
- 1推特社交机器人分类
- 2MMSeg框架segformer模型训练自己的数据集_用mmsegmentation里面的segformer训练自己的数据集
- 3keras实战-入门之RNN(GRU)自编码器_gru自编码器
- 4Flash | RAM | SRAM | DRAM_flash和ram
- 5100ASK-IMX6ULL开发板移值NXP官方Linux_100ask_imx6ull_flashing_tool
- 6QT问题记录:Qt报错msvc-version.conf loaded but QMAKE_MSC_VER isn‘t set_msvc-version conf loaded but qmake_msc_ver isn't s
- 7如何使用 Midjourney?2024年最新更新
- 8YOLOv5以rtmp视频流持续推理本地某一应用窗口场景_yolov5实时读取某窗口
- 9个人推荐Redis比较好的一种使用规范
- 10推荐系统架构_推荐系统三层
使用自己数据及进行PointNet++分类网络训练_使用pointnet++的分割网络来训练二分类数据集要注意萨满
赞
踩
目录
一、概述
使用自己数据及进行PointNet++分类网络训练,这里我选中悉尼大学开放的自动驾驶数据集进行测试。
二、数据集读取
常用数据集
选用悉尼大学开放的自动驾驶数据集进行训练
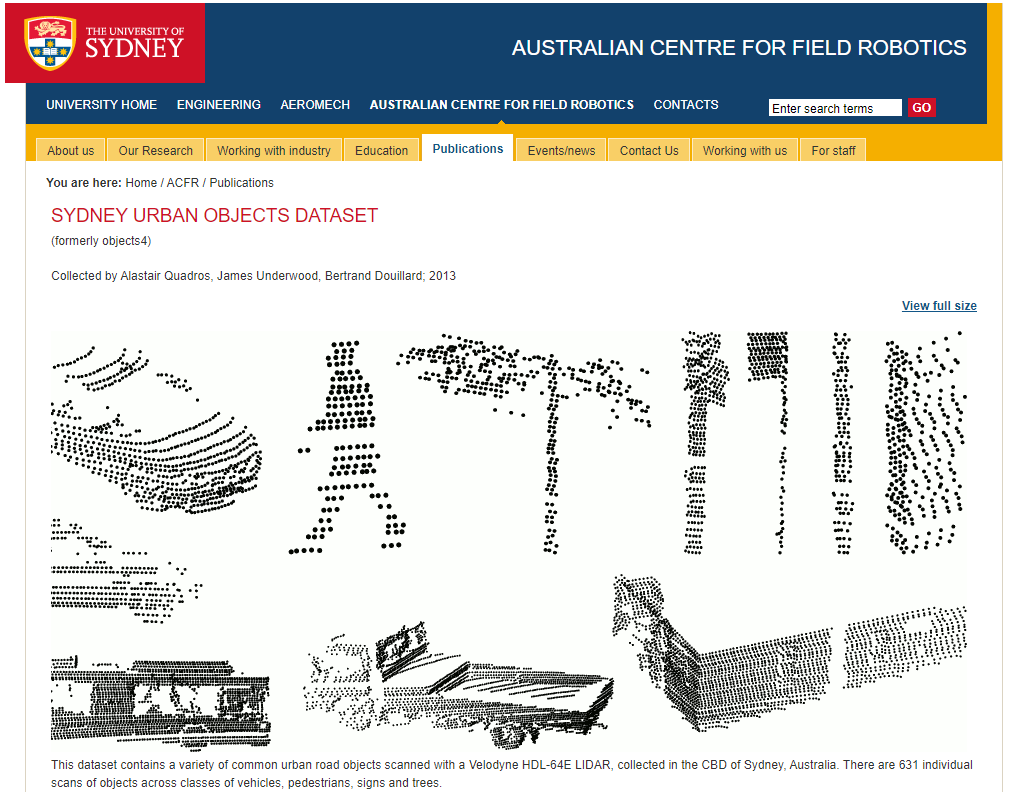
方式一:安装snark软件
math-deg2rad.exe -h

方式二:使用pyton脚本读取
- # -*- coding: utf-8 -*-
- """ Simple example for loading object binary data. """
- import numpy as np
- import matplotlib.pyplot as plt
-
-
- names = ['t','intensity','id',
- 'x','y','z',
- 'azimuth','range','pid']
-
- formats = ['int64', 'uint8', 'uint8',
- 'float32', 'float32', 'float32',
- 'float32', 'float32', 'int32']
-
- binType = np.dtype( dict(names=names, formats=formats) )
- data = np.fromfile('objects/excavator.0.10974.bin', binType)
-
- # 3D points, one per row
- #按垂直方向(行顺序)堆叠数组构成一个新的数组
-
- P = np.vstack([ data['x'], data['y'], data['z'] ]).T
- print(P)
-
- #visulize the pointcloud
- x = []
- y = []
- z = []
- for point in P:
- x.append(point[0])
- y.append(point[1])
- z.append(point[2])
-
- x = np.array(x, dtype=float)
- y = np.array(y, dtype=float)
- z = np.array(z, dtype=float)
-
- ax = plt.subplot(projection='3d')
- ax.set_title('image_show')
- ax.scatter(x, y, z, c='r')
-
- ax.set_xlabel('X')
- ax.set_ylabel('Y')
- ax.set_zlabel('Z')
- plt.show()
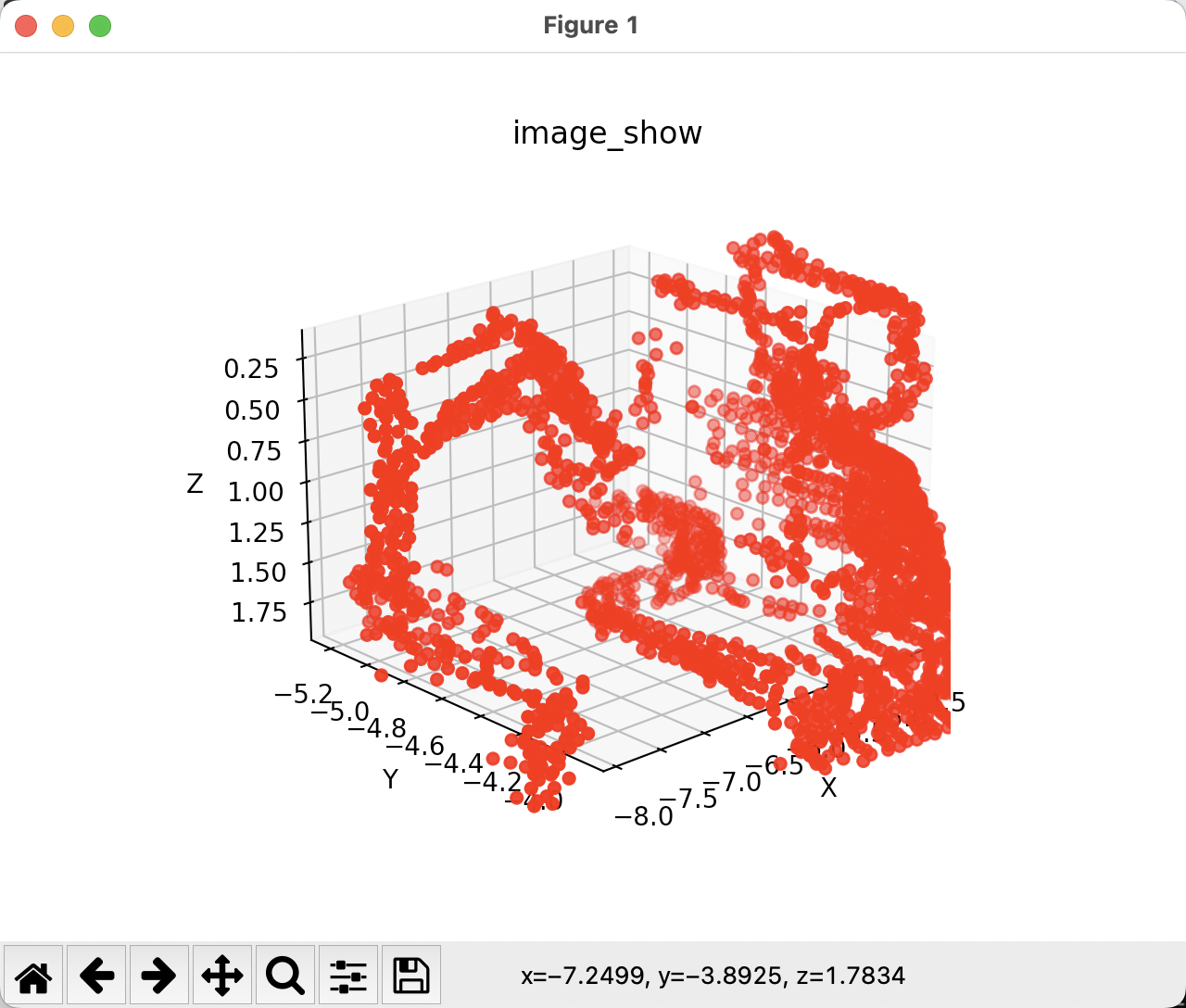
-
制作分类数据集
