
热门标签
热门文章
- 1git回退到特定版本_git回退到某个版本代码没变
- 2CPCI高速信号处理板CPCI6U-4DSP-C6455_cpci srio接口卡有哪些
- 3手机接收机的功能电路(3)---振荡电路、锁相环_通信系统中的中频模块是否采用锁相环结构
- 4SpringBoot:正常启动,Controller 无法访问_springboot的controller层无法访问
- 5ubuntu+jdk+tomcat+mysql_ubuntu上搭建好jdk、tomcat以及mysql
- 6AI智能名片小程序源码在付费媒体与企业营销策略中的创新应用
- 7二叉树笔记_如果要将二叉树建立一个最大堆
- 8html5 维基,HTML5/tokenization
- 9element-ui全局引入、修改组件样式_element-ui 组件内样式
- 10NLM、LLM、MLLM概述
当前位置: article > 正文
在甲骨文云上用 Ray +Vllm 部署 Mixtral 8*7B 模型_mixtral 8x7b 部署
作者:繁依Fanyi0 | 2024-08-15 15:35:22
赞
踩
mixtral 8x7b 部署
0. 背景
根据好几个项目的需求,多次尝试 Mixtral-8x7B-Instruct-v0.1 这个模型,确实性能不错。
怎奈自己的个人电脑在配置上确实无法驾驭 Mixtral-8x7B-Instruct-v0.1 这个 46.7B 的模型(速度太慢),今天就尝试基于甲骨文云的 GPU 实例部署一下,来应对接下来的开发。
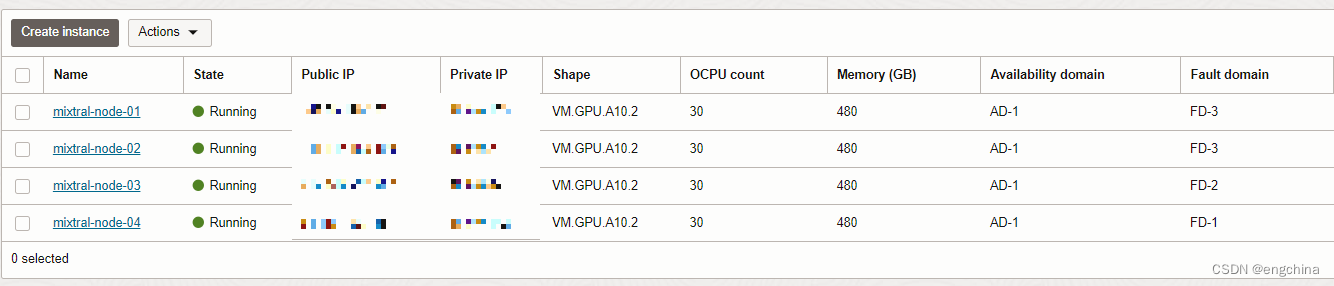
1. 甲骨文云 GPU 实例
今天部署 Mixtral-8x7B-Instruct-v0.1 这个 46.7B 的模型,使用了甲骨文云 4 个 VM.A10.2 GPU 实例,1个 VM.A10.2 有 2 个 24GB 的 A10 GPU,4个的话是 4 * 24GB * 2 = 192GB GPU。
2. 配置 VCN 的 Security List
配置私网 CIDR 10.0.0.0/24 的 All Protocols 是开放的。
注意:生产环境请仅开放必要端口
3. 安装 Ray 和 Vllm
