
- 1设置Linux时区和时间_linux 修改时区为北京
- 2嵌入式系统在工业自动化中的智能化和自适应控制_自适应嵌入式控制
- 3Golang | Leetcode Golang题解之第229题多数元素II
- 4应急响应-战后溯源&IP&ID追踪&URL反查&攻击画像_追踪溯源ip
- 5顶会ICLR2024论文Time-LLM:基于大语言模型的时间序列预测_松鼠ai首席科学家文青松
- 6贪心法之柠檬水找零_贪心法柠檬水找零
- 7python中列表(list)拼接的三种方法_list拼接
- 8Android Studio中Gradle依赖详解
- 9PCA算法原理_pca算法的基本原理
- 10什么是百度快照劫持?百度快照劫持原理和解决办法
Flink学习
赞
踩
Flink学习
Flink基础
实时计算的概念
数据和业务形成闭环

数据的价值时效性:数据的价值随着时间延迟迅速降低
越快越有竞争力->实时计算
大数据计算的一些概念:
根据处理时间:
- 实时计算 :数据实时处理 结果实时存储
- 离线计算 :数据延迟处理 N+1
根据处理方式:
流式处理:一次处理一条或少量 状态小
批量处理:处理大量数据 处理完返回结果
离线计算与实时计算

主流开源实时计算框架:storm,sparkstreaming,Flink
storm:
Storm是Twitter开源的分布式实时大数据处理框架
优势:框架简单,学习成本低 实时性很好,可以提供毫秒级延迟 稳定性很好,框架比较成熟
劣势:编程成本较高 框架处理逻辑和批处理完全不一样,无法共用代码 框架Debug较为复杂
配套框架:HBase Redis 关系型数据库 Kafka
sparkstreaming:
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理。
优势:
- 编程原语丰富,编程简单
- 框架封装层级较高,封装性好
- 可以共用批处理处理逻辑,兼容性好
- 基于Spark,可以无缝内嵌Spark其他子项目,如Spark Sql,MLlib等
劣势:
微批处理,时间延迟大 稳定性相对较差 机器性能消耗较大
配套框架:HBase HDFS Redis 关系型数据库 Kafka
Flink:
Apache Flink是一种可以处理批处理任务的流处理框架
优势:
Flink流处理为先的方法可提供低延迟,高吞吐率,近乎逐项处理的能力
Flink的很多组件是自行管理的
通过多种方式对工作进行分析进而优化任务
提供了基于Web的调度视图
配套框架:HBase HDFS Redis 关系型数据库 Kafka
主流实时计算框架对比

Spark Streaming微批处理 vs. Flink流式处理:

Apache Flink简介
Apache Flink 是一个实时计算框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
- 无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
Apache Flink特性:
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有反压功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理,避免了出现oom
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
Apache Flink组件栈:

IDEA搭建本地环境
新建项目,添加依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-walkthrough-common</artifactId> <version>1.15.4</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>1.15.4</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>1.15.4</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
一个例子:WordCount
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class Demo01StreamWordCount { public static void main(String[] args) throws Exception { // 1、构建Flink环境 StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment(); // 手动改变任务的并行度 env.setParallelism(2); env.setBufferTimeout(200); // 2、通过Socket模拟无界流环境,方便FLink处理 // 虚拟机启动:nc -lk 8888 // 从Source构建第一个DataStream DataStream<String> lineDS = env.socketTextStream("master", 8888); // 统计每个单词的数量 // 第一步:将每行数据的每个单词切出来并进行扁平化处理 DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() { /** * * @param line DS中的一条数据 * @param out 通过collect方法将数据发送到下游 * @throws Exception */ @Override public void flatMap(String line, Collector<String> out) throws Exception { for (String word : line.split(",")) { // 将每个单词发送到下游 out.collect(word); } } }); // 第二步:将每个单词变成 KV格式,V置为1 DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String word) throws Exception { return Tuple2.of(word, 1); } }); // 第三步:按每一个单词进行分组 // keyBy之后数据流会进行分组,相同的key会进入同一个线程中被处理 // 传递数据的规则:hash取余(线程总数,默认CPU的总线程数)原理 KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { @Override public String getKey(Tuple2<String, Integer> tuple2) throws Exception { return tuple2.f0; } }); // 第四步:对1进行聚合sum DataStream<Tuple2<String, Integer>> wordCntDS = keyedDS.sum(1); // 3、打印结果:将DS中的内容Sink到控制台 wordCntDS.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
Flink底层原理:

flink实现批处理:
批处理wordcount
设置Flink程序的处理方式:默认是流处理
- BATCH:批处理,只能处理有界流,底层是MR模型,可以进行预聚合
- STREAMING:流处理,可以处理无界流,也可以处理有界流,底层是持续流模型,数据一条一条处理
- AUTOMATIC:自动判断,当所有的Source都是有界流则使用BATCH模式,当Source中有一个是无界流则会使用STREAMING模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class Demo02BatchWordCount { public static void main(String[] args) throws Exception { // 1、构建环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置Flink程序的处理方式:默认是流处理 /* * BATCH:批处理,只能处理有界流,底层是MR模型,可以进行预聚合 * STREAMING:流处理,可以处理无界流,也可以处理有界流,底层是持续流模型,数据一条一条处理 * AUTOMATIC:自动判断,当所有的Source都是有界流则使用BATCH模式,当Source中有一个是无界流则会使用STREAMING模式 */ env.setRuntimeMode(RuntimeExecutionMode.BATCH); // 2、获得第一个DS // 通过readTextFile可以基于文件构建有界流 DataStream<String> wordsFileDS = env.readTextFile("flink/data/words.txt"); // 3、DS之间的转换 // 统计每个单词的数量 // 第一步:将每行数据的每个单词切出来并进行扁平化处理 DataStream<String> wordsDS = wordsFileDS.flatMap(new FlatMapFunction<String, String>() { /** * * @param line DS中的一条数据 * @param out 通过collect方法将数据发送到下游 * @throws Exception */ @Override public void flatMap(String line, Collector<String> out) throws Exception { for (String word : line.split(",")) { // 将每个单词发送到下游 out.collect(word); } } }); // 第二步:将每个单词变成 KV格式,V置为1 DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String word) throws Exception { return Tuple2.of(word, 1); } }); // 第三步:按每一个单词进行分组 // keyBy之后数据流会进行分组,相同的key会进入同一个线程中被处理 // 传递数据的规则:hash取余(线程总数,默认CPU的总线程数)原理 KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { @Override public String getKey(Tuple2<String, Integer> tuple2) throws Exception { return tuple2.f0; } }); // 第四步:对1进行聚合sum DataStream<Tuple2<String, Integer>> wordCntDS = keyedDS.sum(1); // 4、最终结果的处理(保存/输出打印) wordCntDS.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79

