
- 1聚类算法也可以异常检测?DBSCAN算法详解。
- 2Python多进程库multiprocessing中进程池Pool类的使用_在 'multiprocessing.py' 中找不到引用 'pool
- 3【PyCharm】无法创建虚拟环境,提示:has no attribute CPython3macOsBrew_pycharm无法创建虚拟环境
- 4【开源推荐】本地运行自己的大模型--ollama
- 5华为OD机试D卷 --模拟目录管理功能--24年OD统一考试(Java & JS & Python & C & C++)_java实现一个模拟目录管理功能的软件,输入一个命令序列,输出最后一条命令运行结果
- 6Clion Makefile target的进度条看不到
- 7rknn(rknpu)使用笔记_rknn.config
- 8最新IntelliJ IDEA 2024.1 安装和快速配置教程_idea2024.1
- 9STM32开发实例_基于Zigbee的智能路灯系统(电路图+程序+流程图)24-32-64_tm32单片机,zigbee通信 ,4g模块,onenet平台,远程控制
- 10思科模拟器完成实验报告_思科模拟器实训报告
Doris学习笔记之数据表的创建_doris建表语句
赞
踩
创建用户和数据库
mysql> create user 'test' identified by 'test';
Query OK, 0 rows affected (0.01 sec)
mysql> create database test;
Query OK, 0 rows affected (0.01 sec)
mysql> grant all on test to test;
Query OK, 0 rows affected (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
基本概念
在Doris中,数据都以关系表(Table)的形式进行逻辑上的描述。
Row & Column
一张表包括行(Row)和列(Column)。Row即用户的一行数据,Column用于描述一行数据中不同的字段。
在默认的数据模型中,Column只分为排序列和非排序列。存储引擎会按照排序列对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
而在聚合模型中,Column可以分为两大类:Key和Value。从业务角度看,Key和Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key列相同的行,会聚合成一行。其中Value列的聚合方式由用户在建表时指定。
Partition & Tablet
在Doris的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步地按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
Tablet之间的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。
Partition可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个Partition 进行。
建表示例
基本语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition12,]])
[ENGINE = [olap|mysql|broker|hive]]
[key_desc]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)];
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Doris的建表是一个同步命令,命令返回成功,即表示建表成功。
Doris 支持支持单分区和复合分区两种建表方式。
-
复合分区:既有分区也有分桶
第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围;
第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行HASH分布。 -
单分区:只做HASH分布,即只分桶。
字段类型
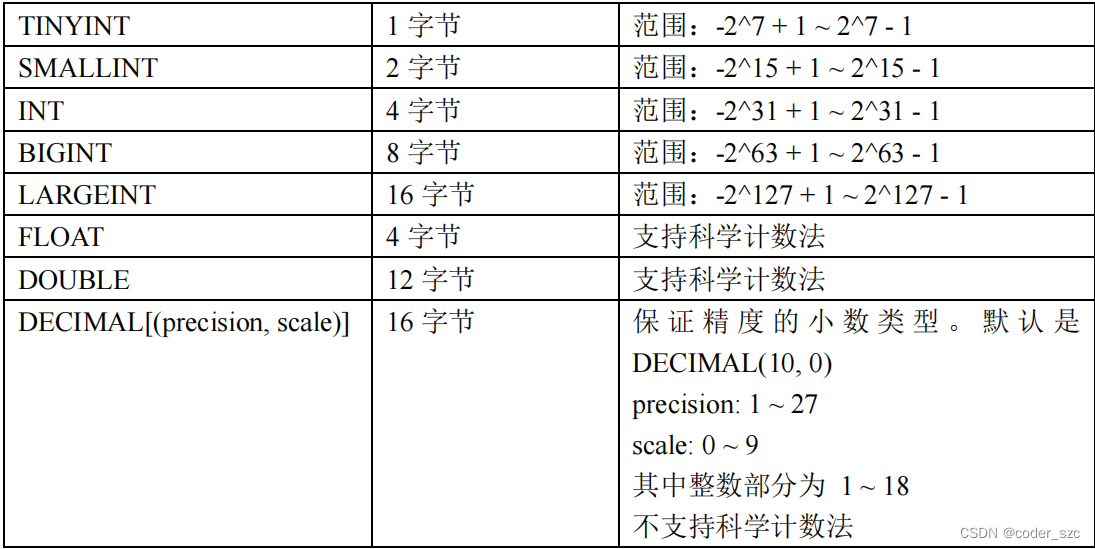
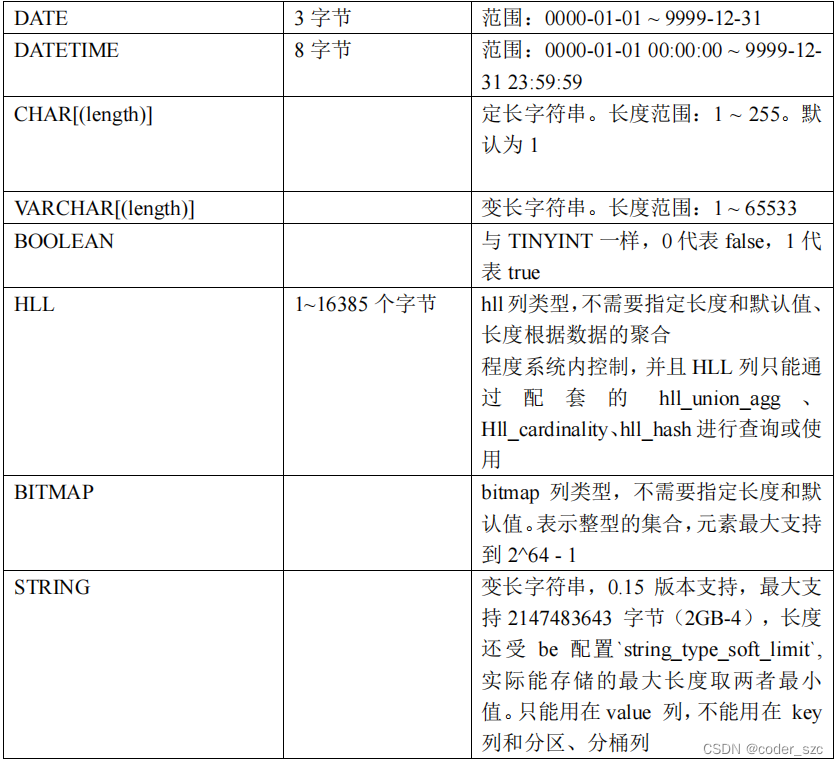
聚合模型在定义字段类型后,可以指定字段的agg_type聚合类型,如果不指定,则该列为key列。否则,该列为value列, agg_type类型包括:SUM、MAX、MIN、REPLACE。
示例
Range分区
CREATE TABLE IF NOT EXISTS test.expamle_range_tbl ( `user_id` LARGEINT NOT NULL COMMENT "用户 id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间" ) ENGINE=olap AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`) PARTITION BY RANGE(`date`) ( PARTITION `p201701` VALUES LESS THAN ("2017-02-01"), PARTITION `p201702` VALUES LESS THAN ("2017-03-01"), PARTITION `p201703` VALUES LESS THAN ("2017-04-01") ) DISTRIBUTED BY HASH(`user_id`) BUCKETS 16 PROPERTIES ( "replication_num" = "1", "storage_medium" = "SSD", "storage_cooldown_time" = "2022-06-01 12:00:00" );

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
List分区
CREATE TABLE IF NOT EXISTS test.expamle_list_tbl ( `user_id` LARGEINT NOT NULL COMMENT "用户 id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳", `city` VARCHAR(20) NOT NULL COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间" ) ENGINE=olap AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`) PARTITION BY LIST(`city`) ( PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"), PARTITION `p_usa` VALUES IN ("New York", "San Francisco"), PARTITION `p_jp` VALUES IN ("Tokyo") ) DISTRIBUTED BY HASH(`user_id`) BUCKETS 16 PROPERTIES ( "replication_num" = "1", "storage_medium" = "SSD", "storage_cooldown_time" = "2022-06-01 12:00:00" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
数据划分
列定义
以AGGREGATE KEY数据模型为例进行说明。更多数据模型参阅Doris数据模型。
列的基本类型,可以通过在mysql-client中执行HELP CREATE TABLE;查看。AGGREGATE KEY数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为Key列。而其余则为Value列。
定义列时,可参照如下建议:
- Key列必须在所有Value列之前;
- 尽量选择整型类型。因为整型类型的计算和查找比较效率远高于字符串;
- 对于不同长度的整型类型的选择原则,遵循够用即可;
- 对于VARCHAR和STRING类型的长度,遵循够用即可;
- 所有列的总字节长度(包括Key和Value)不能超过100KB。
分区与分桶
Doris 支持两层的数据划分。第一层是Partition,支持Range和List划分方式。第二层是Bucket(Tablet),仅支持Hash的划分方式。也可以仅使用一层分区,此时,只支持Bucket划分。
Partition分区
Partition列可以指定一列或多列。分区类必须为KEY列。
- 多列分区的使用方式在后面介绍;
- 不论分区列是什么类型,在写分区值时,都需要加双引号;
- 分区数量理论上没有上限;
- 当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的Partition。该 Partition 对用户不可见,并且不可删改。
Range 分区
分区列通常为时间列,以方便的管理新旧数据。不可添加范围重叠的分区。
Partition 指定范围的方式
VALUES LESS THAN (...)仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。分区的删除不会改变已存在分区的范围,但可能出现数据空洞。
VALUES [...) 指定同时指定上下界,生成一个左闭右开的区间。
通过VALUES [...) 同时指定上下界比较容易理解。这里举例说明,当使用VALUESLESS THAN (...)语句进行分区的增删操作时,分区范围的变化情况:
(1)以如上expamle_range_tbl为例,当建表完成后,会自动生成如下3个分区:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
- 1
- 2
- 3
(2)增加一个分区p201705 VALUES LESS THAN (“2017-06-01”),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
p201705: [2017-04-01, 2017-06-01)
- 1
- 2
- 3
- 4
(3)此时删除分区p201703,则分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
- 1
- 2
- 3
注意到p201702和p201705的分区范围并没有发生变化,而这两个分区之间,出现了一个空洞:[2017-03-01, 2017-04-01)。即如果导入的数据范围在这个空洞范围内,是无法导入的。
(4)继续删除分区p201702,分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201705: [2017-04-01, 2017-06-01)
- 1
- 2
空洞范围变为:[2017-02-01, 2017-04-01)
(5)现在增加一个分区p201702new VALUES LESS THAN (“2017-03-01”),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
- 1
- 2
- 3
可以看到空洞范围缩小为:[2017-03-01, 2017-04-01)
(6)现在删除分区p201701,并添加分区p201612 VALUES LESS THAN (“2017-01-01”),分区结果如下:
p201612: [MIN_VALUE, 2017-01-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
- 1
- 2
- 3
即出现了一个新的空洞:[2017-01-01, 2017-02-01)
List 分区
分区列支持BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区,不可添加范围重叠的分区。
Partition支持通过VALUES IN (...)来指定每个分区包含的枚举值。下面通过示例说明,进行分区的增删操作时,分区的变化。
(1)以example_list_tbl为例,当建表完成后,会自动生成如下3个分区:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
- 1
- 2
- 3
(2)增加一个分区p_uk VALUES IN (“London”),分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
p_uk: ("London")
- 1
- 2
- 3
- 4
(3)删除分区p_jp,分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_uk: ("London")
- 1
- 2
- 3
Bucket
- 如果使用了Partition,则
DISTRIBUTED ...语句描述的是数据在各个分区内的划分规则。如果不使用Partition,则描述的是对整个表的数据的划分规则; - 分桶列可以是多列,但必须为Key列。分桶列可以和Partition列相同或不同;
- 分桶列的选择,是在 查询吞吐和查询并发 之间的一种权衡:
- 如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景;
- 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
- 分桶的数量理论上没有上限。
使用复合分区的场景
- 有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送DELETE语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
多列分区
Doris支持指定多列作为分区列,示例如下:
Range分区
PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")
)
- 1
- 2
- 3
- 4
- 5
- 6
指定date(DATE类型) 和 id(INT类型) 作为分区列。以上示例最终得到的分区如下:
p201701_1000: [(MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
p201702_2000: [("2017-02-01", "1000"), ("2017-03-01", "2000") )
p201703_all: [("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE))
- 1
- 2
- 3
注意,最后一个分区用户缺省只指定了date列的分区值,所以id列的分区值会默认填充MIN_VALUE。当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下(数据 --> 分区):
2017-01-01, 200 --> p201701_1000
2017-01-01, 2000 --> p201701_1000
2017-02-01, 100 --> p201701_1000
2017-02-01, 2000 --> p201702_2000
2017-02-15, 5000 --> p201702_2000
2017-03-01, 2000 --> p201703_all