# 20240131 时点 ray==2.9.1 vllm==0.3.0 的版本报错
# pip install -U ray ray[client] ray[default] vllm
pip install -U vllm==0.2.7 ray==2.9.0 ray[client] ray[default]
- 1
- 2
- 3
4. 启动 Ray
启动 head node,
ray start --disable-usage-stats --head --num-gpus 2 --include-dashboard True --dashboard-host 0.0.0.0 --dashboard-port 8265
- 1
To add another node to this Ray cluster,
ray start --disable-usage-stats --num-gpus 2 --address='<head node ip>:6379'
- 1
5. 启动 Vllm
安装 git lfs,
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
sudo dnf install git-lfs -y
git lfs install
- 1
- 2
- 3
这里使用了 8 个 GPU,所以设置 --tensor-parallel-size 的值是 8。
python -m vllm.entrypoints.openai.api_server --trust-remote-code --served-model-name gpt-4 --model mistralai/Mixtral-8x7B-Instruct-v0.1 --gpu-memory-utilization 1 --tensor-parallel-size 8 --port 8000
- 1
启动之后,通过 Ray Dashboard 查看 Cluster 的情况。
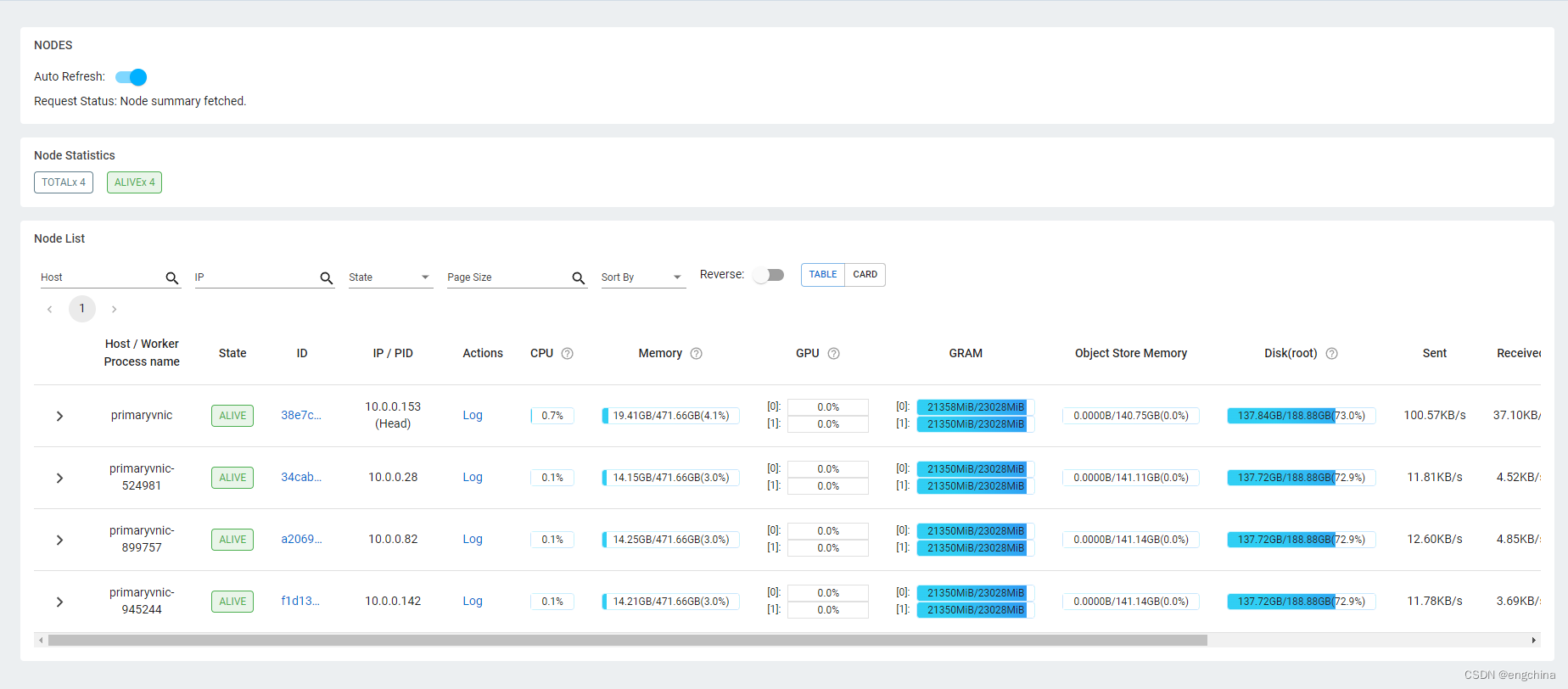
完结!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/984138
推荐阅读
相关标签

