
热门标签
热门文章
- 1计算机跨教育学,某985计算机专业,想要三跨北师大教育学,会不会很难?
- 2多线程编程实现银行家算法(g++11新版本,解决了CSDN相关内容比较陈旧的问题)_g++算法
- 3最全网络安全岗面试题 初级岗(渗透测试和信息安全方向)_十一、现在菜刀连接了一台内网主机,怎么快速地登录上线
- 4docker容器中的centos7系统大部分系统目录为read-only file system?_docker read-only file system
- 5Android每次创建一个项目,就会重新下载.gradle文件_android studio每次都要重新下载
- 6如何利用ThinkPHPv5的漏洞来getshell_thinkphp v5.1.39 漏洞获取主机shell
- 72021-03-10强大的Winform Chart图表控件使用说明_chart.legends[0]是什么
- 8rust - 计算文件的md5和sha1值
- 9Connect to dl.google.com:443 failed: connect time out
- 102022最新Macbookpro M1芯片 搭建RocketMQ_homebrew安装rocketmq
当前位置: article > 正文
OCR表格识别(三)——文本检测与文本识别理论学习_ocr 检测和识别的区别
作者:羊村懒王 | 2024-03-14 00:18:58
赞
踩
ocr 检测和识别的区别
深度学习之图像处理
- 图像识别其实是一个从低层次到高层级特征学习的过程。底层级的特征比较抽象,二高层及的特征比较概念化。在图像识别过程中,也就是从图像像素特征,到图像的形状、轮廓,然后到概念,并进行整合,分类,最终得到目标特征,识别到人脸等。再怎么复杂的信息都是由基本结构组合而成,就像人的认知过程一样,是由浅到深的一个过程。
- 1981年的诺贝尔将颁发给了David Hubel和Torsten Wiesel,以及Roger Sperry。他们发现了人的视觉系统处理信息是分级的。
- 从视网膜(Retina)出发,经过低级的V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化,也即越来越能表现语义或者意图。
- 边缘特征 —–> 基本形状和目标的局部特征——>整个目标
- 这个过程其实和我们的常识是相吻合的,因为复杂的图形,往往就是由一些基本结构组合而成的。同时我们还可以看出:大脑是一个深度架构,认知过程也是深度的。
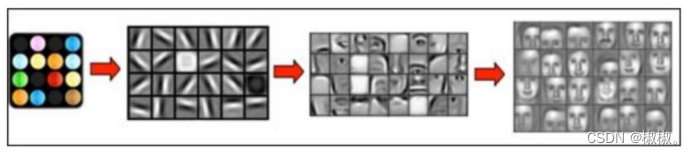
- 深度学习,恰恰就是通过组合低层特征形成更加抽象的高层特征(或属性类别)。例如,在计算机视觉领域,深度学习算法从原始图像去学习得到一个低层次表达,例如边缘检测器、小波滤波器等,然后在这些低层次表达的基础上,通过线性或者非线性组合,来获得一个高层次的表达。此外,不仅图像存在这个规律,声音也是类似的。比如,研究人员从某个声音库中通过算法自动发现了20种基本的声音结构,其余的声音都可以由这20种基本结构来合成!
