
- 1【字节跳动】职级、薪酬、绩效全认知_职级3-1是什么意思
- 2【java】仿级联查询 | Java通过DSL字符串查询ES (es8 dsl java)_java dsl
- 3openstack 查看_软件定义存储之ScaleIO,OpenStack环境部署使用
- 4自适应直方图均衡化(CLAHE)
- 5Video.js使用教程一(详解)
- 6Python_调用/usr/bin下python解释器,来指定脚本用什么解释器来执行
- 7stm32启动代码详细分析记录_stm32 启动代码 实现|c语言
- 8http协议入门之 SameSite cookies_http2.0会有samesite
- 9Coco数据集中的rle格式处理_coco rle
- 102024华为OD机试真题指南宝典—持续更新(JAVA&Python&C++&JS)【彻底搞懂算法和数据结构—算法之翼】
上手机器学习系列-第5篇(上)-XGBoost_agaricus.txt.train
赞
踩
引言
在第4篇中我们简要介绍了GBDT的使用方法,本篇来聊一种进阶的GBDT-XGBoost,这是一款极其优秀的算法解决方案,项目官方网站:https://xgboost.readthedocs.io/en/latest/。
XGBoost本身最大的优势就在于它在工程上做了大量的工作,使得该算法可以广泛应用到不同的生态中(python、spark、C++等)。
Python + XGBoost
对官方DEMO的解剖
以下是XGBoost官网上给出来的一个DEMO代码:
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train')
dtest = xgb.DMatrix('demo/data/agaricus.txt.test')
# specify parameters via map
param = {
'max_depth':2, 'eta':1, 'objective':'binary:logistic' }
num_round = 2
bst = xgb.train(param, dtrain, num_round)
# make prediction
preds = bst.predict(dtest)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里的数据集显然是需要从xgboost软件附带的文件去下载,可以按照官网上说的那样把整个xgboost都git clone到本地(但这个有时候会因为网速的原因,不一定能顺利下载到),也可以到github上(https://github.com/dmlc/xgboost/tree/master/demo/data)去找到对应的目录下的数据,直接复制粘贴到本地文件中,反正怎么高效怎么来。
首先关注一下数据集的格式:
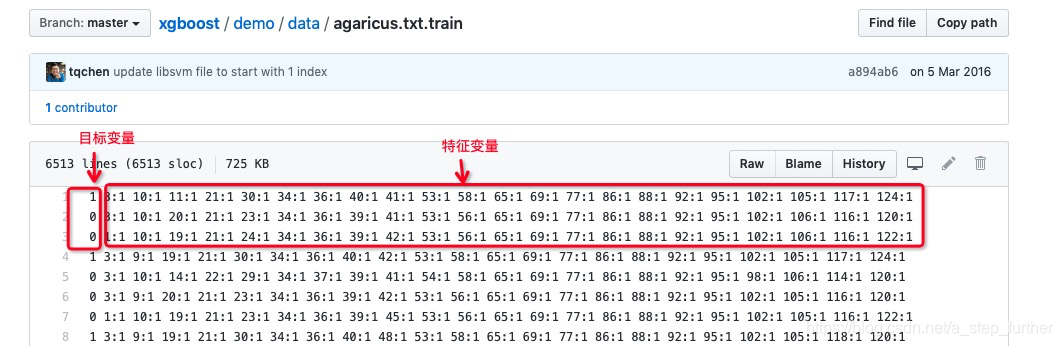
显然,这是已经预处理好的很干净的数据。第一列是目标变量(这一点跟很多数据集不同,一般情况下目标变量是在最后一列,不过没关系,核心还是要看读取数据时是怎么操作的,只要能正确解析就行,一会我们再去看它的代码实现细节)。其次,我们看到这里特征变量是用k:v这样的格式来表达,其实这是非常常用的一种格式,称为dense向量,与之相对的称为sparse向量,我们可以通过下图的示意来理解:

那上面这些120多个特征变量,分别是啥呢?我们可通过github上xgboost/demo/data/featmap.txt 这个文件来了解:
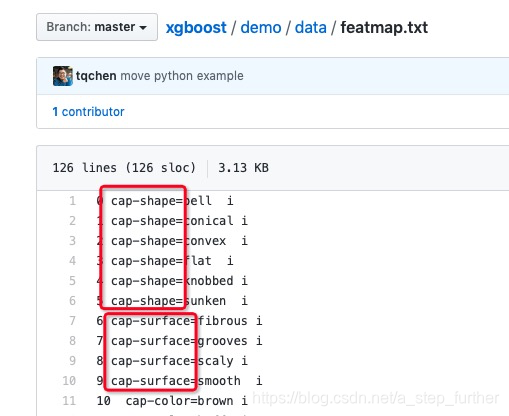
