
- 1数据实时传输平台(CDC)与低代码平台(APAAS)数据集成_cdc平台
- 2ZYNQ petalinux系统使用axi_bram进行PL与PS数据交互_ps和pl通过bram批量数据读写
- 3课工场题库自动化脚本原理分析及实现(文章末尾附免费可用版本)_免费脚本题库配置链接
- 4IOS - swift SDK开发_制作 swift sdk
- 5AI产品经理入门全指南资料库_ai产品经理知识库
- 6Phoenix启动过程出现的问题_phoenix启动后没有master
- 7将句子表示为向量:无监督句子表示学习(sentence embedding)
- 8Fine-tuning: 深度解析P-tuning v2在大模型上的应用_ptuning v2原理
- 9Git笔记-Connection reset by 13.229.188.59 port 22 fatal: Could not read from remote repository._connection reset by 180.76.198.77 port 22 fatal: c
- 1010张图看AI趋势:到2025年全球AI企业营收增幅53%_ai产业对gdp的贡献率 图表
GAN(三)变种介绍_gan网络变种
赞
踩
GAN(一)先验知识
GAN(二)损失函数推导
目录
基础GAN
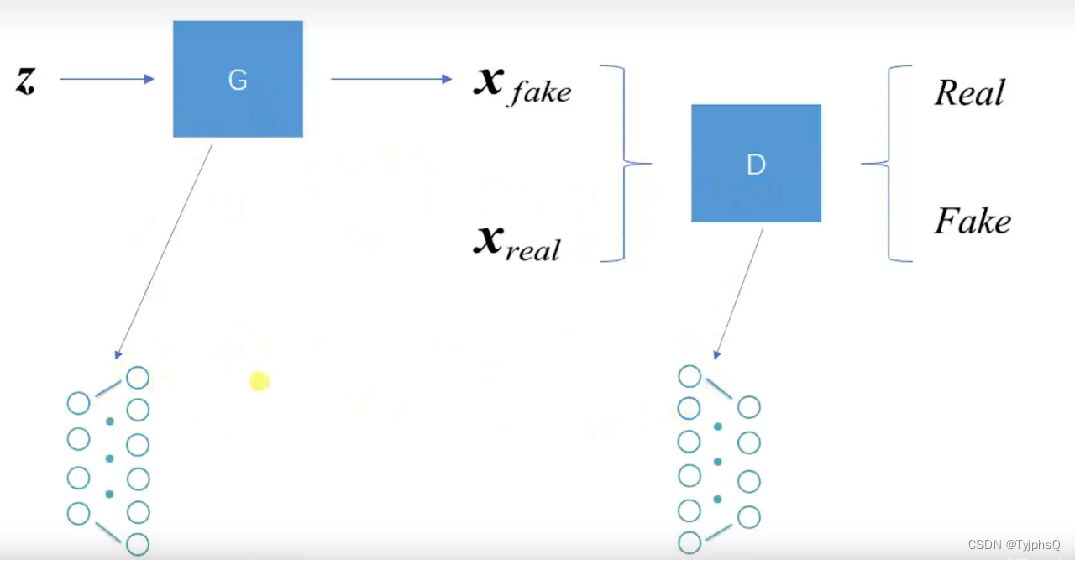
其中G,D 是多层感知机,也就是我们第一部分先验知识所介绍的内容
DCGAN