ocr技术挑战:
算法层:
- 这些问题给文本检测和文本识别都带来了巨大的技术挑战,可以看到,这些挑战主要都是面向自然场景,目前学术界的研究也主要聚焦在自然场景,OCR领域在学术上的常用数据集也都是自然场景。针对这些问题的研究很多,相对来说,识别比检测面临更大的挑战。

应用层:
- 在实际应用中,尤其是在广泛的通用场景下,除了上一节总结的仿射变换、尺度问题、光照不足、拍摄模糊等算法层面的技术难点,OCR技术还面临两大落地难点:
- 1、海量数据要求OCR能够实时处理。 OCR应用常对接海量数据,我们要求或希望数据能够得到实时处理,模型的速度做到实时是一个不小的挑战。
- 2、端侧应用要求OCR模型足够轻量,识别速度足够快。 OCR应用常部署在移动端或嵌入式硬件,端侧OCR应用一般有两种模式:上传到服务器vs. 端侧直接识别,考虑到上传到服务器的方式对网络有要求,实时性较低,并且请求量过大时服务器压力大,以及数据传输的安全性问题,我们希望能够直接在端侧完成OCR识别,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
OCR前沿算法
- 虽然OCR是一个相对具体的任务,但涉及了多方面的技术,包括文本检测、文本识别、端到端文本识别、文档分析等等。学术上关于OCR各项相关技术的研究层出不穷,下文将简要介绍OCR任务中的几种关键技术的相关工作。
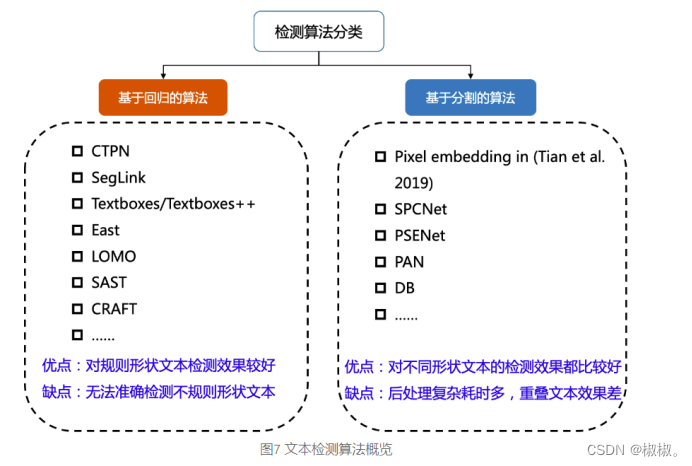
文本检测
- 文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes基于一阶段目标检测器SSD算法,调整目标框使之适合极端长宽比的文本行,CTPN则是基于Faster RCNN架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法,如EAST[5]、PSENet[6]、DBNet[7]等等。
- 目前较为流行的文本检测算法可以大致分为基于回归和基于分割的两大类文本检测算法,也有一些算法将二者相结合。基于回归的算法借鉴通用物体检测算法,通过设定anchor回归检测框,或者直接做像素回归,这类方法对规则形状文本检测效果较好,但是对不规则形状的文本检测效果会相对差一些,比如CTPN[3]对水平文本的检测效果较好,但对倾斜、弯曲文本的检测效果较差,SegLink[8]对长文本比较好,但对分布稀疏的文本效果较差;基于分割的算法引入了Mask-RCNN[9],这类算法在各种场景、对各种形状文本的检测效果都可以达到一个更高的水平,但缺点就是后处理一般会比较复杂,因此常常存在速度问题,并且无法解决重叠文本的检测问题。
文本识别
-
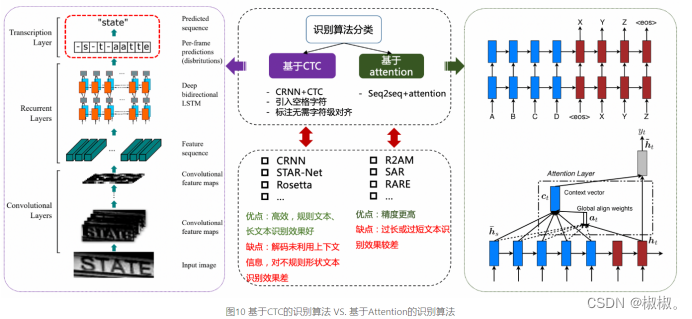
文本识别的任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置;不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向。

-
规则文本识别的算法根据解码方式的不同可以大致分为基于CTC和Sequence2Sequence两种,将网络学习到的序列特征 转化为 最终的识别结果 的处理方式不同。基于CTC的算法以经典的CRNN为代表。
-
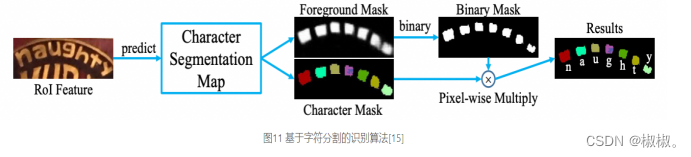
不规则文本的识别算法相比更为丰富,如STAR-Net等方法通过加入TPS等矫正模块,将不规则文本矫正为规则的矩形后再进行识别;RARE等基于Attention的方法增强了对序列之间各部分相关性的关注;基于分割的方法将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易;此外,随着近年来Transfomer的快速发展和在各类任务中的有效性验证,也出现了一批基于Transformer的文本识别算法,这类方法利用transformer结构解决CNN在长依赖建模上的局限性问题,也取得了不错的效果。