2017-03-10, 1 --> p201703_all
2017-04-01, 1000 --> 无法导入
2017-05-01, 1000 --> 无法导入
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
List分区
PARTITION BY LIST(`id`, `city`)
(
PARTITION `p1_city` VALUES IN (("1", "Beijing"), ("1","Shanghai")),
PARTITION `p2_city` VALUES IN (("2", "Beijing"), ("2","Shanghai")),
PARTITION `p3_city` VALUES IN (("3", "Beijing"), ("3","Shanghai"))
)
- 1
- 2
- 3
- 4
- 5
- 6
指定id(INT类型) 和city(VARCHAR类型) 作为分区列。最终得到的分区如下:
p1_city: [("1", "Beijing"), ("1", "Shanghai")]
p2_city: [("2", "Beijing"), ("2", "Shanghai")]
p3_city: [("3", "Beijing"), ("3", "Shanghai")]
- 1
- 2
- 3
当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:
数据 —> 分区
1, Beijing ---> p1_city
1, Shanghai ---> p1_city
2, Shanghai ---> p2_city
3, Beijing ---> p3_city
1, Tianjin ---> 无法导入
4, Beijing ---> 无法导入
- 1
- 2
- 3
- 4
- 5
- 6
PROPERTIES
在建表语句的最后 PROPERTIES 中,可以指定replication_num、storage_medium和storage_cooldown_time三个参数。
replication_num
每个Tablet的副本数量。默认为3,建议保持默认即可。在建表语句中,所有Partition中的Tablet副本数量统一指定。而在增加新分区时,可以单独指定新分区中Tablet的副本数量。
副本数量可以在运行时修改。强烈建议保持奇数。
最大副本数量取决于集群中独立IP的数量(注意不是BE数量)。Doris中副本分布的原则是,不允许同一个Tablet的副本分布在同一台物理机上,而识别物理机即通过IP。所以,即使在同一台物理机上部署了3个或更多BE实例,如果这些BE的IP相同,则依然只能设置副本数为1。
对于一些小,并且更新不频繁的维度表,可以考虑设置更多的副本数。这样在Join查询时,可以有更大的概率进行本地数据Join。
storage_medium & storage_cooldown_time
BE的数据存储目录可以显式的指定为SSD或者HDD(通过.SSD或者.HDD后缀区分)。建表时,可以统一指定所有Partition初始存储的介质。注意,后缀作用是显式指定磁盘介质,而不会检查是否与实际介质类型相符。
默认初始存储介质可通过fe的配置文件fe.conf中指定default_storage_medium=xxx,如果没有指定,则默认为HDD。如果指定为SSD,则数据初始存放在SSD上。
如果没有指定storage_cooldown_time,则默认30天后,数据会从SSD自动迁移到HDD上。如果指定了storage_cooldown_time,则在到达storage_cooldown_time时间后,数据才会迁移。
注意,当指定storage_medium时,如果FE参数enable_strict_storage_medium_check为False该参数只是一个“尽力而为”的设置。即使集群内没有设置SSD存储介质,也不会报错,而是自动存储在可用的数据目录中。 同样,如果SSD介质不可访问、空间不足,都可能导致数据初始直接存储在其他可用介质上。而数据到期迁移到HDD时,如果HDD介质不可访问 、空间不足,也可能迁移失败( 但是会不断尝试)。如果FE参数enable_strict_storage_medium_check为True则当集群内没有设置SSD存储介质时,会报错Failed to find enough host in all backends with storage medium is SSD。
ENGINE
本示例中,ENGINE的类型是olap,即默认的ENGINE类型。在Doris中,只有这个ENGINE类型是由Doris负责数据管理和存储的。其他ENGINE类型,如mysql、broker、es等等,本质上只是对外部其他数据库或系统中的表的映射,以保证Doris可以读取这些数据。而Doris本身并不创建、管理和存储任何非olap ENGINE类型的表和数据。
其他
IF NOT EXISTS表示如果没有创建过该表,则创建。注意这里只判断表名是否存在,而不会判断新建表结构是否与已存在的表结构相同。
数据模型
Doris 的数据模型主要分为 3 类:Aggregate、Uniq、Duplicate。
Aggregate 模型
表中的列按照是否设置了AggregationType,分为Key(维度列)和Value(指标列)。没有设置 AggregationType的称为Key,设置了AggregationType的称为Value。
当我们导入数据时,对于Key列相同的行会聚合成一行,而Value列会按照设置的AggregationType 进行聚合。AggregationType目前有以下四种聚合方式:
- SUM:求和,多行的Value进行累加;
- REPLACE:替代,下一批数据中的Value会替换之前导入过的行中的Value。
- REPLACE_IF_NOT_NULL:当遇到null值则不更新;
- MAX:保留最大值;
- MIN:保留最小值。
数据的聚合,在Doris中有如下三个阶段发生:
- 每一批次数据导入的ETL阶段。该阶段会在每一批次导入的数据内部进行聚合;
- 底层BE进行数据Compaction的阶段。该阶段,BE会对已导入的不同批次的数据进行进一步的聚合;
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。(可参阅聚合模型的局限性一节获得更多详情。)
示例1:导入数据聚合
建表:
CREATE TABLE IF NOT EXISTS test.example_site_visit ( `user_id` LARGEINT NOT NULL COMMENT "用户 id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `last_visit_date_not_null` DATETIME REPLACE_IF_NOT_NULL DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间" ) AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 10 PROPERTIES ( "replication_num" = "1", "storage_medium" = "SSD" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
插入数据:
insert into test.example_site_visit values\
(10000,'2017-10-01','北京',20,0,'2017-10-01 06:00:00','2017-10-01 06:00:00',20,10,10),\
(10000,'2017-10-01','北京',20,0,'2017-10-01 07:00:00','2017-10-01 07:00:00',15,2,2),\
(10001,'2017-10-01','北京',30,1,'2017-10-01 17:05:45','2017-10-01 07:00:00',2,22,22),\
(10002,'2017-10-02','上海',20,1,'2017-10-02 12:59:12',null,200,5,5),\
(10003,'2017-10-02','广州',32,0,'2017-10-02 11:20:00','2017-10-02 11:20:00',30,11,11),\
(10004,'2017-10-01','深圳',35,0,'2017-10-01 10:00:15','2017-10-01 10:00:15',100,3,3),\
(10004,'2017-10-03','深圳',35,0,'2017-10-03 10:20:22','2017-10-03 10:20:22',11,6,6);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:Insert into 单条数据这种操作在 Doris 里只能演示不能在生产使用,会引发写阻塞。
查看表:
mysql> select * from test.example_site_visit;
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| user_id | date | city | age | sex | last_visit_date | last_visit_date_not_null | cost | max_dwell_time | min_dwell_time |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | NULL | 200 | 5 | 5 |
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2017-10-01 07:00:00 | 2 | 22 | 22 |
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
6 rows in set (0.05 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以看到,用户10000只剩下了一行聚合后的数据。而其余用户的数据和原始数据保持一致。经过聚合,Doris中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
示例2:保留明细数据
建表:
CREATE TABLE IF NOT EXISTS test.example_site_visit2 ( `user_id` LARGEINT NOT NULL COMMENT "用户 id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `timestamp` DATETIME COMMENT "数据灌入时间,精确到秒", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间" ) AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 10 PROPERTIES ( "replication_num" = "1", "storage_medium" = "SSD" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
插入数据:
insert into test.example_site_visit2 values(10000,'2017-10-01','2017-10-01 08:00:05','北京',20,0,'2017-10-01 06:00:00',20,10,10),\
(10000,'2017-10-01','2017-10-01 09:00:05','北京',20,0,'2017-10-01 07:00:00',15,2,2),\
(10001,'2017-10-01','2017-10-01 18:12:10','北京',30,1,'2017-10-01 17:05:45',2,22,22),\
(10002,'2017-10-02','2017-10-02 13:10:00','上海',20,1,'2017-10-02 12:59:12',200,5,5),\
(10003,'2017-10-02','2017-10-02 13:15:00','广州',32,0,'2017-10-02 11:20:00',30,11,11),\
(10004,'2017-10-01','2017-10-01 12:12:48','深圳',35,0,'2017-10-01 10:00:15',100,3,3),\
(10004,'2017-10-03','2017-10-03 12:38:20','深圳',35,0,'2017-10-03 10:20:22',11,6,6);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
查看数据:
mysql> select * from test.example_site_visit2;
+---------+------------+---------------------+--------+------+------+---------------------+------+----------------+----------------+
| user_id | date | timestamp | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
+---------+------------+---------------------+--------+------+------+---------------------+------+----------------+----------------+
| 10002 | 2017-10-02 | 2017-10-02 13:10:00 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
| 10001 | 2017-10-01 | 2017-10-01 18:12:10 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
| 10000 | 2017-10-01 | 2017-10-01 08:00:05 | 北京 | 20 | 0 | 2017-10-01 06:00:00 | 20 | 10 | 10 |
| 10000 | 2017-10-01 | 2017-10-01 09:00:05 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 15 | 2 | 2 |
| 10004 | 2017-10-01 | 2017-10-01 12:12:48 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
| 10004 | 2017-10-03 | 2017-10-03 12:38:20 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
| 10003 | 2017-10-02 | 2017-10-02 13:15:00 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
+---------+------------+---------------------+--------+------+------+---------------------+------+----------------+----------------+