数据集格式要求,参照modelnet10、modelnet40分类数据格式:
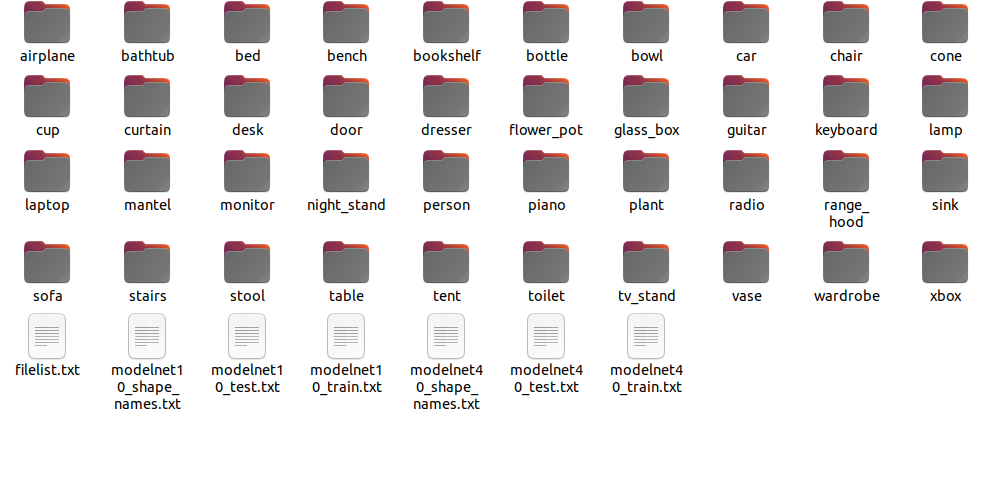
如下图:

说明:
allclass:所有类别说明
filelist:列出所有文件所在路径
testlist:测试数据
trainlist:训练数据
三、运行代码
代码目录:
 新增
新增
train_ownpointcloud_cls.py
- """
- Author: Benny
- Date: Nov 2019
- """
-
- import os
- import sys
- import torch
- import numpy as np
-
- import datetime
- import logging
- import provider
- import importlib
- import shutil
- import argparse
-
- from pathlib import Path
- from tqdm import tqdm
- from data_utils.OwnPointCloudDataLoader import OwnPointCloudDataLoader
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
- def parse_args():
- '''PARAMETERS'''
- parser = argparse.ArgumentParser('training')
- parser.add_argument('--use_cpu', action='store_true', default=False, help='use cpu mode')
- parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')
- parser.add_argument('--batch_size', type=int, default=20, help='batch size in training')
- parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')
- parser.add_argument('--num_category', default=4, type=int, choices=[4,10, 40], help='training on ModelNet10/40')
- parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training')
- parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training')
- parser.add_argument('--num_point', type=int, default=1024, help='Point Number')
- parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training')
- parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
- parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate')
- parser.add_argument('--use_normals', action='store_true', default=False, help='use normals')
- parser.add_argument('--process_data', action='store_true', default=False, help='save data offline')