简写代码:
Flink处理逻辑传入的方式:
1.new XXXFunction 使用匿名内部类
// 使用自定类实现接口中抽象的方法
wordsFileDS.flatMap(new MyFunction()).print();
class MyFunction implements FlatMapFunction<String,String>{
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
for (String word : line.split(",")) {
// 将每个单词发送到下游
out.collect(word);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.使用lambda表达式
// 3、DS之间的转换 // 统计每个单词的数量 // 第一步:将每行数据的每个单词切出来并进行扁平化处理 // DataStream<String> wordsDS = wordsFileDS.flatMap(new FlatMapFunction<String, String>() { // /** // * // * @param line DS中的一条数据 // * @param out 通过collect方法将数据发送到下游 // * @throws Exception // */ // @Override // public void flatMap(String line, Collector<String> out) throws Exception { // for (String word : line.split(",")) { // // 将每个单词发送到下游 // out.collect(word); // } // } // }); // 使用Lambda表达式 /* * ()->{} * 通过 -> 分隔,左边是函数的参数,右边是函数实现的具体逻辑 */ DataStream<String> wordsDS = wordsFileDS.flatMap((line, out) -> { for (String word : line.split(",")) { out.collect(word); } }, Types.STRING); // 使用自定类实现接口中抽象的方法 // wordsFileDS.flatMap(new MyFunction()).print(); // 第二步:将每个单词变成 KV格式,V置为1 // DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() { // @Override // public Tuple2<String, Integer> map(String word) throws Exception { // return Tuple2.of(word, 1); // } // }); DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)); // 第三步:按每一个单词进行分组 // keyBy之后数据流会进行分组,相同的key会进入同一个线程中被处理 // 传递数据的规则:hash取余(线程总数,默认CPU的总线程数)原理 // KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { // @Override // public String getKey(Tuple2<String, Integer> tuple2) throws Exception { // return tuple2.f0; // } // }); KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(kv -> kv.f0, Types.STRING); // 第四步:对1进行聚合sum DataStream<Tuple2<String, Integer>> wordCntDS = keyedDS.sum(1); // 4、最终结果的处理(保存/输出打印) wordCntDS.print(); env.execute();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
Flink Source
Flink 在流处理和批处理上的 source 大概有 4 类:
- 基于本地集合的 source、
- 基于文件的 source、
- 基于网络套接字的 source、
- 自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
1.基于本地集合的 source
import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; public class Demo01ListSource { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 本地集合Source ArrayList<String> arrList = new ArrayList<>(); arrList.add("flink"); arrList.add("flink"); arrList.add("flink"); arrList.add("flink"); arrList.add("flink"); // 有界流 DataStream<String> listDS = env.fromCollection(arrList); listDS.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.基于文件的 source
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.15.4</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
.monitorContinuously(Duration.ofSeconds(5)) 监控一个文件夹 无界流
import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.connector.file.src.FileSource; import org.apache.flink.connector.file.src.reader.TextLineInputFormat; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.time.Duration; public class Demo02FileSource { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 旧版写法 // 默认是有界流 // DataStreamSource<String> wordsDS = env.readTextFile("flink/data/words.txt"); //新版本写法(流批合一):FileSource 有界流 默认 FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("flink/data/words.txt")).build(); // 转换成DS DataStream<String> fileDS = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"fileSource"); // fileDS.print(); // 将读取文件变成无界流 FileSource<String> fileSource1 = FileSource.forRecordStreamFormat( new TextLineInputFormat(), new Path("flink/data/words") )//类似Flume中的spool dir,可以监控一个目录下文件的变化 .monitorContinuously(Duration.ofSeconds(5)) .build(); DataStreamSource<String> fileDS1 = env.fromSource(fileSource1, WatermarkStrategy.noWatermarks(), "fileSource1"); fileDS1.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
3.基于网络套接字的 source
socketTextStream
4.自定义Source
import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; public class Demo03MySource { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // env.fromSource() DataStream<String> mySourceDS = env.addSource(new MySource()); mySourceDS.print(); env.execute(); } } // 自定义一个source class MySource implements SourceFunction<String>{ // Source启动时会执行 // run方法如果会结束,则Source会得到一个有界流 // run方法如果不会结束,则Source会得到一个无界流 @Override public void run(SourceContext<String> s) throws Exception { System.out.println("run方法开始喽"); // s 可以通过collect方法向下游发送数据 long cot = 0L; while (true){ s.collect(cot+""); cot ++; // 休眠一会 Thread.sleep(1000); } } // Source结束时会执行 @Override public void cancel() { System.out.println("source结束了"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
连接Mysql
添加依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; // 读mysql学生数据 求班级人数 public class Demo04MysqlSource { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<Students> stuDS = env.addSource(new MySource2()); // stuDS.print(); // 统计班级人数 DataStream<Tuple2<String, Integer>> clazzCntDS = stuDS .map(stu -> Tuple2.of(stu.clazz, 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .sum(1); clazzCntDS.print(); // 统计性别人数 DataStream<Tuple2<String, Integer>> genderCntDS = stuDS .map(stu -> Tuple2.of(stu.gender, 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .sum(1); genderCntDS.print(); env.execute(); } } class MySource2 implements SourceFunction<Students>{ @Override public void run(SourceContext sc) throws Exception { // run方法只会执行一次 // 建立连接 Connection conn = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata30", "root", "123456"); // 创建statement Statement st = conn.createStatement(); // 执行查询 ResultSet rs = st.executeQuery("select * from students"); //提取数据 结构化数据 定义类接收 while (rs.next()){ long id = rs.getLong("id"); String name = rs.getString("name"); int age = rs.getInt("age"); String gender = rs.getString("gender"); String clazz = rs.getString("clazz"); Students stu = new Students(id, name, age, gender, clazz); sc.collect(stu); } rs.close(); st.close(); conn.close(); } @Override public void cancel() { } } // 自定义学生类 接收数据 class Students { Long id; String name; Integer age; String gender; String clazz; // 构造方法 public Students(Long id, String name, Integer age, String gender, String clazz) { this.id = id; this.name = name; this.age = age; this.gender = gender; this.clazz = clazz; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
Flink Sink
Flink 将转换计算后的数据发送的地点 。
Flink 常见的 Sink 大概有如下几类:
- 写入文件、
- 打印出来、
- 写入 socket 、
- 自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
1.从socket接入写入文件
import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.configuration.MemorySize; import org.apache.flink.connector.file.sink.FileSink; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.time.Duration; public class Demo01FileSink { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lineDS = env.socketTextStream("master", 8888); // 构建FileSink FileSink<String> fileSink = FileSink .<String>forRowFormat(new Path("flink/data/fileSink"), new SimpleStringEncoder<String>("UTF-8")) .withRollingPolicy( DefaultRollingPolicy.builder() .withRolloverInterval(Duration.ofSeconds(10)) .withInactivityInterval(Duration.ofSeconds(10)) .withMaxPartSize(MemorySize.ofMebiBytes(1)) .build()) .build(); lineDS.sinkTo(fileSink); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2.自定义Sink
import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.SinkFunction; import java.util.ArrayList; public class Demo02MySink { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<String> arrList = new ArrayList<>(); arrList.add("flink"); arrList.add("flink"); arrList.add("flink"); arrList.add("flink"); DataStreamSource<String> ds = env.fromCollection(arrList); ds.addSink(new MySinkFunction()); env.execute(); } } class MySinkFunction implements SinkFunction<String>{ @Override public void invoke(String value, Context context) throws Exception { System.out.println("进入了invoke方法"); // invoke 每一条数据会执行一次 // 最终数据需要sink到哪里,就对value进行处理即可 System.out.println(value); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Transformation
Transformation:
数据转换的各种操作,有 Map / FlatMap / Filter /KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,
操作很多,可以将数据转换计算成你想要的数据。
Map
import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo01Map { public static void main(String[] args) throws Exception { // 传入一条数据返回一条数据 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds = env.socketTextStream("master", 8888); // 1、使用匿名内部类 DataStream<Tuple2<String, Integer>> mapDS = ds.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String word) throws Exception { return Tuple2.of(word, 1); } }); // mapDS.print(); // 2、使用lambda表达式 DataStream<Tuple2<String, Integer>> mapDS2 = ds.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)); mapDS2.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
FlatMap
需要两个参数
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class Demo02FlatMap { public static void main(String[] args) throws Exception { // 传入一条数据返回多条数据,类似UDTF函数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds = env.socketTextStream("master", 8888); // 1、使用匿名内部类 SingleOutputStreamOperator<Tuple2<String, Integer>> flatMapDS01 = ds.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { for (String word : line.split(",")) { out.collect(Tuple2.of(word, 1)); } } }); flatMapDS01.print(); // 2、使用lambda表达式 SingleOutputStreamOperator<Tuple> flatMapDS02 = ds.flatMap((line, out) -> { for (String word : line.split(",")) { out.collect(Tuple2.of(word, 1)); } }, Types.TUPLE(Types.STRING, Types.INT)); flatMapDS02.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
Filter
import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo03Filter { public static void main(String[] args) throws Exception { // 过滤数据,注意返回值必须是布尔类型,返回true则保留数据,返回false则过滤数据 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds = env.socketTextStream("master", 8888); // 只输出大于10的数字 SingleOutputStreamOperator<String> filterDS = ds.filter(new FilterFunction<String>() { @Override public boolean filter(String value) throws Exception { return Integer.parseInt(value) > 10; } }); filterDS.print(); ds.filter(value -> Integer.parseInt(value) > 10).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
KeyBy
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo04KeyBy { public static void main(String[] args) throws Exception { // 用于就数据流分组,让相同的Key进入到同一个任务中进行处理,后续可以跟聚合操作 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds = env.socketTextStream("master", 8888); KeyedStream<String, String> keyByDS = ds.keyBy(new KeySelector<String, String>() { @Override public String getKey(String value) throws Exception { return value; } }); keyByDS.print(); ds.keyBy(value -> value.toLowerCase(), Types.STRING).print(); ds.keyBy(String::toLowerCase, Types.STRING).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Reduce
import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo05Reduce { public static void main(String[] args) throws Exception { // 用于对KeyBy之后的数据流进行聚合计算 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds = env.socketTextStream("master", 8888); // 统计班级的平均年龄 并计算每个班的人数 /* * 文科一班,20 * 文科一班,22 * 文科一班,21 * 文科一班,20 * 文科一班,22 * * 理科一班,20 * 理科一班,21 * 理科一班,20 * 理科一班,21 * 理科一班,20 * */ SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> kvDS = ds.map(line -> { String[] split = line.split(","); String clazz = split[0]; int age = Integer.parseInt(split[1]); return Tuple3.of(clazz, age, 1); }, Types.TUPLE(Types.STRING, Types.INT, Types.INT)); KeyedStream<Tuple3<String, Integer, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0, Types.STRING); keyByDS.reduce(new ReduceFunction<Tuple3<String, Integer, Integer>>() { @Override public Tuple3<String, Integer, Integer> reduce(Tuple3<String, Integer, Integer> value1, Tuple3<String, Integer, Integer> value2) throws Exception { return Tuple3.of(value1.f0, value1.f1 + value2.f1, value1.f2 + value2.f2); } }).map(t3 -> Tuple2.of(t3.f0, (double) t3.f1 / t3.f2),Types.TUPLE(Types.STRING,Types.DOUBLE)) .print(); keyByDS.reduce((v1,v2)->Tuple3.of(v1.f0, v1.f1 + v2.f1, v1.f2 + v2.f2)).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
Window
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; public class Demo06Window { public static void main(String[] args) throws Exception { // Flink窗口操作:时间、计数、会话 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds = env.socketTextStream("master", 8888); SingleOutputStreamOperator<Tuple2<String, Integer>> kvDS = ds.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)); // 每隔5s钟统计每个单词的数量 ---> 滚动窗口实现 SingleOutputStreamOperator<Tuple2<String, Integer>> outputDS01 = kvDS .keyBy(kv -> kv.f0, Types.STRING) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .sum(1); // outputDS01.print(); // 每隔5s钟统计最近10s内的每个单词的数量 ---> 滑动窗口实现 kvDS .keyBy(kv -> kv.f0, Types.STRING) .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) .sum(1) .print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Union
import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo07Union { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds01 = env.socketTextStream("master", 8888); DataStream<String> ds02 = env.socketTextStream("master", 9999); DataStream<String> unionDS = ds01.union(ds02); // union 就是将两个相同结构的DS合并成一个DS unionDS.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Process 底层的逻辑
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; public class Demo08Process { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds01 = env.socketTextStream("master", 8888); ds01.process(new ProcessFunction<String, Object>() { /* * 每进来一条数据就会执行一次 * value :一条数据 * ctx:可以获取任务执行时的信息 * out:用于输出数据 */ @Override public void processElement(String value, ProcessFunction<String, Object>.Context ctx, Collector<Object> out) throws Exception { // 通过processElement实现Map算子操作 out.collect(Tuple2.of(value, 1)); // 通过processElement实现flatMap算子操作 for (String word : value.split(",")) { out.collect(word); } // 通过processElement实现filter算子操作 if("java".equals(value)){ out.collect("java ok"); } } }).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
KeyBy之后的Process
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import java.util.HashMap; public class Demo09KeyByProcess { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds01 = env.socketTextStream("master", 8888); KeyedStream<Tuple2<String, Integer>, String> keyedDS = ds01.process(new ProcessFunction<String, Tuple2<String, Integer>>() { @Override public void processElement(String value, ProcessFunction<String, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception { for (String word : value.split(",")) { out.collect(Tuple2.of(word, 1)); } } }).keyBy(t2 -> t2.f0, Types.STRING); // 基于分组之后的数据流同样可以调用process方法 keyedDS .process(new KeyedProcessFunction<String, Tuple2<String, Integer>, String>() { HashMap<String, Integer> wordCntMap; // 当KeyedProcessFunction构建时只会执行一次 @Override public void open(Configuration parameters) throws Exception { wordCntMap = new HashMap<String, Integer>(); } // 每一条数据会执行一次 @Override public void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<String, Tuple2<String, Integer>, String>.Context ctx, Collector<String> out) throws Exception { // 通过process实现word count // 判断word是不是第一次进入,通过HashMap查找word是否有count值 String word = value.f0; int cnt = 1; if (wordCntMap.containsKey(word)) { int newCnt = wordCntMap.get(word) + 1; wordCntMap.put(word, newCnt); cnt = newCnt; } else { wordCntMap.put(word, 1); } out.collect(word + ":" + cnt); } }).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
Flink架构及原理
Flink集群核心组件:client,JobManager,TaskManager
当 Flink 集群启动后,首先会启动一个 JobManager 和一个或多个的 TaskManager。
JobManager负责作业调度,收集TaskManager的Heartbeat和统计信息,
TaskManager 之间以流的形式进行数据的传输。
搭建Flink集群
1.独立集群
版本:1.15.4
1、上传解压配置环境变量
# 解压
tar -xvf flink-1.15.4-bin-scala_2.12.tgz
# 配置环境变量
vim /etc/profile
FLINK_HOME=/usr/local/soft/flink-1.15.4
export PATH=$FLINK_HOME/bin:$PATH
source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2、修改配置文件
# 1、修改 flink-conf.yaml # 修改以下配置 jobmanager.rpc.address: master jobmanager.bind-host: 0.0.0.0 taskmanager.bind-host: 0.0.0.0 taskmanager.host: node1/node2 # node1和node2需要单独改成对应主机名 taskmanager.numberOfTaskSlots: 4 rest.address: master rest.bind-address: 0.0.0.0 # 2、masters master:8081 # 3、workers node1 node2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3、同步到所有节点
scp -r flink-1.15.4/ node1:`pwd`
scp -r flink-1.15.4/ node2:`pwd`
# 分别修改node1和node2中taskmanager.host
taskmanager.host: node1/node2
- 1
- 2
- 3
- 4
- 5
4、启动Flink集群
# 启动集群
start-cluster.sh
# 关闭独立集群
stop-cluster.sh
# web ui
http://master:8081
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5、提交任务
# 1、将代码打包上传到服务器中运行
flink run -c com.shujia.flink.core.Demo01StreamWordCount flink-1.0.jar
# 2、在网页中直接上传提交
- 1
- 2
- 3
- 4


任务成功运行,在8888端口打一些数据,可以得到结果:
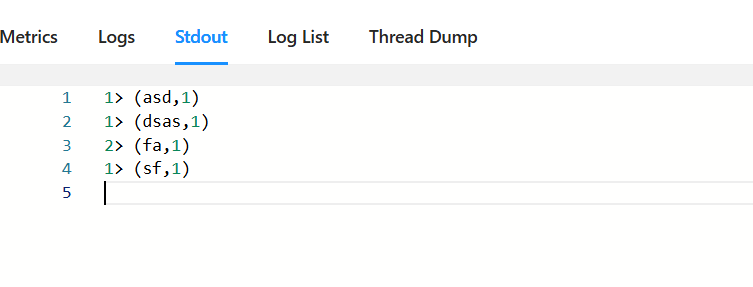

2、Flink on YARN
1、整合HADOOP
# 在环境变量中增加HADOOP_CLASSPATH
vim /etc/profile
# 在最后面添加
export HADOOP_CLASSPATH=`hadoop classpath`
source /etc/profile
# 启动hadoop
start-all.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、Application mode
1、相当于spark的 cluster
2、在本地没有详细的错误日志
3、一般用于生产
4、直接提交任务,每一个任务单独启动一个JobManager和多个taskManager
# 提交任务到yarn上运行
flink run-application -t yarn-application -c com.shujia.flink.core.Demo01StreamWordCount flink-1.0.jar
# 查看错误日志
yarn logs -applicationId application_1705563704331_0002
- 1
- 2
- 3
- 4
- 5

打数据:

3、Per-Job Cluster Mode
1、相当于spark 的client模式
2、在本地可以看到错误日志
3、一般用于测试
4、直接提交任务,每一个任务单独启动一个JobManager和多个taskManager
# 提交任务
flink run -t yarn-per-job -c com.shujia.flink.core.Demo01StreamWordCount flink-1.0.jar
- 1
- 2
4、Session Mode
1、会话模式是先在yarn启动启动一个JobManager,再提交任务,提交任务时动态申请taskmanager
2、任务共享同一个JobManager
# 1、启动会话集群 后台启动
yarn-session.sh -d
# 2、提交任务
# 可以在命令行提交
flink run -t yarn-session -Dyarn.application.id=application_1722254091246_0002 -c com.shujia.flink.core.Demo01StreamWordCount flink-1.0.jar
# 在网页中提交 submit
#修改hadoop中的capacity-scheduler.xml 使得可以多个任务同时跑,不用在等待资源
yarn.scheduler.capacity.maximum-am-resource-percent的value 改大一点
#分发到各个节点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

