
- 1【Git系列】rebase的使用场景_git rebase 使用
- 2四种优秀的数据库设计工具_table设计工具在哪里
- 3已解决,Python 报错ModuleNotFoundError : No module named ‘_tkinter’的正确解决方法,亲测有效,嘿嘿嘿_no module named 'tkinter
- 4倒计时2天!AI Developers我们WAVE SUMMIT+2022见!
- 5Android Studio实现连连看小游戏,比比看谁过关最快~_android studio小游戏
- 6【Unity3D开发小游戏】《植物大战僵尸游戏》Unity开发教程_unity植物大战僵尸
- 7OpenHarmony实战开发-减少卡顿丢帧、合理使用renderGroup_openharmony打印缓存使用情况
- 8浅析Linux进程地址空间_将一段完整的程序按地址划分成不同的区域进行开发,
- 9PL/SQL如何设置主键自动递增_plsql设置主键自增
- 10机器学习10大网站_机器学习网站
Mysql数据结构
赞
踩
大家都知道mysql的数据结构是用b+tree来实现的。为什么不用其他数据结构呢?比如说hash、二叉树、红黑树、b-tree。要了解mysql底层的数据结构实现,需要先了解一下各个数据结构的特点以及存储方式:
Hash
哈希表是键值对的集合,通过键(key)值即可快速的取出对应的值(value),因此hash表查询的速度很快。但是,哈希算法有hash冲突的问题,也就是说多个不同的key最后得到的index相同,虽然hash通过链表的方法解决了hash冲突,但是如果使用hash用来存储数据,mysql可能会将每一行数据都存储在hash表中,这样数据都会通过hash表来维护,如果数据库操作数据量特别庞大,添加数据的时候会增加hash冲突次数。这是原因之一。
还有一个原因是因为hash不支持顺序查找,假如我们要对表中的数据进行排序和范围搜索,hash实现起来会很麻烦。
二叉树
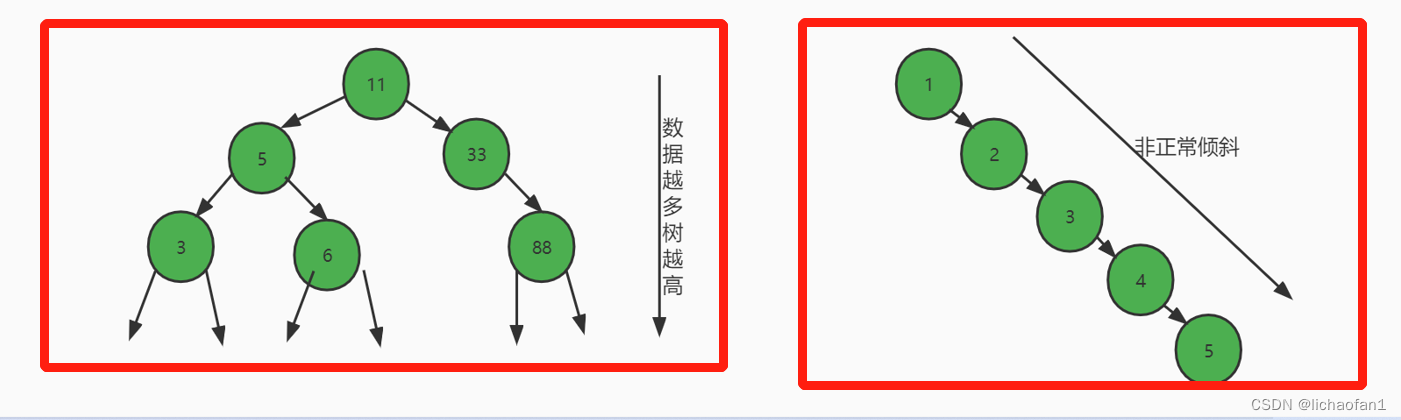
二叉树的每一个节点都只有两个子节点,当需要向其插入更多的数据的时候,就必须要增加树的高度,而增加树的高度会导致IO的次数变多,对于二叉树而言,它的查找操作的时间复杂度就是树的高度,树的高度越高查询性能会随着数据的增多越来越低。
二叉树节点中,右边的节点一定会大于左边的节点。如果是非正常的倾斜(比如id是自增的情况)的二叉树,查询一次数据就相当于与全表搜索。
红黑树
红黑树是一个二叉平衡树。平衡树在插入和删除的时候,会通过旋转操作将树的左右节点达到平衡。红黑树的特性导致从根节点到叶子节点的最长路径不会超过最短路径的2倍。在实际场景应用当中,MySQL表数据,一般情况下都是比较庞大、海量的。如果使用红黑树,树的高度会特别高,红黑树虽说查询效率很高。但是在海量数据的情况下,树的高度并不可控,而且红黑树也需要不断的调整平衡性,也需要消耗性能。如果我们要查询的数据,正好在树的叶子节点。那查询会非常慢。
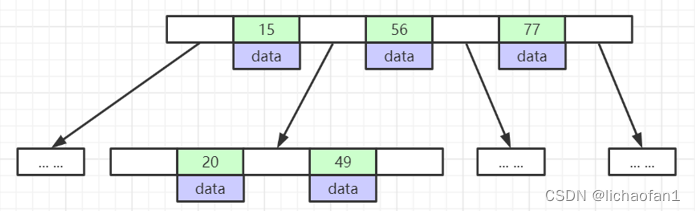
b-tree
B树的叶子结点具有相同的深度。所有索引元素不重复,节点中的数据索引从左到右递增排列。
那么为什么不选择B-tree呢?