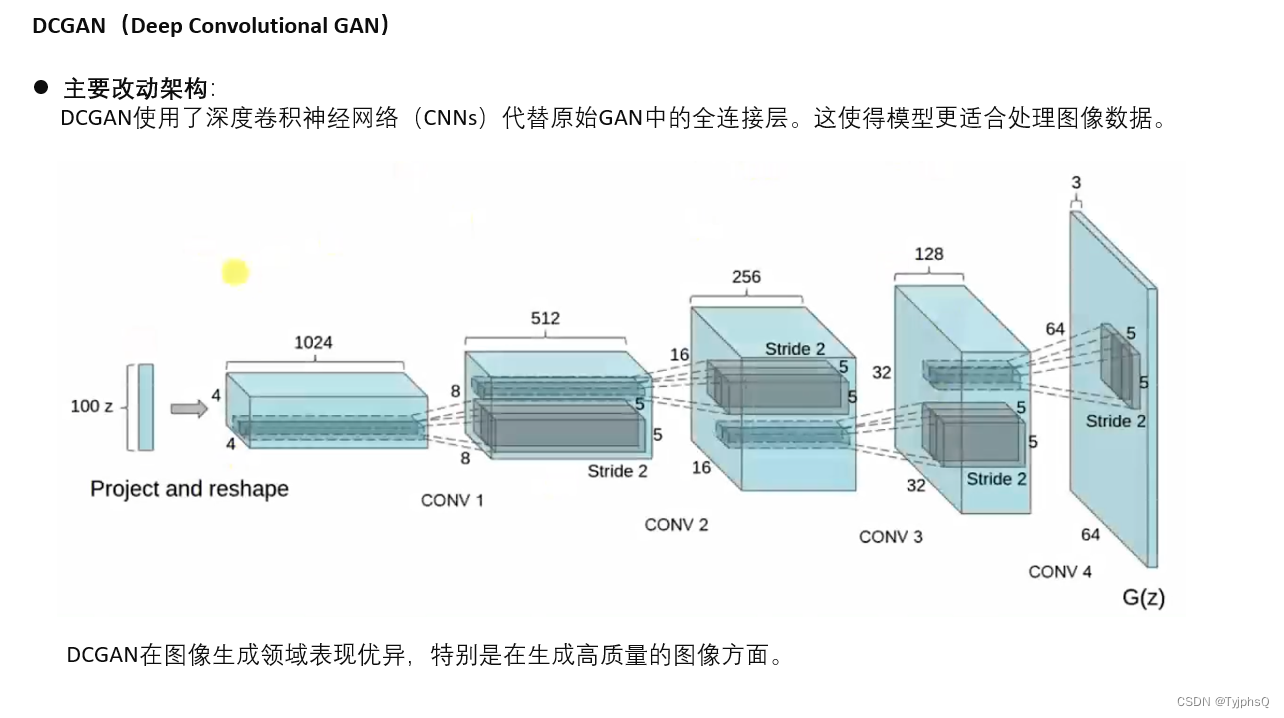
通过使用批标准化(Batch Normalization)和Leaky ReLU激活函数,DCGAN改进了训练的稳定性和收敛速度。
CGAN
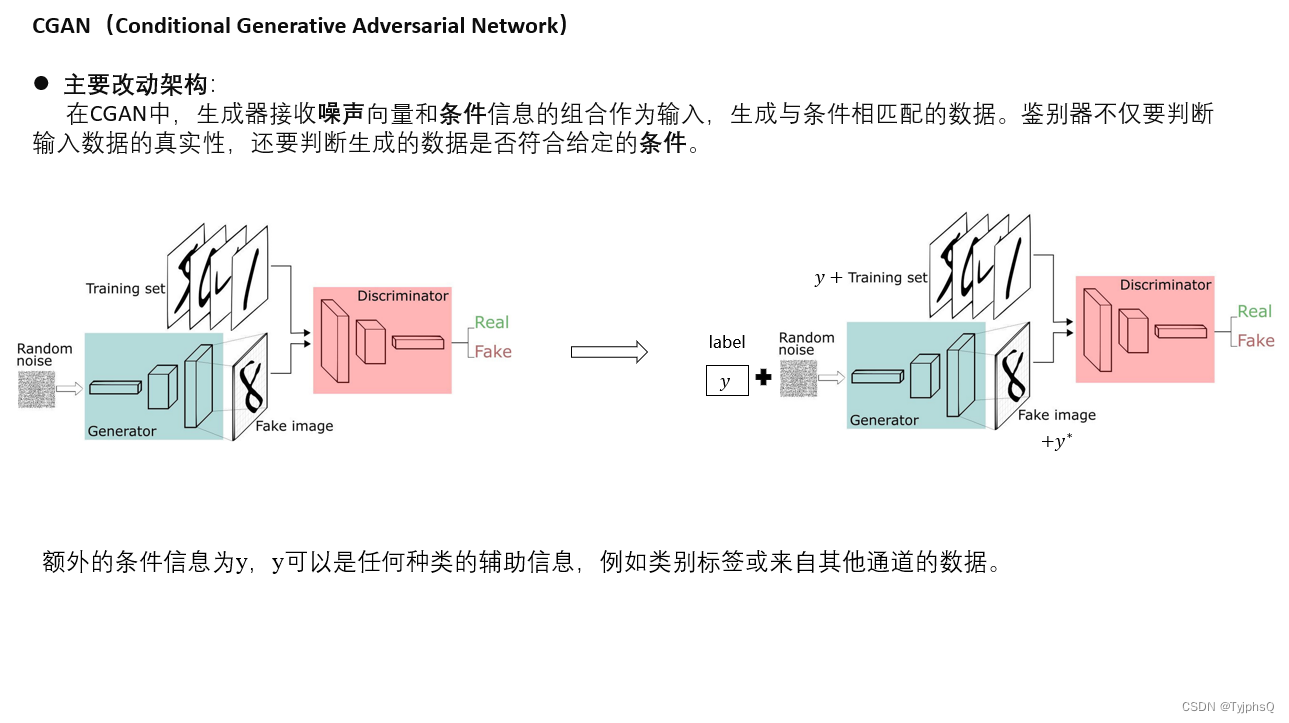 在CGAN中,生成器,判别器,损失函数都进行的小幅度的改动,
在CGAN中,生成器,判别器,损失函数都进行的小幅度的改动,
- 生成器 G:它学习映射函数 G(z,c),其中 z 是从潜在空间的先验分布中抽取的噪声向量,c 是条件信息。生成器的目标是生成既真实又符合条件 c 的数据。
- 鉴别器 D:它输出数据 x 和条件 c 的组合是真实数据的概率。鉴别器试图区分真实的数据对 (x,c) 和由生成器生成的数据对 (G(z,c),c)。
- 损失函数:CGAN的训练过程涉及最小化以下的对抗损失函数,其中生成器和鉴别器按条件 c 进行优化:
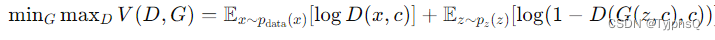
Pix2Pix
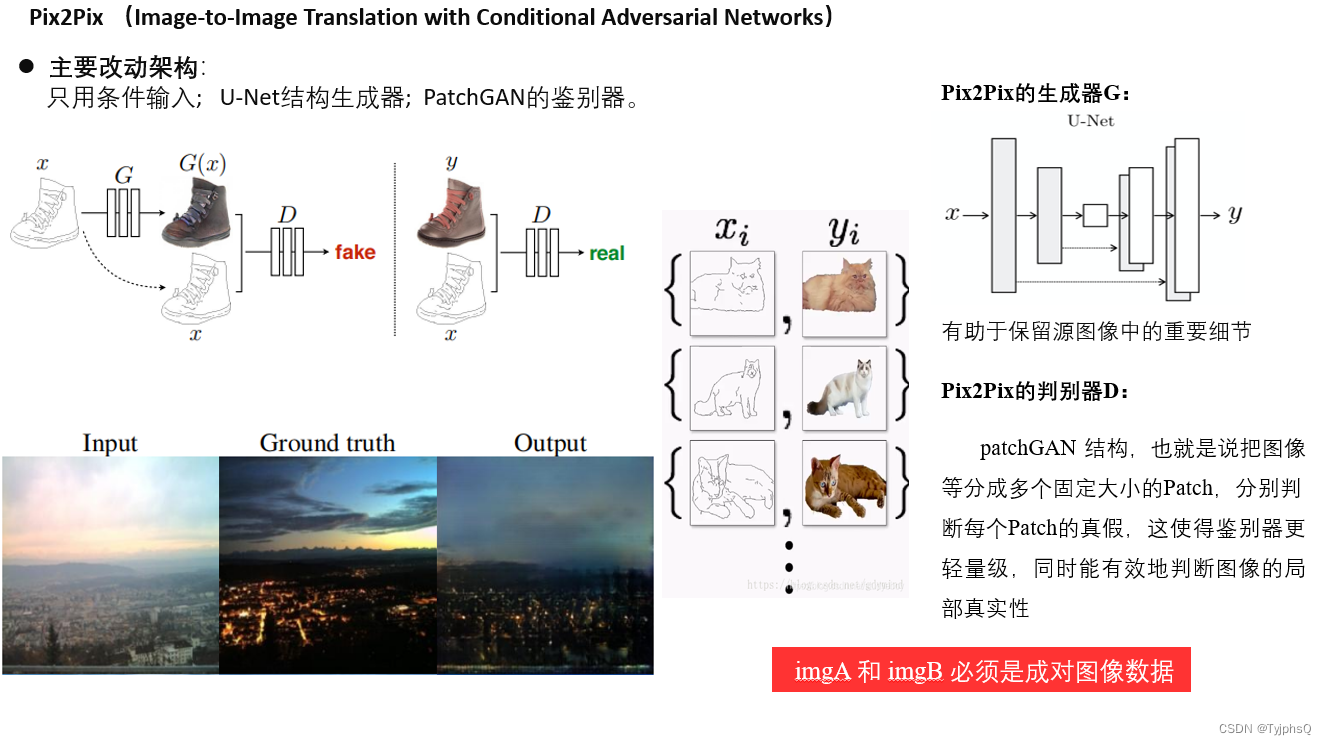
工作流程
以基于图像边缘生成图像为例,介绍Pix2Pix的工作流程:
首先输入图像用y表示,输入图像的边缘图像用x表示,Pix2Pix在训练时需要成对的图像(x和y)。
x作为生成器G的输入(随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起最为G的输入,可以得到更多样的输出)得到生成图像G(x)。