从这个文件的内容,我们可以推测出来它是对特征进行了one-hot-encoding。很多机器学习算法都不支持具有枚举值的变量,所以需要做这样的一个特征工程处理,原理如下图所示:
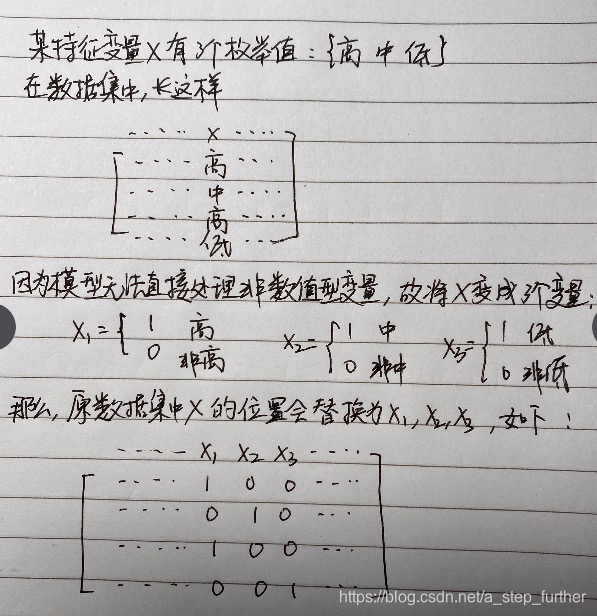
这样我们就对数据有了初步了解。接着去看代码操作。
在上面的代码中是用.Dmatrix读入数据,我们自己用 type(dtrain) 查看一下,发现返回的是xgboost.core.DMatrix这样一种数据类型,看来是xgboost自己定义的数据格式了。那么问题来了,
dtrain = xgb.DMatrix(‘demo/data/agaricus.txt.train’)
这一步操作之后,是把特征变量与目标变量保持到了一个数据集中,这与我们以往使用的sklearn接口是不同的,还记得吗,我们通常是把数据集拆成X_train, y_train 这样,有特征集与目标变量之分,之后再调用.fit(X_train, y_train)这样的接口来拟合数据。而这里我们看到是这样用的:
bst = xgb.train(param, dtrain, num_round)
train 我们可以认为等同于sklearn里面算法包接口的fit方法,但这里只传了一个dtrain数据集,并没有拆分开哪一列是目标变量,train这个方法是怎么知道用哪一列来拟合呢?我们猜想train这个方法一定与DMatrix数据结构有约定好的格式。为了解这里究竟是怎么处理的(没错,就是要多保留一些好奇心,这样写代码才有趣),我们去翻翻github上xgboost的源代码。
找啊找,我们在文件dmlc/xgboost/blob/master/python-package/xgboost/core.py中看到了DMatrix这个类的定义:
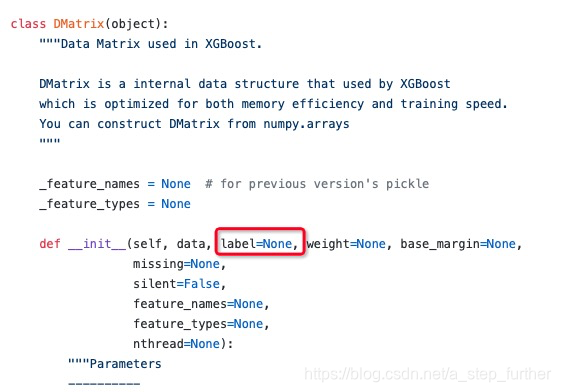
可见这里其实是支持传入目标向量的,但可以默认为空,那么猜想如果传入为空,它一定默认从前面的data中去提取这个目标向量了。
--------------以下过程不感兴趣的可以跳过————————
继续往下看,发现这样一个线索:
if label is not None:
self.set_label(label)
- 1
- 2
看来,当传入的label不为空时,通过set_label 这个方法就直接获取到了label, 那么label未传入呢?但是我们居然没有找到 if label is None 这个逻辑的处理!呃,一定是在某个地方隐式处理了,继续找线索:
def get_label(self): """Get the label of the DMatrix. Returns ------- label : array """ return self.get_float_info('label') .... def get_float_info(self, field): """Get float property from the DMatrix. Parameters ---------- field: str The field name of the information Returns ------- info : array a numpy array of float information of the data """ length = c_bst_ulong() ret = ctypes.POINTER

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

