
- 1Spring Boot框架的过滤器(Filters)和拦截器(Interceptors)使用
- 2MATLAB的rvctools工具箱熟悉运动学【机械臂机器人示例】_startup_rvc
- 3关于操作系统_blackberry 操作系统 发展
- 4Android Kotlin知识汇总(三)Kotlin 协程
- 5大预言模型——ChatGPT,Claude3、Sora、等技术
- 6C++进行代码加速、多线程等知识点。pthread、openomp进行多线程加速、SSE进行加速
- 7hive之拉链表实现过程及剖析_hive拉链表的实现过程
- 8Sora学习笔记 Sora技术原理解析_sora原理 csdn
- 9Linux 文件系统只读_linux 只读文件系统
- 10【爬虫】使用selenium爬取网易云音乐热歌榜_爬虫网易音乐排行榜的信息
Linux——进程间通信
赞
踩
目录
进程间通信介绍
什么是进程间通信
进程通信是指在进程间传输数据 (交换信息)。 进程通信根据交换信息量的多少和效率的高低,分为低级通信(只能传递状态和整数值)和高级通信(提高信号通信的效率,传递大量数据,减轻程序编制的复杂度)。简单说就是在不同进程直接传播或交换信息。
为什么要进行进程间通信
- 数据传输:一个进程将数据发送给另一个进程。
- 资源共享:多个进程共享同样的资源。
- 通知:一个进程向另一个进程发送消息(进程终止通知父进程)。
- 进程控制:某个进程想要控制另一个进程。
进程间通信时很有必要的,原来我们写的都是单进程的,那么也就无法使用并发能力,也就无法实现多进程协同开发。
怎么做到进程间通信
因为进程间具有独立性,所以想要通信不是那么容易,如果让两个进程可以看到同一份资源那就可以实现,但又这块空间不能属于任何一个进程,它应该是共享的。
管道
这是一种单向传输的方式,在这之中传输的都是资源,资源是什么,它就是数据。
管道的原理
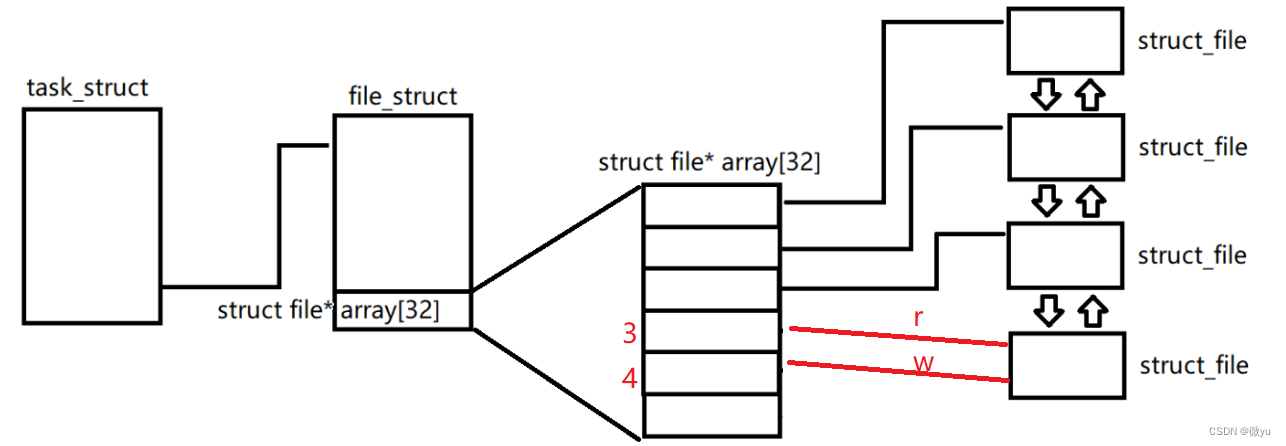
管道通信其实是进程直接通过管道进行通信。
第一步:分别以读写方式打开同一个文件。
第二步:fork()创建子进程。
创建子进程,因为进程具有独立性,所以子进程也要有自己的内核数据结构,但是不需要拷贝文件的数据结构,fork只创建进程,不需要再打开文件,它只要拷贝文件描述符表就可以指向相同的struct_file。
这不就是让不同的进程看到了同一份资源吗。
第三步:双方进程关闭不需要的文件描述符,父进程写入就关闭读端,子进程读取就关闭写端。
其实我们原来就已经用过管道了,在进程阶段使用的ps axj | grep mytest。
【注意】:管道虽然用的是文件,但操作系统不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率。有些文件只会在内存当中存在,而不会在磁盘当中存在。