然后将G(x)和x基于通道维度合并在一起,最后作为判别器D的输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。
真实图像y和x也基于通道维度合并在一起,作为判别器D的输入得到概率预测值。因此判别器D的训练目标就是在输入不是一对真实图像(x和G(x))时输出小的概率值(比如最小是0),在输入是一对真实图像(x和y)时输出大的概率值(比如最大值是1)。
生成器G的训练目标就是使得生成的G(x)和x作为判别器D的输入时,判别器D输出的概率值尽可能大,这样就相当于成功欺骗了判别器D。
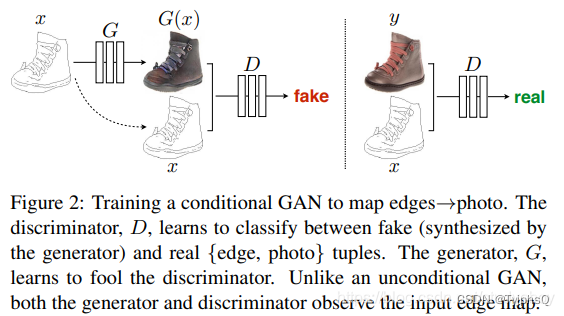
结构改动
相较于前几个GAN, Pix2Pix 的输入通常为图片,而不再是噪音或条件,它专为图像到图像的转换任务设计,如将草图转换为照片、黑白图像上色、街景转换为地图等。
- 生成器 G:生成器在Pix2Pix中通常是一个U-Net结构,该结构通过使用跳过连接(skip connections)来合并编码器和解码器的特征,这有助于保留源图像中的重要细节。
- 鉴别器 D:Pix2Pix使用了一种称为PatchGAN的鉴别器,这种鉴别器评估图像中的局部区域(或“补丁”)而不是整个图像。这使得鉴别器能够专注于图像的细节特征,从而判断这些局部区域是否真实。
- 损失函数:除了传统的GAN损失,Pix2Pix还添加了L1损失,L1损失用于量化生成图像与真实图像之间的平均绝对误差,这有助于确保生成的图像不仅能欺骗鉴别器,而且在内容上与目标图像保持一致。
