
- 1java汉服服装租赁系统计算机毕业设计MyBatis+系统+LW文档+源码+调试部署
- 2鸿蒙 HarmonyOS应用开发之API:Context_鸿蒙os getcontext_鸿蒙 getcontext(this).reso
- 3[python]python下载文件几种方法_python download file
- 4IDEA 使用_add file to git
- 5探索Yoga:一款强大的跨平台UI框架
- 6夜天之书 #99 改良 SQL Interval 语法:一次开源贡献的经历
- 7CVE-2020-16898: Windows TCP/IP远程执行代码漏洞通告_cve-2021-16878
- 8SwiftData 简介:SwiftUI 中数据持久化的未来
- 9XML外部实体注入(XXE)_外部实体注入的危害和处置
- 10深耕版本控制、代码质量与安全等领域,龙智荣获“Perforce 2023年度合作伙伴”奖项
【论文阅读】LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
赞
踩
代码:KwaiVGI/LivePortrait: Make one portrait alive! (github.com)
介绍
动机:基于扩散的方法计算成本高,并且缺乏精确的可控制性。因此作者探索并扩展了基于隐式关键点的视频驱动框架,平衡了泛化性、计算效率和可控性。
训练数据为6900万高质量帧,采用混合图像-视频训练策略,升级网络架构,并设计了更好的运动变换和优化目标。此外,我们发现紧凑的隐式关键点可以有效地表示一种混合形状,并提出了拼接和两个重定向模块,这些模块利用一个具有可忽略计算开销的小型MLP,以增强可控性。
图1,定性肖像动画结果。给定静态肖像图像作为输入,模型可以生动地使其动画化,确保无缝拼接并提供对眼睛和嘴唇运动的精确控制。

原理

作者选择face vid2vid作为基本模型。改进包括:高质量的数据管理、混合图像和视频训练策略、升级的网络架构、可扩展的运动转换、地标引导的隐式关键点优化和级联损失项。这些改进大大提高了动画的表现力和模型的泛化能力。
第一阶段:基础模型训练
第一个训练阶段的pipeline如图2所示,基础模型训练,优化了外观和运动提取器F和M、翘曲模块W和解码器G。
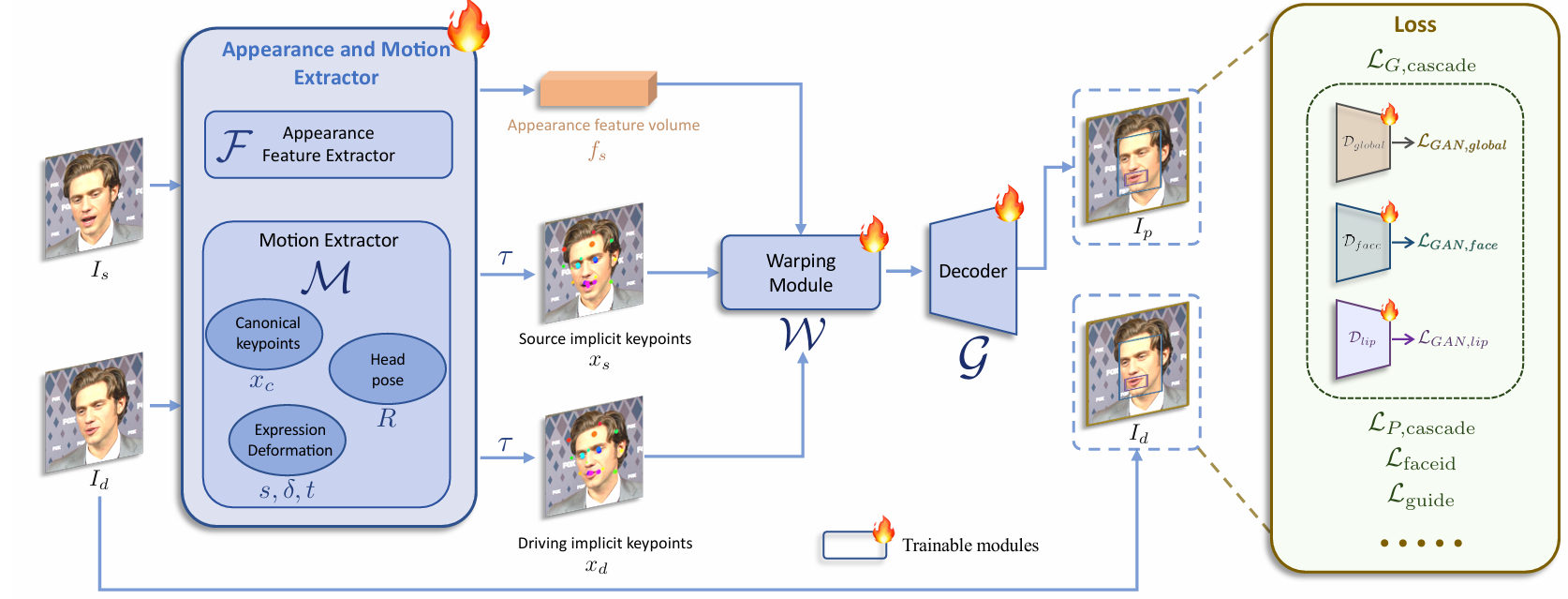
混合图像和视频训练。仅在逼真人像视频上训练的模型在人像方面表现良好,但在风格化人像(如动漫)上的泛化能力较差。风格化人像视频稀缺,我们仅收集了大约1300个来自不到100个身份的视频剪辑。相比之下,高质量的风格化人像图像更为丰富;我们收集了大约6万张图像,每张图像代表一个独特的身份,提供了多样的身份信息。为了利用这两种数据类型,我们将单一图像视为一帧视频剪辑,并在图像和视频上训练模型。这种混合训练提高了模型的泛化能力。
升级的网络架构。将原始的规范隐式关键点检测器L、头部姿态估计网络H和表情变形估计网络∆统一为一个单一的模型M,使用ConvNeXt-V2-Tiny作为骨干网络,直接预测输入图像的规范关键点、头部姿态和表情变形。此外,我们按照[43]使用SPADE解码器作为生成器G,这比face vid2vid中的原始解码器更强大。扭曲特征体积 声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