三种模式的区别
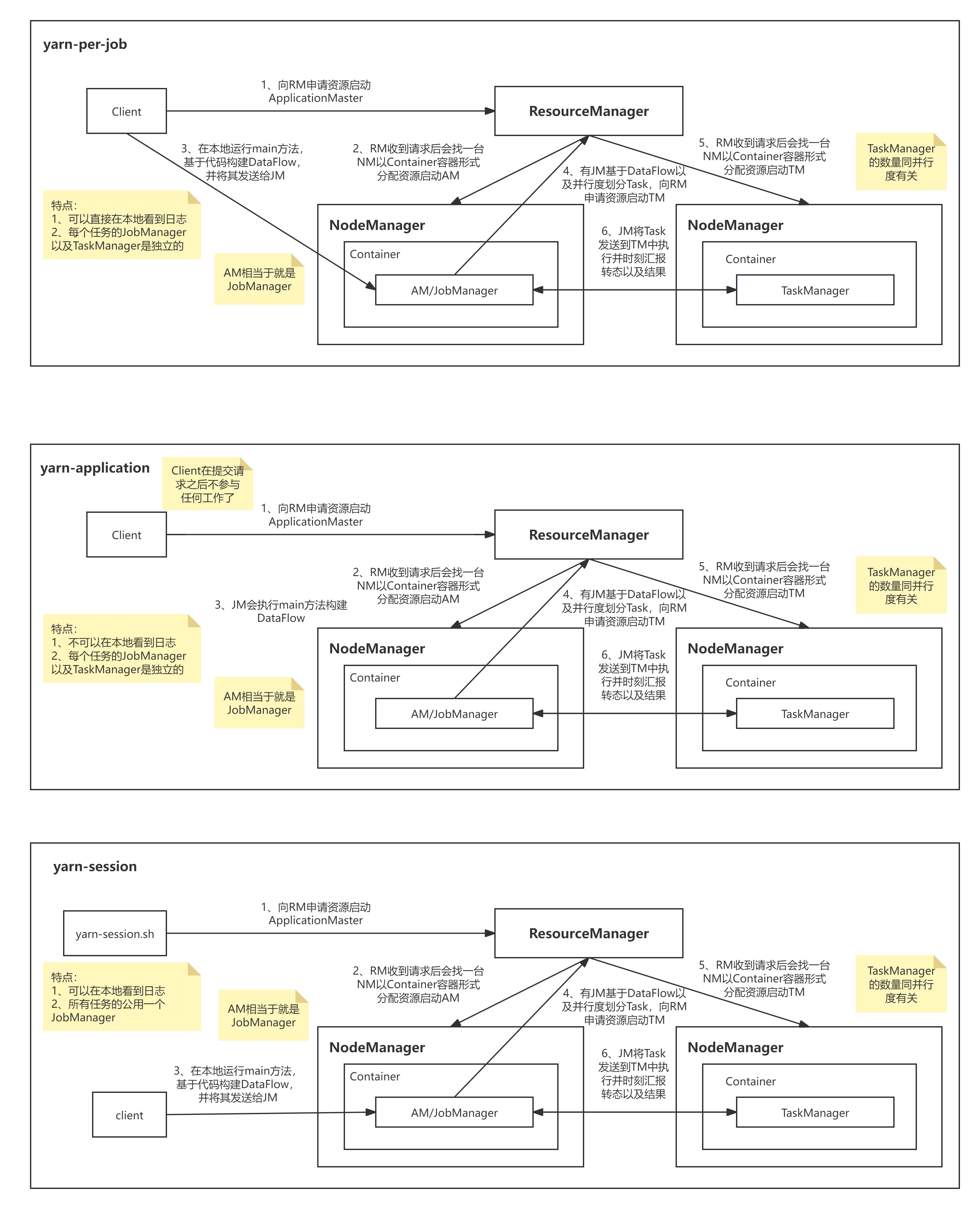
Flink并行度详解
如何设置并行度?
1、考虑吞吐量
有聚合操作的任务:1w条/s 一个并行度
无聚合操作的任务:10w条/s 一个并行度
2、考虑集群本身的资源
Task的数量由并行度以及有无Shuffle一起决定
Task Slot数量 是由任务中最大的并行度决定
TaskManager的数量由配置文件中每个TaskManager设置的Slot数量及任务所需的Slot数量一起决定
三种方式设置并行度:
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo03Parallelism { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 1、通过env设置,不推荐,如果需要台调整并行度得修改代码重新打包提交任务 4个task 3个slot // env.setParallelism(3); DataStreamSource<String> ds = env.socketTextStream("master", 8888); // 2、每个算子可以单独设置并行度,视实际情况决定,一般不常用 SingleOutputStreamOperator<Tuple2<String, Integer>> kvDS = ds .map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)) .setParallelism(4); SingleOutputStreamOperator<Tuple2<String, Integer>> wordCntDS2P = kvDS.keyBy(kv -> kv.f0) .sum(1) .setParallelism(2); // 如果算子不设置并行度则以全局为准 wordCntDS2P.print(); // 3、还可以在提交任务的时候指定并行度,最常用 比较推荐的方式 // 命令行:flink run 可以通过 -p 参数设置全局并行度 // web UI:填写parallelism输入框即可设置,优先级:算子本身的设置 > env做的全局设置 > 提交任务时指定的 > 配置文件flink-conf.yaml env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
Flink事件时间

时间与窗口相关
时间戳和 watermark 都是从 1970-01-01T00:00:00Z 起的 Java 纪元开始,并以毫秒为单位。
.assignTimestampsAndWatermarks
内置 Watermark 生成器 :
单调递增时间戳分配器 WatermarkStrategy.forMonotonousTimestamps();
数据之间存在最大固定延迟的时间戳分配器 WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
.withTimestampAssigner提取数据的某一部分作为事件时间
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import java.time.Duration; public class Demo04EventTime { public static void main(String[] args) throws Exception { // 事件时间:数据本身自带的时间 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 并行度 设置为1可以看到效果 env.setParallelism(1); /* 数据格式:单词,时间戳(很大的整数,Long类型) a,1722233813000 a,1722233814000 a,1722233815000 a,1722233816000 a,1722233817000 a,1722233818000 a,1722233819000 a,1722233820000 a,1722233822000 a,1722233827000 */ DataStreamSource<String> wordTsDS = env.socketTextStream("master", 8888); SingleOutputStreamOperator<Tuple2<String, Long>> mapDS = wordTsDS .map(line -> Tuple2.of(line.split(",")[0], Long.parseLong(line.split(",")[1])), Types.TUPLE(Types.STRING, Types.LONG)); // 指定数据的时间戳,告诉Flink,将其作为事件时间进行处理 SingleOutputStreamOperator<Tuple2<String, Long>> assDS = mapDS .assignTimestampsAndWatermarks( WatermarkStrategy // // 单调递增时间戳策略,不考虑数据乱序问题 // .<Tuple2<String, Long>>forMonotonousTimestamps() // 容忍5s的数据乱序到达,本质上将水位线前移5s,缺点:导致任务延时变大 // 水位线:某个线程中所接收到的数据中最大的时间戳 .<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5)) // 可以提取数据的某一部分作为事件时间 .withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> t2, long recordTimestamp) { return t2.f1; } }) ); // 不管是事件时间还是处理时间都需要搭配窗口操作一起使用 assDS.map(kv -> Tuple2.of(kv.f0, 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) // 窗口触发的条件:水位线超过了窗口的结束时间 .window(TumblingEventTimeWindows.of(Time.seconds(5))) .sum(1) .print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
第一种:forMonotonousTimestamps() 打入数据 时间戳 大于5s后才会计算:
缺点: 乱序的数据无法被计算

第二种 forBoundedOutOfOrderness(Duration.ofSeconds(5)) 水位线前移 会容忍5s的数据乱序到达
缺点:导致任务延时变大


多并行度情况下的水位线
自定义水位线策略
参考链接:https://blog.csdn.net/zznanyou/article/details/121666563
1.在Source之后就指定水位线策略
import com.shujia.flink.event.MyEvent; import org.apache.flink.api.common.eventtime.*; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; public class Demo05WaterMarkStrategy { public static void main(String[] args) throws Exception { // 自定义水位线策略 // 参考链接:https://blog.csdn.net/zznanyou/article/details/121666563 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); DataStreamSource<String> eventDS = env.socketTextStream("master", 8888); // 在Source之后就指定水位线策略 eventDS.assignTimestampsAndWatermarks(new WatermarkStrategy<String>() { // 指定时间戳的提取策略 @Override public TimestampAssigner<String> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return new SerializableTimestampAssigner<String>() { @Override public long extractTimestamp(String element, long recordTimestamp) { return Long.parseLong(element.split(",")[1]); } }; // 简写方式 // return (ele,ts)->Long.parseLong(ele.split(",")[1]); } // 指定水位线的策略 @Override public WatermarkGenerator<String> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new MyWatermarkGenerator(); } }) // 将数据变成KV格式,即:单词,1 .map(line -> Tuple2.of(line.split(",")[0], 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .window(TumblingEventTimeWindows.of(Time.seconds(5))) // 当窗口满足执行条件:1、水位线超过了窗口的结束时间 2、窗口有数据 触发一次process方法 .process(new ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>() { @Override public void process(String s, ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>.Context context, Iterable<Tuple2<String, Integer>> elements, Collector<Tuple2<String, Integer>> out) throws Exception { System.out.println("窗口触发执行了。"); System.out.println("当前水位线为:" + context.currentWatermark() + ",当前窗口的开始时间:" + context.window().getStart() + ",当前窗口的结束时间:" + context.window().getEnd()); // 基于elements做统计 通过out可以将结果发送到下游 } }).print(); env.execute(); } } // 用于Source之后直接指定水位线生成策略 class MyWatermarkGenerator implements WatermarkGenerator<String> { private final long maxOutOfOrderness = 5000; private long currentMaxTimeStamp; // 每来一条数据会处理一次 @Override public void onEvent(String event, long eventTimestamp, WatermarkOutput output) { currentMaxTimeStamp = Math.max(currentMaxTimeStamp, eventTimestamp); System.out.println("当前线程编号为:" + Thread.currentThread().getId() + ",当前水位线为:" + (currentMaxTimeStamp - maxOutOfOrderness)); } // 周期性的执行:env.getConfig().getAutoWatermarkInterval(); 默认是200ms @Override public void onPeriodicEmit(WatermarkOutput output) { // 水位线前移5s output.emitWatermark(new Watermark(currentMaxTimeStamp - maxOutOfOrderness)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
2.在map之后指定水位线生成策略
package com.shujia.flink.core; import org.apache.flink.api.common.eventtime.*; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; public class Demo05WaterMarkStrategy { public static void main(String[] args) throws Exception { // 自定义水位线策略 // 参考链接:https://blog.csdn.net/zznanyou/article/details/121666563 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); DataStreamSource<String> eventDS = env.socketTextStream("master", 8888); // 将每条数据变成MyEvent类型 eventDS.map(new MapFunction<String, MyEvent>() { @Override public MyEvent map(String value) throws Exception { String[] split = value.split(","); return new MyEvent(split[0],Long.parseLong(split[1])); } }).assignTimestampsAndWatermarks(new WatermarkStrategy<MyEvent>() { @Override public TimestampAssigner<MyEvent> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return new SerializableTimestampAssigner<MyEvent>() { @Override public long extractTimestamp(MyEvent element, long recordTimestamp) { return element.getTs(); } }; } @Override public WatermarkGenerator<MyEvent> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new MyMapWatermarkGenerator(); } }).keyBy(my->my.word) .window(TumblingEventTimeWindows.of(Time.seconds(5))) // 当窗口满足执行条件:1、所有线程的水位线都超过了窗口的结束时间 2、窗口有数据 触发一次process方法 .process(new ProcessWindowFunction<MyEvent, String, String, TimeWindow>() { @Override public void process(String s, ProcessWindowFunction<MyEvent, String, String, TimeWindow>.Context context, Iterable<MyEvent> elements, Collector<String> out) throws Exception { System.out.println("窗口触发执行了。"); System.out.println("当前水位线为:" + context.currentWatermark() + ",当前窗口的开始时间:" + context.window().getStart() + ",当前窗口的结束时间:" + context.window().getEnd()); // 基于elements做统计 通过out可以将结果发送到下游 } }).print(); env.execute(); } } // 用于map之后指定水位线生成策略 class MyMapWatermarkGenerator implements WatermarkGenerator<MyEvent> { private final long maxOutOfOrderness = 0; private long currentMaxTimeStamp; // 每来一条数据会处理一次 @Override public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) { currentMaxTimeStamp = Math.max(currentMaxTimeStamp, eventTimestamp); System.out.println("当前线程编号为:" + Thread.currentThread().getId() + ",当前水位线为:" + (currentMaxTimeStamp - maxOutOfOrderness)); } // 周期性的执行:env.getConfig().getAutoWatermarkInterval(); 默认是200ms @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(currentMaxTimeStamp - maxOutOfOrderness)); } } class MyEvent { String word; Long ts; public MyEvent(String word, Long ts) { this.ts = ts; this.word = word; } public Long getTs() { return ts; } public void setTs(Long ts) { this.ts = ts; } public String getWord() { return word; } public void setWord(String word) { this.word = word; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
Flink窗口
时间窗口:
package com.shujia.flink.window; import com.shujia.flink.event.MyEvent; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import java.time.Duration; public class Demo01TimeWindow { public static void main(String[] args) throws Exception { /* * 时间窗口:滚动、滑动 * 时间类型:处理时间、事件时间 */ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<MyEvent> myDS = env.socketTextStream("master", 8888) .map(new MapFunction<String, MyEvent>() { @Override public MyEvent map(String value) throws Exception { String[] split = value.split(","); return new MyEvent(split[0], Long.parseLong(split[1])); } }); // 基于处理时间的滚动、滑动窗口 SingleOutputStreamOperator<Tuple2<String, Integer>> processDS = myDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) // 滚动窗口 每隔5s统计一次 // .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) // 滑动窗口 每隔5s统计最近10s内的数据 .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) .sum(1); // 基于事件时间的滚动、滑动窗口 SingleOutputStreamOperator<MyEvent> assDS = myDS.assignTimestampsAndWatermarks( WatermarkStrategy .<MyEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5)) .withTimestampAssigner((event, ts) -> event.getTs()) ); SingleOutputStreamOperator<Tuple2<String, Integer>> eventDS = assDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) // 滚动窗口,由于水位线前移了5s,整体有5s的延时 // .window(TumblingEventTimeWindows.of(Time.seconds(5))) // 滑动窗口 .window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5))) .sum(1); // processDS.print(); eventDS.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
会话窗口
import com.shujia.flink.event.MyEvent; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows; import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows; import org.apache.flink.streaming.api.windowing.time.Time; public class Demo02Session { public static void main(String[] args) throws Exception { // 会话窗口:当一段时间没有数据,那么就认定此次会话结束并触发窗口的执行 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<MyEvent> myDS = env.socketTextStream("master", 8888) .map(new MapFunction<String, MyEvent>() { @Override public MyEvent map(String value) throws Exception { String[] split = value.split(","); return new MyEvent(split[0], Long.parseLong(split[1])); } }); // 基于处理时间的会话窗口 SingleOutputStreamOperator<Tuple2<String, Integer>> processSessionDS = myDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) //等待10s .window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))) .sum(1); // 基于事件时间的会话窗口 // 指定水位线策略并提供数据中的时间戳解析规则 SingleOutputStreamOperator<MyEvent> assDS = myDS.assignTimestampsAndWatermarks( WatermarkStrategy .<MyEvent>forMonotonousTimestamps() .withTimestampAssigner((e, ts) -> e.getTs()) ); SingleOutputStreamOperator<Tuple2<String, Integer>> eventSessionDS = assDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .window(EventTimeSessionWindows.withGap(Time.seconds(10))) .sum(1); // processSessionDS.print(); eventSessionDS.print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
计数窗口
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo03CountWindow { public static void main(String[] args) throws Exception { // 计数窗口:滚动、滑动 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> ds = env.socketTextStream("master", 8888); ds.map(word-> Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT)) .keyBy(t2->t2.f0) // .countWindow(5) // 每同一个key的5条数据会统计一次 .countWindow(10,5) // 每隔同一个key的5条数据统计最近10条数据 .sum(1) .print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Kafka学习
kafka简介:kafka是一个高吞吐的分布式消息系统
主要作用:缓冲,减压
消息队列:
- 生产者负责生产数据
- 消费者负责消费数据