由于是条件GAN,Pix2Pix需要成对的图像数据进行训练(即输入图像和目标图像的对)
CycleGAN
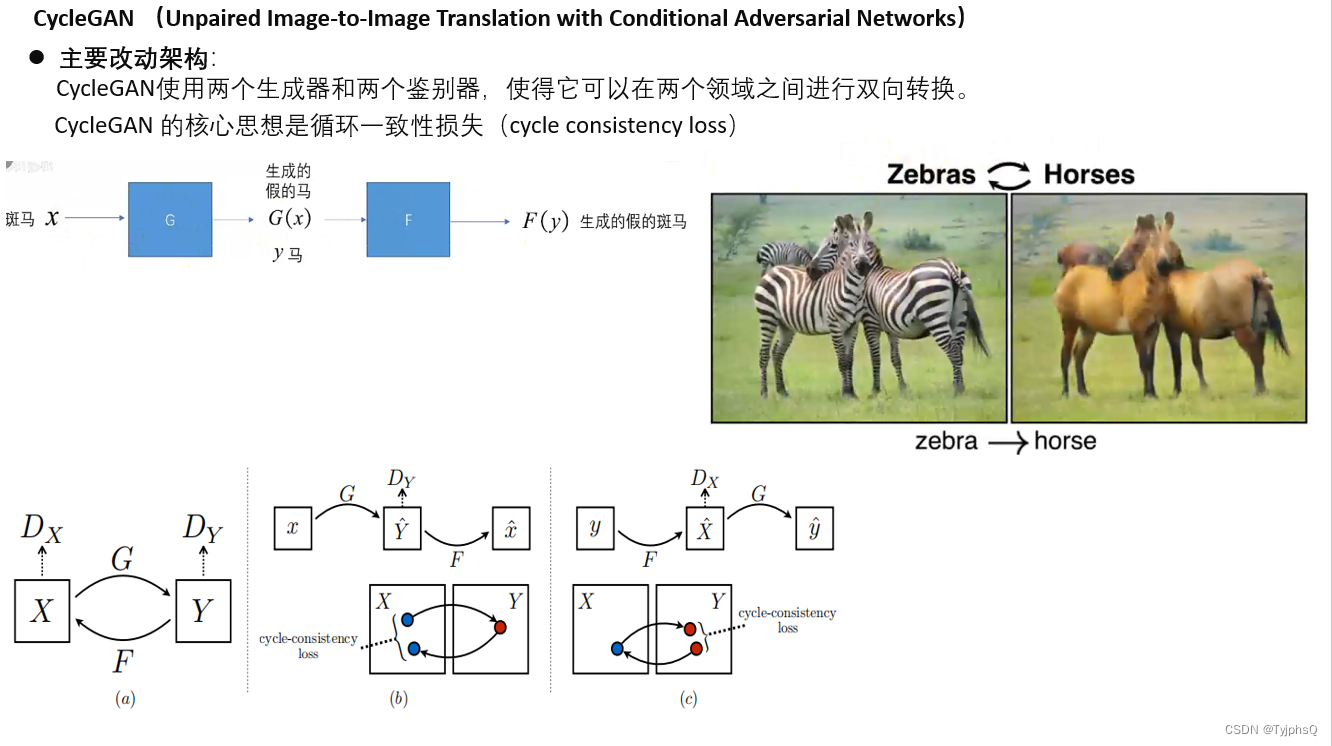
CycleGAN用于未配对图像之间的风格转换,其特点是使用两个生成器和两个判别器进行循环一致性训练。
CycleGAN中的每个判别器通常只接收一张图片作为输入。这些判别器独立地评估各自域(domain)中的图片是否真实。例如,如果一个CycleGAN被训练来将马转换成斑马,那么一个判别器将只处理马的图片,另一个只处理斑马的图片。
工作流程
使用生成器 G 将域 X 中的图像 x 转换为看起来像域 Y 中图像的 y^ = G(x)。
使用生成器 F 将域 Y 中的图像 y 转换为看起来像域 X 中图像的 x^ = F(y)。
判别器 DY 学习区分域 Y 中的真实图像 y 和生成的图像 y^。
判别器 DX 学习区分域 X 中的真实图像 x 和生成的图像 x^。
对于通过 G 生成的图像y^,使用 F 再将 y^ 转换回域 X 的 x~=F(y^)。理论上,x~ 应接近原始图像 x。
对于通过 F 生成的图像 x^,使用 G 再将 x^ 转换回域 Y 的 y~=G(x^)。理论上,y~ 应接近原始图像 y。
结构改动
CycleGAN包括两个生成器,分别记为 G 和 F:
- 生成器 G:负责将图像从域 X 转换到域 Y。例如,将马的图片转换成斑马的图片。
- 生成器 F:负责将图像从域 Y 转换回域 X。例如,将斑马的图片转换回马的图片。