7 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以发现,存储的数据和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了timestamp列,所有行的Key都不完全相同。也就是说,只要保证导入的数据中,每一行的 Key都不完全相同,那么即使在聚合模型下,Doris也可以保存完整的明细数据。
示例3:导入数据与已有数据聚合
往示例1中继续插入数据:
insert into test.example_site_visit values(10004,'2017-10-03','深圳',35,0,'2017-10-03 11:22:00',null,44,19,19),\
(10005,'2017-10-03','长沙',29,1,'2017-10-03 18:11:02','2017-10-03 18:11:02',3,1,1);
- 1
- 2
查看数据:
mysql> select * from test.example_site_visit;
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| user_id | date | city | age | sex | last_visit_date | last_visit_date_not_null | cost | max_dwell_time | min_dwell_time |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | NULL | 200 | 5 | 5 |
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2017-10-01 07:00:00 | 2 | 22 | 22 |
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
| 10005 | 2017-10-03 | 长沙 | 29 | 1 | 2017-10-03 18:11:02 | 2017-10-03 18:11:02 | 3 | 1 | 1 |
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 11:22:00 | 2017-10-03 10:20:22 | 55 | 19 | 6 |
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
+---------+------------+--------+------+------+---------------------+--------------------------+------+----------------+----------------+
7 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看到,用户10004的已有数据和新导入的数据发生了聚合,同时新增了10005用户的数据。
Uniq模型
在某些多维分析场景下,用户更关注的是如何保证Key的唯一性,即如何获得Primary Key唯一性约束。因此,我们引入了Uniq的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
建表:
CREATE TABLE IF NOT EXISTS test.user ( `user_id` LARGEINT NOT NULL COMMENT "用户 id", `username` VARCHAR(50) NOT NULL COMMENT "用户昵称", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `phone` LARGEINT COMMENT "用户电话", `address` VARCHAR(500) COMMENT "用户地址", `register_time` DATETIME COMMENT "用户注册时间" ) UNIQUE KEY(`user_id`, `username`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 10 PROPERTIES ( "replication_num" = "1", "storage_medium" = "SSD" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
插入数据:
insert into test.user values\
(10000,'wuyanzu',' 北京',18,0,12345678910,' 北京朝阳区 ','2017-10-01 07:00:00'),\
(10000,'wuyanzu',' 北京',19,0,12345678910,' 北京朝阳区 ','2017-10-01 07:00:00'),\
(10000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15 06:10:20');
- 1
- 2
- 3
- 4
查看数据:
mysql> select * from test.user;
+---------+----------+---------+------+------+-------------+-------------------+---------------------+
| user_id | username | city | age | sex | phone | address | register_time |
+---------+----------+---------+------+------+-------------+-------------------+---------------------+
| 10000 | wuyanzu | 北京 | 19 | 0 | 12345678910 | 北京朝阳区 | 2017-10-01 07:00:00 |
| 10000 | zhangsan | 北京 | 20 | 0 | 12345678910 | 北京海淀区 | 2017-11-15 06:10:20 |
+---------+----------+---------+------+------+-------------+-------------------+---------------------+
2 rows in set (0.03 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Uniq 模型完全可以用聚合模型中的REPLACE方式替代,其内部的实现方式和数据存储方式也完全一样。
Duplicate模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。Duplicate数据模型可以满足这类需求。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。而在建表语句中指定的DUPLICATE KEY,只是用来指明底层数据按照哪些列进行排序。
建表:
CREATE TABLE IF NOT EXISTS test.example_log ( `timestamp` DATETIME NOT NULL COMMENT "日志时间", `type` INT NOT NULL COMMENT "日志类型", `error_code` INT COMMENT "错误码", `error_msg` VARCHAR(1024) COMMENT "错误详细信息", `op_id` BIGINT COMMENT "负责人 id", `op_time` DATETIME COMMENT "处理时间" ) DUPLICATE KEY(`timestamp`, `type`) DISTRIBUTED BY HASH(`timestamp`) BUCKETS 10 PROPERTIES ( "replication_num" = "1", "storage_medium" = "SSD" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
插入数据:
insert into test.example_log values\
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),\
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),\
('2017-10-01 08:00:05',2,404,'not found page', 101, '2017-10-01 08:00:06'),\
('2017-10-01 08:00:06',2,404,'not found page', 101, '2017-10-01 08:00:07');
- 1
- 2
- 3
- 4
- 5
查看表:
mysql> select * from test.example_log;
+---------------------+------+------------+----------------+-------+---------------------+
| timestamp | type | error_code | error_msg | op_id | op_time |
+---------------------+------+------------+----------------+-------+---------------------+
| 2017-10-01 08:00:05 | 1 | 404 | not found page | 101 | 2017-10-01 08:00:05 |
| 2017-10-01 08:00:05 | 1 | 404 | not found page | 101 | 2017-10-01 08:00:05 |
| 2017-10-01 08:00:05 | 2 | 404 | not found page | 101 | 2017-10-01 08:00:06 |
| 2017-10-01 08:00:06 | 2 | 404 | not found page | 101 | 2017-10-01 08:00:07 |
+---------------------+------+------------+----------------+-------+---------------------+
4 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数据模型的选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
- Aggregate模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对count(*) 查询很不友好。同时因为固定了Value列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性;
- Uniq模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用ROLLUP等预聚合带来的查询优势(因为本质是REPLACE,没有SUM这种聚合方式);
- Duplicate适合任意维度的Ad-hoc查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有Key列)。
聚合模型的局限性
这里我们针对Aggregate模型(包括Uniq模型),来介绍下聚合模型的局限性。在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
假设表结构如下:
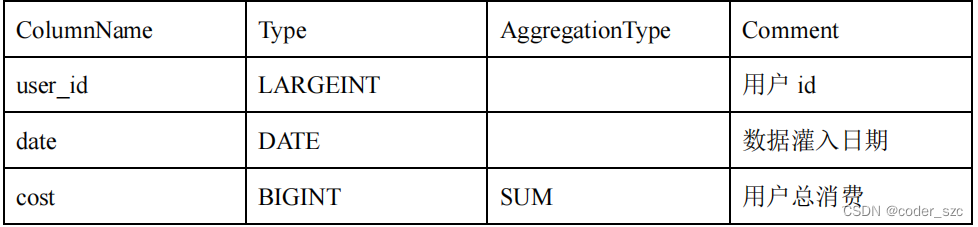
假设存储引擎中有如下两个已经导入完成的批次的数据:
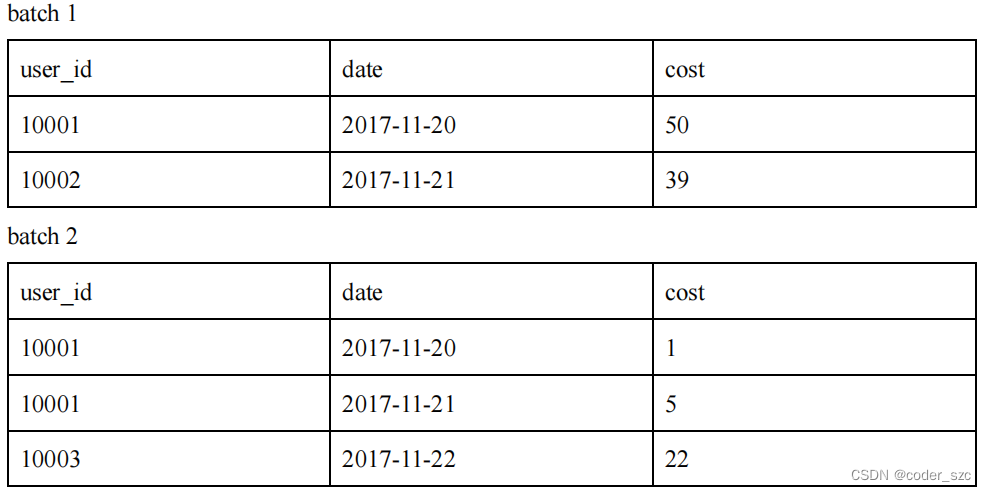
可以看到,用户10001分属在两个导入批次中的数据还没有聚合。但是为了保证用户只能查询到如下最终聚合后的数据:


首先,可以在在查询引擎中加入聚合算子,以保证数据对外的一致性。
另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如我们在如上示例中执行如下查询:
SELECT MIN(cost) FROM table;
- 1
得到的结果是5,而不是1。
同时,这种一致性保证在某些查询中,会极大的降低查询效率。我们以最基本的count(*) 查询为例:
SELECT COUNT(*) FROM table;
- 1
在其他数据库中,这类查询都会很快的返回结果。因为在实现上,我们可以通过如“导入时对行进行计数,保存count的统计信息”,或者在查询时“仅扫描某一列数据,获得 count值”的方式,只需很小的开销,即可获得查询结果。但是在Doris的聚合模型中,这种查询的开销非常大。
上面的例子,select count(*) from table; 的正确结果应该为4。但如果我们只扫描user_id这一列,如果加上查询时聚合,最终得到的结果是3(10001, 10002, 10003)。而如果不加查询时聚合,则得到的结果是5(两批次一共5行数据)。可见这两个结果都是不对的。
为了得到正确的结果,我们必须同时读取user_id和date这两列的数据,再加上查询时聚合,才能返回4这个正确的结果。也就是说,在count(*) 查询中,Doris必须扫描所有的AGGREGATE KEY 列(这里就是user_id和date),并且聚合后,才能得到语意正确的结果。
当聚合列非常多时,count(*)查询需要扫描大量的数据。因此,当业务上有频繁的count(*) 查询时,我们建议用户通过增加一个值恒为1 、聚合类型为SUM的列来模拟 count(*)。如刚才的例子中的表结构,我们修改如下:
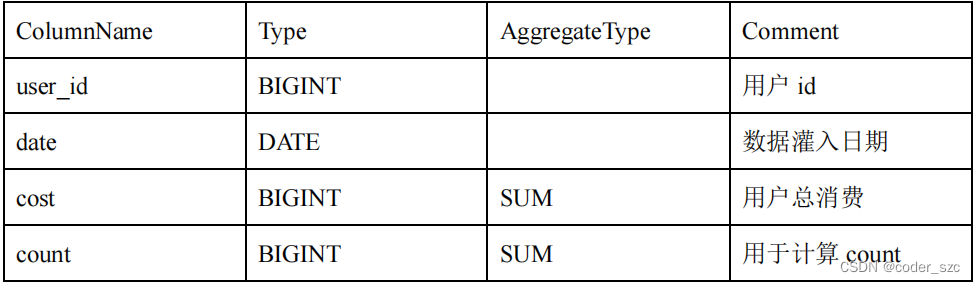
增加一个count列,并且导入数据中,该列值恒为1。则select count(*) from table; 的结果等价于 select sum(count) from table;。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入AGGREGATE KEY列都相同的行。否则,select sum(count) from table; 只能表述原始导入的行数,而不是select count(*) from table; 的语义。
另一种方式,就是将如上的count列的聚合类型改为REPLACE,且依然值恒为1。那么select sum(count) from table;和select count(*) from table;的结果将是一致的。并且这种方式,没有导入重复行的限制。
动态分区
动态分区是在Doris 0.12版本中引入的新功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能,动态分区只支持Range分区。
原理
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
通过动态分区功能,用户可以在建表时设定动态分区的规则。FE会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则。
- 建表时指定:
CREATE TABLE tbl1
(...)