应用场景:
系统之间解耦合
- queue模型
- publish-subscribe模型
峰值压力缓冲
异步通信
kafka的特点:
消息系统的特点:生存者消费者模型,FIFO
高性能:单节点支持上千个客户端,百MB/s吞吐
持久性:消息直接持久化在普通磁盘上且性能好
分布式:数据副本冗余、流量负载均衡、可扩展
很灵活:消息长时间持久化+Client维护消费状态
kafka为什么快,性能好?
kafka写磁盘是顺序的,所以不断的往前产生,不断的往后写
kafka还用了sendFile的0拷贝技术,提高速度
而且还用到了批量读写,一批批往里写,64K为单位
“零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
kafka集群:

kafka架构:
producer:消息生存者
consumer:消息消费者
broker:kafka集群的server,负责处理消息读、写请求,存储消息
topic:消息队列/分类
broker就是代理,在kafka cluster这一层这里,其实里面是有很多个broker
topic就相当于queue
图里没有画其实还有zookeeper,这个架构里面有些元信息是存在zookeeper上面的,整个集群的管理也和zookeeper有很大的关系
图:

kafka的消息存储和生产消费模型
一个topic分成多个partition
每个partition内部消息强有序,其中的每个消息都有一个序号叫offset(偏移量)
一个partition只对应一个broker,一个broker可以管多个partition
消息不经过内存缓冲,直接写入文件
根据时间策略删除,而不是消费完就删除 (默认7天)
producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略

kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition里面是有序的,相当于有序的队列,其中每个消息都有个序号,比如0到12,从前面读往后面写,一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition
这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念,这个模型带来了很多个好处,这个我们后面再讨论一下这里producer自己决定往哪个partition里面去写,这里有一些的策略,譬如如果hash就不用多个partition之间去join数据了
kafka的消息存储和生产消费模型
consumer自己维护消费到哪个offset
每个consumer都有对应的group
group内是queue消费模型,各个consumer消费不同的partition,因此一个消息在group内只消费一次
group间是publish-subscribe消费模型各个group各自独立消费,互不影响,因此一个消息在被每个group消费一次

Kafka搭建
1、上传解压修改环境变量
# 解压
tar -xvf kafka_2.11-1.0.0.tgz
mv kafka_2.11-1.0.0 kafka-1.0.0
# 配置环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/soft/kafka-1.0.0
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2、修改配置文件
vim config/server.properties
broker.id=0 每一个节点broker.id 要不一样
zookeeper.connect=master:2181,node1:2181,node2:2181/kafka
log.dirs=/usr/local/soft/kafka-1.0.0/data 数据存放的位置
- 1
- 2
- 3
3、将kafka文件同步到node1,node2
# 同步kafka文件
scp -r kafka-1.0.0/ node1:`pwd`
scp -r kafka-1.0.0/ node2:`pwd`
# 修改node1、node2中的/etc/profile,增加Kafka环境变量
KAFKA_HOME=/usr/local/soft/kafka-1.0.0
export PATH=$KAFKA_HOME/bin:$PATH
# 在ndoe1和node2中执行source
source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4、修改node1和node2中的broker.id
vim config/server.properties
# node1
broker.id=1
# node2
broker.id=2
- 1
- 2
- 3
- 4
5、启动kafka
# 1、需要启动zookeeper, kafka使用zk保存元数据 # 需要在每个节点中执行启动的命令 zkServer.sh start # 查看启动的状体 zkServer.sh status # 2、启动kafka,每个节点中都要启动(去中心化的架构) # -daemon后台启动 kafka-server-start.sh -daemon /usr/local/soft/kafka-1.0.0/config/server.properties # 测试是否成功 #生产者 kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic zy # 消费者 --from-beginning #从头消费,, 如果不在执行消费的新的数据 kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic zy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Kafka使用
1、创建topic
在生产和消费数据时,如果topic不存在会自动创建一个分区为1,副本为1的topic
--replication-factor ---每一个分区的副本数量, 同一个分区的副本不能放在同一个节点,副本的数量不能大于kafak集群节点的数量
--partition --分区数, 根据数据量设置
--zookeeper zk的地址,将topic的元数据保存在zookeeper中
kafka-topics.sh --create --zookeeper master:2181,node1:2181,node2:2181/kafka --replication-factor 2 --partitions 3 --topic topic01
- 1
- 2
- 3
- 4
- 5
2、查看topic描述信息
kafka-topics.sh --describe --zookeeper master:2181,node1:2181,node2:2181/kafka --topic topic01
- 1
3、获取所有topic
__consumer_offsetsL kafka用于保存消费便宜量的topic
kafka-topics.sh --list --zookeeper master:2181,node1:2181,node2:2181/kafka
- 1
4、创建控制台生产者
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic topic01
- 1
5、创建控制台消费者
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node3:9092 --from-beginning --topic topic02
- 1
6、kafka数据保存的方式
# 1、保存的文件 /usr/local/soft/kafka_2.11-1.0.0/data # 2,每一个分区每一个副本对应一个目录 # 3、每一个分区目录中可以有多个文件, 文件时滚动生成的 00000000000000000000.log 00000000000000000001.log 00000000000000000002.log # 4、滚动生成文件的策略 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 # 5、文件删除的策略,默认时7天,以文件为单位删除 log.retention.hours=168
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
7.删除一个topic
kafka-topics.sh --delete --topic zy --zookeeper master:2181/kafka
# 会被标记删除,数据还在 会等时间一起删除
- 1
- 2
Kafka Java API
添加依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
创建生产者
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class Demo01KafkaProducer { public static void main(String[] args) { Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092"); properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 创建Kafka 生产者 KafkaProducer<String, String> producer = new KafkaProducer<>(properties); // 向Kafka写数据 如果topic不存在则会自动创建一个副本和分区数都是1的topic producer.send(new ProducerRecord<String,String>("topic02","1500100001,施笑槐,22,女,文科六班")); producer.flush(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

将1000条学生数据写入kafka
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.Properties; public class Demo02KafkaStuProducer { // 将1000条学生数据写入Kafka public static void main(String[] args) throws IOException { Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092"); properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 创建Kafka 生产者 KafkaProducer<String, String> producer = new KafkaProducer<>(properties); // 读取文件 BufferedReader br = new BufferedReader(new FileReader("kafka/data/stu/students.txt")); String line; while ((line = br.readLine()) != null) { producer.send(new ProducerRecord<>("students1000", line)); } producer.flush(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
创建消费者
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.ArrayList; import java.util.Properties; public class Demo03KafkaConsumer { public static void main(String[] args) throws InterruptedException { Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092"); properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); /* * 消费者组的偏移量设定规则: * earliest 相当于from-beginning 从头开始消费 * latest 从最新的数据开始消费 */ properties.setProperty("auto.offset.reset", "earliest"); // 设置消费者组id properties.setProperty("group.id", "grp01"); // 创建Kafka的消费者 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties); ArrayList<String> topic = new ArrayList<>(); topic.add("students1000"); // 指定消费的topic consumer.subscribe(topic); // 一直读 加循环 while (true){ // 超时时间 ConsumerRecords<String, String> records = consumer.poll(10000); for (ConsumerRecord<String, String> record : records) { // 头部信息 // System.out.println(record.headers()); //偏移量 System.out.println(record.offset()); //时间戳 System.out.println(record.timestamp()); //分区 System.out.println(record.partition()); // System.out.println(record.key()); System.out.println(record.value()); } // 避免读太快 Thread.sleep(5000); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
Flink整合kafka
1、idea中整合
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo01KafkaSource { public static void main(String[] args) throws Exception { // 构建flink环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //创建kafkaSource KafkaSource<String> kafkaSource = KafkaSource .<String>builder() .setBootstrapServers("master:9092,node1:9092,node2:9092") .setGroupId("grp001") .setTopics("students1000") /* * 设置当前消费的偏移量位置: * 1、earliest从头开始消费 * 2、latest 从最后开始消费 * 3、timestamp 设置从某个时间戳开始 * 4、offset 设置从哪个偏移量开始 * ...... */ .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); //从kafkaSource接收数据变成DS 无界流 // Topic有几个分区,则KafkaSource有几个并行度去读取Kafka的数据 DataStreamSource<String> DS1 = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource"); // 统计班级人数 DS1 .map(line -> Tuple2.of(line.split(",")[4], 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .sum(1) .print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
读取车辆数据
求平均速度
先构成sink
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.connector.base.DeliveryGuarantee; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo02KafkaSink { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> carDS = env.readTextFile("flink/data/cars_sample.json"); // 创建sink KafkaSink<String> sink = KafkaSink.<String>builder() .setBootstrapServers("master:9092,node1:9092,node2:9092") .setRecordSerializer( KafkaRecordSerializationSchema .builder() .setTopic("cars_json") // 不存在会自动创建 .setValueSerializationSchema(new SimpleStringSchema()) .build() ) /* 设置写入时的语义: 1、AT_LEAST_ONCE:保证数据至少被写入了一次,性能会更好,但是又可能会写入重复的数据 2、EXACTLY_ONCE:保证数据只会写入一次,不多不少,性能会有损耗 */ .setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) .build(); carDS.sinkTo(sink); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
添加依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.49</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
import com.alibaba.fastjson.JSON; import lombok.AllArgsConstructor; import lombok.Getter; import lombok.NoArgsConstructor; import lombok.Setter; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo03CarsAvgSpeed { public static void main(String[] args) throws Exception { // 基于Kafka Cars数据实时统计每条道路的平均车速 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 构建Kafka Source KafkaSource<String> kafkaSource = KafkaSource .<String>builder() .setBootstrapServers("master:9092,node1:9092,node2:9092") .setGroupId("grp001") .setTopics("cars_json") .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); // {"car":"皖AQLXL2","city_code":"340100","county_code":"340111","card":117331031812010,"camera_id":"01012","orientation":"西","road_id":34406326,"time":1614731906,"speed":47.86} DataStreamSource<String> carStrDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "cars"); //处理json数据 SingleOutputStreamOperator<Car> carDS = carStrDS.map(carStr -> JSON.parseObject(carStr, Car.class)); carDS .map(car-> Tuple3.of(car.road_id,car.speed,1), Types.TUPLE(Types.LONG,Types.DOUBLE,Types.INT)) .keyBy(t3->t3.f0,Types.LONG) .reduce(new ReduceFunction<Tuple3<Long, Double, Integer>>() { @Override public Tuple3<Long, Double, Integer> reduce(Tuple3<Long, Double, Integer> value1, Tuple3<Long, Double, Integer> value2) throws Exception { return Tuple3.of(value1.f0, value1.f1 + value2.f1, value1.f2 + value2.f2); } }) .map(t3 -> Tuple2.of(t3.f0, t3.f1 / t3.f2),Types.TUPLE(Types.LONG,Types.DOUBLE)) .print(); env.execute(); } } // 定义一个Car类型 //通过注解的方式加上getset方法,构造器 @Getter @Setter @AllArgsConstructor @NoArgsConstructor class Car{ String car; Integer city_code; Integer county_code; Long card; String camera_id; String orientation; Long road_id; Long time; Double speed; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
2、集群中整合
# 将flink-sql-connector-kafka-{flink.version}.jar包上传到Flink的lib目录下
cd /usr/local/soft/flink-{flink.version}/lib
- 1
- 2
Flink状态与容错
状态:
Flink在计算过程中可以将中间结果保存到状态中,保存到状态中的数据会checkpoint定时持久化到HDFS中
状态的原理
1、状态的数据会先保存在状态后端(HashMapStateBackend:内存的状态后端,EmbeddedRocksDBStateBackend:磁盘的状态后端)
2、当触发checkpoint时会将状态后端中保存的状态的数据持久化到HDFS中
3、当任务执行失败了,重启任务时可以基于HDFS中保存的状态数据恢复任务,保证状态不丢失
有状态算子
package com.shujia.flink.state; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; import java.util.HashMap; public class Demo01State { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds01 = env.socketTextStream("master", 8888); SingleOutputStreamOperator<Tuple2<String,Integer>> wordDS = ds01.flatMap((line, out) -> { for (String word : line.split(",")) { out.collect(Tuple2.of(word, 1)); } }, Types.TUPLE(Types.STRING, Types.INT)); KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordDS.keyBy(t2 -> t2.f0, Types.STRING); // 基于分组之后的数据流同样可以调用process方法 keyedDS .process(new KeyedProcessFunction<String, Tuple2<String, Integer>, String>() { /** * 为了将每个单词当前的计算结果保存起来 * 以便下一次使用 * * 当前的结果——状态 * * 状态:FLink实时任务某一时刻的计算结果以及消费的偏移量 * * 由于HashMap是将数据存储在内存中的,所以状态不能够被持久化 * 如果程序发生了故障,那么无法恢复 * 所以需要一种可靠的存储系统,例如HDFS * 将状态保存到HDFS的过程——CheckPoint */ HashMap<String, Integer> wordCntMap; // 当KeyedProcessFunction构建时只会执行一次 @Override public void open(Configuration parameters) throws Exception { wordCntMap = new HashMap<String, Integer>(); } // 每一条数据会执行一次 @Override public void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<String, Tuple2<String, Integer>, String>.Context ctx, Collector<String> out) throws Exception { // 通过process实现word count // 判断word是不是第一次进入,通过HashMap查找word是否有count值 String word = value.f0; int cnt = 1; if (wordCntMap.containsKey(word)) { int newCnt = wordCntMap.get(word) + 1; wordCntMap.put(word, newCnt); cnt = newCnt; } else { wordCntMap.put(word, 1); } out.collect(word + ":" + cnt); } }).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
package com.shujia.flink.state; import org.apache.flink.api.common.functions.RuntimeContext; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; public class Demo03ValueState { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> ds01 = env.socketTextStream("master", 8888); // 在配置文件中开启了CK,则不需要通过env再设置了 SingleOutputStreamOperator<Tuple2<String,Integer>> wordDS = ds01.flatMap((line, out) -> { for (String word : line.split(",")) { out.collect(Tuple2.of(word, 1)); } }, Types.TUPLE(Types.STRING, Types.INT)); KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordDS.keyBy(t2 -> t2.f0, Types.STRING); // 基于分组之后的数据流同样可以调用process方法 keyedDS .process(new KeyedProcessFunction<String, Tuple2<String, Integer>, String>() { // 定义一个ValueState单值状态,包含两个方法:update更新状态、value获取状态 // Flink会给每一个keyBy的key单独维护一个状态 /** * ListState :状态为多值 * MapState : 状态为KV * ReducingState :状态需要聚合,最终还是单值状态 * AggregatingState:状态需要聚合,最终还是单值状态 */ ValueState<Integer> valueState; // 当KeyedProcessFunction构建时只会执行一次 @Override public void open(Configuration parameters) throws Exception { // 使用Flink Context来初始化状态 RuntimeContext context = getRuntimeContext(); ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>("count", Types.INT); valueState = context.getState(descriptor); } // 每一条数据会执行一次 @Override public void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<String, Tuple2<String, Integer>, String>.Context ctx, Collector<String> out) throws Exception { Integer cnt = valueState.value(); int count = 1; // 如果是第一次处理某个单词,则返回null if (cnt != null){ count = cnt + 1; } valueState.update(count); out.collect(value.f0+","+count); } }).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
Checkpoint
checkpoint可以定时将flink计算过程中的状态持久化到hdfs中,保存状态不丢失
CheckPoint原理