- parser.add_argument('--use_uniform_sample', action='store_true', default=False, help='use uniform sampiling')
- return parser.parse_args()
-
-
- def inplace_relu(m):
- classname = m.__class__.__name__
- if classname.find('ReLU') != -1:
- m.inplace=True
-
-
- def test(model, loader, num_class=40):
- mean_correct = []
- class_acc = np.zeros((num_class, 3))
- classifier = model.eval()
-
- for j, (points, target) in tqdm(enumerate(loader), total=len(loader)):
-
- if not args.use_cpu:
- points, target = points.cuda(), target.cuda()
-
- points = points.transpose(2, 1)
- pred, _ = classifier(points)
- pred_choice = pred.data.max(1)[1]
-
- for cat in np.unique(target.cpu()):
- classacc = pred_choice[target == cat].eq(target[target == cat].long().data).cpu().sum()
- class_acc[cat, 0] += classacc.item() / float(points[target == cat].size()[0])
- class_acc[cat, 1] += 1
-
- correct = pred_choice.eq(target.long().data).cpu().sum()
- mean_correct.append(correct.item() / float(points.size()[0]))
-
- class_acc[:, 2] = class_acc[:, 0] / class_acc[:, 1]
- class_acc = np.mean(class_acc[:, 2])
- instance_acc = np.mean(mean_correct)
-
- return instance_acc, class_acc
-
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
-
- '''CREATE DIR'''
- timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
- exp_dir = Path('./log/')
- exp_dir.mkdir(exist_ok=True)
- exp_dir = exp_dir.joinpath('classification')
- exp_dir.mkdir(exist_ok=True)
- if args.log_dir is None:
- exp_dir = exp_dir.joinpath(timestr)
- else:
- exp_dir = exp_dir.joinpath(args.log_dir)
- exp_dir.mkdir(exist_ok=True)
- checkpoints_dir = exp_dir.joinpath('checkpoints/')
- checkpoints_dir.mkdir(exist_ok=True)
- log_dir = exp_dir.joinpath('logs/')
- log_dir.mkdir(exist_ok=True)
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- '''DATA LOADING'''
