
热门标签
热门文章
- 1C和C++相互调用 error LNK2001: unresolved external symbol_c++unresolved什么意思
- 2利用低代码从0到1开发一款小程序_小程序低代码
- 3Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本_gpt-4的层数和训练参数
- 4使用org.apache.commons.io.FileUtils,IOUtils;工具类操作文件
- 5shell命令-find常用命令_shell find -exec
- 6Gradle 安装和配置教程_gradle-8.3-bin.zip放哪个位置
- 7《最长的一帧》理解01_场景渲染
- 8负载均衡_用户将请求发送给负载均衡
- 9Apriori算法中使用Hash树进行支持度计数_hash树在apriori算法中的作用
- 10glance服务器上传的镜像支持,openstack-理解glance组件和镜像服务
当前位置: article > 正文
开源中文医疗大模型_medbert
作者:羊村懒王 | 2024-04-03 13:45:46
赞
踩
medbert
中文医疗大模型
中文医疗大模型是指通过利用自然语言处理技术和机器学习算法,在大量的医疗文本数据中预训练出来的模型。它可以实现对医疗信息的分类、摘要、问答系统、机器翻译等功能,是医疗行业中的重要工具。在医疗领域中,大规模语言模型(Large Language Model)具有广泛的应用潜力。
开源医疗大模型
目前,开源中文医疗大模型还没有特别成熟的项目,但是有一些相关的开源项目和数据集可以使用。
- MedBERT:由清华大学自然语言处理与社会人文计算实验室(THUNLP)开发的基于BERT模型的医疗领域预训练模型,可以用于中文医疗文本的处理和分析。项目地址:
https://github.com/ymcui/Medical-Transformer - CMeIE:由中国科学院计算技术研究所开发的中文医疗实体识别和关系抽取工具包,基于深度学习模型,可以用于从中文医疗文本中提取实体和关系。项目地址:
https://github.com/csking1/CMeIE - 中文医疗问答数据集:由哈工大社会计算与信息检索研究中心发布的中文医疗问答数据集,包含了大量的医疗领域问题和对应的答案。可以用于训练医疗问答系统等任务。
数据集地址:
https://github.com/zhangsheng93/Chinese-Health-Question-Answering-Dataset
这些开源项目和数据集可以为中文医疗大模型的开发提供一些基础资源,但是需要根据具体的应用场景和需求进行进一步的开发和调优。
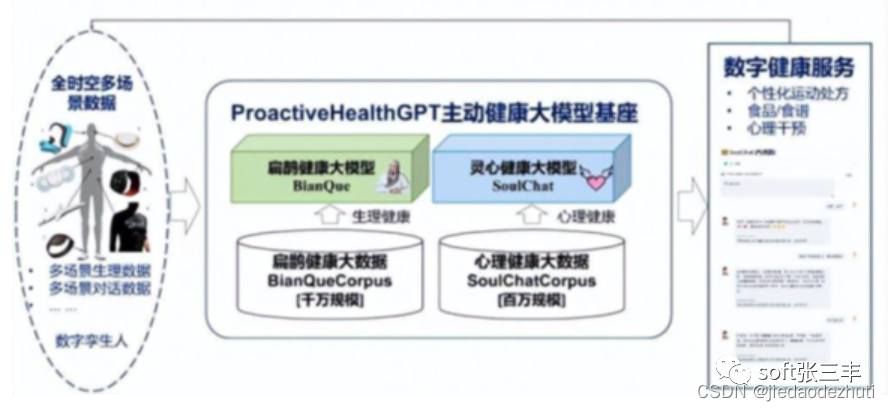
华佗 GPT
HuatuoGPT(华佗 GPT)是开源中文医疗大模型,基于医生回复和 ChatGPT 回复,让语言模型成为医生,提供丰富且准确的问诊。

HuatuoGPT 致力于通过融合 ChatGPT 生成的 “蒸馏数据” 和真实世界医生回复的数据,以使语言模型具备像医生一样的诊断能力和提供有用信息的能力,同时保持对用户流畅的交互和内容的丰富性,对话更加丝滑。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/355718
推荐阅读
相关标签