在代码中开启
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo02CheckPoint { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 开启CK,每 1000ms 开始一次 checkpoint env.enableCheckpointing(5000); // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig().setCheckpointTimeout(60000); // 允许两个连续的 checkpoint 错误 env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2); // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留 env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 开启实验性的 unaligned checkpoints env.getCheckpointConfig().enableUnalignedCheckpoints(); // 设置CK保存的路径,一般是HDFS的路径 env.getCheckpointConfig().setCheckpointStorage("hdfs://master:9000/flink/checkpoint"); // Flink算子在计算时,实际上已经自带了状态,但是并没有主动进行CheckPoint env .socketTextStream("master", 8888) .map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0).sum(1) .print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
修改配置文件
记得重启yarn-session
修改flink-conf.yaml配置文件
# 修改以下配置
execution.checkpointing.interval: 5000
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION #是否保留
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 0
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 10min
execution.checkpointing.tolerable-failed-checkpoints: 0
execution.checkpointing.unaligned: false
state.backend: hashmap
#checkpoint保存的地址
state.checkpoints.dir: hdfs://master:9000/file/checkpoint
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
任务提交流程
# 1、第一次执行直接提交任务
flink run -t yarn-per-job -c com.shujia.flink.state.Demo1ValueState flink-1.0-SNAPSHOT.jar
# 2、获取hdfs中保存的checkpoint路径
# appid需要在flink 的页面中获取
hdfs dfs -ls /flink/checkpoint/[appid]
# 3、任务失败重启
# 基于HDFS中保存的状态重启任务
flink run -t yarn-per-job -c com.shujia.flink.state.Demo1ValueState -s hdfs://master:9000/flink/checkpoint/e16e4a32785b6394e745a34eb122f4a1/chk-5 flink-1.0-SNAPSHOT.jar
# 或者在WEB界面通过savepoint path指定任务恢复路径
#或者打包jar包直接在web界面提交并指定类名运行 ->Demo03ValueState
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
欺诈检测
import lombok.AllArgsConstructor; import lombok.Data; import org.apache.flink.api.common.functions.RuntimeContext; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; public class Demo04FraudCheck { public static void main(String[] args) throws Exception { // 对某个人的交易流水进行欺诈检测:如果有一笔交易小于一元,然后紧接着的一笔交易大于500,则判断有欺诈风险 /* * 1,1000 * 1,500 * 1,200 * 1,0.1 * 1,1000 * 1,0.1 * 1,300 */ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> transDS = env.socketTextStream("master", 8888); SingleOutputStreamOperator<MyTrans> MyTransDS = transDS.map(s -> { String[] split = s.split(","); return new MyTrans(split[0], Double.parseDouble(split[1])); }); MyTransDS.keyBy(MyTrans::getId)//每个人的户号分组 .process(new KeyedProcessFunction<String, MyTrans, String>() { // 定义一个状态 ValueState<Boolean>zyState; @Override public void open(Configuration parameters) throws Exception { //初始化状态 RuntimeContext context = getRuntimeContext(); zyState=context.getState(new ValueStateDescriptor<Boolean>("zy", Types.BOOLEAN)); } @Override public void processElement(MyTrans myTrans, KeyedProcessFunction<String, MyTrans, String>.Context context, Collector<String> collector) throws Exception { // 获取上一条纪录的状态,如果为true,则表示上一条记录是小于1的,则需要对当前记录进行是否大于500的判断 // false,则只需要判断当前记录中的金额是否小于1 Boolean zy = zyState.value(); if(zy==null){ zy = false; } //获取每笔交易中的金额 Double trans = myTrans.getTrans(); if (trans<1){ zyState.update(true); } if (zy){ if (trans>500){ System.out.println("存在交易风险"); } zyState.update(false); } } }); // flink不需要action算子触发任务,由事件触发 env.execute(); } } @Data @AllArgsConstructor // 构造方法 class MyTrans{ String id; Double trans; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
Exactly Once
完全一次
Kafka Exactly Once


kafka事务:
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class Demo03KafkaTransaction { public static void main(String[] args) throws InterruptedException { // 通过事务的方式写Kafka Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092"); properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty("transactional.id", "trans01"); // 创建Kafka 生产者 KafkaProducer<String, String> producer = new KafkaProducer<>(properties); // 开启一个事务 producer.initTransactions(); producer.beginTransaction(); // 向Kafka写数据 如果topic不存在则会自动创建一个副本和分区数都是1的topic producer.send(new ProducerRecord<String,String>("trans_topic","1500100001,施笑槐,22,女,文科六班")); producer.send(new ProducerRecord<String,String>("trans_topic","1500100002,施笑槐,22,女,文科六班")); producer.send(new ProducerRecord<String,String>("trans_topic","1500100003,施笑槐,22,女,文科六班")); Thread.sleep(10000); producer.send(new ProducerRecord<String,String>("trans_topic","1500100004,施笑槐,22,女,文科六班")); producer.send(new ProducerRecord<String,String>("trans_topic","1500100005,施笑槐,22,女,文科六班")); producer.flush(); // 提交事务之后才算写入完成 producer.commitTransaction(); } } // 消费时设置:kafaka-console-consumer.sh --isolaiton-level read_committed --bootstrap-server master:9092 --from-beginning --topic trans_topic
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Flink Exactly Once



import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Demo05ConsumeKafkaExactlyOnce { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置CK的时间间隔 env.enableCheckpointing(15000); // 如果需要提交到集群运行,记得在$FLINK_HOME/lib目录下添加flink-sql-connector-kafka-1.15.4.jar依赖 KafkaSource<String> kafkaSource = KafkaSource .<String>builder() .setBootstrapServers("master:9092,node1:9092,node2:9092") .setGroupId("grp001") // 第一次可以随便指定,如果需要恢复则必须和上一次同步 .setTopics("words001") // 读取的时候如果不存在会报错 // 如果是故障后从CK恢复,FLink会自动将其设置为committedOffsets,即从上一次失败的位置继续消费 .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); // 从KafkaSource接收数据变成DS 无界流 // Topic有几个分区,则KafkaSource有几个并行度去读取Kafka的数据 DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource"); // 统计班级人数 kafkaDS .map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .sum(1) .print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.connector.base.DeliveryGuarantee; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Properties; public class Demo06SinkKafkaExactlyOnce { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置CK的时间间隔 env.enableCheckpointing(15000); KafkaSource<String> kafkaSource = KafkaSource .<String>builder() .setBootstrapServers("master:9092,node1:9092,node2:9092") .setGroupId("grp001") // 第一次可以随便指定,如果需要恢复则必须和上一次同步 .setTopics("words001") // 读取的时候如果不存在会报错 // 如果是故障后从CK恢复,FLink会自动将其设置为committedOffsets,即从上一次失败的位置继续消费 .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); // 从KafkaSource接收数据变成DS 无界流 // Topic有几个分区,则KafkaSource有几个并行度去读取Kafka的数据 DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource"); Properties prop = new Properties(); /* * org.apache.flink.kafka.shaded.org.apache.kafka.common.KafkaException: * Unexpected error in InitProducerIdResponse; * The transaction timeout is larger than the maximum value allowed by the broker * (as configured by transaction.max.timeout.ms). * * transaction.max.timeout.ms : Kafka事务最大的超时时间,默认15分钟,即Broker允许的事务最大时间为15分钟 * Flink的KafkaSink默认事务的超时时间为1小时 * * transaction.timeout.ms :设置Kafka Sink的事务时间,只要小于15分钟即可 */ prop.setProperty("transaction.timeout.ms", 15 * 1000 + ""); KafkaSink<String> sink = KafkaSink.<String>builder() .setBootstrapServers("master:9092,node1:9092,node2:9092") .setKafkaProducerConfig(prop) .setRecordSerializer( KafkaRecordSerializationSchema .builder() .setTopic("word_cnt01") // 不存在会自动创建 .setValueSerializationSchema(new SimpleStringSchema()) .build() ) /* 设置写入时的语义: 1、AT_LEAST_ONCE:保证数据至少被写入了一次,性能会更好,但是又可能会写入重复的数据 2、EXACTLY_ONCE:保证数据只会写入一次,不多不少,性能会有损耗 */ .setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE) .build(); // 统计班级人数 kafkaDS .map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t2 -> t2.f0) .sum(1) // 将结果的二元组转换成String才能写入Kafka .map(t2 -> t2.f0 + "," + t2.f1) .sinkTo(sink); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
Flink SQL
动态表和连续查询
动态表 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个 连续查询 。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。需要注意的是,连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。

- 将流转换为动态表。
- 在动态表上计算一个连续查询,生成一个新的动态表。
- 生成的动态表被转换回流。
注意: 动态表首先是一个逻辑概念。在查询执行期间不一定(完全)物化动态表。
在流上定义表
为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。
注意: 在流上定义的表在内部没有物化。
eg:

连续查询
在动态表上计算一个连续查询,并生成一个新的动态表。与批处理查询不同,连续查询从不终止,并根据其输入表上的更新更新其结果表。在任何时候,连续查询的结果在语义上与以批处理模式在输入表快照上执行的相同查询的结果相同。


更新和追加查询
虽然这两个示例查询看起来非常相似(都计算分组计数聚合),但它们在一个重要方面不同:
- 第一个查询更新先前输出的结果,即定义结果表的 changelog 流包含 INSERT 和 UPDATE 操作。
- 第二个查询只附加到结果表,即结果表的 changelog 流只包含 INSERT 操作。
一个查询是产生一个只追加的表还是一个更新的表有一些含义:
产生更新更改的查询通常必须维护更多的状态。
将 append-only 的表转换为流与将已更新的表转换为流是不同的。
查询限制
许多(但不是全部)语义上有效的查询可以作为流上的连续查询进行评估。有些查询代价太高而无法计算,这可能是由于它们需要维护的状态大小,也可能是由于计算更新代价太高。
状态大小: 连续查询在无界流上计算,通常应该运行数周或数月。因此,连续查询处理的数据总量可能非常大。必须更新先前输出的结果的查询需要维护所有输出的行,以便能够更新它们。例如,第一个查询示例需要存储每个用户的 URL 计数,以便能够增加该计数并在输入表接收新行时发送新结果。如果只跟踪注册用户,则要维护的计数数量可能不会太高。但是,如果未注册的用户分配了一个惟一的用户名,那么要维护的计数数量将随着时间增长,并可能最终导致查询失败。
SELECT user, COUNT(url)FROM clicksGROUP BY user;
计算更新: 有些查询需要重新计算和更新大量已输出的结果行,即使只添加或更新一条输入记录。显然,这样的查询不适合作为连续查询执行。下面的查询就是一个例子,它根据最后一次单击的时间为每个用户计算一个 RANK。一旦 click 表接收到一个新行,用户的 lastAction 就会更新,并必须计算一个新的排名。然而,由于两行不能具有相同的排名,所以所有较低排名的行也需要更新。
SELECT user, RANK() OVER (ORDER BY lastAction)FROM ( SELECT user, MAX(cTime) AS lastAction FROM clicks GROUP BY user);
表到流的转换
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
- Append-only 流: 仅通过 INSERT 操作修改的动态表可以通过输出插入的行转换为流。
- Retract 流: retract 流包含两种类型的 message: add messages 和 retract messages 。通过将INSERT 操作编码为 add message、将 DELETE 操作编码为 retract message、将 UPDATE 操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,将动态表转换为 retract 流。下图显示了将动态表转换为 retract 流的过程。
- Upsert 流: upsert 流包含两种类型的 message: upsert messages 和delete messages。转换为 upsert 流的动态表需要(可能是组合的)唯一键。通过将 INSERT 和 UPDATE 操作编码为 upsert message,将 DELETE 操作编码为 delete message ,将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。
使用Flink SQL命令行
#1、启动一个Flink集群,可以时独立集群,也可以是yarn-session集群
yarn-session.sh -d
#2、启动sql-client
sql-client.sh
- 1
- 2
- 3
- 4
- 5
一个建表语句:

SQL客户端
基本使用
-
启动yarn-session
yarn-session.sh -d- 1
-
启动Flink SQL客户端
sql-client.sh- 1
-
测试
重启SQL客户端之后,需要重新建表
-- 建表语句 -- 构建Kafka Source -- 无界流 drop table if exists students_kafka_source; CREATE TABLE if not exists students_kafka_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'students1000', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 执行查询,基于KafkaSource是无界流,所以查询是连续变化的 select * from students_kafka_source; select clazz,count(*) as cnt from students_kafka_source group by clazz; -- 向Kafka生产数据 students1000中是1000条学生数据 kafka-console-producer.sh --broker-list master:9092 --topic students1000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
三种显示模式
-
表格模式
SQL客户端默认的结果显示模式
在内存中实体化结果,并将结果用规则的分页表格可视化展示出来
SET 'sql-client.execution.result-mode' = 'table';- 1
-
变更日志模式
不会实体化和可视化结果,而是由插入(
+)和撤销(-)组成的持续查询产生结果流SET 'sql-client.execution.result-mode' = 'changelog';- 1
-
Tableau模式
更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上
SET 'sql-client.execution.result-mode' = 'tableau';- 1
不同的执行模式
-
批处理
只能处理有界流
结果是固定的
底层是基于MR模型
SET 'execution.runtime-mode' = 'batch';- 1
-
流处理
默认的方式
既可以处理无界流,也可以处理有界流
结果是连续变化的
底层是基于持续流模型
SET 'execution.runtime-mode' = 'streaming';- 1
常用的connector
Kafka
-
准备工作
# 下载依赖 https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.15.4/flink-sql-connector-kafka-1.15.4.jar # 上传至${FLINK_HOME}/lib # 重启yarn-session.sh # 先找到yarn-session的application id yarn application -list # kill掉yarn-session在Yarn上的进程 yarn application -kill application_1722331927004_0007 # 再启动yarn-session yarn-session.sh -d # 再启动sql-client sql-client.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
Source
-- 构建Kafka Source -- 无界流 drop table if exists students_kafka_source; CREATE TABLE if not exists students_kafka_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, -- Kafka Source提供的数据之外的数据(元数据) `event_time` TIMESTAMP(3) METADATA FROM 'timestamp', `pt` BIGINT METADATA FROM 'partition', `offset` BIGINT METADATA FROM 'offset', `topic` STRING METADATA FROM 'topic' ) WITH ( 'connector' = 'kafka', 'topic' = 'students1000', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 执行查询 select id,name,event_time,pt,`offset`,`topic` from students_kafka_source limit 10;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
Sink
-
结果不带更新的Sink
drop table if exists students_lksb_sink; CREATE TABLE if not exists students_lksb_sink ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'students_lksb_sink', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 执行不带更新的查询 insert into students_lksb_sink select id,name,age,gender,clazz from students_kafka_source where clazz='理科四班';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
结果带更新的Sink
Kafka只支持追加的写入,不支持更新数据
故有更新的查询结果无法直接编码,写入Kafka
虽然Kafka支支持append,但是可以将更新流编码成“ +、-”不断追加到Kafka中
如果有更新,那么往Kafka写两条记录即可表示更新,即:先“-”再“+”
但是csv这种格式无法表达“-”或“+”操作,故无法在有更新的结果写Kafka时使用
需要使用:canal-json或者是debezium-json
canal-json:{“data”:[{“clazz”:“文科六班”,“cnt”:104}],“type”:“DELETE”}
debezium-json:{“before”:null,“after”:{“clazz”:“理科四班”,“cnt”:94},“op”:“c”}
-- 基于Kafka Source 统计班级人数 最终结果写入Kafka drop table if exists clazz_cnt_sink; CREATE TABLE if not exists clazz_cnt_sink ( `clazz` String, `cnt` BIGINT ) WITH ( 'connector' = 'kafka', 'topic' = 'clazz_cnt_sink_02', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'canal-json' -- 或者是指定为debezium-json ); -- 执行查询并且将查询结果插入到Sink表中 insert into clazz_cnt_sink select clazz,count(*) as cnt from students_kafka_source group by clazz;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
JDBC
用于连接数据库,例如:MySQL、Oracle、PG、Derby
-
准备工作
# 下载依赖 https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc/1.15.4/flink-connector-jdbc-1.15.4.jar # 上传依赖至FLINK的lib目录下 # 重启yarn-session以及sql客户端- 1
- 2
- 3
- 4
- 5
- 6
-
Source
有界流,只会查询一次,查询完后直接结束
drop table if exists students_mysql_source; CREATE TABLE if not exists students_mysql_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://master:3306/bigdata30?useSSL=false', 'table-name' = 'students', 'username' = 'root', 'password' = '123456' ); -- 执行查询 select * from students_mysql_source; -- 将模式换成tableau 看结果变化的全过程 SET 'sql-client.execution.result-mode' = 'tableau'; -- 默认会以 流处理的方式 执行,所以可以看到结果连续变化的过程 select gender,count(*) as cnt from students_mysql_source group by gender; -- 将运行模式切换成批处理 SET 'execution.runtime-mode' = 'batch'; -- 再试执行,只会看到最终的一个结果,没有变化的过程 select gender,count(*) as cnt from students_mysql_source group by gender;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
Sink
从Kafka接收无界流的学生数据,统计班级人数,将最终的结果写入MySQL
-- 创建MySQL的结果表 -- 无主键的MySQL建表语句 -- 最终发现写入的结果是有连续变换的过程,并不是直接写入最终的结果,很不好看 drop table if exists `clazz_cnt`; CREATE TABLE if not exists `clazz_cnt`( `clazz` varchar(255) DEFAULT NULL ,`cnt` bigint DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- 将班级设置为主键 -- 最终写入的结果是可以通过主键进行更新,所以可以展示最终的结果,并且可以实时更新 drop table if exists `clazz_cnt`; CREATE TABLE if not exists `clazz_cnt`( `clazz` varchar(255) NOT NULL, `cnt` bigint(20) DEFAULT NULL, PRIMARY KEY (`clazz`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- 创建MySQL的Sink表 drop table if exists clazz_cnt_mysql_sink; CREATE TABLE if not exists clazz_cnt_mysql_sink ( `clazz` STRING, `cnt` BIGINT, -- 如果查询的结果有更新,则需要设置主键 PRIMARY KEY (clazz) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://master:3306/bigdata30?useSSL=false', 'table-name' = 'clazz_cnt', 'username' = 'root', 'password' = '123456' ); -- 记得将执行模式切换成流处理,因为Kafka是无界流 SET 'execution.runtime-mode' = 'streaming'; -- 执行查询:实时统计班级人数,将结果写入MySQL insert into clazz_cnt_mysql_sink select clazz,count(*) as cnt from students_kafka_source where clazz is not null group by clazz;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
HDFS
-
Source
-
有界流
默认的方式
drop table if exists students_hdfs_source; CREATE TABLE if not exists students_hdfs_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, `file.path` STRING NOT NULL METADATA ) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://master:9000/bigdata30/students.csv', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
无界流
同DataStream的FileSource一致
可以通过设置source.monitor-interval参数,来指定一个监控的间隔时间,例如:5s
FLink就会定时监控目录的一个变换,有新的文件就可以实时进行读取
最终得到一个无界流
-- 创建HDFS目录 hdfs dfs -mkdir /bigdata30/flink -- 创建Source表 drop table if exists students_hdfs_unbounded_source; CREATE TABLE if not exists students_hdfs_unbounded_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, `file.path` STRING NOT NULL METADATA ) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://master:9000/bigdata30/flink', 'source.monitor-interval' = '5s', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 执行查询 select * from students_hdfs_unbounded_source; -- 向目录上传文件 hdfs dfs -cp /bigdata30/students.csv /bigdata30/flink/students.csv1 hdfs dfs -cp /bigdata30/students.csv /bigdata30/flink/students.csv2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
-
Sink
-
查询结果没有更新
drop table if exists students_hdfs_sink; CREATE TABLE if not exists students_hdfs_sink ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, `file_path` STRING ) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://master:9000/bigdata30/sink/', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); insert into students_hdfs_sink select * from students_hdfs_source;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
查询结果有更新
同Kafka类似,HDFS不支持更新数据,故需要将变换的结果编码成canal-json或者是debezium-json的格式才能进行insert
drop table if exists clazz_cnt_hdfs_sink; CREATE TABLE if not exists clazz_cnt_hdfs_sink ( `clazz` STRING, `cnt` BIGINT ) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://master:9000/bigdata30/clazz_cnt/', 'format' = 'canal-json' ); insert into clazz_cnt_hdfs_sink select clazz,count(*) as cnt from students_hdfs_source group by clazz;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
HBase
-
准备工作
# 下载依赖 https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hbase-2.2/1.15.4/flink-sql-connector-hbase-2.2-1.15.4.jar # 上传依赖并重启yarn-session及sql客户端 #master:16010- 1
- 2
- 3
- 4
- 5
-
Source
同MySQL类似,得到是一个有界流
drop table if exists students_hbase_source; CREATE TABLE if not exists students_hbase_source ( rowkey STRING, info ROW<name STRING, age STRING,gender STRING,clazz STRING>, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'hbase-2.2', 'table-name' = 'students', 'zookeeper.quorum' = 'master:2181' ); select rowkey,info.name,info.age,info.gender,info.clazz from students_hbase_source;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
Sink
同MySQL类似
-- 在HBase中建表 create 'stu01','info' -- 构建HBase Sink表 drop table if exists stu_hbase_sink; CREATE TABLE if not exists stu_hbase_sink ( id STRING, info ROW<name STRING,clazz STRING>, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'hbase-2.2', 'table-name' = 'stu01', 'zookeeper.quorum' = 'master:2181' ); -- 丢弃null的数据 set 'table.exec.sink.not-null-enforcer'='DROP'; -- 仅追加的结果写入,由于HBase有rk存在,相同的RK会进行覆盖 insert into stu_hbase_sink select cast(id as STRING) as id,ROW(name,clazz) as info from students_kafka_source; -- 此时在kafka中生产数据可以实时更新到hbase中 -- 在HBase中建表 create 'clazz_cnt_01','info' -- 构建HBase Sink表 drop table if exists clazz_cnt_hbase_sink; CREATE TABLE if not exists clazz_cnt_hbase_sink ( clazz STRING, info ROW<cnt BIGINT>, PRIMARY KEY (clazz) NOT ENFORCED ) WITH ( 'connector' = 'hbase-2.2', 'table-name' = 'clazz_cnt_01', 'zookeeper.quorum' = 'master:2181' ); -- 带更新的查询结果可以实时在HBase中通过RK进行更新 insert into clazz_cnt_hbase_sink select clazz,ROW(count(*)) as info from students_kafka_source group by clazz ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
DataGen
用于按照指定的规则生成数据,一般用于性能测试
drop table if exists datagen; CREATE TABLE if not exists datagen ( id BIGINT ,random_id BIGINT ,name STRING ) WITH ( 'connector' = 'datagen', -- optional options -- 'rows-per-second'='200000', -- 设置每秒钟生成的数据量 'fields.id.kind' = 'random', 'fields.id.min'='10000000', 'fields.id.max'='99999999', 'fields.random_id.kind' = 'random', 'fields.random_id.min'='10000000', 'fields.random_id.max'='99999999', 'fields.name.length'='5' );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Blackhole
用于性能测试,可以作为Sink端
drop table if exists blackhole_table; CREATE TABLE if not exists blackhole_table WITH ('connector' = 'blackhole') LIKE datagen (EXCLUDING ALL); insert into blackhole_table select * from datagen group by name; drop table if exists blackhole_table; CREATE TABLE if not exists blackhole_table( name String, cnt BIGINT ) WITH ('connector' = 'blackhole') ; insert into blackhole_table select name,count(*) as cnt from datagen group by name;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
将结果数据在TaskManager中输出
drop table if exists print_table;
CREATE TABLE if not exists print_table (
name STRING,
cnt BIGINT
) WITH (
'connector' = 'print'
);
insert into print_table
select name,count(*) as cnt from datagen group by name;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
常用的格式
CSV
逗号分隔符文件
在作为Sink时的format,仅支持写入不带更新的结果
解析每条数据是通过顺序匹配
常用参数:
csv.ignore-parse-errors 默认false,忽略解析错误,不会导致程序直接停止
csv.field-delimiter 默认 逗号,指定数据的列分隔符
JSON
json
普通的json格式,解析数据是通过列名进行匹配
同csv类似,只支持写入不带更新的结果
drop table if exists cars_json_source; CREATE TABLE if not exists cars_json_source ( car String ,county_code INT ,city_code INT ,card BIGINT ,camera_id String ,orientation String ,road_id BIGINT ,`time` BIGINT ,speed Double ) WITH ( 'connector' = 'kafka', 'topic' = 'cars_json', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json' );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
canal-json
一种特殊的JSON格式
支持写入更新的结果
{“data”:[{“clazz”:“文科六班”,“cnt”:104}],“type”:“DELETE”}
debezium-json
同canal-json,只是数据格式有些许差异
{“before”:null,“after”:{“clazz”:“理科四班”,“cnt”:94},“op”:“c”}
ORC
一般不用
PARQUET
一般不用
时间属性
处理时间
基于系统的时间