- log_string('Load dataset ...')
- data_path = 'data/owndata/'
-
- train_dataset = OwnPointCloudDataLoader(root=data_path, args=args, split='train', process_data=args.process_data)
- test_dataset = OwnPointCloudDataLoader(root=data_path, args=args, split='test', process_data=args.process_data)
- trainDataLoader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=10, drop_last=True)
- testDataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=10)
-
- '''MODEL LOADING'''
- num_class = args.num_category
- model = importlib.import_module(args.model)
- shutil.copy('./models/%s.py' % args.model, str(exp_dir))
- shutil.copy('models/pointnet2_utils.py', str(exp_dir))
- shutil.copy('./train_classification.py', str(exp_dir))
-
- classifier = model.get_model(num_class, normal_channel=args.use_normals)
- criterion = model.get_loss()
- classifier.apply(inplace_relu)
-
- if not args.use_cpu:
- classifier = classifier.cuda()
- criterion = criterion.cuda()
-
- try:
- checkpoint = torch.load(str(exp_dir) + '/checkpoints/best_model.pth')
- start_epoch = checkpoint['epoch']
- classifier.load_state_dict(checkpoint['model_state_dict'])
- log_string('Use pretrain model')
- except:
- log_string('No existing model, starting training from scratch...')
- start_epoch = 0
-
- if args.optimizer == 'Adam':
- optimizer = torch.optim.Adam(
- classifier.parameters(),
- lr=args.learning_rate,
- betas=(0.9, 0.999),
- eps=1e-08,
- weight_decay=args.decay_rate
- )
- else:
- optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)
-
- scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
- global_epoch = 0
- global_step = 0
- best_instance_acc = 0.0
- best_class_acc = 0.0
-
- '''TRANING'''
- logger.info('Start training...')