与两个生成器相对应,CycleGAN还包括两个判别器,分别记为 DX 和 DY:
- 判别器 DX:负责判断图像是否属于域 X。它的任务是区分域 X 中的真实图像和由生成器 F 生成的图像。
- 判别器 DY:负责判断图像是否属于域 Y。它的任务是区分域 Y 中的真实图像和由生成器 G 生成的图像。
CycleGAN 的核心思想是循环一致性(cycle consistency),这意味着如果一个图像从域 X 转换到域 Y,然后再从域 Y 转换回域 X,最终得到的图像应该与原始图像尽可能相似。这一点通过循环一致性损失来实现:
- 正向循环一致性:F(G(x))≈x。
- 反向循环一致性:G(F(y))≈y。
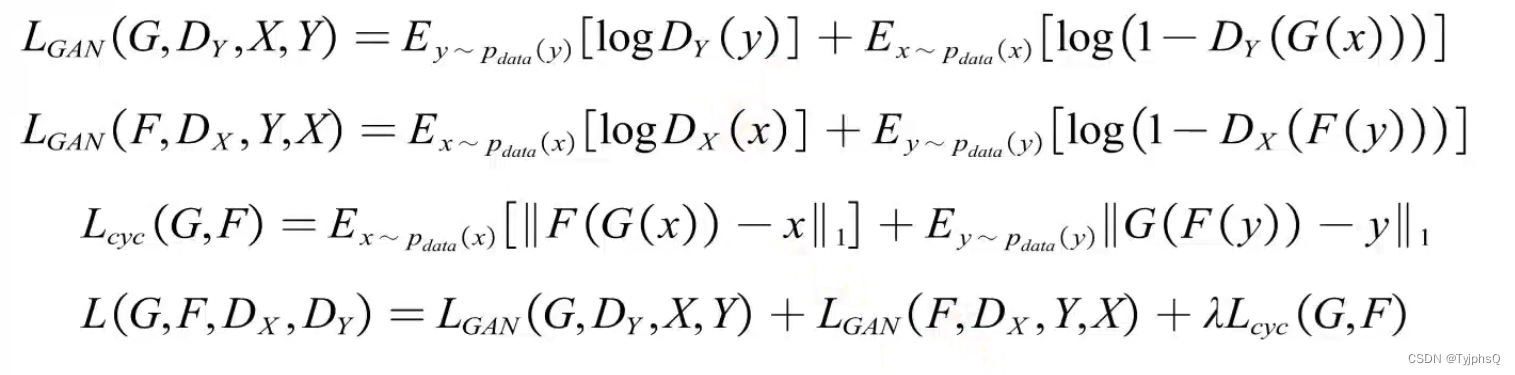
损失函数
![]()
GAN网络生成文本和数据文件
以下是几种可以生成文本或数据文件的GAN变体:
-
TextGAN:
- TextGAN是用于生成自然语言文本的GAN模型。它通过调整生成器和判别器的结构,能够生成语法上正确且逻辑上连贯的文本。
-
SeqGAN:
- SeqGAN将序列生成问题建模为强化学习问题。生成器生成文本序列,并通过判别器评估来优化,使得生成的文本在语义和结构上与真实文本相似。
-
RankGAN:
- 如前所述,RankGAN通过引入基于排序的判别器来生成文本,使生成的文本在质量和一致性上更接近人类写作。
-
LeakGAN:
- LeakGAN通过在生成过程中向生成器“泄漏”判别器的信息,以生成更高质量的文本。这种信息泄漏帮助生成器更好地理解判别器的决策过程,从而优化生成的文本。
