
- 1Android Studio在导入项目后编译出现java版本错误解决方法
- 2【华为OD机试真题 JS语言】477、路口最短时间问题 | 机试真题+思路参考+代码解析(C卷)
- 3堡垒机上内网 socket 访问端口_mobaxterm socket
- 4从 Elasticsearch 到 Apache Doris,统一日志检索与报表分析,360 企业安全浏览器的数据架构升级实践_elasticsearch apache doris
- 5位运算知识点 (& ^ | )_位运算中&
- 6【每日一题】2834. 找出美丽数组的最小和-2024.3.8
- 7彻底明白Java的IO系统(文摘)---JAVA之精髓IO流 _如果我们想实现“先把要写入文件的数据先缓存到存中,再把缓存中的数据写入文件中
- 8基于Pytorch框架的手写体识别_基于pytorch的字母识别系统0
- 92023年苹果MacBook清理软件哪个好用?CleanMyMac 怎么样?_官网下载的cleanmymac能用多久
- 10最全新手建站教程 如何搭建网站Windows服务器
flink cdc 连接 postgresql kafka_flink postgresql
赞
踩
最近工作中,需要拉取业务库postgresql的数据作实时处理。调研一番,决定用Flink cdc特性,踩了一些坑,特此记录便于日后查阅。
| 组件 | 版本 |
| Flink | 1.12.2 |
| postgresql | 10.10 |
| kafka | 2.12-2.4.0 |
| scala | 2.11.12 |
开干前需要引用一些jar包
flink-sql-connector-postgres-cdc-1.2.0.jar -- flink cdc 连接到pgsql
flink-format-changelog-json-1.2.0.jar -- flink 数据sink到kafka时格式化
flink-connector-kafka_2.12-1.12.2.jar -- flink 连接到kafka
flink-connector-jdbc_2.12-1.12.2.jar -- flink 连接到jdbc (pgsql、mysql)
jar包、flink和postgresql的传送门:https://pan.baidu.com/s/1LSPDjwfcnuNRc9kuj3uSMA 提取码:1234
1--6步在说明安装postgresql,如果已安装好可直接跳至第7步
1、安装postgresql所需要的依赖
- $ sudo apt-get install libreadline-dev
- $ sudo apt-get install zlib1g
- $ sudo apt-get install zlib1g.dev
- $ sudo apt-get install libreadline-dev
2、 解压;编译安装 PostgreSQL
- $ tar -zxf postgresql-10.10.tar.gz
- $ cd postgresql-10.10
- $ ./configure
- $ make && sudo make install
3、创建一个postgres,并赋予权限
- $ adduser postgres
- $ cd /usr/local/pgsql
- $ mkdir data
- $ chown postgres /usr/local/pgsql/data
- $ su postgres
- $ /usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data
- $ su root
- $ /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data >logfile 2>&1 &
4、启动数据库
- $ cd /usr/local/pgsql/bin
- $ su postgres
- $ ./pg_ctl start -D /usr/local/pgsql/data
5、为 pg_ctl 创建软链接;访问数据库;设置 postgres 数据库密码;退出数据库
- $ ln -s /usr/local/pgsql/bin/pg_ctl /usr/bin/pg_ctl
- $ ./psql
- ALTER USER postgres WITH PASSWORD 'postgres';
- \q
6、配置远程访问
$ vim /usr/local/pgsql/data/pg_hba.conf
并编辑 postgresql.conf 文件,并修改为以下内容:
- $ vim /usr/local/pgsql/data/postgresql.conf
- listen_addresses = '*'
- port = 5432
至此。 PostgreSQL安装完成。
7、打开pgsql的binlog模式, 并重启数据库
- $ vim /usr/local/pgsql/data/postgresql.conf
- wal_level = logical
- $ su postgres
- $ pg_ctl restart -D /usr/local/pgsql/data
8、pg建表语句
- -- 查询表
- CREATE TABLE "public"."cdc_pg_source" (
- "id" int2 NOT NULL DEFAULT NULL,
- "age" int2 DEFAULT NULL,
- "name" varchar(255) COLLATE "pg_catalog"."default" DEFAULT NULL,
- CONSTRAINT "cdc_pg_source_pkey" PRIMARY KEY ("id")
- );
-
- -- 写入表
- CREATE TABLE "public"."cdc_pg_sink" (
- "id" int2 NOT NULL DEFAULT NULL,
- "age" int2 DEFAULT NULL,
- "name" varchar(255) COLLATE "pg_catalog"."default" DEFAULT NULL::character varying,
- CONSTRAINT "cdc_pg_sink_pkey" PRIMARY KEY ("id")
- );
9、 修改表的逻辑复制权限,FULL: 更新和删除包含所有列的先前值
- ALTER TABLE public.cdc_pg_source REPLICA IDENTITY FULL
- ALTER TABLE public.cdc_pg_sink REPLICA IDENTITY FULL
10 、 开启flink服务;进入flink-sql客户端
- FLINK_HOME/bin/start-cluster.sh
- FLINK_HOME/bin/sql-client.sh embedded
11、从postgresql查,写入到postgresql
在flink-sql中创建与pg的映射表, 并执行job (sink.buffer-flush.max-rows :配置刷新前缓冲记录的最大大小)
- -- pg中映射表,source
- CREATE TABLE cdc_pg_source (
- id INT,
- age INT,
- name STRING
- ) WITH (
- 'connector' = 'postgres-cdc',
- 'hostname' = '192.168.1.88',
- 'port' = '5432',
- 'database-name' = 'postgres',
- 'schema-name' = 'public',
- 'username' = 'postgres',
- 'password' = 'postgres',
- 'table-name' = 'cdc_pg_source',
- 'decoding.plugin.name' = 'pgoutput',
- 'debezium.slot.name' = 'cdc_pg_source');
-
- -- pg中映射表,sink
- CREATE TABLE cdc_pg_sink (
- id INT,
- age INT,
- name STRING,
- PRIMARY KEY (id) NOT ENFORCED
- ) WITH (
- 'connector' = 'jdbc',
- 'url' = 'jdbc:postgresql://192.168.1.88:5432/postgres',
- 'username' = 'postgres',
- 'password' = 'postgres',
- 'table-name' = 'cdc_pg_sink',
- 'sink.buffer-flush.max-rows' = '1');
-
- -- flink job
- INSERT INTO cdc_pg_sink select * from cdc_pg_source;