PROPERTIES
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 运行时修改:
ALTER TABLE tbl1 SET
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
);
- 1
- 2
- 3
- 4
- 5
- 6
规则参数
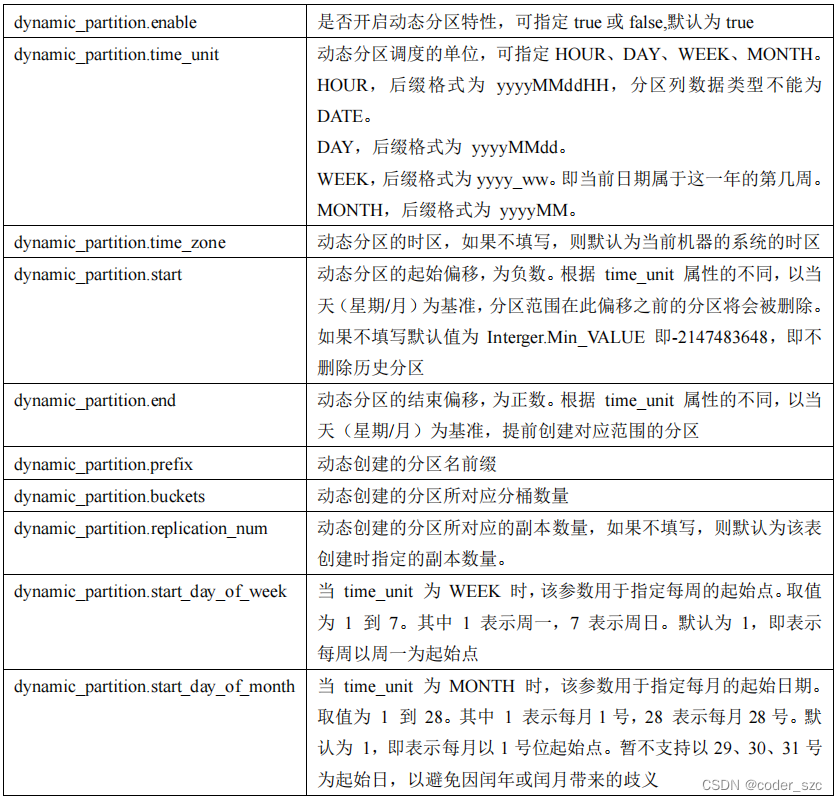
主要参数
动态分区的规则参数都以 dynamic_partition. 为前缀:
创建历史分区的参数
- dynamic_partition.create_history_partition:默认为false。当置为true时,Doris 会自动创建所有分区,当期望创建的分区个数大于max_dynamic_partition_num值时,操作将被禁止。当不指定 start属性时,该参数不生效;
- dynamic_partition.history_partition_num:当create_history_partition为true时,该参数用于指定创建历史分区数量。默认值为-1, 即未设置;
- dynamic_partition.hot_partition_num:指定最新的多少个分区为热分区。对于热分区,系统会自动设置其 storage_medium 参数为SSD,并且设置storage_cooldown_time;
- hot_partition_num:往前n天和未来所有分区。我们举例说明。假设今天是2021-05-20,按天分区,动态分区的属性设置为:hot_partition_num=2, end=3, start=-3。则系统会自动创建以下分区,并且设置 storage_medium和storage_cooldown_time参数:
p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- dynamic_partition.reserved_history_periods:需要保留的历史分区的时间范围。
- 当 dynamic_partition.time_unit设置为"DAY/WEEK/MONTH" 时,需要以[yyyy-MM-dd,yyyy-MM-dd],[…,…] 格式进行设置;
- 当dynamic_partition.time_unit 设置为"HOUR" 时,需要以[yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[…,…]的格式来进行设置;
- 如果不设置,默认为 “NULL”。
我们举例说明。假设今天是2021-09-06,按天分类,动态分区的属性设置为:
time_unit="DAY/WEEK/MONTH", \
end=3, \
start=-3, \
reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"
- 1
- 2
- 3
- 4
则系统会自动保留:
["2020-06-01","2020-06-20"],
["2020-10-31","2020-11-15"]
- 1
- 2
或者
time_unit="HOUR", \
end=3, \
start=-3, \
reserved_history_periods="[2020-06-01 00:00:00,2020-06-01 03:00:00]"
- 1
- 2
- 3
- 4
则系统会自动保留:
["2020-06-01 00:00:00","2020-06-01 03:00:00"]
- 1
这两个时间段的分区。其中,reserved_history_periods的每一个[…,…]是一对设置项,两者需要同时被设置,且第一个时间不能大于第二个时间。
创建历史分区规则
假设需要创建的历史分区数量为expect_create_partition_num,根据不同的设置具体数量如下:
- create_history_partition = true:
dynamic_partition.history_partition_num未设置,即 -1,则expect_create_partition_num = end - start;
dynamic_partition.history_partition_num已设置,则expect_create_partition_num = end - max(start, -histoty_partition_num); - create_history_partition = false:
不会创建历史分区,expect_create_partition_num = end - 0; - 当expect_create_partition_num > max_dynamic_partition_num(默认500):
禁止创建过多分区。
创建历史分区举例
假设今天是2021-05-20,按天分区,动态分区的属性设置为:create_history_partition=true,end=3, start=-3, history_partition_num=1,则系统会自动创建以下分区(4个,且历史分区只有1个):
p20210519
p20210520
p20210521
p20210522
p20210523
- 1
- 2
- 3
- 4
- 5
history_partition_num=5,其余属性不变,则系统会自动创建以下分区(6个,历史分区3个):
p20210517
p20210518
p20210519
p20210520
p20210521
p20210522
p20210523
- 1
- 2
- 3
- 4
- 5
- 6
- 7
history_partition_num=-1 即不设置历史分区数量,其余属性不变,则系统会自动创建以下分区(6个,历史分区3个):
p20210517
p20210518
p20210519
p20210520
p20210521
p20210522
p20210523
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意事项
动态分区使用过程中,如果因为一些意外情况导致dynamic_partition.start和dynamic_partition.end之间的某些分区丢失,那么当前时间与dynamic_partition.end之间的丢失分区会被重新创建,dynamic_partition.start与当前时间之间的丢失分区不会重新创建。
示例
创建表,分区列time类型为DATE,创建一个动态分区规则。按天分区,只保留最近7天的分区,并且预先创建未来3天的分区:
create table student_dynamic_partition1 ( id int, time date, name varchar(50), age int ) duplicate key(id,time) PARTITION BY RANGE(time)() DISTRIBUTED BY HASH(id) buckets 10 PROPERTIES( "dynamic_partition.enable" = "true", "dynamic_partition.time_unit" = "DAY", "dynamic_partition.start" = "-7", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.buckets" = "10", "replication_num" = "1", "storage_medium" = "SSD" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
查看动态分区调度情况:
mysql> SHOW DYNAMIC PARTITION TABLES;
+----------------------------+--------+----------+-------+------+--------+---------+----------------+-------------------------+---------+---------------------+---------------------+--------+------------------------+----------------------+------------------------+
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | ReplicationNum | ReplicaAllocation | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
+----------------------------+--------+----------+-------+------+--------+---------+----------------+-------------------------+---------+---------------------+---------------------+--------+------------------------+----------------------+------------------------+
| student_dynamic_partition1 | true | DAY | -7 | 3 | p | 10 | 1 | tag.location.default: 1 | NULL | 2022-05-14 16:17:24 | 2022-05-14 16:17:24 | NORMAL | NULL | NULL | NULL |
+----------------------------+--------+----------+-------+------+--------+---------+----------------+-------------------------+---------+---------------------+---------------------+--------+------------------------+----------------------+------------------------+
1 row in set (0.02 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中:
- LastUpdateTime: 最后一次修改动态分区属性的时间;
- LastSchedulerTime: 最后一次执行动态分区调度的时间;
- State: 最后一次执行动态分区调度的状态;
- LastCreatePartitionMsg: 最后一次执行动态添加分区调度的错误信息;
- LastDropPartitionMsg: 最后一次执行动态删除分区调度的错误信息
查看表的分区:
mysql> SHOW PARTITIONS FROM student_dynamic_partition1;
+-------------+---------------+----------------+---------------------+--------------------+--------+--------------+----------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+--------------------------+----------+------------+-------------------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | VisibleVersionHash | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation |
+-------------+---------------+----------------+---------------------+--------------------+--------+--------------+----------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+--------------------------+----------+------------+-------------------------+
| 10365 | p20220514 | 1 | 2022-05-14 16:17:24 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-14]; ..types: [DATE]; keys: [2022-05-15]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 |
| 10386 | p20220515 | 1 | 2022-05-14 16:17:24 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-15]; ..types: [DATE]; keys: [2022-05-16]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 |
| 10407 | p20220516 | 1 | 2022-05-14 16:17:24 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-16]; ..types: [DATE]; keys: [2022-05-17]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 |
| 10428 | p20220517 | 1 | 2022-05-14 16:17:24 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-17]; ..types: [DATE]; keys: [2022-05-18]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 |
+-------------+---------------+----------------+---------------------+--------------------+--------+--------------+----------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+--------------------------+----------+------------+-------------------------+
4 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
插入测试数据,注意要把时间改成分区里的时间:
mysql> insert into student_dynamic_partition1 values(1,'2022-05-15 11:00:00','name1',18);
Query OK, 1 row affected (0.06 sec)
{'label':'insert_3c4b08c175d14cb9-998c4b5bcd732a28', 'status':'VISIBLE', 'txnId':'9'}
mysql> insert into student_dynamic_partition1 values(1,'2022-05-14 11:00:00','name1',18);
Query OK, 1 row affected (0.03 sec)
{'label':'insert_40a2af42900f4741-a127684ca5700fb6', 'status':'VISIBLE', 'txnId':'10'}
mysql> insert into student_dynamic_partition1 values(1,'2022-05-16 11:00:00','name1',18);
Query OK, 1 row affected (0.07 sec)
{'label':'insert_6f9ed7c84c624de3-ae13f44bb7dab360', 'status':'VISIBLE', 'txnId':'11'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
设置创建历史分区:
ALTER TABLE student_dynamic_partition1 SET ("dynamic_partition.create_history_partition" = "true");
- 1
查看分区情况:
