询卸载到 Aurora 快速克隆 – 您可以考虑使用 Aurora 快速数据库克隆(https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html#Aurora.Clone.Overview) 功能创建数据库的克隆。无需访问实时生产数据的长时间运行的查询可能会卸载到 Aurora 克隆(例如,用于生成季度报告的查询)。
将查询拆分为多个较小的查询 – 将复杂的长时间运行的查询分解为多个较短和较小的查询,这样可以更好地利用应用程序层的水平可扩展性,并将查询分发到多个应用程序实例。
让您的环境保持最新 – PostgreSQL 社区和 Amazon 不断努力进行增强和修复错误,以缓解冲突。例如,PostgreSQL v14 添加了参数 client_connection_check_interval (https://www.postgresql.org/docs/14/runtime-config-connection.html#GUC-CLIENT-CONNECTION-CHECK-INTERVAL),使您能够在客户端断开连接时尽快中止长时间运行的查询,并添加了参数 idle_session_timeout (https://www.postgresql.org/docs/current/runtime-config-client.html#RUNTIME-CONFIG-CLIENT-STATEMENT) 来关闭空闲会话。Aurora PostgreSQL v12.9 和 v13.5(及更高版本)添加了一项优化,以便尽可能减少在缓冲区引脚冲突情况下取消某些运行时间超过 max_standby_streaming_delay 的查询的需求。有关增强功能的更多信息,请参阅 Amazon Aurora PostgreSQL 更新(https://docs.aws.amazon.com/AmazonRDS/latest/AuroraPostgreSQLReleaseNotes/AuroraPostgreSQL.Updates.html)。强烈建议您使 Aurora 环境在最新的次要版本中保持最新。
在工作负载量较小或对取消查询的容忍度更高的情况下,继续运行繁重的维护操作(如 vacuum 或 DDL)非常重要。
结论
在这篇文章中,我们讨论了在 Aurora 读取器节点上长时间运行读取查询的常见场景,这些场景可能会导致与 Aurora 主节点上的 DML 和 DDL 操作发生冲突。我们分享了主动管理长时间运行的读取查询并减轻潜在冲突影响的最佳实践。
我们欢迎您提供反馈。请在评论中分享您的经验和任何问题。
既然您正在阅读这篇文章,您可能还对以下内容感兴趣:
通过迁移到 Amazon Aurora 和 Amazon RDS 上的分区表,提高大型 PostgreSQL 表的性能和可管理性
(https://aws.amazon.com/cn/blogs/database/improve-performance-and-manageability-of-large-postgresql-tables-by-migrating-to-partitioned-tables-on-amazon-aurora-and-amazon-rds/)
本篇作者

Wanda He
亚马逊云科技的高级数据库专业解决方案架构师。她与客户合作设计、部署和优化 Amazon 上的关系数据库。

Avi Jain
亚马逊云科技技术基准测试团队的高级产品经理。他领导团队对使用 Amazon 技术产品和服务的端到端客户体验(CX)进行评估、衡量并推动改善。

点击上方【立即报名】
直通大咖云集的亚马逊云科技中国峰会!

听说,点完下面4个按钮
就不会碰到bug了!
![[ 云计算 | AWS 实践 ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全](https://img-blog.csdnimg.cn/direct/f6b4b45ef01445aa9a147e7c5f1a8f15.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