匿名管道
匿名管道用于进程间通信,且仅限于本地父子进程之间的通信。
pipe函数
int pipe(int pipefd[2]);
功能:创建一个无名管道。
参数:这又是一个输出型参数,fd[0]表示读端,fd[1]表示写端。
返回值:成功返回0,失败返回-1,并且设置错误码。
pipe函数的参数是一个输出型参数,数组pipefd用于返回两个指向管道读端和写端的文件描述符。
一段小代码来演示一下pipe的使用,fork创建子进程,规定父进程写入,子进程读取,所以父进程关闭读取fd也就是pipefd[0],子进程关闭写入fd也就是pipefd[1]。子进程要打印read读取pipefd[0]的数据,先把数据放到缓冲区中再打印出来;父进程也要有缓冲区,把要写入的数据用snprintf格式化输出到缓冲区中,再write写入pipefd[1]中。
特点:
- 管道是用来进行具有血缘关系的进程进行进程间通信,常用与父子进程间通信。
- 上面的代码父进程一秒写一次,子进程没有限制的读,信息还是每秒读一条,曾经向父子进程向显示器中写入,可不会这样,那是因为这种缺乏访问控制,而管道是一个文件,它想让进程间协同,所以提供了访问控制。
- 管道提供的是面向流式的通信服务,面向字节流。(后面再谈)
- 管道是基于文件的,文件的生命周期是随进程的,所以管道的生命周期也是随进程的。
- 管道是单向通信的,它就是半双工的,半双工就是要么我在写,要么我在读,就像两个人对话一样,一个人说一个人听。
这段代码也可以实现下面这些现象,通过sleep就可以实现:
- 写的快,读的慢,写满就不能再写了。
- 写的慢,读的快,管道没有数据的时候,读的快的一方就要等待。
- 写的关闭,读到0个数据,代表读到文件结尾。
- 读的关闭,写要继续写,操作系统会终止写进程。


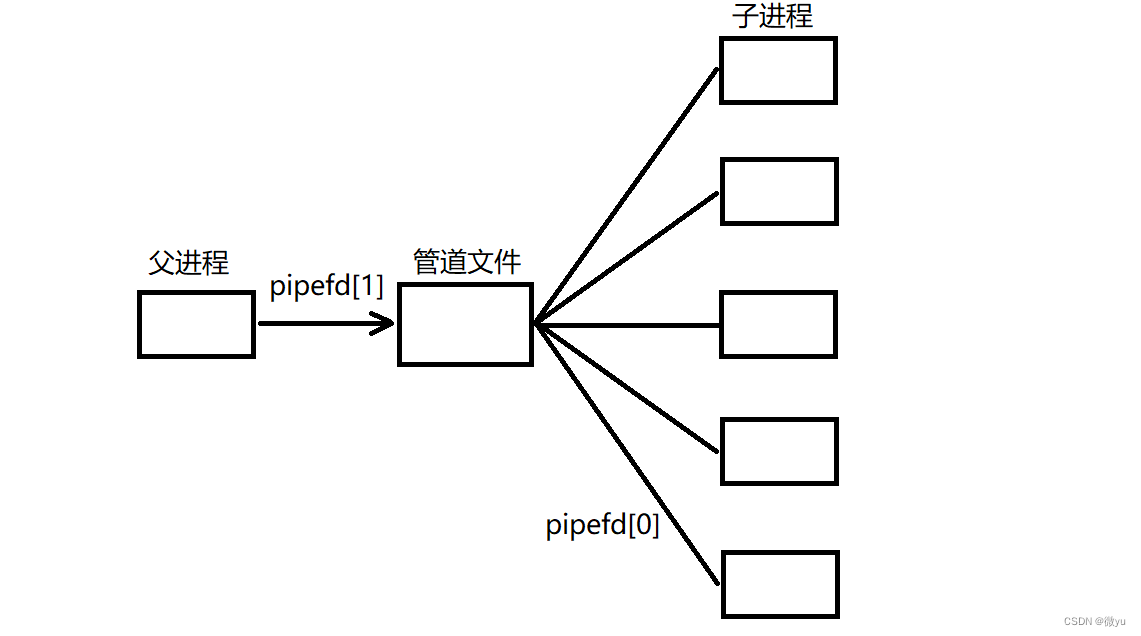
简单线程池
有了上面的这些知识的补充,我们现在就可以实现一个简单的进程池。使用循环的方式创建管道,再创建多个子进程,这次依旧是父进程派发任务(写端),子进程模拟收到任务并执行(读端),这时候这几个进程看到的都是内存级的同一个管道文件,父进程通过写端向管道中写数据,再通过单机版的负载均衡选出一个子进程开始派发指令,子进程拿到指令执行对应的方法。
从这里我们可以看到父进程指派了不同的进程来执行不同的任务,而且操作系统中也有父进程创建的多个子进程。
我们可以再来说一下关于close接口的细节,当我们close一个文件描述符的时候,我们真的关闭了吗?其实在struct_file中也有着引用计数的成员变量,不同的指针指向相同的文件描述符会使引用计数增加,close的时候你告诉操作系统你不用了,引用计数就--,减到零的时候才会被释放。
管道读写的规则
- 如果所有管道写端对应的文件描述符被关闭,则read返回0。
- 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出(后面再说)。
- 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
- 当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。