mysql> SHOW PARTITIONS FROM student_dynamic_partition1; +-------------+---------------+----------------+---------------------+---------------------+--------+--------------+----------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+--------------------------+----------+------------+-------------------------+ | PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | VisibleVersionHash | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | +-------------+---------------+----------------+---------------------+---------------------+--------+--------------+----------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+--------------------------+----------+------------+-------------------------+ | 10452 | p20220507 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-07]; ..types: [DATE]; keys: [2022-05-08]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10473 | p20220508 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-08]; ..types: [DATE]; keys: [2022-05-09]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10494 | p20220509 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-09]; ..types: [DATE]; keys: [2022-05-10]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10515 | p20220510 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-10]; ..types: [DATE]; keys: [2022-05-11]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10536 | p20220511 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-11]; ..types: [DATE]; keys: [2022-05-12]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10557 | p20220512 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-12]; ..types: [DATE]; keys: [2022-05-13]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10578 | p20220513 | 1 | 2022-05-14 16:19:57 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-13]; ..types: [DATE]; keys: [2022-05-14]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10365 | p20220514 | 2 | 2022-05-14 16:18:55 | 929516207550812448 | NORMAL | time | [types: [DATE]; keys: [2022-05-14]; ..types: [DATE]; keys: [2022-05-15]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10386 | p20220515 | 2 | 2022-05-14 16:18:42 | 7997457037777189294 | NORMAL | time | [types: [DATE]; keys: [2022-05-15]; ..types: [DATE]; keys: [2022-05-16]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10407 | p20220516 | 2 | 2022-05-14 16:18:58 | 7092394304145677063 | NORMAL | time | [types: [DATE]; keys: [2022-05-16]; ..types: [DATE]; keys: [2022-05-17]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | | 10428 | p20220517 | 1 | 2022-05-14 16:17:24 | 0 | NORMAL | time | [types: [DATE]; keys: [2022-05-17]; ..types: [DATE]; keys: [2022-05-18]; ) | id | 10 | 1 | HDD | 9999-12-31 23:59:59 | NULL | 0.000 | false | tag.location.default: 1 | +-------------+---------------+----------------+---------------------+---------------------+--------+--------------+----------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+--------------------------+----------+------------+-------------------------+ 11 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
动态分区表与手动分区表相互转换:
对于一个表来说,动态分区和手动分区可以自由转换,但二者不能同时存在,有且只有一种状态。
- 手动分区转换为动态分区:
如果一个表在创建时未指定动态分区,可以通过ALTER TABLE在运行时修改动态分区相关属性来转化为动态分区,具体示例可以通过HELP ALTER TABLE查看。
注意:如果已设定dynamic_partition.start,分区范围在动态分区起始偏移之前的历史分区将会被删除。 - 动态分区转换为手动分区:
关闭动态分区功能后,Doris 将不再自动管理分区,需要用户手动通过 ALTER TABLE的方式创建或删除分区。
ALTER TABLE tbl_name SET ("dynamic_partition.enable" = "false")
- 1
Rollup
ROLLUP在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
基本概念
在Doris中,我们将用户通过建表语句创建出来的表称为Base表(Base Table)。Base表中保存着按用户建表语句指定的方式存储的基础数据。
在Base表之上,我们可以创建任意多个ROLLUP表。这些ROLLUP的数据是基于Base表产生的,并且在物理上是独立存储的。
ROLLUP表的基本作用,在于在Base表的基础上,获得更粗粒度的聚合数据。
Aggregate和Uniq模型中的Rollup
因为Uniq只是Aggregate模型的一个特例,所以这里我们不加以区别。
示例1:以example_site_visit2表为例
- 查看表的结构信息
mysql> desc example_site_visit2 all; +---------------------+---------------+-----------------+-------------+------+-------+---------------------+---------+---------+ | IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible | +---------------------+---------------+-----------------+-------------+------+-------+---------------------+---------+---------+ | example_site_visit2 | AGG_KEYS | user_id | LARGEINT | No | true | NULL | | true | | | | date | DATE | No | true | NULL | | true | | | | timestamp | DATETIME | Yes | true | NULL | | true | | | | city | VARCHAR(20) | Yes | true | NULL | | true | | | | age | SMALLINT | Yes | true | NULL | | true | | | | sex | TINYINT | Yes | true | NULL | | true | | | | last_visit_date | DATETIME | Yes | false | 1970-01-01 00:00:00 | REPLACE | true | | | | cost | BIGINT | Yes | false | 0 | SUM | true | | | | max_dwell_time | INT | Yes | false | 0 | MAX | true | | | | min_dwell_time | INT | Yes | false | 99999 | MIN | true | +---------------------+---------------+-----------------+-------------+------+-------+---------------------+---------+---------+ 10 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 比如需要查看某个用户的总消费,那么可以建立一个只有user_id和cost的rollup:
alter table example_site_visit2 add rollup rollup_cost_userid(user_id,cost);
- 1
- 查看表的结构信息:
mysql> desc example_site_visit2 all; +---------------------+---------------+-----------------+-------------+------+-------+---------------------+---------+---------+ | IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible | +---------------------+---------------+-----------------+-------------+------+-------+---------------------+---------+---------+ | example_site_visit2 | AGG_KEYS | user_id | LARGEINT | No | true | NULL | | true | | | | date | DATE | No | true | NULL | | true | | | | timestamp | DATETIME | Yes | true | NULL | | true | | | | city | VARCHAR(20) | Yes | true | NULL | | true | | | | age | SMALLINT | Yes | true | NULL | | true | | | | sex | TINYINT | Yes | true | NULL | | true | | | | last_visit_date | DATETIME | Yes | false | 1970-01-01 00:00:00 | REPLACE | true | | | | cost | BIGINT | Yes | false | 0 | SUM | true | | | | max_dwell_time | INT | Yes | false | 0 | MAX | true | | | | min_dwell_time | INT | Yes | false | 99999 | MIN | true | | | | | | | | | | | | rollup_cost_userid | AGG_KEYS | user_id | LARGEINT | No | true | NULL | | true | | | | cost | BIGINT | Yes | false | 0 | SUM | true | +---------------------+---------------+-----------------+-------------+------+-------+---------------------+---------+---------+ 13 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 然后可以通过 explain 查看执行计划,是否使用到了 rollup:
mysql> explain SELECT user_id, sum(cost) FROM example_site_visit2 GROUP BY user_id; +---------------------------------------------------------------------------------------+ | Explain String | +---------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:<slot 2> `user_id` | <slot 3> sum(`cost`) | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 2:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | UNPARTITIONED | | | | 1:AGGREGATE (update finalize) | | | output: sum(`cost`) | | | group by: `user_id` | | | cardinality=-1 | | | | | 0:OlapScanNode | | TABLE: example_site_visit2 | | PREAGGREGATION: ON | | partitions=1/1 | | rollup: rollup_cost_userid | | tabletRatio=10/10 | | tabletList=10601,10603,10605,10607,10609,10611,10613,10615,10617,10619 | | cardinality=0 | | avgRowSize=24.0 | | numNodes=1 | +---------------------------------------------------------------------------------------+ 31 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
Doris会自动命中这个ROLLUP表,从而只需扫描极少的数据量,即可完成这次聚合查询。
- 通过命令查看完成状态:
mysql> SHOW ALTER TABLE ROLLUP;
+-------+---------------------+---------------------+---------------------+---------------------+--------------------+----------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------------+---------------------+---------------------+---------------------+--------------------+----------+---------------+----------+------+----------+---------+
| 10599 | example_site_visit2 | 2022-05-14 16:25:23 | 2022-05-14 16:25:44 | example_site_visit2 | rollup_cost_userid | 10600 | 12 | FINISHED | | NULL | 86400 |
+-------+---------------------+---------------------+---------------------+---------------------+--------------------+----------+---------------+----------+------+----------+---------+
1 row in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间
- 创建 ROLLUP
alter table example_site_visit2 add rollup rollup_city_age_cost_maxd_mind(city,age,cost,max_dwell_time,min_dwell_time);
- 1
- 查看 rollup 使用