- for epoch in range(start_epoch, args.epoch):
- log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
- mean_correct = []
- classifier = classifier.train()
-
- scheduler.step()
- #print('================batch_id===============')
-
- for batch_id, (points, target) in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):
- optimizer.zero_grad()
-
- points = points.data.numpy()
- #print(points)
- points = provider.random_point_dropout(points)
- points[:, :, 0:3] = provider.random_scale_point_cloud(points[:, :, 0:3])
- points[:, :, 0:3] = provider.shift_point_cloud(points[:, :, 0:3])
- points = torch.Tensor(points)
- points = points.transpose(2, 1)
-
- if not args.use_cpu:
- points, target = points.cuda(), target.cuda()
-
- pred, trans_feat = classifier(points)
- loss = criterion(pred, target.long(), trans_feat)
- pred_choice = pred.data.max(1)[1]
-
- correct = pred_choice.eq(target.long().data).cpu().sum()
- mean_correct.append(correct.item() / float(points.size()[0]))
- loss.backward()
- optimizer.step()
- global_step += 1
-
- train_instance_acc = np.mean(mean_correct)
- log_string('Train Instance Accuracy: %f' % train_instance_acc)
-
- with torch.no_grad():
- instance_acc, class_acc = test(classifier.eval(), testDataLoader, num_class=num_class)
-
- if (instance_acc >= best_instance_acc):
- best_instance_acc = instance_acc
- best_epoch = epoch + 1
-
- if (class_acc >= best_class_acc):
- best_class_acc = class_acc
- log_string('Test Instance Accuracy: %f, Class Accuracy: %f' % (instance_acc, class_acc))
- log_string('Best Instance Accuracy: %f, Class Accuracy: %f' % (best_instance_acc, best_class_acc))
-
- if (instance_acc >= best_instance_acc):
- logger.info('Save model...')
- savepath = str(checkpoints_dir) + '/best_model.pth'
- log_string('Saving at %s' % savepath)
- state = {
- 'epoch': best_epoch,
- 'instance_acc': instance_acc,
- 'class_acc': class_acc,
- 'model_state_dict': classifier.state_dict(),
- 'optimizer_state_dict': optimizer.state_dict(),
- }
- torch.save(state, savepath)
- global_epoch += 1
-
- logger.info('End of training...')
-
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
新增OwnPointCloudDataLoader.py
- '''
- @author: Xu Yan
- @file: ModelNet.py
- @time: 2021/3/19 15:51
- '''
- import os
- import numpy as np
- import warnings
- import pickle
-
- from tqdm import tqdm
- from torch.utils.data import Dataset
-
- warnings.filterwarnings('ignore')
-
-
- def pc_normalize(pc):
- centroid = np.mean(pc, axis=0)
- pc = pc - centroid
- m = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))
- pc = pc / m
- return pc
-
-