drop table if exists students_kafka_source; CREATE TABLE if not exists students_kafka_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, -- 通过系统时间给表增加一列,即:处理时间 proc_time as PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'students1000', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); select clazz ,count(*) as cnt ,tumble_start(proc_time,INTERVAL '5' SECONDS) as window_start ,tumble_end(proc_time,INTERVAL '5' SECONDS) as window_end from students_kafka_source group by clazz,tumble(proc_time,INTERVAL '5' SECONDS) ; -- 向Topic中生产数据 kafka-console-producer.sh --broker-list master:9092 --topic students1000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
事件时间
基于数据自带的时间
java,2024-08-03 10:41:50
java,2024-08-03 10:41:51
java,2024-08-03 10:41:52
drop table if exists words_kafka_source; CREATE TABLE if not exists words_kafka_source ( `word` STRING, -- 从数据中过来的一列,作为事件时间 event_time TIMESTAMP(3), -- 指定水位线前移策略,并同时声明数据中的哪一列是事件时间 WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND ) WITH ( 'connector' = 'kafka', 'topic' = 'words_event_time', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 创建topic kafka-topics.sh --zookeeper master:2181/kafka --create --replication-factor 1 --partitions 1 --topic words_event_time -- 执行查询,使用滚动的事件时间窗口进行word count,每5s统计一次 select word ,count(*) as cnt ,tumble_start(event_time,INTERVAL '5' SECONDS) as window_start ,tumble_end(event_time,INTERVAL '5' SECONDS) as window_end from words_kafka_source group by word,tumble(event_time,INTERVAL '5' SECONDS) ; -- 向Topic中生产数据 kafka-console-producer.sh --broker-list master:9092 --topic words_event_time
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
SQL语法
Hints
在SQL查询时动态修改表的参数配置
-- words_kafka_source 默认从最后开始消费
select * from words_kafka_source; // 只能查询到最新的数据,不会从头开始消费
-- 假设现在需要从头开始消费
-- 第一种方案,将words_kafka_source删除重建
-- 第二种方案,通过alter table 对表进行修改
-- 第三种方案,通过hints动态调整表的配置
select * from words_kafka_source /*+OPTIONS('scan.startup.mode' = 'earliest-offset') */ ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
With
用于将多次执行的同一查询通过with先定义,后面可以进行多次使用,避免重复的SQL
应用场景:1、多次使用的SQL查询可以缓存提高性能 2、将多级嵌套解开来,降低主SQL的复杂度
drop table if exists students_mysql_source; CREATE TABLE if not exists students_mysql_source ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://master:3306/bigdata30?useSSL=false', 'table-name' = 'students', 'username' = 'root', 'password' = '123456' ); select id,name from students_mysql_source where clazz = '理科一班' union all select id,name from students_mysql_source where clazz = '理科一班' ; -- 通过with可以将多次使用的SQL进行定义 with stu_lkyb as ( select id,name from students_mysql_source where clazz = '理科一班' ) select * from stu_lkyb union all select * from stu_lkyb union all select * from stu_lkyb ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
Where
可以进行过滤
select id,name,clazz,age from students_mysql_source where clazz = '理科一班' and age > 20;
-- 找到重复数据并进行过滤
select id,name,age,gender,clazz
from (
select id,name,age,gender,clazz,count(*) as cnt from students_mysql_source group by id,name,age,gender,clazz
) t1 where t1.cnt = 1;
-- 聚合后的过滤可以使用Having
select id,name,age,gender,clazz,count(*) as cnt from students_mysql_source group by id,name,age,gender,clazz
having count(*) = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Distinct
用于去重
需要对每条不同的数据维护一个状态,状态会无限制的增大,最终任务可能会失败
无界流是正常可以去重的
有界流必须在分组之后带上聚合操作才能去重,如果直接distinct或者是groupby不聚合,最终任务里不会产生shuffle,即不会分组,也就无法去重
-- 去重
select id,name,age,gender,clazz from students_mysql_source group by id,name,age,gender,clazz;
-- 等价于distinct
select distinct id,name,age,gender,clazz from students_mysql_source;
select distinct id from students_mysql_source;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Windowing TVFs
目前提供了三类TVFs窗口操作:TUMBLE、HOP、CUMULATE
会话SESSION窗口只能通过GROUP WINDOW FUNCTION实现
计数窗口在FLINK SQL中暂未支持
Tumble
需要设置一个滚动时间
每隔一段时间会触发一次窗口的统计
-- 创建Bid订单表 drop table if exists bid_kafka_source; CREATE TABLE if not exists bid_kafka_source ( `item` STRING, `price` DOUBLE, `bidtime` TIMESTAMP(3), `proc_time` as PROCTIME(), -- 指定水位线前移策略,并同时声明数据中的哪一列是事件时间 WATERMARK FOR bidtime AS bidtime ) WITH ( 'connector' = 'kafka', 'topic' = 'bid', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 准备数据 C,4.00,2020-04-15 08:05:00 A,2.00,2020-04-15 08:07:00 D,5.00,2020-04-15 08:09:00 B,3.00,2020-04-15 08:11:00 E,1.00,2020-04-15 08:13:00 F,6.00,2020-04-15 08:17:00 -- 创建Kafka Topic kafka-topics.sh --zookeeper master:2181/kafka --create --replication-factor 1 --partitions 1 --topic bid -- 生产数据 kafka-console-producer.sh --broker-list master:9092 --topic bid -- 基于事件时间的滚动窗口 SELECT window_start,window_end,sum(price) as sum_price FROM TABLE( -- tumble函数 会给bid表增加三个窗口列:window_start、window_end、window_time -- 如果需要基于窗口的统计则按照窗口列分组即可 TUMBLE(TABLE bid_kafka_source, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES) ) group by window_start,window_end ; -- 基于处理时间的滚动窗口 SELECT window_start,window_end,sum(price) as sum_price FROM TABLE( -- tumble函数 会给bid表增加三个窗口列:window_start、window_end、window_time -- 如果需要基于窗口的统计则按照窗口列分组即可 TUMBLE(TABLE bid_kafka_source, DESCRIPTOR(proc_time), INTERVAL '10' SECONDS) ) group by window_start,window_end ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
HOP
滑动窗口
需要指定两个时间:滑动的时间、窗口的大小
-- 基于事件时间的滑动窗口 SELECT window_start,window_end,sum(price) as sum_price FROM TABLE( -- HOP函数 会给bid表增加三个窗口列:window_start、window_end、window_time -- 如果需要基于窗口的统计则按照窗口列分组即可 HOP(TABLE bid_kafka_source, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES) ) group by window_start,window_end ; -- 基于处理时间的滑动窗口 SELECT window_start,window_end,sum(price) as sum_price FROM TABLE( -- HOP函数 会给bid表增加三个窗口列:window_start、window_end、window_time -- 如果需要基于窗口的统计则按照窗口列分组即可 HOP(TABLE bid_kafka_source, DESCRIPTOR(proc_time), INTERVAL '5' SECONDS, INTERVAL '10' SECONDS) ) group by window_start,window_end ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
CUMULATE
累积窗口:首先会按照步长初始化一个窗口大小,然后按照步长的间隔时间触发窗口的统计,接下来窗口大小会不断增大,直到达到设置的最大size,然后重复这个过程
需要指定两个时间间隔:步长、最大的size
例如:步长为2分钟,size为10分钟
每隔2分钟会触发一次统计,第一次统计的最近两分钟的数据,第二次统计是最近4分钟的…第5次统计是最近10分钟的数据,第6次统计是最近2分钟的数据…
-- 基于事件时间的累计窗口 SELECT window_start,window_end,sum(price) as sum_price FROM TABLE( -- CUMULATE函数 会给bid表增加三个窗口列:window_start、window_end、window_time -- 如果需要基于窗口的统计则按照窗口列分组即可 CUMULATE(TABLE bid_kafka_source, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES) ) group by window_start,window_end ; -- 基于处理时间的累计窗口 SELECT window_start,window_end,sum(price) as sum_price FROM TABLE( -- CUMULATE函数 会给bid表增加三个窗口列:window_start、window_end、window_time -- 如果需要基于窗口的统计则按照窗口列分组即可 CUMULATE(TABLE bid_kafka_source, DESCRIPTOR(proc_time), INTERVAL '2' SECONDS, INTERVAL '10' SECONDS) ) group by window_start,window_end ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
SESSION
会话窗口,目前版本不支持TVFs写法
需要使用老版本的写法:GROUP WINDOW FUNCTION
间隔一段时间没有数据就会触发窗口的统计
-- 基于事件时间的会话窗口
select session_start(bidtime, INTERVAL '2' MINUTES) as session_start
,session_end(bidtime, INTERVAL '2' MINUTES) as session_end
,sum(price) as sum_price
from bid_kafka_source
group by session(bidtime, INTERVAL '2' MINUTES)
;
-- 基于处理时间的会话窗口
select session_start(proc_time, INTERVAL '2' SECONDS) as session_start
,session_end(proc_time, INTERVAL '2' SECONDS) as session_end
,sum(price) as sum_price
from bid_kafka_source
group by session(proc_time, INTERVAL '2' SECONDS)
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Over聚合
聚合类
sum、max、min、count、avg
sum 比较特殊:如果指定了order By,则表示累加求和,不指定则表示整个窗口求和
max、min、count、avg 不需要指定order By
-- 准备数据 item,supply_id,price,bidtime A,001,4.00,2020-04-15 08:05:00 A,002,2.00,2020-04-15 08:06:00 A,001,5.00,2020-04-15 08:07:00 B,002,3.00,2020-04-15 08:08:00 A,001,1.00,2020-04-15 08:09:00 A,002,6.00,2020-04-15 08:10:00 B,001,6.00,2020-04-15 08:11:00 A,001,6.00,2020-04-15 08:12:00 B,002,6.00,2020-04-15 08:13:00 B,002,6.00,2020-04-15 08:14:00 A,001,66.00,2020-04-15 08:15:00 B,001,6.00,2020-04-15 08:16:00 -- 创建order订单表 drop table if exists order_kafka_source; CREATE TABLE if not exists order_kafka_source ( `item` STRING, `supply_id` STRING, `price` DOUBLE, `bidtime` TIMESTAMP(3), -- 指定水位线前移策略,并同时声明数据中的哪一列是事件时间 WATERMARK FOR bidtime AS bidtime ) WITH ( 'connector' = 'kafka', 'topic' = 'order', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 创建Kafka Topic kafka-topics.sh --zookeeper master:2181/kafka --create --replication-factor 1 --partitions 1 --topic order -- 生产数据 kafka-console-producer.sh --broker-list master:9092 --topic order -- 聚合类函数在实时的Over窗口上只会产生追加的数据,没有更新 -- 最终需要维护的状态大小同partition by指定的字段有关 -- 1、统计每种商品的累计成交金额 select item -- 必须指定order by ,而且必须使用时间列升序, -- 如果本条数据的时间小于上一条数据的时间,则本条数据会被忽略,不参与计算 -- 相当于sum只能做累加求和,来一条数据累加一次,无法做全局聚合 ,sum(price) over (partition by item order by bidtime) as sum_price from order_kafka_source ; -- 2、统计每种商品的最大成交金额 select item -- 必须指定order by ,而且必须使用时间列升序, -- 如果本条数据的时间小于上一条数据的时间,则本条数据会被忽略,不参与统计 -- 来一条数据就会输出一条数据,max会将截止到当前时间戳最大的数据中取最大的一个值 ,max(price) over (partition by item order by bidtime) as max_price from order_kafka_source ; -- 3、统计每种商品的最小、平均成交金额/交易次数 同上 -- 4、统计最近10分钟内每种商品的累计成交金额
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
排名类
组内排名
row_number、rank、dense_rank
-- 1、统计每种商品成交时间的排名 select item ,price -- 同上面的聚合类over一样,order by必须指定时间,而且必须时升序 ,row_number() over (partition by item order by bidtime) as rn from order_kafka_source ; -- 2、统计每种商品成交金额的排名, 无法统计所有数据的排名,代价太大,所以只能做TopN -- 统计每种商品成交金额的排名Top3 select t1.item ,t1.price ,t1.rn from ( select item ,price ,row_number() over (partition by item order by price desc) as rn from order_kafka_source ) t1 where t1.rn <= 3 ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Order By
全局排序,注意代价
select *
from order_kafka_source /*+OPTIONS('scan.startup.mode' = 'earliest-offset')*/
-- 如果直接基于非时间列排序是不被支持的
-- order by price desc
order by bidtime,price desc
;
-- 会保留排序最大的前10条数据,但是这10条数据并不是按序输出的
select *
from order_kafka_source /*+OPTIONS('scan.startup.mode' = 'earliest-offset')*/
order by price desc
-- 还可以通过limit来限制代价
limit 10
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Limit
用于限制返回的条数
在实时场景中一般结合Order By来降低排序的代价
Join
Regular Join
常规Join,同HiveSQL、SparkSQL一致
可以进行:inner join、left join、right join、full join
注意状态的大小,可以设置TTL
drop table if exists students_join; CREATE TABLE if not exists students_join ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, proc_time AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'students_join', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); drop table if exists score_join; CREATE TABLE if not exists score_join ( `id` BIGINT, `subject_id` BIGINT, `score` INT, proc_time AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'score_join', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 进行join -- 用法同离线join没有任何区别 -- 但是要注意:一个流中的数据会一直等待另一个流中的数据达到,意味着状态会一直变大,最终任务肯定会失败 -- 可以在join的时候指定状态的过期时间TTL,这样状态不会无限制的变大 -- 设置TTL set 'table.exec.state.ttl' = '10000ms'; select t1.id ,t1.name ,t2.subject_id ,t2.score -- join没有限制,可以实现内/外join from students_join t1 left join score_join t2 on t1.id = t2.id; -- 向Kafka生产数据 kafka-console-producer.sh --broker-list master:9092 --topic students_join kafka-console-producer.sh --broker-list master:9092 --topic score_join
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
Interval Join
时间间隔关联
在Regular Join的基础之上指定一个时间间隔
实际上也是通过时间间隔来让状态不会一直变大,类似TTL
select t1.id
,t1.name
,t2.subject_id
,t2.score
-- join没有限制,可以实现内/外join
from students_join t1
left join score_join t2
on t1.id = t2.id
and t1.proc_time BETWEEN t2.proc_time - INTERVAL '10' SECONDS AND t2.proc_time
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Temporal Join
时态表关联
适用于流表关联时态表
时态表:随着时间一直变化
