
- 1Caused by: javax.transaction.RollbackException: Transaction set to rollback only
- 2【Transformer系列(4)】Transformer模型结构超详细解读_transformer结构
- 3数学建模篇---2022国赛C题(二)(全程python,完整论文和代码可取!)_2022国赛国二论文c题
- 4鸿蒙开发实战--DevEco Studio真机调试方法_deveco studio 真机调试
- 5SpringBoot整合短信验证码_spring工程融合验证码
- 6机器学习(复试)
- 7Paddle OCR 常用cmd命令_cmd脚本启动ocr
- 8QGIS下载卫星影像全攻略_qgis导出卫星图像
- 9Python 自然语言处理笔记(五)——信息检索系统,基于Lucene实现_自然语言处理信息检索系统
- 10MySQL数据库连接失败,报错:ERROR 1040 (HY000): Too many connections_mysql 1040
YOLOv5和OpenCV的金属缺陷检测系统(源码和部署教程)_yolov5缺陷检测
赞
踩
1.研究背景与意义
随着工业化的快速发展,金属制品在各个领域的应用越来越广泛。然而,由于金属材料的特殊性质,例如易受腐蚀、疲劳、热胀冷缩等,金属制品在使用过程中容易出现各种缺陷,如裂纹、气孔、夹杂物等。这些缺陷不仅会降低金属制品的强度和耐久性,还可能导致严重的事故和损失。因此,金属缺陷检测成为了工业生产中非常重要的一环。
传统的金属缺陷检测方法主要依赖于人工目视检测,这种方法存在着许多问题。首先,人工目视检测需要大量的人力资源,费时费力。其次,人的视觉判断容易受到主观因素的影响,导致检测结果的不准确性和不一致性。此外,人眼对于微小的缺陷很难察觉,因此可能会漏检一些潜在的缺陷。因此,开发一种高效、准确、自动化的金属缺陷检测系统具有重要的意义。