命名管道
进程间通信就是让不同的进程看到同一份资源,那么通过父子关系的进程可以实现,那我要是想让两个不相干的进程实现进程间通信呢?那么就要用到命名管道。
因为文件在系统中路径具有唯一性,所以两个进程就可以通过管道文件的路径看到同一份资源。
所以命名管道和匿名管道除了创建和打开的方式不同,其他的都一样。

创建一个管道文件
命名管道可以再命令行上创建。
mkfifo 文件名
这里的p就代表管道文件。
这个意思就是将“hello world”输出重定向到管道文件中,此时这个脚本已经运行起来了,现在只往管道文件中写了,但是没有人读,那么就会阻塞在这里。
在另一个窗口使用cat就可以拿到数据了。

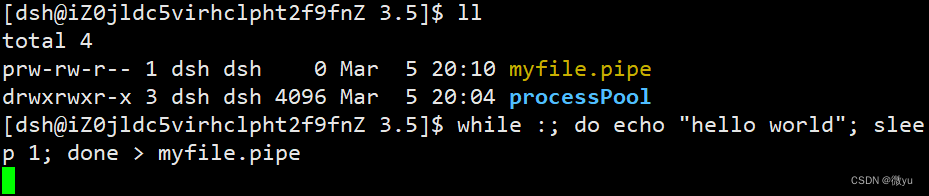

在代码中创建管道
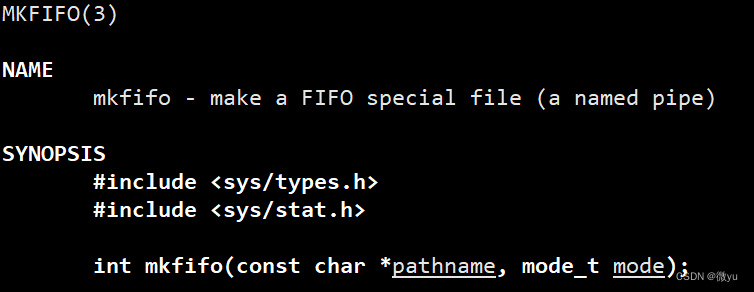
命名管道也可以在代码中创建。
- 参数:pathname就是要创建的管道文件,有两种做法,一是给出路径,二是直接写文件名默认创建到当前路径下;第二个参数就是文件的权限。
- 返回值:创建成功返回0,创建失败返回-1。
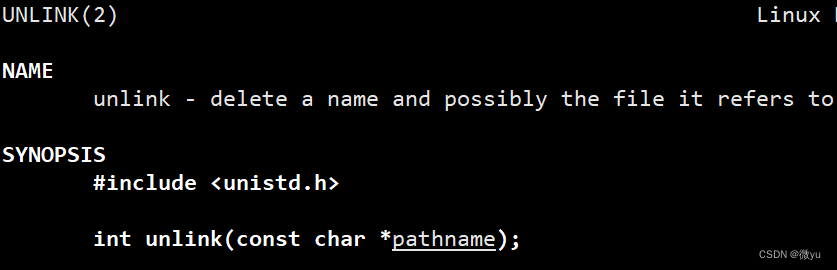
在代码中删除管道
参数:pathname就是路径
返回值:成功返回0,失败返回-1
命名管道实现serve与client通信
下面就创建两个不相干的进程,实现服务端(server.cpp)和客户端(client.cpp)之间的进程通信。
我们需要先让服务端运行起来,让服务端运行后创建一个命名管道文件,然后再以读的方式打开该命名管道文件,之后服务端就可以从该命名管道当中读取客户端发来的信息。
然后再让客户端运行起来,以写的方式打开管道文件,向文件中写入数据。
只需要修改一下代码,创建管道文件之后,再创建子进程,也可以实现多进程通信。