mysql> explain SELECT city, age, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM example_site_visit2 GROUP BY city, age; +-----------------------------------------------------------------------------------------------------------------------------------------+ | Explain String | +-----------------------------------------------------------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:<slot 5> `city` | <slot 6> `age` | <slot 7> sum(`cost`) | <slot 8> max(`max_dwell_time`) | <slot 9> min(`min_dwell_time`) | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 4:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: <slot 5> `city`, <slot 6> `age` | | | | STREAM DATA SINK | | EXCHANGE ID: 04 | | UNPARTITIONED | | | | 3:AGGREGATE (merge finalize) | | | output: sum(<slot 7> sum(`cost`)), max(<slot 8> max(`max_dwell_time`)), min(<slot 9> min(`min_dwell_time`)) | | | group by: <slot 5> `city`, <slot 6> `age` | | | cardinality=-1 | | | | | 2:EXCHANGE | | | | PLAN FRAGMENT 2 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | HASH_PARTITIONED: <slot 5> `city`, <slot 6> `age` | | | | 1:AGGREGATE (update serialize) | | | STREAMING | | | output: sum(`cost`), max(`max_dwell_time`), min(`min_dwell_time`) | | | group by: `city`, `age` | | | cardinality=-1 | | | | | 0:OlapScanNode | | TABLE: example_site_visit2 | | PREAGGREGATION: ON | | partitions=1/1 | | rollup: example_site_visit2 | | tabletRatio=10/10 | | tabletList=10255,10257,10259,10261,10263,10265,10267,10269,10271,10273 | | cardinality=6 | | avgRowSize=1358.0 | | numNodes=1 | +-----------------------------------------------------------------------------------------------------------------------------------------+ 47 rows in set (0.00 sec) mysql> explain SELECT city, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM example_site_visit2 GROUP BY city; +------------------------------------------------------------------------------------------------------------------------+ | Explain String | +------------------------------------------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:<slot 4> `city` | <slot 5> sum(`cost`) | <slot 6> max(`max_dwell_time`) | <slot 7> min(`min_dwell_time`) | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 4:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: <slot 4> `city` | | | | STREAM DATA SINK | | EXCHANGE ID: 04 | | UNPARTITIONED | | | | 3:AGGREGATE (merge finalize) | | | output: sum(<slot 5> sum(`cost`)), max(<slot 6> max(`max_dwell_time`)), min(<slot 7> min(`min_dwell_time`)) | | | group by: <slot 4> `city` | | | cardinality=-1 | | | | | 2:EXCHANGE | | | | PLAN FRAGMENT 2 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | HASH_PARTITIONED: <slot 4> `city` | | | | 1:AGGREGATE (update serialize) | | | STREAMING | | | output: sum(`cost`), max(`max_dwell_time`), min(`min_dwell_time`) | | | group by: `city` | | | cardinality=-1 | | | | | 0:OlapScanNode | | TABLE: example_site_visit2 | | PREAGGREGATION: ON | | partitions=1/1 | | rollup: rollup_city_age_cost_maxd_mind | | tabletRatio=10/10 | | tabletList=10623,10625,10627,10629,10631,10633,10635,10637,10639,10641 | | cardinality=0 | | avgRowSize=32.0 | | numNodes=1 | +------------------------------------------------------------------------------------------------------------------------+ 47 rows in set (0.00 sec) mysql> explain SELECT city, age, sum(cost), min(min_dwell_time) FROM example_site_visit2 GROUP BY city, age; +--------------------------------------------------------------------------------------------------------+ | Explain String | +--------------------------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:<slot 4> `city` | <slot 5> `age` | <slot 6> sum(`cost`) | <slot 7> min(`min_dwell_time`) | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 4:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: <slot 4> `city`, <slot 5> `age` | | | | STREAM DATA SINK | | EXCHANGE ID: 04 | | UNPARTITIONED | | | | 3:AGGREGATE (merge finalize) | | | output: sum(<slot 6> sum(`cost`)), min(<slot 7> min(`min_dwell_time`)) | | | group by: <slot 4> `city`, <slot 5> `age` | | | cardinality=-1 | | | | | 2:EXCHANGE | | | | PLAN FRAGMENT 2 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`example_site_visit2`.`user_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | HASH_PARTITIONED: <slot 4> `city`, <slot 5> `age` | | | | 1:AGGREGATE (update serialize) | | | STREAMING | | | output: sum(`cost`), min(`min_dwell_time`) | | | group by: `city`, `age` | | | cardinality=-1 | | | | | 0:OlapScanNode | | TABLE: example_site_visit2 | | PREAGGREGATION: ON | | partitions=1/1 | | rollup: rollup_city_age_cost_maxd_mind | | tabletRatio=10/10 | | tabletList=10623,10625,10627,10629,10631,10633,10635,10637,10639,10641 | | cardinality=0 | | avgRowSize=30.0 | | numNodes=1 | +--------------------------------------------------------------------------------------------------------+ 47 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 通过命令查看完成状态
mysql> SHOW ALTER TABLE ROLLUP;
+-------+---------------------+---------------------+---------------------+---------------------+--------------------------------+----------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------------+---------------------+---------------------+---------------------+--------------------------------+----------+---------------+----------+------+----------+---------+
| 10599 | example_site_visit2 | 2022-05-14 16:25:23 | 2022-05-14 16:25:44 | example_site_visit2 | rollup_cost_userid | 10600 | 12 | FINISHED | | NULL | 86400 |
| 10621 | example_site_visit2 | 2022-05-14 16:27:54 | 2022-05-14 16:28:24 | example_site_visit2 | rollup_city_age_cost_maxd_mind | 10622 | 13 | FINISHED | | NULL | 86400 |
+-------+---------------------+---------------------+---------------------+---------------------+--------------------------------+----------+---------------+----------+------+----------+---------+
2 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Duplicate模型中的Rollup
因为Duplicate模型没有聚合的语意,所以该模型中的ROLLUP,已经失去了“上卷”这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。下面详细介绍前缀索引,以及如何使用ROLLUP改变前缀索引,以获得更好的查询效率。
前缀索引
不同于传统的数据库设计,Doris不支持在任意列上创建索引。Doris这类MPP架构的OLAP数据库,通常都是通过提高并发来处理大量数据的。
本质上,Doris的数据存储在类似SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
在Aggregate、Uniq 和 Duplicate三种数据模型中,底层的数据存储是按照各自建表语句中,AGGREGATE KEY、UNIQ KEY和DUPLICATE KEY中指定的列进行排序存储的。而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
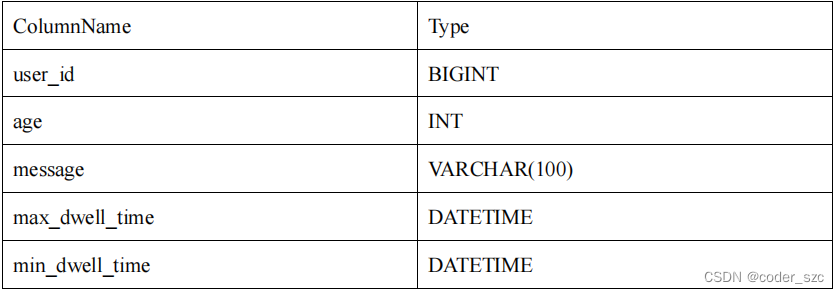
我们将一行数据的前36个字节作为这行数据的前缀索引。当遇到VARCHAR类型时,前缀索引会直接截断。举例说明:
- 以下表结构的前缀索引为 user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
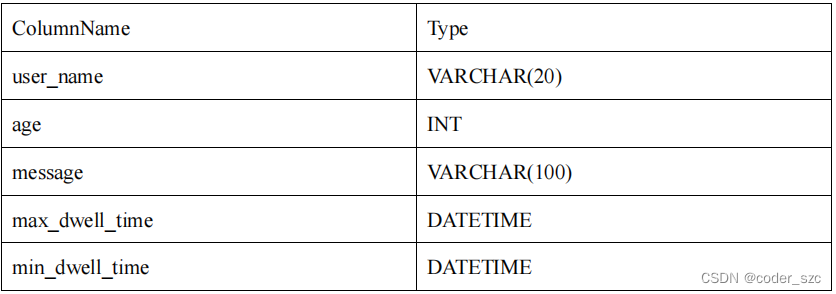
- 以下表结构的前缀索引为user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到VARCHAR,所以直接截断,不再往后继续。
- 当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;
- 1
该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;
- 1
所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
Rollup调整前缀索引
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建ROLLUP来人为的调整列顺序。
举例说明,Base表结构如下:
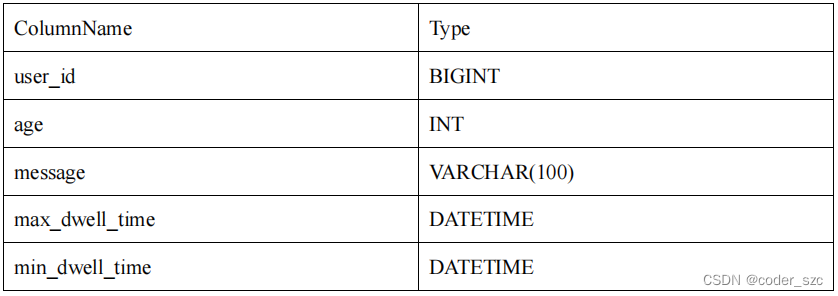
我们可以在此基础上创建一个ROLLUP表:
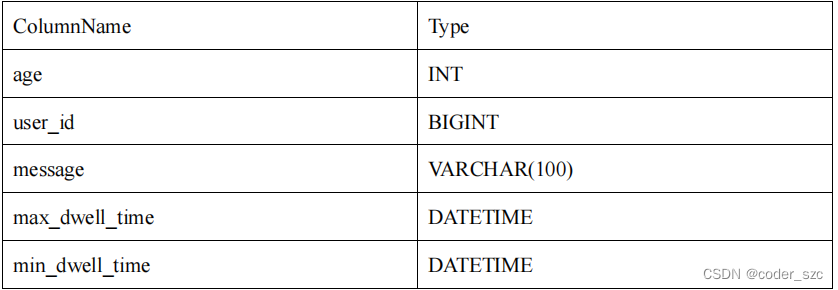
可以看到,ROLLUP和Base表的列完全一样,只是将user_id 和age的顺序调换了。那么当我们进行如下查询时:
SELECT * FROM table where age=20 and message LIKE "%error%";
- 1
会优先选择ROLLUP表,因为ROLLUP的前缀索引匹配度更高。
几点说明
- ROLLUP最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此ROLLUP的含义已经超出了“上卷”的范围。这也是为什么在源代码中,将其命名为Materialized Index(物化索引)的原因;
- ROLLUP是附属于Base表的,可以看做是Base表的一种辅助数据结构。用户可以在Base表的基础上,创建或删除ROLLUP,但是不能在查询中显式的指定查询某ROLLUP。是否命中 ROLLUP完全由Doris系统自动决定;
- ROLLUP的数据是独立物理存储的。因此,创建的ROLLUP越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有ROLLUP的数据),但是不会降低查询效率(只会更好);
- ROLLUP的数据更新与Base表是完全同步的。用户无需关心这个问题;
- ROLLUP中列的聚合方式,与Base表完全相同。在创建ROLLUP无需指定,也不能修改;
- 查询能否命中ROLLUP的一个必要条件(非充分条件)是,查询所涉及的所有列(包括select list和where中的查询条件列等)都存在于该ROLLUP的列中。否则,查询只能命中Base表;
- 某些类型的查询(如 count(*))在任何条件下,都无法命中ROLLUP。具体参见前文聚合模型的局限性一节;
- 可以通过
EXPLAIN your_sql;命令获得查询执行计划,在执行计划中,查看是否命中ROLLUP; - 可以通过
DESC tbl_name ALL;语句显示Base表和所有已创建完成的ROLLUP。
物化视图
物化视图就是包含了查询结果的数据库对象,可能是对远程数据的本地copy,也可能是一个表或多表join后结果的行或列的子集,也可能是聚合后的结果。说白了,就是预先存储查询结果的一种数据库对象。
在Doris中的物化视图,就是查询结果预先存储起来的特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
适用场景
- 分析需求覆盖明细数据查询以及固定维度查询两方面;
- 查询仅涉及表中的很小一部分列或行;
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等;
- 查询需要匹配不同前缀索引。
优势
- 对于那些经常重复的使用相同的子查询结果的查询性能大幅提升;
- Doris自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证base表和物化视图表的数据一致性。无需任何额外的人工维护成本;
- 查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。
自动维护物化视图的数据会造成一些维护开销,会在后面的物化视图的局限性中展开说明。
物化视图和Rollup