近年来,计算机视觉技术的快速发展为金属缺陷检测提供了新的解决方案。特别是基于深度学习的目标检测算法,如YOLO(You Only Look Once)系列算法,已经在图像识别和目标检测领域取得了显著的成果。这些算法通过训练神经网络模型,可以实现对图像中目标的自动检测和定位。而OpenCV作为一个开源的计算机视觉库,提供了丰富的图像处理和分析工具,可以方便地与深度学习算法结合使用。
基于OpenCV和YOLOv5的金属缺陷检测系统可以利用计算机视觉技术的优势,实现对金属制品中的缺陷进行自动化检测。首先,通过使用OpenCV库中的图像处理和分析工具,可以对金属制品的图像进行预处理,如去噪、增强对比度等,以提高后续目标检测算法的准确性。然后,利用YOLOv5算法训练一个深度学习模型,该模型可以对金属缺陷进行自动检测和定位。最后,通过将模型应用于实际的金属制品图像中,可以实现对金属缺陷的快速、准确的检测。
该金属缺陷检测系统具有以下几个重要的意义。首先,它可以大大提高金属缺陷检测的效率和准确性,减少人力资源的消耗。其次,由于该系统是自动化的,可以避免人为因素对检测结果的影响,提高检测结果的一致性和可靠性。此外,该系统还可以检测到人眼难以察觉的微小缺陷,从而提前发现潜在的问题,避免事故和损失的发生。最后,该系统的开发和应用将推动计算机视觉技术在金属缺陷检测领域的发展,为工业生产提供更加可靠和高效的解决方案。
综上所述,基于OpenCV和YOLOv5的金属缺陷检测系统具有重要的研究背景和意义。通过结合计算机视觉技术和深度学习算法,该系统可以实现对金属制品中缺陷的自动化检测,提高检测效率和准确性,减少人力资源的消耗,避免事故和损失的发生。该系统的研究和应用将推动金属缺陷检测技术的发展,为工业生产提供更加可靠和高效的解决方案。
2.图片演示
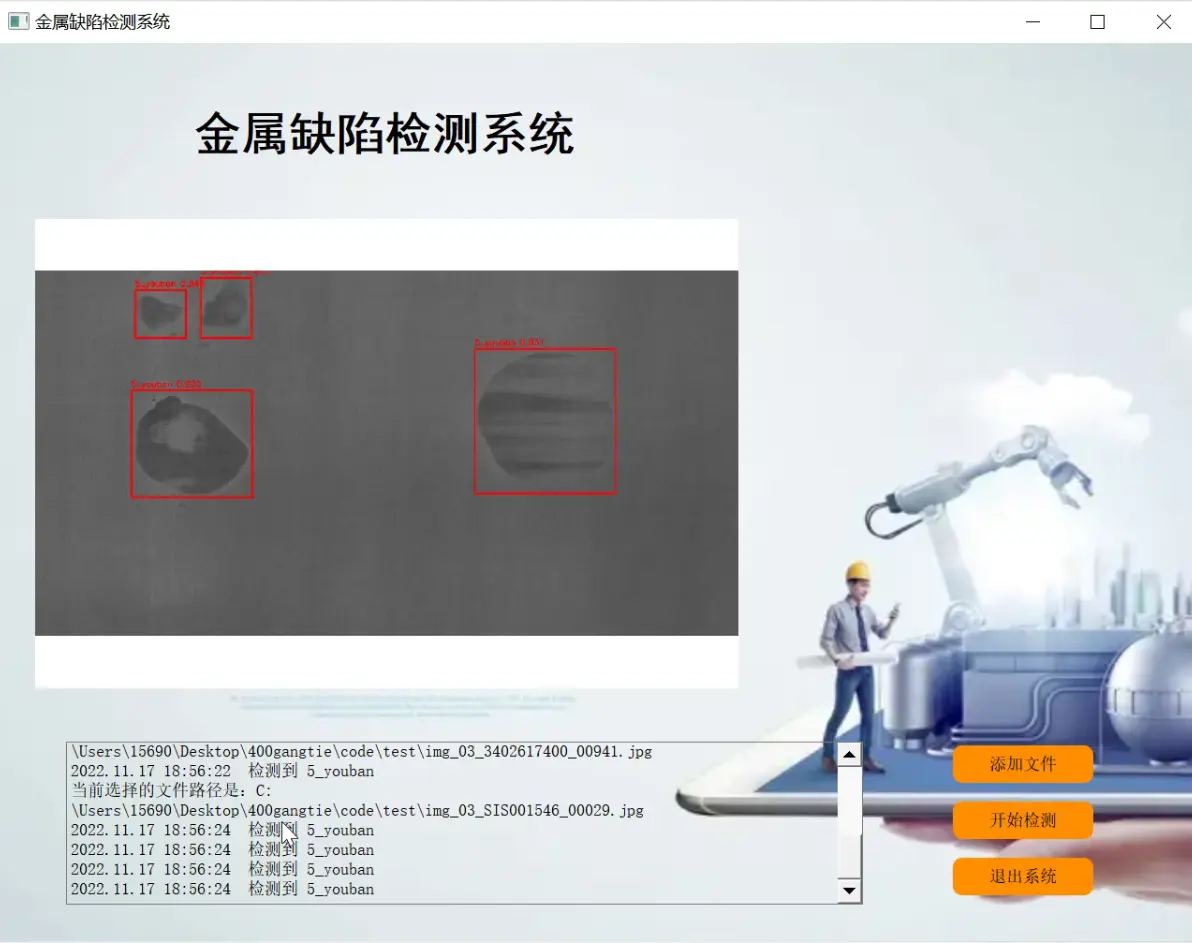
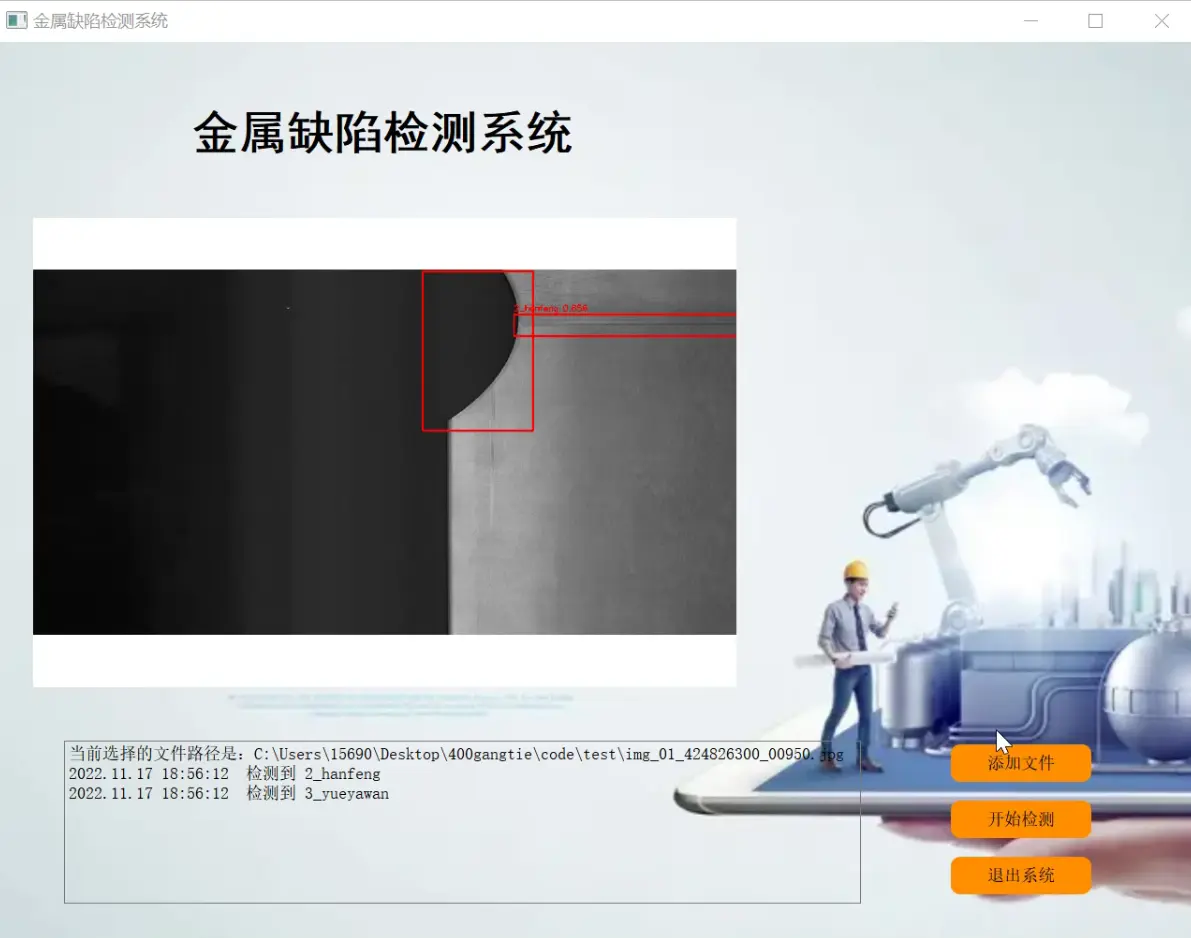
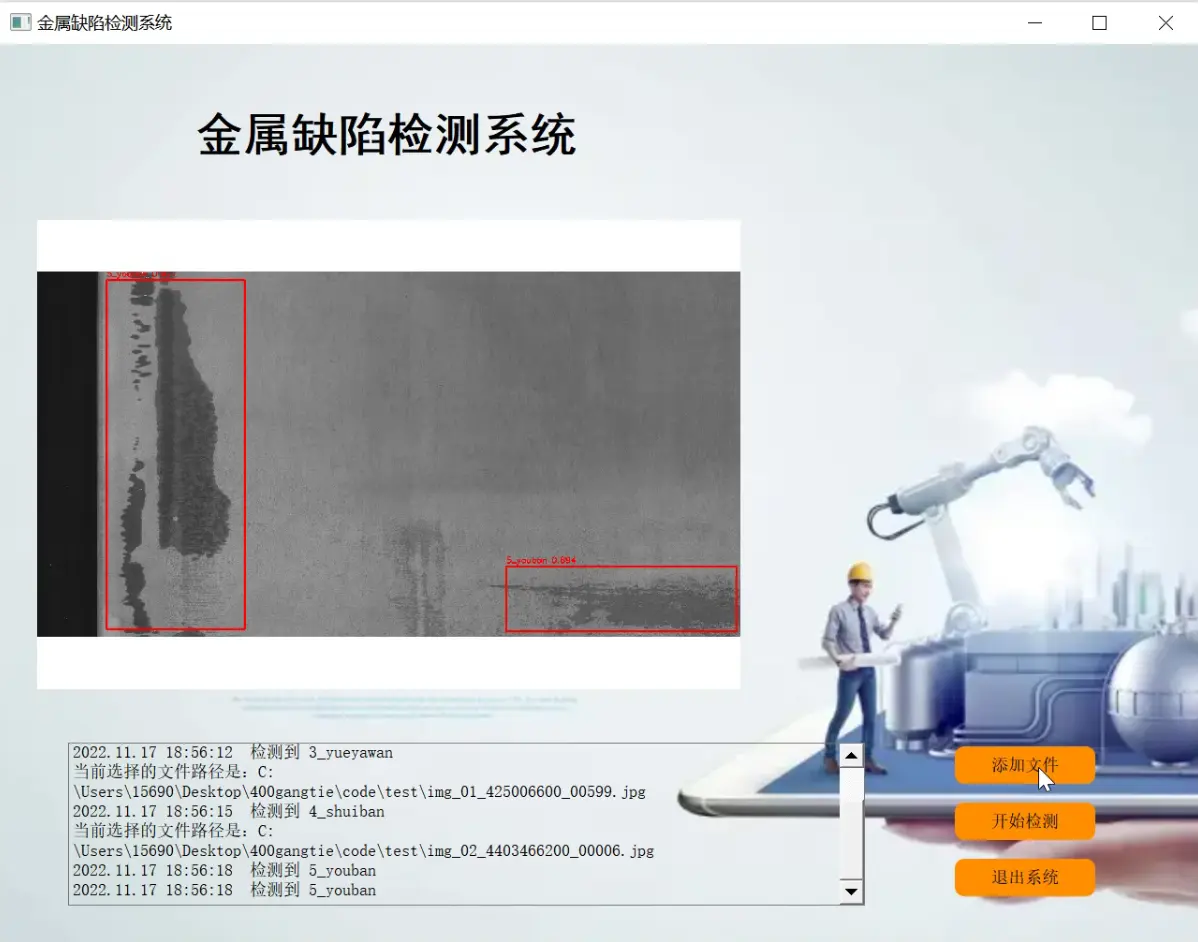
3.视频演示