- def farthest_point_sample(point, npoint):
- """
- Input:
- xyz: pointcloud data, [N, D]
- npoint: number of samples
- Return:
- centroids: sampled pointcloud index, [npoint, D]
- """
- N, D = point.shape
- xyz = point[:, :3]
- centroids = np.zeros((npoint,))
- distance = np.ones((N,)) * 1e10
- farthest = np.random.randint(0, N)
- for i in range(npoint):
- centroids[i] = farthest
- centroid = xyz[farthest, :]
- dist = np.sum((xyz - centroid) ** 2, -1)
- mask = dist < distance
- distance[mask] = dist[mask]
- farthest = np.argmax(distance, -1)
- point = point[centroids.astype(np.int32)]
- return point
-
-
- class OwnPointCloudDataLoader(Dataset):
- def __init__(self, root, args, split='train', process_data=False):
- self.root = root
- self.npoints = args.num_point
- self.process_data = process_data
- self.uniform = args.use_uniform_sample
- self.use_normals = args.use_normals
- self.num_category = args.num_category
-
- if self.num_category == 10:
- self.catfile = os.path.join(self.root, 'allclass.txt')
- else:
- self.catfile = os.path.join(self.root, 'allclass.txt')
-
- self.cat = [line.rstrip() for line in open(self.catfile)]
- #print('cat')
- #print(self.cat)
- self.classes = dict(zip(self.cat, range(len(self.cat))))
-
- shape_ids = {}
- if self.num_category == 10:
- shape_ids['train'] = [line.rstrip() for line in open(os.path.join(self.root, 'trainlist.txt'))]
- shape_ids['test'] = [line.rstrip() for line in open(os.path.join(self.root, 'testlist.txt'))]
- else:
- shape_ids['train'] = [line.rstrip() for line in open(os.path.join(self.root, 'trainlist.txt'))]
- shape_ids['test'] = [line.rstrip() for line in open(os.path.join(self.root, 'testlist.txt'))]
-
- print('shape_ids:')
- print(shape_ids['train'] )
-
- assert (split == 'train' or split == 'test')
- #origin format : airplane_0627
- #new format : pedestrian.9.6994
- shape_names = [''.join(x.split('.')[0]) for x in shape_ids[split]]
- print('shapenames:')
- print(shape_names)
- self.datapath = [(shape_names[i], os.path.join(self.root, shape_names[i], shape_ids[split][i]) + '.txt') for i
- in range(len(shape_ids[split]))]
- print('The size of %s data is %d' % (split, len(self.datapath)))
-
- if self.uniform:
- self.save_path = os.path.join(root,
- 'ownpointcloud%d_%s_%dpts_fps.dat' % (self.num_category, split, self.npoints))
- else:
- self.save_path = os.path.join(root, 'ownpointcloud%d_%s_%dpts.dat' % (self.num_category, split, self.npoints))
-
- if self.process_data:
- if not os.path.exists(self.save_path):
- print('Processing data %s (only running in the first time)...' % self.save_path)