AIGC主要使用的技术
AIGC(AI生成内容)通常涉及使用多种机器学习和深度学习技术来自动化内容的创作过程。以下是AIGC中常用的几种技术:
-
自然语言处理(NLP):
- 用于文本生成、语言翻译、内容摘要等。技术如变换器(Transformers)、BERT、GPT系列等广泛应用于这些任务。
-
生成对抗网络(GANs):
- 在图像生成、艺术创作以及视频内容生成中非常有效。GANs 能生成逼真的图像和视频,也用于音乐生成和三维模型生成。
-
变分自编码器(VAEs):
- 用于生成新的数据实例,如图像和音乐。VAEs通过学习数据的潜在特征空间来生成新的数据点。
-
强化学习:
- 在内容生成中,尤其是游戏设计和交互式内容生成中,强化学习被用来优化生成内容的决策过程。
-
Transformer模型:
- 由于其强大的序列到序列建模能力,Transformer和基于它的模型(如GPT-3、BERT等)被广泛应用于生成高质量的文本内容。
参考链接:CycleGAN的基本原理以及Pytorch框架实现-CSDN博客
https://www.cnblogs.com/qiynet/p/12304004.html
GAN原理-听不懂不要钱,哦对,本来我也不要钱_哔哩哔哩_bilibili
GAN原论文网盘:https://pan.baidu.com/s/1xsSk3KSSkqx5xwnVRq6JnA
提取码:78w7
GAN汇报PPT:https://pan.baidu.com/s/1PUFK8pKVjTzhneA6Ugq2jQ
提取码:a7ob