system V共享内存
共享内存的原理
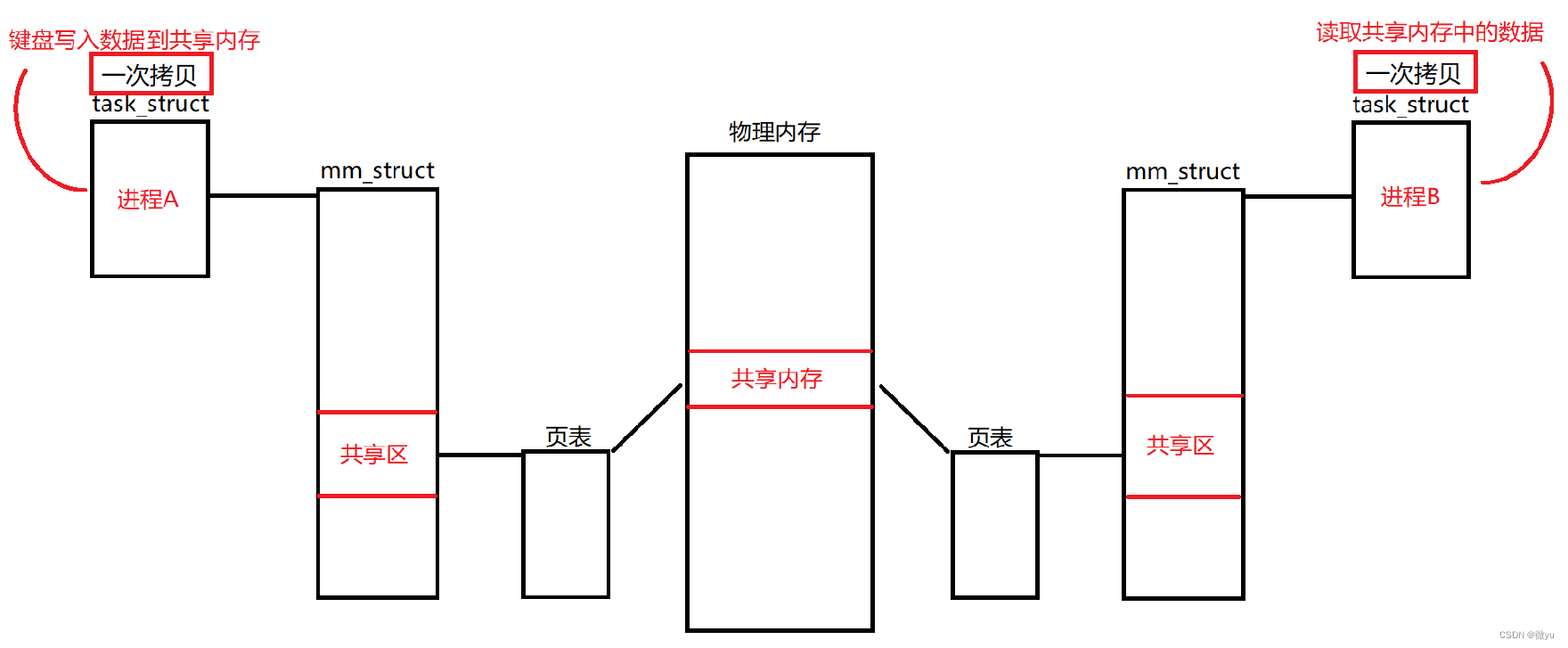
共享内存也要让不同进程看到同一份资源,第一步就要在物理内存当中申请一块内存空间,第二步将这块内存空间与各个进程地址空间通过页表建立映射,第三步返回这块空间的虚拟地址,这样多个进程就看到了同块物理内存,这块物理内存就叫做共享内存。
申请内存的时候,使用的是系统接口,释放的时候把地址空间和内存的映射去掉就可以了。
这个共享内存不属于任何一个进程,它属于操作系统,共享内存是操作系统提供的,它是操作系统专门提供的一个内存模块用来进程间通信,前两种用文件的形式创建管道那是文件的特性,所以操作系统一定会提供相应的接口使用共享内存。
假如操作系统中有很多的共享内存,操作系统也要管理起来,怎么管理就是先描述再组织,所以共享内存 = 共享内存块 + 对应的内核数据结构。