- B树的索引节点既要存索引信息,又要存其对应的数据,每个节点一次I/O操作就可以完全载入,这样能大大提高对数据读取的效率。但是如果数据很大,那么当树的体量很大时,节点上的数据会超过磁盘块大小范围。但是B树的高度是根据索引的大小决定的,比如一个叶子节点的大小是16Kb,一个索引元素按照1kb(比如一个表有二十个字段,每个字段都是bigint占用8个字节,可以算出,一行数据应该不会超出1KB,这是一个预估值《按照平均1kb计算》),一个叶子节点只能存16个索引元素,如果要查找千万级的数据,需要16 的N次方=一千万才能查到数据,N就是查找的索引次数。
b+tree
-
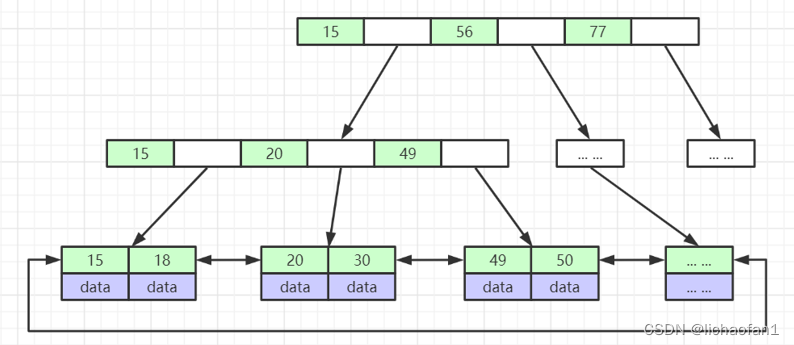
B+Tree和B-Tree的差距在于B+Tree的分支节点只存储索引信息,把数据都放在叶子节点上(非叶子节点是冗余节点,取得是叶子节点在磁盘节点上某些部分的索引),而且叶子节点包含了书中所有的索引结构,从左到右有序的递增的,这样保证了相近的数据都能存在同一块数据块里。叶子节点的每一页都包含了上一页和下一页的内存地址的指针索引,因此B+树具备了天然排序功能,在排序和范围查找的时候更方便。
-
同时B+树的查询次数更稳定,每次查询次数都是相同的,都需要查询到叶子节点。比如:在mysql中B+Tree默认的磁盘页节点大小是16KB,假设索引(主键索引)是bigint类型的,那么他会占8个字节,加上叶子结点的磁盘文件地址6个字节,节点索引大小大概是14tb,那么每一个索引行(页)就可以存储1170个索引元素,加入第三行存的是叶子节点,因为节点中包含所有数据信息(假设是整行数据,大小算1kb《比如一个表有二十个字段,每个字段都是bigint占用8个字节,可以算出,一行数据应该不会超出1KB,这是一个预估值》),那么b+tree树只需要三行就可以存放1170×1170×16=21,902,400 个索引元素了。所以B+Tree只需要三次的磁盘io就可以找到需要查找的元素了。也就说千万级的数据(走索引的情况)查找只需要经过三级就可以快速的查找到需要的元素了。
b-tree和b+tree的区别
- b+树只需要三级既可以存储千万级别的数据索引了,而b-树需要是根据索引的索引元素大小来构建索引节点的,数据量较大的时候,b+树io次数更少。
- b+树只有的叶子才会存储数据,b-树所有索引节点都会存储数据。
- b+树所有查询都要查找到叶子节点,查询性能稳定。
- b+树所有叶子节点在这里插入图片描述
形成有序链表,便于范围查询。
mysql的存储引擎