001,2,DOL,2024-08-05 11:20:20 001,3,DOL,2024-08-05 11:25:20 001,5,DOL,2024-08-05 11:30:20 001,6,DOL,2024-08-05 11:45:20 001,4,DOL,2024-08-05 12:15:20 -- 构建订单表,流表 drop table if exists orders_join; CREATE TABLE if not exists orders_join ( order_id STRING, price DECIMAL(32,2), currency STRING, order_time TIMESTAMP(3), WATERMARK FOR order_time AS order_time ) WITH ( 'connector' = 'kafka', 'topic' = 'orders_join', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 构建货币汇率表,时态表 -- 会随着时间一直变化 drop table if exists currency_rates; CREATE TABLE if not exists currency_rates( currency STRING, conversion_rate DECIMAL(32, 2), update_time TIMESTAMP(3), WATERMARK FOR update_time AS update_time, PRIMARY KEY(currency) NOT ENFORCED ) WITH ( 'connector' = 'kafka', 'topic' = 'currency_rates', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'canal-json' ); -- 准备数据 {"data":[{"currency":"DOL","conversion_rate":7.14,"update_time":"2024-08-05 10:30:00"}],"type":"INSERT"} {"data":[{"currency":"DOL","conversion_rate":7.24,"update_time":"2024-08-05 11:25:00"}],"type":"INSERT"} {"data":[{"currency":"DOL","conversion_rate":7.04,"update_time":"2024-08-05 12:00:00"}],"type":"INSERT"} {"data":[{"currency":"DOL","conversion_rate":7.34,"update_time":"2024-08-05 12:14:00"}],"type":"INSERT"} {"data":[{"currency":"DOL","conversion_rate":7.14,"update_time":"2024-08-05 12:20:00"}],"type":"INSERT"} -- 向Kafka生产数据 kafka-console-producer.sh --broker-list master:9092 --topic orders_join kafka-console-producer.sh --broker-list master:9092 --topic currency_rates -- 时态表Join select t1.order_id ,t1.currency ,t1.price ,t1.order_time ,t2.conversion_rate ,t2.update_time ,t1.price * t2.conversion_rate as price_rmb from orders_join t1 -- 通过FOR SYSTEM_TIME 来表示进行时态JOIN left join currency_rates FOR SYSTEM_TIME AS OF t1.order_time t2 on t1.currency = t2.currency ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
LookUp Join
适用于流表关联维表
维表:存储维度数据,通常变化频率不是很高
-- MySQL直接作为Source ---> 有界流 -- MySQL的学生信息表作为维表 drop table if exists students_mysql_join; CREATE TABLE if not exists students_mysql_join ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://master:3306/bigdata30?useSSL=false', 'table-name' = 'students', 'username' = 'root', 'password' = '123456', -- 设置LookUp缓存的条数以及过期时间 'lookup.cache.max-rows' = '1000', 'lookup.cache.ttl' = '60s' ); -- 使用Regular Join中的score_join作为事实表 -- 如果MySQL有数据更新,程序不会识别到,因为MySQL的数据只会加载一次,有数据变更时需要重启任务 select t1.id ,t1.score ,t2.name ,t2.clazz from score_join t1 left join students_mysql_join t2 on t1.id = t2.id ; -- 使用Lookup Join select t1.id ,t1.score ,t2.name ,t2.clazz from score_join t1 -- 来一数据就会去MySQL中查询一次,立马能够识别到更新的数据 -- 对MySQL的性能影响较大 left join students_mysql_join FOR SYSTEM_TIME AS OF t1.proc_time t2 on t1.id = t2.id ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
模式匹配(CEP)
语法:
SELECT T.aid, T.bid, T.cid FROM MyTable MATCH_RECOGNIZE ( PARTITION BY userid ORDER BY proctime MEASURES -- 相当于select A.id AS aid, B.id AS bid, C.id AS cid -- 定义A B C三个规则,默认每个规则只需要匹配1次即可 -- 当所有的规则都满足,则输出数据 PATTERN (A B C) DEFINE -- 定义具体规则 A AS name = 'a', B AS name = 'b', C AS name = 'c' ) AS T
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
欺诈检测
- 实时监控某个账户的交易流水,如果出现一笔交易小于1,紧接着下一笔交易大于500,那么就输出一个警告
-- 创建一个交易流水表 drop table if exists trans; CREATE TABLE if not exists trans ( `id` STRING, `price` DOUBLE, proc_time AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'trans', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 准备数据 001,2 001,600 001,0.1 001,200 001,700 001,0.8 001,600 001,0.7 001,400 -- 向Kafka生产数据 kafka-console-producer.sh --broker-list master:9092 --topic trans -- 进行模式匹配 SELECT T.min_price,T.max_price,T.a_proc_time,T.b_proc_time FROM trans MATCH_RECOGNIZE ( PARTITION BY id -- 按什么分组统计 ORDER BY proc_time -- 按时间升序排列数据 MEASURES -- 相当于select A.price as min_price ,A.proc_time as a_proc_time ,B.price as max_price ,B.proc_time as b_proc_time -- 定义A B 两个规则,当所有的规则都满足,则输出数据 PATTERN (A B) DEFINE -- 定义具体规则 A AS price < 1, B AS price > 500 ) AS T ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 实时监控某个账户的交易流水,如果出现三笔交易小于1,紧接着下一笔交易大于500,那么就输出一个警告
-- 进行模式匹配 SELECT * FROM trans MATCH_RECOGNIZE ( PARTITION BY id -- 按什么分组统计 ORDER BY proc_time -- 按时间升序排列数据 MEASURES -- 相当于select A.price as last_price -- 默认取出来的是最后一条A的记录 ,avg(A.price) as avg_price ,A.proc_time as a_proc_time ,B.price as max_price ,B.proc_time as b_proc_time -- 定义A B 两个规则,当所有的规则都满足,则输出数据 -- A{3} 表示需要匹配3次A的规则,才能进行B规则的匹配 PATTERN (A{3} B) DEFINE -- 定义具体规则 A AS price < 1, B AS price > 500 ) AS T ; 001,0.1 001,0.2 001,0.4 001,600
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 实时监控某个账户的交易流水,如果出现一笔交易小于1,紧接着下一笔交易大于500,两笔交易时间差如果小于5s钟,那么就输出一个警告
SELECT T.min_price,T.max_price,T.a_proc_time,T.b_proc_time FROM trans MATCH_RECOGNIZE ( PARTITION BY id -- 按什么分组统计 ORDER BY proc_time -- 按时间升序排列数据 MEASURES -- 相当于select A.price as min_price ,A.proc_time as a_proc_time ,B.price as max_price ,B.proc_time as b_proc_time -- 定义A B 两个规则,当所有的规则都满足,则输出数据 PATTERN (A B) WITHIN INTERVAL '5' SECOND DEFINE -- 定义具体规则 A AS price < 1, B AS price > 500 ) AS T ; 001,0.1 001,600 001,0.1 -- 等待5s 001,600
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
股票检测
- 实时监控股票价格走势,找出连续下降的区间
drop table if exists symbol; CREATE TABLE if not exists symbol ( `symbol` STRING, `rowtime` TIMESTAMP(3), `price` DECIMAL(10,2), WATERMARK FOR rowtime AS rowtime ) WITH ( 'connector' = 'kafka', 'topic' = 'symbol', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 准备数据 ACME,2024-08-05 10:00:00,17 ACME,2024-08-05 10:20:00,18 ACME,2024-08-05 10:40:00,20 ACME,2024-08-05 11:00:00,21 ACME,2024-08-05 11:20:00,22 ACME,2024-08-05 11:40:00,20 ACME,2024-08-05 12:00:00,15 ACME,2024-08-05 12:20:00,14 ACME,2024-08-05 12:40:00,13 ACME,2024-08-05 13:00:00,16 ACME,2024-08-05 13:20:00,19 -- 创建Topic kafka-topics.sh --zookeeper master:2181/kafka --create --replication-factor 1 --partitions 1 --topic symbol -- 向Kafka生产数据 kafka-console-producer.sh --broker-list master:9092 --topic symbol -- 进行模式匹配 SELECT * FROM symbol MATCH_RECOGNIZE ( PARTITION BY symbol -- 按什么分组统计 ORDER BY rowtime -- 按时间升序排列数据 MEASURES -- 相当于select A.price as a_price ,A.rowtime as a_rowtime ,max(B.price) as max_price ,min(B.price) as min_price ,min(B.rowtime) as start_time ,max(B.rowtime) as end_time ,C.price as c_price ,C.rowtime as c_rowtime AFTER MATCH SKIP PAST LAST ROW -- 定义A B C三个规则,当所有的规则都满足,则输出数据 -- B+ 表示至少要符合一次 PATTERN (A B{2,} C) DEFINE -- 定义具体规则 -- 如果B是顶点数据,那么往前取一条B匹配到的数据是取不到的,则返回null -- 如果B是下降区间的数据,那么往前取一条B匹配到的数据是可以取到数据的 B as (LAST(B.price, 1) > B.price) or (LAST(B.price, 1) is null and B.price > A.price) ,C as LAST(B.price) < C.price ) AS T ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
整合Hive
获取解析Hive的元数据
Flink整合Hive主要有两个目的:
1、将Flink本身的元数据借助Hive保存
2、可以加载Hive中的数据,正常通过Spark处理Hive的数据
准备工作
# 1、下载Hive的connector依赖
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.15.4/flink-sql-connector-hive-3.1.2_2.12-1.15.4.jar
# 2、上传到FLINK的lib目录下
# 3、重启yarn-session以及sql客户端
- 1
- 2
- 3
- 4
- 5
- 6
创建Catalog
Catalog --> 库 --> 表 --> 数据
-- 使用catalog之前需要先启动hive的metastore服务
-- hive --service metastore
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/usr/local/soft/hive-3.1.2/conf/'
);
-- 切换catalog
USE CATALOG myhive;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
将FlinkSQL的表存入Hive
flink的SQL客户端默认会使用内存保存元数据Catalog,重启之后会丢失,需要重新创建
借助Hive的Catalog来保存Flink表的元数据,重启后还能保留
保存的元数据虽然能在hive中看到,但只能在Flink环境下使用
drop table if exists students_join; CREATE TABLE if not exists students_join ( `id` BIGINT, `name` STRING, `age` INT, `gender` STRING, `clazz` STRING, proc_time AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'students_join', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); -- 查询数据 select * from students_join /*+OPTIONS('scan.startup.mode' = 'earliest-offset')*/ ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
加载Hive的函数
LOAD MODULE hive WITH ('hive-version' = '3.1.2'); select split('hello,world',','); drop table if exists words; CREATE TABLE if not exists words ( line STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'words', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); select word from words, lateral table(explode(split(line,'#'))) as t(word);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
CheckPoint
准备任务
需要通过sql-client.sh -f 来执行
将下列SQL放到word_cnt.sql文件中
drop table if exists words; CREATE TABLE if not exists words ( word STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'words', 'properties.bootstrap.servers' = 'master:9092', 'properties.group.id' = 'grp1', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', -- 是否忽略脏数据 'csv.ignore-parse-errors' = 'true' ); drop table if exists word_cnt; CREATE TABLE if not exists word_cnt ( word STRING, cnt BIGINT ) WITH ( 'connector' = 'print' ); insert into word_cnt select word ,count(*) as cnt from words group by word ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
提交任务
第一次提交,不需要指定恢复的目录
sql-client.sh -f word_cnt.sql
- 1
故障之后的恢复
-- 1、先找到任务在HDFS保存的CK的路径
/flink/checkpoint/1671967bd489e4dcb9b817d72f5a74a9/chk-5
-- 2、在刚刚的word_cnt.sql文件中的insert语句前加入下面内容
SET 'execution.savepoint.path' = 'hdfs://master:9000/flink/checkpoint/1671967bd489e4dcb9b817d72f5a74a9/chk-5';
-- 3、再次通过sql-client.sh提交任务
sql-client.sh -f word_cnt.sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
优化
Source被多次使用
drop table if exists students_01; CREATE TABLE if not exists students_01( id STRING, name STRING, age INT, gender STRING, clazz STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'students_01', -- 指定topic 'properties.bootstrap.servers' = 'master:9092', -- 指定kafka集群列表 'properties.group.id' = 'testGroup', -- 指定消费者组 'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置 'format' = 'csv', -- 指定数据的格式 'csv.field-delimiter' = ',' ,-- 指定分隔符 'csv.ignore-parse-errors' ='true' -- 跳过脏数据 ); -- 创建sink表 CREATE TABLE clazz_cnt ( clazz STRING, cnt BIGINT ) WITH ( 'connector' = 'print' ); CREATE TABLE gender_cnt ( gender STRING, cnt BIGINT ) WITH ( 'connector' = 'print' ); CREATE TABLE age_cnt ( age INT, cnt BIGINT ) WITH ( 'connector' = 'print' ); -- 假设同一个source被使用多次 -- 统计班级人数 insert into clazz_cnt select clazz ,count(*) as cnt from students_01 group by clazz ; -- 统计性别人数 insert into gender_cnt select gender ,count(*) as cnt from students_01 group by gender ; -- 统计年龄人数 insert into age_cnt select age ,count(*) as cnt from students_01 group by age ; -- 每个insert都会提交一次job,最终会产生三个job -- 但每个job的source都一样,故可以进行合并 -- 执行一组INSERT,最终只会生成一个Job EXECUTE STATEMENT SET BEGIN -- 统计班级人数 insert into clazz_cnt select clazz ,count(*) as cnt from students_01 group by clazz ; -- 统计性别人数 insert into gender_cnt select gender ,count(*) as cnt from students_01 group by gender ; -- 统计年龄人数 insert into age_cnt select age ,count(*) as cnt from students_01 group by age ; END;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
反压
下游任务处理数据的速度 无法跟上 上游Source接收数据的速度
-
准备数据
-- 创建datagen source表 drop table if exists words_datagen; CREATE TABLE words_datagen ( word STRING ) WITH ( 'connector' = 'datagen', 'rows-per-second'='50000', -- 指定每秒生成的数据量 'fields.word.length'='5' ); drop table if exists blackhole_table; CREATE TABLE blackhole_table ( word STRING, cnt BIGINT ) WITH ( 'connector' = 'blackhole' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据量太大
insert into blackhole_table select word, count(1) as cnt from words_datagen /*+ OPTIONS('rows-per-second'='50000') */ group by word; -- 开启微批处理 set 'table.exec.mini-batch.enabled' ='true'; set 'table.exec.mini-batch.allow-latency' = '5 s'; set 'table.exec.mini-batch.size' ='100000'; -- 开启预聚合 set 'table.optimizer.agg-phase-strategy' ='TWO_PHASE';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
状态过大
CK消耗的时间过大
insert into blackhole_table select word, count(1) as cnt from words_datagen /*+ OPTIONS('fields.word.length'='6') */ group by word; -- 增加资源 -- 1、增加并行度 SET 'parallelism.default' = '8'; -- 2、增加TM内存 -- 修改配置文件 taskmanager.memory.process.size: 5000m -- 通过命令提交时,可以通过参数指定: -ytm,--yarntaskManagerMemory flink run -ytm 5000m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