在没有物化视图功能之前,用户一般都是使用Rollup功能通过预聚合方式提升查询效率的。但是 Rollup具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了Rollup的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是Rollup的一个超集。也就是说,之前ALTER TABLE ADD ROLLUP语法支持的功能现在均可以通CREATE MATERIALIZED VIEW实现。
原理
Doris系统提供了一整套对物化视图的DDL语法,包括创建,查看,删除。DDL 的语法和PostgreSQL, Oracle都是一致的。但是Doris目前创建物化视图只能在单表操作,不支持join。
创建物化视图
首先要根据查询语句的特点来决定创建一个什么样的物化视图。并不是说物化视图定义和某个查询语句一模一样就最好。这里有两个原则:
- 从查询语句中抽象出,多个查询共有的分组和聚合方式作为物化视图的定义;
- 不需要给所有维度组合都创建物化视图。
第一点,一个物化视图如果抽象出来,并且多个查询都可以匹配到这张物化视图。这种物化视图效果最好,因为物化视图的维护本身也需要消耗资源。如果物化视图只和某个特殊的查询很贴合,而其他查询均用不到这个物化视图。则会导致这张物化视图的性价比不高,既占用了集群的存储资源,还不能为更多的查询服务。所以用户需要结合自己的查询语句,以及数据维度信息去抽象出一些物化视图的定义。
第二点,在实际的分析查询中,并不会覆盖到所有的维度分析。所以给常用的维度组合创建物化视图即可,从而到达一个空间和时间上的平衡。
通过下面命令就可以创建物化视图了。创建物化视图是一个异步的操作,也就是说用户成功提交创建任务后,Doris会在后台对存量的数据进行计算,直到创建成功。
具体的语法可以通过下面命令查看:HELP CREATE MATERIALIZED VIEW,这里以一个销售记录表为例:

比如我们有一张销售记录明细表,存储了每个交易的时间,销售员,销售门店,和金额。提交完创建物化视图的任务后,Doris就会异步在后台生成物化视图的数据,构建物化视图。在构建期间,用户依然可以正常的查询和导入新的数据。创建任务会自动处理当前的存量数据和所有新到达的增量数据,从而保持和base表的数据一致性。用户不需关心一致性问题。
查询
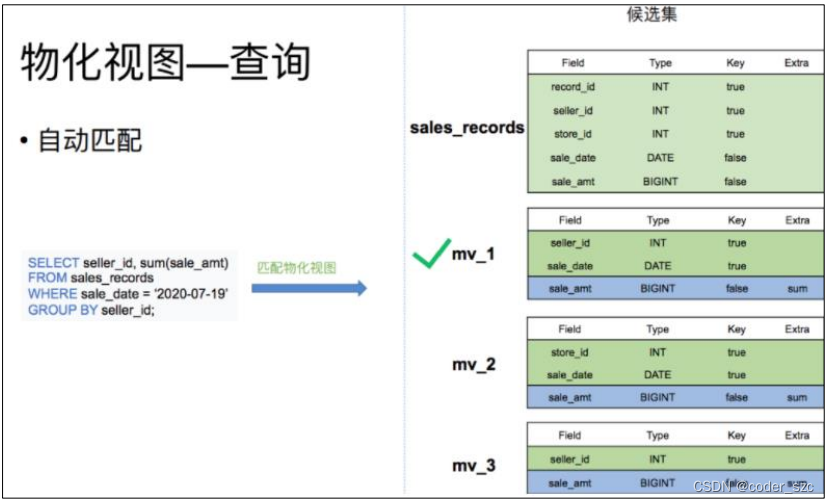
物化视图创建完成后,用户的查询会根据规则自动匹配到最优的物化视图。比如我们有一张销售记录明细表,并且在这个明细表上创建了三张物化视图。一个存储了不同时间不同销售员的售卖量,一个存储了不同时间不同门店的销售量,以及每个销售员的总销售量。当查询7月19日,各个销售员都买了多少钱时,就可以匹配mv_1物化视图,直接对mv_1 的数据进行查询。
查询自动匹配
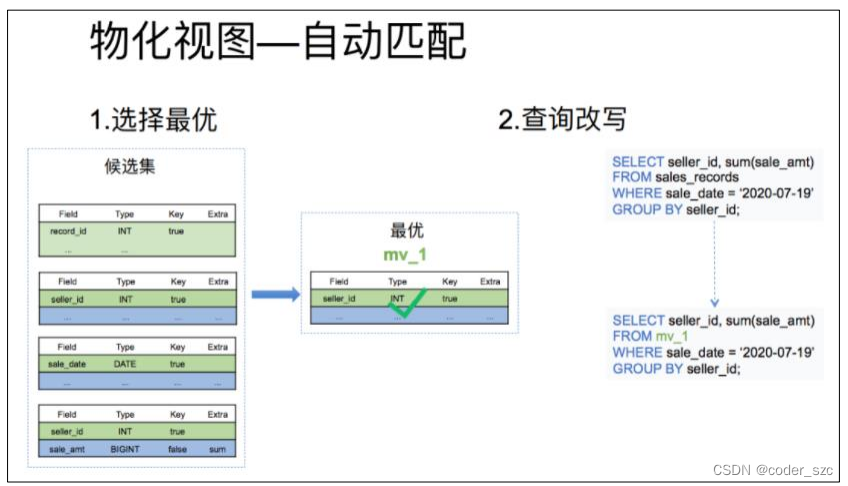
物化视图的自动匹配分为下面两个步骤:
- 根据查询条件删选出一个最优的物化视图:这一步的输入是所有候选物化视图表的元数据,根据查询的条件从候选集中输出最优的一个物化视图;
- 根据选出的物化视图对查询进行改写:这一步是结合上一步选择出的最优物化视图,进行查询的改写,最终达到直接查询物化视图的目的。
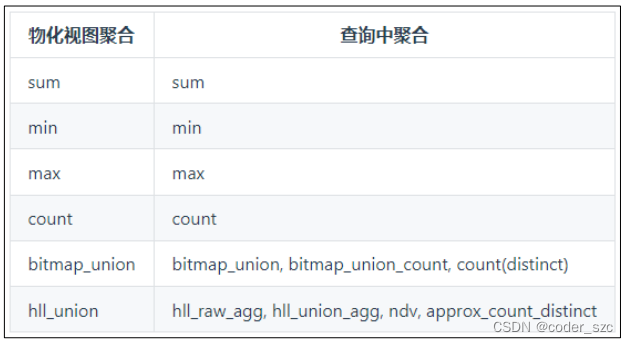
其中bitmap和hll的聚合函数在查询匹配到物化视图后,查询的聚合算子会根据物化视图的表结构进行改写,如物化视图的查询所示。
最优路径选择
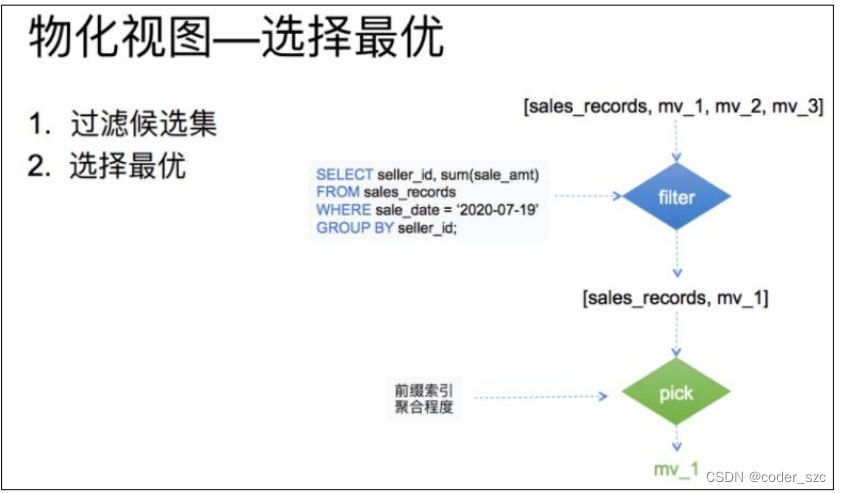
这里分为两个步骤:
- 对候选集合进行一个过滤。只要是查询的结果能从物化视图数据计算(取部分行,部分列,或部分行列的聚合)出都可以留在候选集中,过滤完成后候选集合大小>=1。
- 从候选集合中根据聚合程度,索引等条件选出一个最优的也就是查询花费最少物化视图。
这里再举一个相对复杂的例子,来体现这个过程:
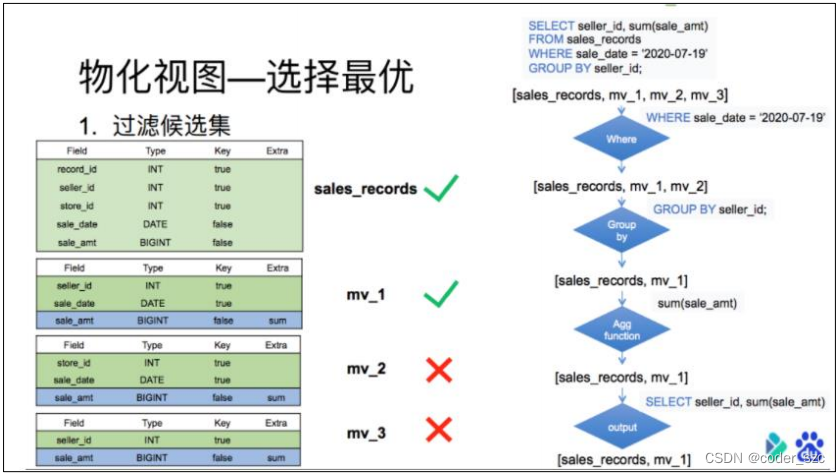
候选集过滤目前分为4层,每一层过滤后去除不满足条件的物化视图。比如查询7月19日,各个销售员都卖了多少钱,候选集中包括所有的物化视图以及base表共4个:
第一层过滤先判断查询where中的谓词涉及到的数据是否能从物化视图中得到。也就是销售时间列是否在表中存在。由于第三个物化视图中根本不存在销售时间列。所以在这一层过滤中,mv_3就被淘汰了;
第二层是过滤查询的分组列是否为候选集的分组列的子集。也就是销售员id是否为表中分组列的子集。由于第二个物化视图中的分组列并不涉及销售员id。所以在这一层过滤中,mv_2也被淘汰了;
第三层过滤是看查询的聚合列是否为候选集中聚合列的子集。也就是对销售额求和是否能从候选集的表中聚合得出。这里base表和物化视图表均满足标准;
最后一层是过滤看查询需要的列是否存在于候选集合的列中。由于候选集合中的表均满足标准,所以最终候选集合中的表为销售明细表,以及mv_1。

候选集过滤完后输出一个集合,这个集合中的所有表都能满足查询的需求。但每张表的查询效率都不同。这时候就需要再这个集合根据前缀索引是否能匹配到,以及聚合程度的高低来选出一个最优的物化视图。
从表结构中可以看出,base表的销售日期列是一个非排序列,而物化视图表的日期是一个排序列,同时聚合程度上mv_1表明显比base表高。所以最后选择出mv_1作为该查询的最优匹配。
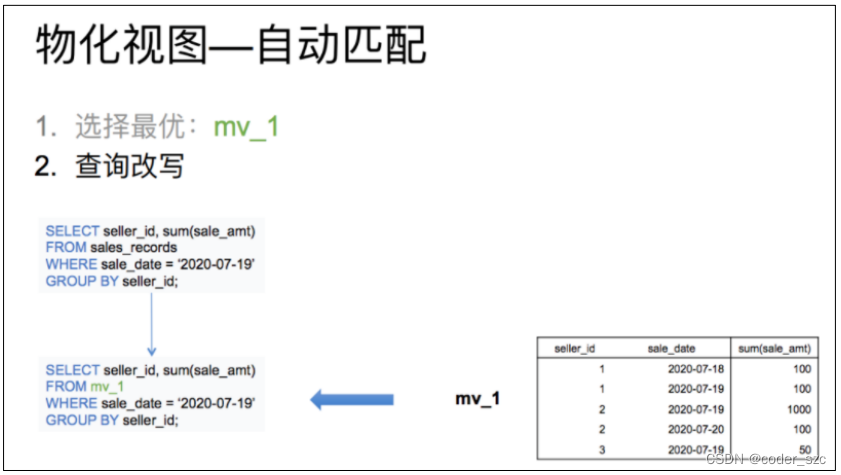
最后再根据选择出的最优解,改写查询。刚才的查询选中mv_1后,将查询改写为从mv_1中读取数据,过滤出日志为7月19日的mv_1中的数据然后返回即可。
查询改写

有些情况下的查询改写还会涉及到查询中的聚合函数的改写,比如业务方经常会用到count distinct对PV、UV进行计算。
例如:广告点击明细记录表中存放哪个用户点击了什么广告,从什么渠道点击的,以及点击的时间。并且在这个base表基础上构建了一个物化视图表,存储了不同广告不同渠道的用户bitmap 值。由于bitmap union这种聚合方式本身会对相同的用户user id进行一个去重聚合。当用户查询广告在web端的uv的时候,就可以匹配到这个物化视图。匹配到这个物化视图表后就需要对查询进行改写,将之前的对用户id求count(distinct)改为对物化视图中bitmap union列求count。所以最后查询取物化视图的第一和第三行求bitmap聚合中有几个值。
使用及限制

- 目前支持的聚合函数包括,常用的sum,min,max count,以及计算pv ,uv,留存率,等常用的去重算法hll_union,和用于精确去重计算count(distinct)的算法bitmap_union;
- 物化视图的聚合函数的参数不支持表达式仅支持单列,比如: sum(a+b)不支持;
- 使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的DML类型操作会有一些限制:如果表的物化视图key中不包含删除语句中的条件列,则删除语句不能执行。比如想要删除渠道为app端的数据,由于存在一个物化视图并不包含渠道这个字段,则这个删除不能执行,因为删除在物化视图中无法被执行。这时候你只能把物化视图先删除,然后删除完数据后,重新构建一个新的物化视图;
- 单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和base表数据是同步更新的,如果一张表的物化视图表超过10张,则有可能导致导入速度很慢。这就像单次导入需要同时导入10张表数据是一样的;
- 相同列,不同聚合函数,不能同时出现在一张物化视图中,比如:
select sum(a),min(a) from table不支持; - 物化视图针对Unique Key数据模型,只能改变列顺序,不能起到聚合的作用,所以在Unique Key模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作。
示例
示例1
创建表:
create table sales_records(
record_id int,
seller_id int,
store_id int,
sale_date date,
sale_amt bigint
)
distributed by hash(record_id)
properties("replication_num" = "1");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
插入数据:
insert into sales_records values(1,2,3,'2020-02-02',10);
- 1
创建物化视图:
create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
- 1
由于创建物化视图是一个异步的操作,用户在提交完创建物化视图任务后,需要异步地通过命令检查物化视图是否构建完成:
mysql> SHOW ALTER TABLE MATERIALIZED VIEW FROM test;
+-------+---------------------+---------------------+---------------------+---------------------+--------------------------------+----------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------------+---------------------+---------------------+---------------------+--------------------------------+----------+---------------+----------+------+----------+---------+
| 10599 | example_site_visit2 | 2022-05-14 16:25:23 | 2022-05-14 16:25:44 | example_site_visit2 | rollup_cost_userid | 10600 | 12 | FINISHED | | NULL | 86400 |
| 10621 | example_site_visit2 | 2022-05-14 16:27:54 | 2022-05-14 16:28:24 | example_site_visit2 | rollup_city_age_cost_maxd_mind | 10622 | 13 | FINISHED | | NULL | 86400 |
| 10667 | sales_records | 2022-05-14 17:56:50 | 2022-05-14 17:57:14 | sales_records | store_amt | 10668 | 15 | FINISHED | | NULL | 86400 |
+-------+---------------------+---------------------+---------------------+---------------------+--------------------------------+----------+---------------+----------+------+----------+---------+
3 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
检验当前查询是否匹配到了合适的物化视图:
mysql> EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id; +-----------------------------------------------------------------------------------+ | Explain String | +-----------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:<slot 2> `store_id` | <slot 3> sum(`sale_amt`) | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 4:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: <slot 2> `store_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 04 | | UNPARTITIONED | | | | 3:AGGREGATE (merge finalize) | | | output: sum(<slot 3> sum(`sale_amt`)) | | | group by: <slot 2> `store_id` | | | cardinality=-1 | | | | | 2:EXCHANGE | | | | PLAN FRAGMENT 2 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`sales_records`.`record_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | HASH_PARTITIONED: <slot 2> `store_id` | | | | 1:AGGREGATE (update serialize) | | | STREAMING | | | output: sum(`sale_amt`) | | | group by: `store_id` | | | cardinality=-1 | | | | | 0:OlapScanNode | | TABLE: sales_records | | PREAGGREGATION: ON | | partitions=1/1 | | rollup: store_amt | | tabletRatio=10/10 | | tabletList=10669,10671,10673,10675,10677,10679,10681,10683,10685,10687 | | cardinality=0 | | avgRowSize=12.0 | | numNodes=1 | +-----------------------------------------------------------------------------------+ 47 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
删除物化视图:
DROP MATERIALIZED VIEW 物化视图名 on Base表名;
- 1
案例2:计算pv和uv
假设用户的原始广告点击数据存储在Doris,那么针对广告PV, UV查询就可以通过创建bitmap_union的物化视图来提升查询速度。
创建表:
create table advertiser_view_record(
time date,
advertiser varchar(10),
channel varchar(10),
user_id int
)
distributed by hash(time)
properties("replication_num" = "1");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
插入数据:
insert into advertiser_view_record values('2020-02-02','a','app',123);
- 1
创建物化视图:
create materialized view advertiser_uv as
select advertiser, channel, bitmap_union(to_bitmap(user_id))
from advertiser_view_record
group by advertiser, channel;
- 1
- 2
- 3
- 4
在Doris中,count(distinct)聚合的结果和bitmap_union_count聚合的结果是完全一致的。而bitmap_union_count等于bitmap_union的结果求count,所以如果查询中涉及到count(distinct)则通过创建带bitmap_union聚合的物化视图方可加快查询。
因为本身user_id是INT类型,所以在Doris中需要先将字段通过函数to_bitmap转换为bitmap类型然后才可以进行bitmap_union聚合。
检验是否匹配到物化视图:
mysql> explain SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel; +-------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Explain String | +-------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:<slot 7> `advertiser` | <slot 8> `channel` | <slot 9> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`) | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 4:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: <slot 4> `advertiser`, <slot 5> `channel` | | | | STREAM DATA SINK | | EXCHANGE ID: 04 | | UNPARTITIONED | | | | 3:AGGREGATE (merge finalize) | | | output: bitmap_union_count(<slot 6> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`)) | | | group by: <slot 4> `advertiser`, <slot 5> `channel` | | | cardinality=-1 | | | | | 2:EXCHANGE | | | | PLAN FRAGMENT 2 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`advertiser_view_record`.`time` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | HASH_PARTITIONED: <slot 4> `advertiser`, <slot 5> `channel` | | | | 1:AGGREGATE (update serialize) | | | STREAMING | | | output: bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`) | | | group by: `advertiser`, `channel` | | | cardinality=-1 | | | | | 0:OlapScanNode | | TABLE: advertiser_view_record | | PREAGGREGATION: ON | | partitions=1/1 | | rollup: advertiser_uv | | tabletRatio=10/10 | | tabletList=10715,10717,10719,10721,10723,10725,10727,10729,10731,10733 | | cardinality=0 | | avgRowSize=48.0 | | numNodes=1 | +-------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 47 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