flink web UI 查看job已经在运行中

12 、从postgresql查,写入到kafka
注意: debezium.slot.name的值要唯一,不然会报错:Failed to start replication stream at LSN{0/1608BC8};
when setting up multiple connectors for the same database host,
please make sure to use a distinct replication slot name for each.
在第11步pg写pg时,pg中的表 'cdc_pg_source'已经映射成'debezium.slot.name' = 'cdc_pg_source', 同一张表再sink到kafka时,要把'debezium.slot.name'重新赋值
- -- pg映射表,source
- CREATE TABLE cdc_pg_source_kafka (
- id INT,
- age INT,
- name STRING
- ) WITH (
- 'connector' = 'postgres-cdc',
- 'hostname' = '192.168.1.88',
- 'port' = '5432',
- 'database-name' = 'postgres',
- 'schema-name' = 'public',
- 'username' = 'postgres',
- 'password' = 'postgres',
- 'table-name' = 'cdc_pg_source',
- 'decoding.plugin.name' = 'pgoutput',
- 'debezium.slot.name' = 'cdc_pg_source_kafka');
-
- -- 创建的表sink到kafka
- CREATE TABLE pg_to_kafka (
- id INT,
- age INT,
- name STRING
- ) WITH (
- 'connector' = 'kafka',
- 'topic' = 'pg_to_kafka',
- 'scan.startup.mode' = 'earliest-offset',
- 'properties.bootstrap.servers' = '192.168.1.88:9092',
- 'format' = 'changelog-json');
-
- -- 写入到kafka
- INSERT INTO pg_to_kafka select * from cdc_pg_source_kafka ;
flink web UI 查看job已经在运行中
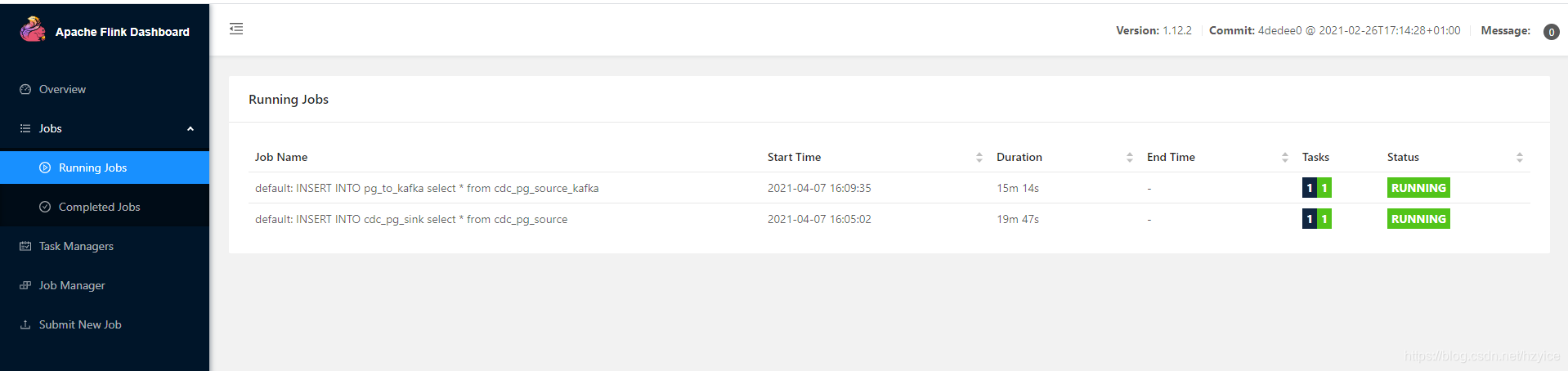
查看kafka topic 列表,flink-sql客户端的topic已经创建

消费创建的topic,已经有数据打印出来

complete