YOLOv5和OpenCV的金属缺陷检测系统(源码和部署教程)_哔哩哔哩_bilibili
4.YOLOv5 算法关键点分析
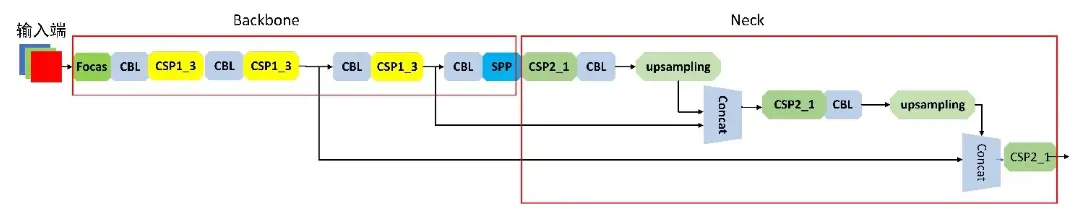
在YOLOv5的输人端中共有下列几个关键点:
(1)数据增强:YOLOv5采用了Mosaic数据增强的方式,通过采用4张图片随机缩放、随机裁剪、随机排布的方式进行拼接,大大丰富了检测数据集Mosaic增强训练时,可以直接计算4张图片的数据,且只需要一个GPU就可以达到比较好的预期效果。
(2)自适应锚框:在YOLO算法中针对不同的数据集,都会有初始设定长宽的锚框。YOLOv5中将外部计算锚框的方式嵌到代码中,每次训练时它能够自适应地计算不同训练集中的最佳锚框值。
(3)自适应图片缩放:在常用的目标检测中,输入的图片长宽比并不统一,YOLOv5为改进此问题,在源码中加入填充功能,针对小的原始图进行黑边填充,大的原始图进行缩放,之后变为统一的图像标准,减少了人力操作,提高了效率。

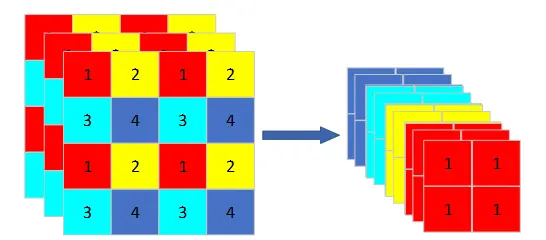
在Backbone 中 , YOLOv5增加了在之前YOLO版本中没有的Focus结构,其关键操作是将图片切片"",如图1所示。其主要作用是从高分辨率的图中,呈周期性地抽出像素点进行重构,组成低分辨率图像,提升每个视野的感受点,减少原图信息的丢失。可在没有参数的情况下将输入维度进行下采样,最大限度地保留原有信息,减少计算量,增加检测速度。
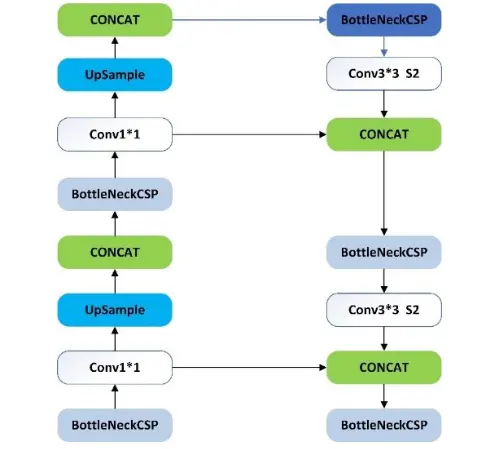
Neck 用于形成特征金字塔(Feature PyramidNetworks , FPN)"7l,特征金字塔可增强网络对不同尺寸的图像的检测,进而识别不同大小和尺度的同一物体,路径聚合网络(Perceptual Adversarial Network ,PAN)如图5所示ll’。YOLOv5采用了FPN+PAN结构,此结构主要加强了信息传播,使得网络能检测到更细微的原图信息,在目标识别上得到更高的精度。