在 EXPLAIN 的结果中,首先可以看到OlapScanNode的rollup属性值为advertiser_uv。也就是说,查询会直接扫描物化视图的数据,说明匹配成功。其次对于user_id字段求count(distinct)被改写为求bitmap_union_count(to_bitmap),也就是通过bitmap的方式来达到精确去重的效果。
案例3
用户的原始表有(k1, k2, k3)三列。其中k1, k2为前缀索引列。这时候如果用户查询条件中包含 where k1=1 and k2=2就能通过索引加速查询。但是有些情况下,用户的过滤条件无法匹配到前缀索引,比如where k3=3,则无法通过索引提升查询速度,而创建以k3作为第一列的物化视图就可以解决这个问题。
查询:
mysql> explain select record_id,seller_id,store_id from sales_records where store_id=3; +-----------------------------------------------------------------------------------+ | Explain String | +-----------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:`record_id` | `seller_id` | `store_id` | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 1:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`sales_records`.`record_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 01 | | UNPARTITIONED | | | | 0:OlapScanNode | | TABLE: sales_records | | PREAGGREGATION: ON | | PREDICATES: `store_id` = 3 | | partitions=1/1 | | rollup: sales_records | | tabletRatio=10/10 | | tabletList=10646,10648,10650,10652,10654,10656,10658,10660,10662,10664 | | cardinality=1 | | avgRowSize=923.0 | | numNodes=1 | +-----------------------------------------------------------------------------------+ 27 rows in set (0.01 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
创建物化视图:
create materialized view mv_1 as
select
store_id,
record_id,
seller_id,
sale_date,
sale_amt
from sales_records;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
通过上面语法创建完成后,物化视图中既保留了完整的明细数据,且物化视图的前缀索引为 store_id列。
查看表结构:
mysql> desc sales_records all; +---------------+---------------+-----------+--------+------+-------+---------+-------+---------+ | IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible | +---------------+---------------+-----------+--------+------+-------+---------+-------+---------+ | sales_records | DUP_KEYS | record_id | INT | Yes | true | NULL | | true | | | | seller_id | INT | Yes | true | NULL | | true | | | | store_id | INT | Yes | true | NULL | | true | | | | sale_date | DATE | Yes | false | NULL | NONE | true | | | | sale_amt | BIGINT | Yes | false | NULL | NONE | true | | | | | | | | | | | | mv_1 | DUP_KEYS | store_id | INT | Yes | true | NULL | | true | | | | record_id | INT | Yes | true | NULL | | true | | | | seller_id | INT | Yes | true | NULL | | true | | | | sale_date | DATE | Yes | false | NULL | NONE | true | | | | sale_amt | BIGINT | Yes | false | NULL | NONE | true | | | | | | | | | | | | store_amt | AGG_KEYS | store_id | INT | Yes | true | NULL | | true | | | | sale_amt | BIGINT | Yes | false | NULL | SUM | true | +---------------+---------------+-----------+--------+------+-------+---------+-------+---------+ 14 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
查询匹配:
mysql> explain select record_id,seller_id,store_id from sales_records where store_id=3; +-----------------------------------------------------------------------------------+ | Explain String | +-----------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS:`record_id` | `seller_id` | `store_id` | | PARTITION: UNPARTITIONED | | | | RESULT SINK | | | | 1:EXCHANGE | | | | PLAN FRAGMENT 1 | | OUTPUT EXPRS: | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`sales_records`.`record_id` | | | | STREAM DATA SINK | | EXCHANGE ID: 01 | | UNPARTITIONED | | | | 0:OlapScanNode | | TABLE: sales_records | | PREAGGREGATION: ON | | PREDICATES: `store_id` = 3 | | partitions=1/1 | | rollup: mv_1 | | tabletRatio=10/10 | | tabletList=10737,10739,10741,10743,10745,10747,10749,10751,10753,10755 | | cardinality=0 | | avgRowSize=12.0 | | numNodes=1 | +-----------------------------------------------------------------------------------+ 27 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这时候查询就会直接从刚才创建的mv_1物化视图中读取数据。由于物化视图对store_id是存在前缀索引的,查询效率也会提升。
修改表
使用ALTER TABLE命令可以对表进行修改,包括partition 、rollup、schema change、rename和index五种。语法:
ALTER TABLE [database.]table
alter_clause1[, alter_clause2, ...];
alter_clause 分为 partition 、rollup、schema change、rename 和 index 五种。
- 1
- 2
- 3
rename
将名为 table1的表修改为table2:
ALTER TABLE table1 RENAME table2;
- 1
将表example_table中名为rollup1的rollup index修改为rollup2:
ALTER TABLE example_table RENAME ROLLUP rollup1 rollup2;
- 1
将表example_table中名为p1的partition修改为p2:
ALTER TABLE example_table RENAME PARTITION p1 p2;
- 1
partition
增加分区, 使用默认分桶方式,如现有分区[MIN, 2013-01-01),增加分区[2013-01-01, 2014-01-01):
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2014-01-01");
- 1
增加分区,使用新的分桶数:
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2015-01-01") DISTRIBUTED BY HASH(k1) BUCKETS 20;
- 1
增加分区,使用新的副本数:
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2015-01-01") ("replication_num"="1");
- 1
修改分区副本数:
ALTER TABLE example_db.my_table MODIFY PARTITION p1 SET("replication_num"="1");
- 1
批量修改指定分区:
ALTER TABLE example_db.my_table MODIFY PARTITION (p1, p2, p4) SET("in_memory"="true");
- 1
批量修改所有分区:
ALTER TABLE example_db.my_table MODIFY PARTITION (*) SET("storage_medium"="HDD");
- 1
删除分区:
ALTER TABLE example_db.my_table DROP PARTITION p1;
- 1
增加一个指定上下界的分区:
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES [("2014-01-01"), ("2014-02-01"));
- 1
rollup
创建index: example_rollup_index,基于base index(k1,k2,k3,v1,v2),列式存储:
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index(k1, k3, v1, v2);
- 1
- 2
创建index: example_rollup_index2,基于example_rollup_index(k1,k3,v1,v2):
ALTER TABLE example_db.my_table ADD ROLLUP example_rollup_index2 (k1, v1) FROM example_rollup_index;
- 1
创建index: example_rollup_index3, 基于base index (k1,k2,k3,v1), 自定义rollup超时时间一小时:
ALTER TABLE example_db.my_table ADD ROLLUP example_rollup_index(k1, k3, v1) PROPERTIES("timeout" = "3600");
- 1
删除index: example_rollup_index2:
ALTER TABLE example_db.my_table DROP ROLLUP example_rollup_index2;
- 1
表结构变更
使用ALTER TABLE命令可以修改表的Schema,包括:增加列、删除列、修改列类型、改变列顺序。以增加列为例:
我们新增一列uv,类型为BIGINT,聚合类型为SUM,默认值为0:
ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT '0' after pv;
- 1
提交成功后,可以通过以下命令查看作业进度:
SHOW ALTER TABLE COLUMN;
- 1
当作业状态为FINISHED,则表示作业完成,新的Schema已生效。
查看新的Schema:
DESC table1;
- 1
可以使用以下命令取消当前正在执行的作业:
CANCEL ALTER TABLE ROLLUP FROM table1;
- 1
更多可以参阅:HELP ALTER TABLE。
删除数据
Doris目前可以通过两种方式删除数据:DELETE FROM语句和ALTER TABLE DROP PARTITION 语句。
条件删除(drop from)
delete from语句类似标准delete语法,具体使用可以查看help delete;帮助。
语法:
DELETE FROM table_name [PARTITION partition_name]
WHERE
column_name1 op { value | value_list } [ AND column_name2 op { value
| value_list } ...];
- 1
- 2
- 3
- 4
如:
delete from student_kafka where id=1;
- 1
注意事项:
- 该语句只能针对Partition级别进行删除。如果一个表有多个partition含有需要删除的数据,则需要执行多次针对不同Partition的delete 语句。而如果是没有使用Partition的表,partition的名称即表名;
- where后面的条件谓词只能针对Key列,并且谓词之间,只能通过AND连接。如果想实现OR的语义,需要执行多条delete;
- delete是一个同步命令,命令返回即表示执行成功;
- 从代码实现角度,delete是一种特殊的导入操作。该命令所导入的内容,也是一个新的数据版本,只是该版本中只包含命令中指定的删除条件。在实际执行查询时,会根据这些条件进行查询时过滤。所以,不建议大量频繁使用delete命令,因为这可能导致查询效率降低;
- 数据的真正删除是在BE进行数据Compaction时进行的。所以执行完delete命令后,并不会立即释放磁盘空间;
- delete命令一个较强的限制条件是,在执行该命令时,对应的表,不能有正在进行的导入任务(包括PENDING、ETL、LOADING)。而如果有QUORUM_FINISHED状态的导入任务,则可能可以执行;
- delete也有一个隐含的类似QUORUM_FINISHED的状态。即如果 delete只在多数副本上完成了,也会返回用户成功。但是会在后台生成一个异步的delete job(Async Delete Job),来继续完成对剩余副本的删除操作。如果此时通过show delete命令,可以看到这种任务在state一栏会显示QUORUM_FINISHED。
分区删除(drop partition)
该命令可以直接删除指定的分区。因为Partition是逻辑上最小的数据管理单元,所以使用DROP PARTITION命令可以很轻量地完成数据删除工作,并且不受load以及任何其他操作的限制,同时不会影响查询效率,是比较推荐的一种数据删除方式。该命令是同步命令,执行成功即生效。而后台数据真正删除的时间可能会延迟10分钟左右。