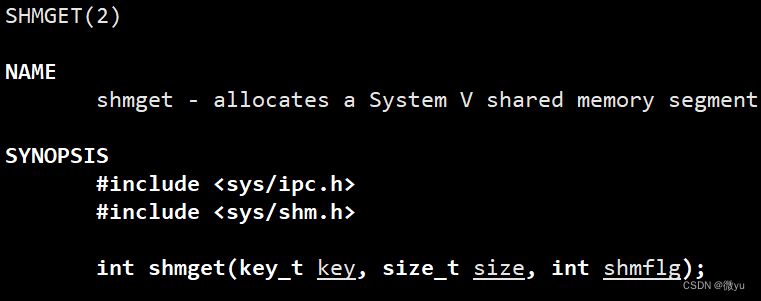
共享内存的创建
参数:
- key表示通过它创建的共享内存具有唯一标识,是几不重要,只要key相同看到的就是同一块共享内存
- size表示创建共享内存的大小。共享内存的大小最好是页(PAGE:4096)的整数倍,如果申请4097,那么会直接申请4096*2 没用的4095就会浪费。
- shmflg表示创建共享内存的方式
- IPC_CREAT:这个选项单独使用,如果底层已经存在共享内存就获取它并返回;如果不存在就创建并返回。
- IPC_EXCL:它单独使用没有意义,和IPC_CREAT一起使用时,如果底层不存在就创建并返回;如果存在就出错并返回。
- 所以两个选项一起使用返回的一定是一个全新的shm;单独使用IPC_CREAT是想让他获取shm的。
返回值:
- 成功返回一个合法的共享内存标识符(用户层标识符,类似文件描述符)。
- 失败就返回-1,错误码被设置。
参数key标识唯一性,那么就让两个进程使用同样的算法规则就可以形成相同的key值,这个工作也不需要我们自己做,我们可以交给ftok。
这个函数不会进行任何的系统调用,它内部就是一套算法,这套算法就是把pathname和proj_id合成一个唯一值,这里pathname是通过这个路径拿到文件的inode编号,用这个编号和proj_id进行数学运算形成一个唯一值key,通过key创建共享内存,两个进程通过同一个key看到的一定是相同的共享内存。
返回值:成功返回key值,失败返回-1。

当我们创建好共享内存的时候可以使用ipcs指令 -m选项查看共享内存。
当我再次运行这个程序却报错了,说文件已经存在。


共享内存的释放
这就意味着我们的程序都结束了,共享内存还在,所以system V IPC资源的生命周期是随内核的。
想要删除有两种方法,第一种就是使用ipcrm -m shmid号,但是手动又不合适,所以还是使用第二种,代码删除。
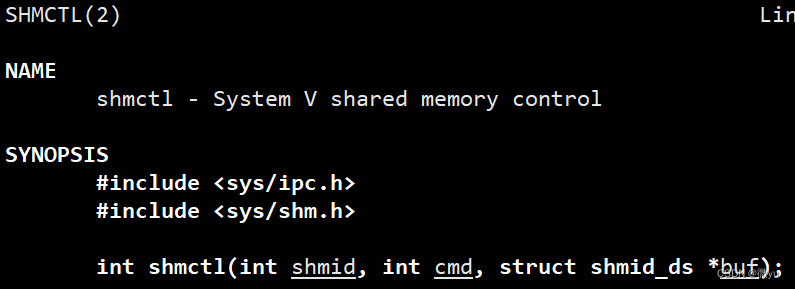
参数:
- shmid就是共享内存标识符,cmd就是选项,想要删除就使用IPC_RMID,最后的buf就是这块共享内存的数据结构,删除设置为nullptr就可以。
返回值:
- 成功返回0,失败返回-1。
还要注意的是:在这个表中有一列是perms,这个的意思就是权限,如果没有权限,那么就无法访问,也就没有意义。
int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666);