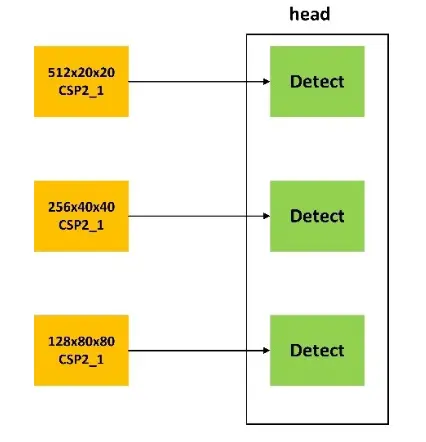
Head模块如图6所示,其作用在最终检测,它在输入的检测图像上生成锚定框,在框上生成检测出的类别以及识别的准确度。
5.算法改进
5.1 自适应锚框改进
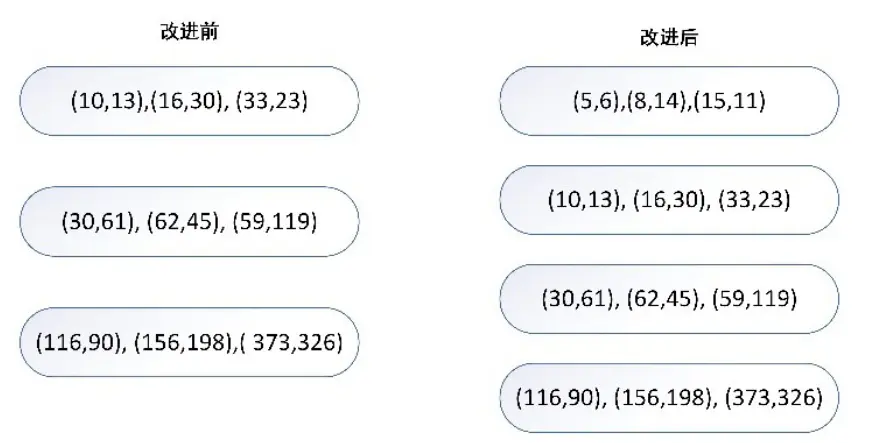
在实际应用中,由于YOLOv5自带的计算锚框只有9个检测框,在遇到不符合锚框尺寸的更细微的小缺陷时很可能会造成漏检、误检。参考该博客提出的改进方法,通过外部重新计算,重新进行anchor box个数及尺寸确定。而使用算法选取k-means聚类算法,通过自制数据集上的标注目标框信息( ground truth),手动计算最适合的自适应锚框个数及锚框尺寸,可增加检测的准确率及检测的效率。
在金属表面缺陷检测任务中,进行聚类是为了使anchor box 与 ground truth 的IOU越大越好,所以不可采用平常聚类方法的欧式距离来计算,应采用1OU作为度量函数进行计算。新公式如下:
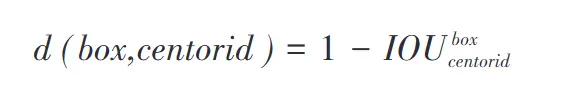
anchor box个数K与IOU(交并比)的关系曲线如图7所示。数据集的IOU与K成正相关,在K为10~12.5时逐渐趋于平稳,故本文选择K =122。在原有9个检测框的情况下又增加了3个尺寸更小的检测框,用来针对最大图片中的小目标缺陷,使检测更准,图8所示为增加前后锚框尺寸对比。
5.2 增加小目标检测层
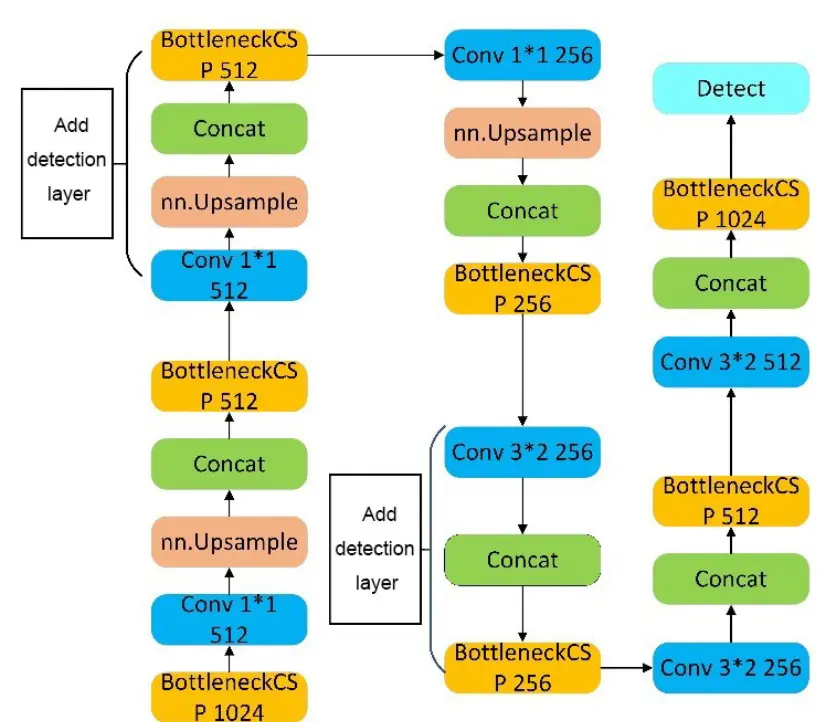
参考该博客的代码,在训练阶段,针对金属表面小目标缺陷检测准确度不够,将特征提取进行增强,在原有特征提取层中,继续增加了3个特征提取层,使算法在20 ×20、40 ×40、80 × 80和160 × 160共4类特征尺度上进行特征提取。