- self.list_of_points = [None] * len(self.datapath)
- self.list_of_labels = [None] * len(self.datapath)
-
- for index in tqdm(range(len(self.datapath)), total=len(self.datapath)):
- fn = self.datapath[index]
- cls = self.classes[self.datapath[index][0]]
- cls = np.array([cls]).astype(np.int32)
- point_set = np.loadtxt(fn[1], delimiter=',').astype(np.float32)
-
- if self.uniform:
- point_set = farthest_point_sample(point_set, self.npoints)
- else:
- point_set = point_set[0:self.npoints, :]
-
- self.list_of_points[index] = point_set
- self.list_of_labels[index] = cls
-
- with open(self.save_path, 'wb') as f:
- pickle.dump([self.list_of_points, self.list_of_labels], f)
- else:
- print('Load processed data from %s...' % self.save_path)
- with open(self.save_path, 'rb') as f:
- self.list_of_points, self.list_of_labels = pickle.load(f)
-
- def __len__(self):
- return len(self.datapath)
-
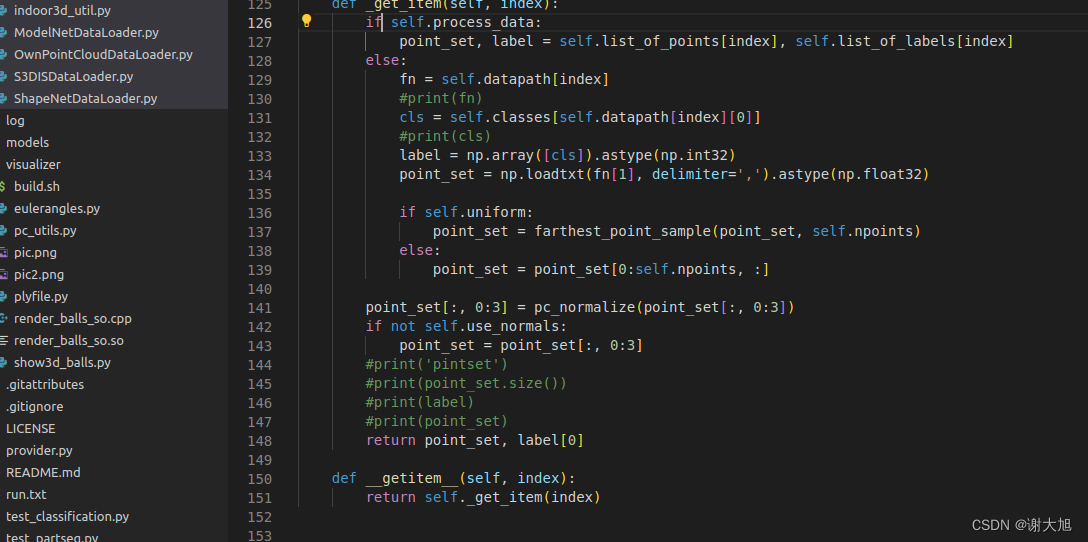
- def _get_item(self, index):
- if self.process_data:
- point_set, label = self.list_of_points[index], self.list_of_labels[index]
- else:
- fn = self.datapath[index]
- #print(fn)
- cls = self.classes[self.datapath[index][0]]
- #print(cls)
- label = np.array([cls]).astype(np.int32)
- point_set = np.loadtxt(fn[1], delimiter=',').astype(np.float32)
-
- if self.uniform:
- point_set = farthest_point_sample(point_set, self.npoints)
- else:
- point_set = point_set[0:self.npoints, :]
-
- point_set[:, 0:3] = pc_normalize(point_set[:, 0:3])
- if not self.use_normals:
- point_set = point_set[:, 0:3]
- #print('pintset')
- #print(point_set.size())
- #print(label)
- #print(point_set)
- return point_set, label[0]
-
- def __getitem__(self, index):
- return self._get_item(index)
-
-
- if __name__ == '__main__':
- import torch
-
- data = OwnPointCloudDataLoader('/data/owndata/', split='train')
- DataLoader = torch.utils.data.DataLoader(data, batch_size=4, shuffle=True)
- for point, label in DataLoader:
- print(point.shape)
- print(label.shape)
运行截图:
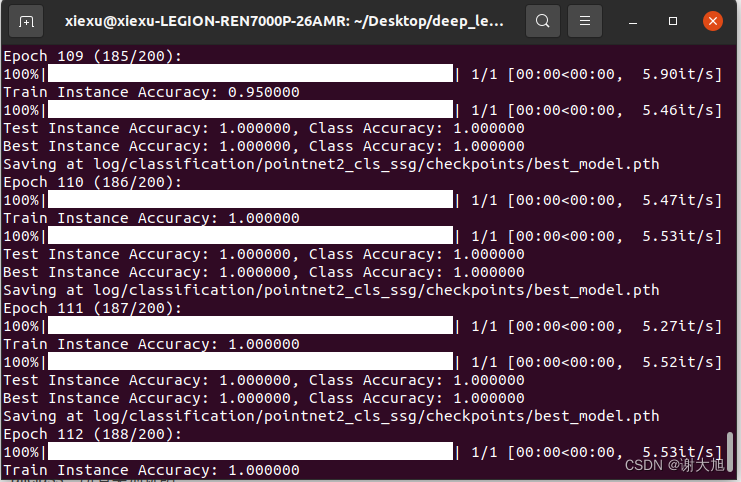
四、问题解决
解决问题过程出现了好几处,都是比较容易解决的问题,这里记录这个我感觉比较棘手的。
1、 RuntimeError: stack expects each tensor to be equal size, but got [124, 3] at entry 0 and [162, 3] at entry 1
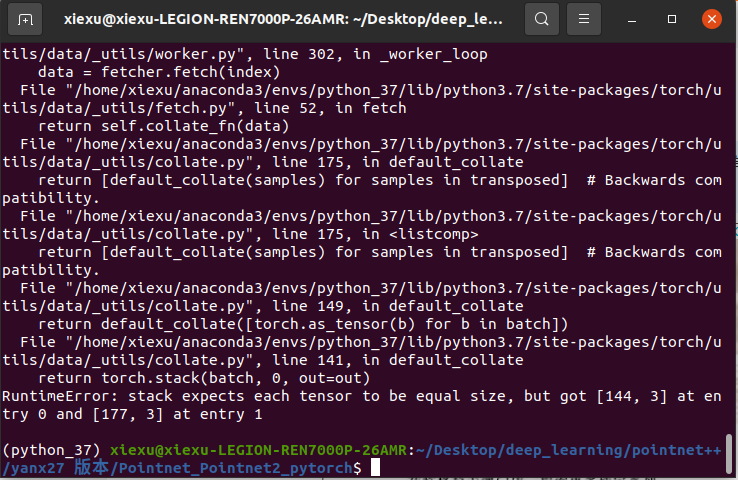
这个问题是daloaded读取时候,modelnet默认·每个txt都是10000个点,因此自己数据数据量不统一,就报错了。
解决办法:保证数据到torch.stack里边张量的size一直
1、保证txt点云点的个数一致
2、实现getitem时候,张量进行补全,代码在这
五、总结
记录几个在制作数据集时候需要注意的问题:
1、目录结构要保持一致,文件名不用一致,因为代码里边能够改
2、txt内容要一致,不管是格式还是数量(比如上边的问题),因为作者的数据集比较标准,用自己数据时候可能情况比较复杂,当前也能够在代码角度进行解决。
3、建议使用小批量数据进行测试,测试没有问题后,在开始用脚本进行数据集的输入,不然制作的数据集出问题,反复改代码,也是麻烦。还可能带来新的错误,毕竟有时候情况复杂,考虑不周。