共享内存的挂接
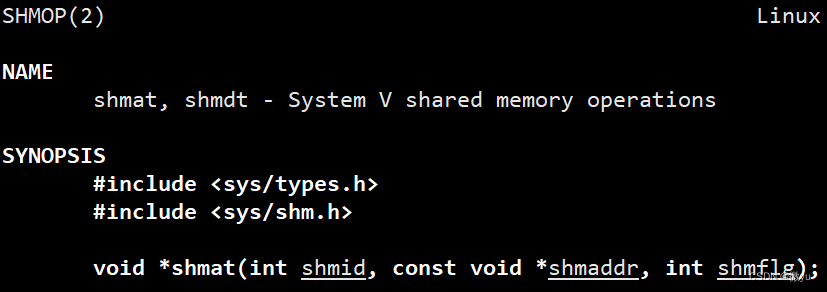
还有一个就是nattch,这个意思就是n个进程和这块共享内存挂接,那么我们就要将指定的共享内存,挂接到自己的地址空间。
参数:
- shmid表示共享内存标识符。
- shmaddr指定共享内存映射到进程地址空间的某一地址,通常设置为NULL,表示让内核自己决定一个合适的位置。
- shmflg表示挂接共享内存时设置的某些属性,例如SHM_RDONLY表示只读或者0表示读取。
返回值:
- 成功返回共享内存映射到进程地址空间的起始地址。
- 失败返回(void*)-1。
使用起来挺像malloc。
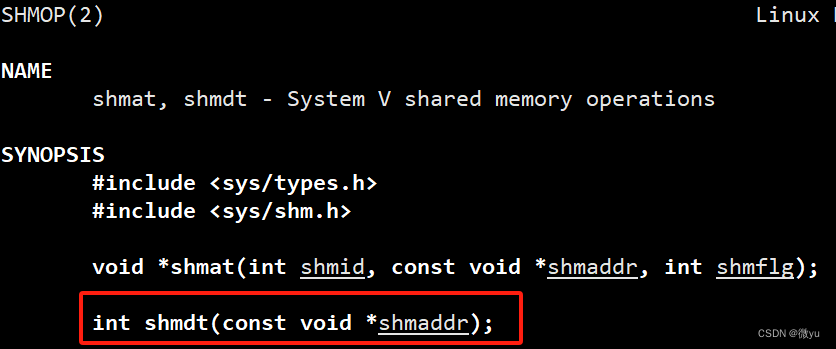
共享内存去关联
只需要把创建时返回的地址填入即可。
成功返回0,失败返回-1。
示例

共享内存实现serve与client通信
不管是pipe实现匿名管道还是mkfifo实现命名管道,他们最终都是对文件进行访问,也就是使用open、close、read、write这些系统调用,因为还是要对文件操作,文件是在内核当中的一种数据结构,所以是操作系统自己维护的。
原来说的进程地址空间,用户空间是0~3G,3~4G是内核空间,内核空间我们无权访问,必须通过系统调用接口,那这里的共享内存是在堆栈之间的共享区,这都属于用户空间,所以不需要使用系统调用接口就可以访问共享内存。
共享内存的特点
拷贝次数少:
只要一方向共享内存中写入,另一方立马能看到,而且共享内存是所有进程间通信最快的,因为它不需要过多的拷贝。
管道就类似于这样,而共享内存大拷贝次数会比较少

缺乏访问控制:
当我们运行上面这些代码的时候会发现,Server一直在读取,不管Client有没有向共享内存中写入,这叫做缺乏访问控制,这时候就有可能出现写端还没有写完,读端已经读了一部分了。
但是管道使用的是系统接口,他是有访问限制的,所以我们可以写一个类来帮我们自动创建和销毁管道文件,当Server端要读取共享内存的数据时,它要等待管道文件的写端写入,当Client端写入数据到共享内存时,这才会往管道文件中写入,从而唤醒管道文件的读端,这样Server再读取共享内存中的数据。
共享内存带来的问题
让不同的进程看到同一块资源这就是进程间通信的前提,但是这也带来了一些时序性的问题,就像上面说的数据还没有写完就被读走了,这就会出问题。
再来说一些概念:
- 一般把多个执行流看到的公共的资源叫做临界资源。
- 每个进程访问临界资源的代码叫做临界区。
- 为了保护临界区,多执行流在任何时刻都只能有一个进程进入临界区,这就叫做互斥。
在非临界区时,多个执行流不受影响,如果不加保护的访问了临界资源就会出问题。
- 原子性:对于一件事要么做要么不做,没有中间状态就成为原子性。