首先,分别针对20 ×20、40 x40、80× 80尺寸的特征图进行特征提取,它们的感受视野分别为大、中、小,在 head 中得到小型特征图后,继续对输入特征图进行上采样等处理,使得特征图继续扩大,获得大小为160 × 160的特征图,将其与骨干网络中第2层特征图进行concat融合,以此获取更大的特征图进行金属表面缺陷小目标检测。之后继续进行中型图的特征提取,再进行小型图的特征提取。图9所示为修改后的MODEL层结构。
6.金属表面缺陷检测流程
综合以上分析,配合当前效果较优的图像处理手段,结合现有的摄像头拍摄到待检测的金属表面图,得到检测金属表面伤痕具体位置的完整方案,具体检测流程如下:
(1)相机获取到金属表面图片,进行归一化处理后,记录原图。
(2)图像定位:对图片中待检测的区域进行设置,标注出检测的位置。
(3)图像预处理将图像灰度值改变为(0,255),将图片灰度归一化,去噪(高斯滤波)。
(4)输入训练数据,采用更改后的代码(YOLOv5m_modify)进行训练,得到训练权重。
(5)输人测试数据到检测网络中,采用步骤(4)得到的权重进行检测。
(6)输出检测图像,得到缺陷位置及准确度。
7.核心代码讲解
7.1 detect.py
class YOLOv5Detector: def __init__(self, weights, source, data, imgsz, conf_thres, iou_thres, max_det, device, view_img, save_txt, save_conf, save_crop, nosave, classes, agnostic_nms, augment, visualize, update, project, name, exist_ok, line_thickness, hide_labels, hide_conf, half, dnn): self.weights = weights self.source = source self.data = data self.imgsz = imgsz self.conf_thres = conf_thres self.iou_thres = iou_thres self.max_det = max_det self.device = device self.view_img = view_img self.save_txt = save_txt self.save_conf = save_conf self.save_crop = save_crop self.nosave = nosave self.classes = classes self.agnostic_nms = agnostic_nms self.augment = augment self.visualize = visualize self.update = update self.project = project self.name = name self.exist_ok = exist_ok self.line_thickness = line_thickness self.hide_labels = hide_labels self.hide_conf = hide_conf self.half = half self.dnn = dnn def run(self): source = str(self.source) save_img = not self.nosave and not source.endswith('.txt') # save inference images is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS) is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://')) webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file) if is_url and is_file: source = check_file(source) # download # Directories save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run (save_dir

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
这个程序文件是YOLOv5的推理程序,用于在图像、视频、目录、流等上运行推理。
程序首先解析命令行参数,包括模型路径、输入源、数据集路径、推理尺寸、置信度阈值、NMS IOU阈值等。然后加载模型和数据集,并进行推理。推理过程中,程序会对每个输入进行预处理,然后通过模型进行推理,得到预测结果。然后对预测结果进行非最大抑制处理,去除重叠的边界框。最后,程序会根据需要保存结果到文件或显示结果。
程序还提供了一些可选的功能,如保存结果到文本文件、保存裁剪的预测框、隐藏标签和置信度等。
整个程序的主要逻辑是在run函数中实现的,main函数用于解析命令行参数并调用run函数。
程序的入口是if __name__ == "__main__":,在这里解析命令行参数并调用main函数开始执行程序。
7.2 Interface.py
class YOLOv5Detector: def __init__(self, weights, data, device='', half=False, dnn=False): self.weights = weights self.data = data self.device = device self.half = half self.dnn = dnn self.model = None self.stride = None self.names = None self.pt = None self.jit = None self.onnx = None self.engine = None def load_model(self): # Load model device
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