文档结构化识别
- 传统意义上的OCR技术可以解决文字的检测和识别需求,但在实际应用场景中,最终需要获取的往往是结构化的信息,如身份证、发票的信息格式化抽取,表格的结构化识别等等,多在快递单据抽取、合同内容比对、金融保理单信息比对、物流业单据识别等场景下应用。OCR结果+后处理是一种常用的结构化方案,但流程往往比较复杂,并且后处理需要精细设计,泛化性也比较差。在OCR技术逐渐成熟、结构化信息抽取需求日益旺盛的背景下,版面分析、表格识别、关键信息提取等关于智能文档分析的各种技术受到了越来越多的关注和研究。
版面分析 - 版面分析(Layout
Analysis)主要是对文档图像进行内容分类,类别一般可分为纯文本、标题、表格、图片等。现有方法一般将文档中不同的板式当做不同的目标进行检测或分割,如Soto Carlos[16]在目标检测算法Faster R-CNN的基础上,结合上下文信息并利用文档内容的固有位置信息来提高区域检测性能;Sarkar Mausoom等人提出了一种基于先验的分割机制,在非常高的分辨率的图像上训练文档分割模型,解决了过度缩小原始图像导致的密集区域不同结构无法区分进而合并的问题。
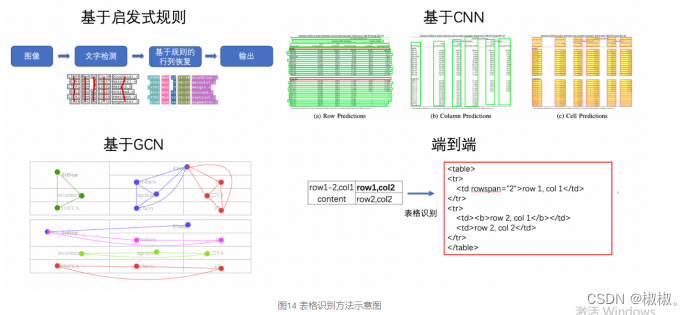
表格识别 - 表格识别(Table Recognition)的任务就是将文档里的表格信息进行识别和转换到excel文件中。文本图像中表格种类和样式复杂多样,例如不同的行列合并,不同的内容文本类型等,除此之外文档的样式和拍摄时的光照环境等都为表格识别带来了极大的挑战。这些挑战使得表格识别一直是文档理解领域的研究难点。
- 表格识别的方法种类较为丰富,早期的基于启发式规则的传统算法,如Kieninger[18]等人提出的T-Rect等算法,一般通过人工设计规则,连通域检测分析处理;近年来随着深度学习的发展,开始涌现一些基于CNN的表格结构识别算法,如Siddiqui Shoaib Ahmed[等人提出的DeepTabStR,Raja Sachin[等人提出的TabStruct-Net等;此外,随着图神经网络(Graph Neural Network)的兴起,也有一些研究者尝试将图神经网络应用到表格结构识别问题上,基于图神经网络,将表格识别看作图重建问题,如Xue Wenyuan等人提出的TGRNet;基于端到端的方法直接使用网络完成表格结构的HTML表示输出,端到端的方法大多采用Seq2Seq方法来完成表格结构的预测,如一些基于Attention或Transformer的方法,如 TableMaster[22]。
关键信息提取
- 关键信息提取(Key Information Extraction,KIE)是Document
VQA中的一个重要任务,主要从图像中提取所需要的关键信息,如从身份证中提取出姓名和公民身份号码信息,这类信息的种类往往在特定任务下是固定的,但是在不同任务间是不同的。
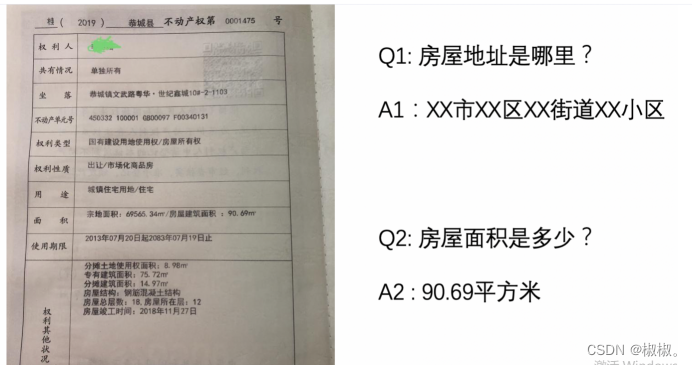
- KIE通常分为两个子任务进行研究:
- SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
- RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。

- 一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的的原理可以将这些方法分为下面四种:
- 基于Grid的方法
- 基于Token的方法
- 基于GCN的方法
- 基于End to End 的方法
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/231407
推荐阅读
相关标签

