
- 1Yakit工具篇:WebFuzzer模块之序列操作
- 2SpringBoot2---单元测试(Junit5)(1),2024年最新金九银十
- 3ping: sendto: No route to host
- 4图详解第五篇:单源最短路径--Bellman-Ford算法
- 5ElasticSearch查询流程详解_elasticsearch查询过程
- 6pytest自动化测试框架_pytest框架
- 7Java自然语言处理实现基于酒店评价的词云可视化(前端与后端交互使用)_java词云分析
- 8看langchain代码之前必备知识之 - Python 协程:异步编程的利器_langchian python
- 9阿里计算巢:开启数据集市场的宝库,助力AI研究和应用_cmekg数据集
- 10IT入门知识第五部分《前端开发》(5/10)
VITS声学模型的云端训练和本地推理_vits模型
赞
踩
前言:云端训练白嫖谷歌的显卡,本地推理需要有一张3GB显存及以上的N卡
一、云端训练篇(以100条10秒内的短语音为例)素材自备
1、进入笔记本(需要科学上网),登录自己的账号
这个地址可以白嫖谷歌,每天有免费的时常,足够(每天)训练一个模型。
笔记本地址:VITS-fast-finetuning.ipynb - Colaboratory (google.com)VITS-fast-finetuning.ipynb - Colaboratory (google.com)VITS-fast-finetuning.ipynb - Colaboratory (google.com)笔记本地址:
1.(可不做)运行代码块,查看云端显卡型号(免费的一般是Tesla T4 )

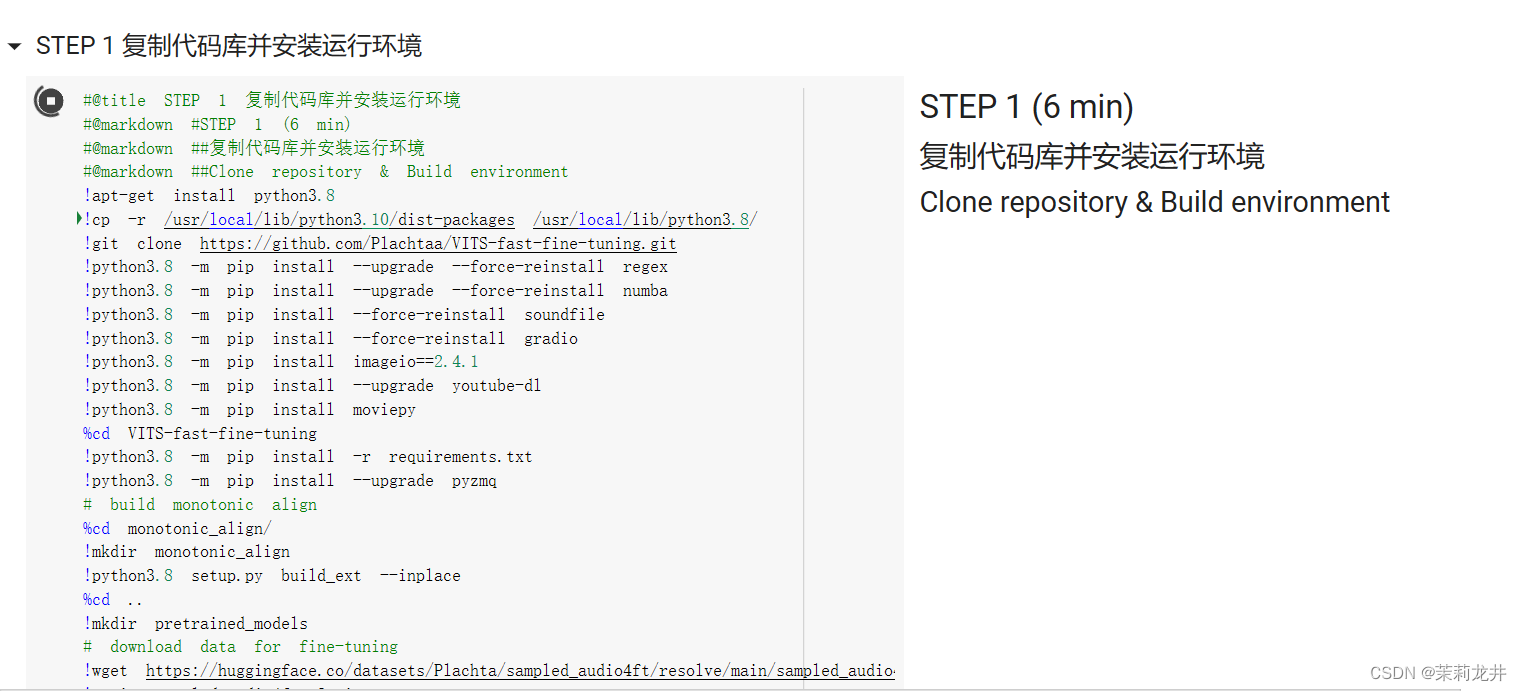
2.继续点击 STEP 1 下的按钮执行代码块,安装运行环境
此过程大概需要等待几分钟
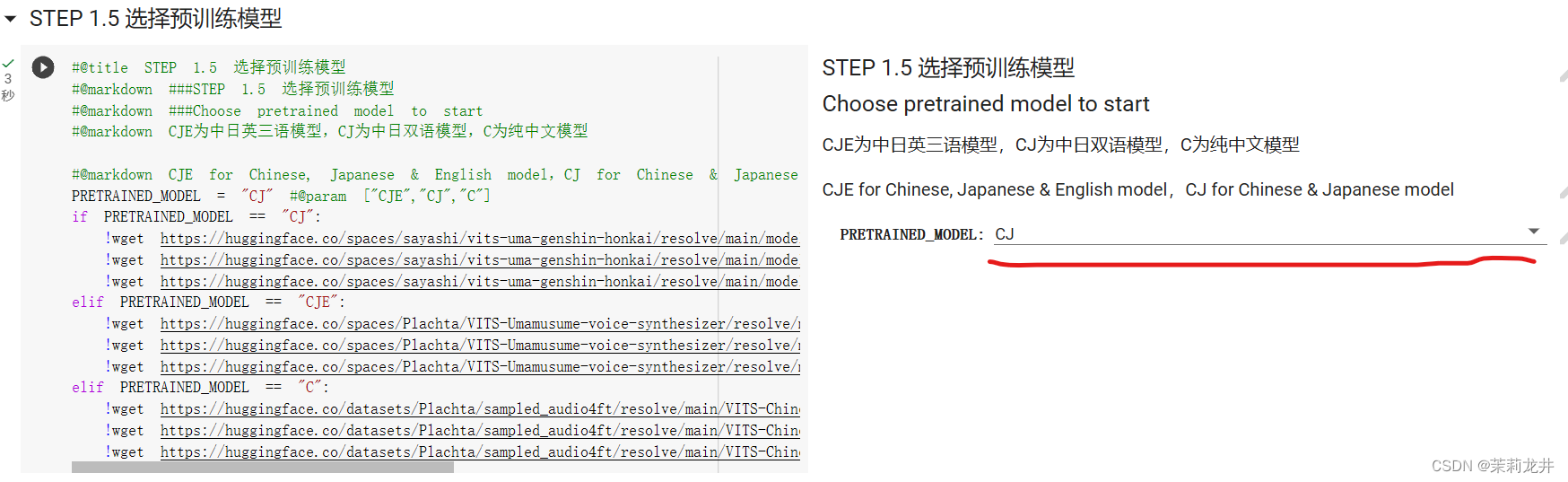
3、选择并生成声学模型
CJ是中日双语,CJE是中日英三语,根据自己的需要选择
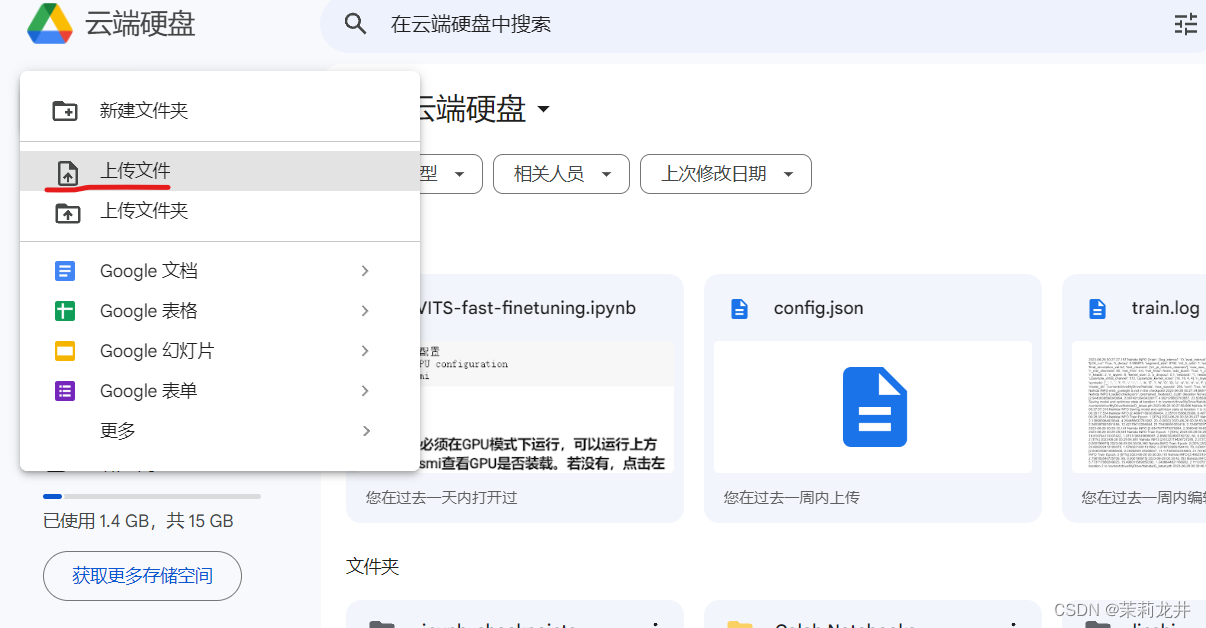
4、把训练素材上传到谷歌云盘
我们用谷歌云盘导入素材,因为这种方法导入很快,如果用本地导入,上传速度慢
用一个文件夹装着你的语音素材(语音素材质量比数量重要),然后压缩这个文件夹,上传到谷歌云盘上
在云盘上点击新建,选择上传文件,上传训练素材
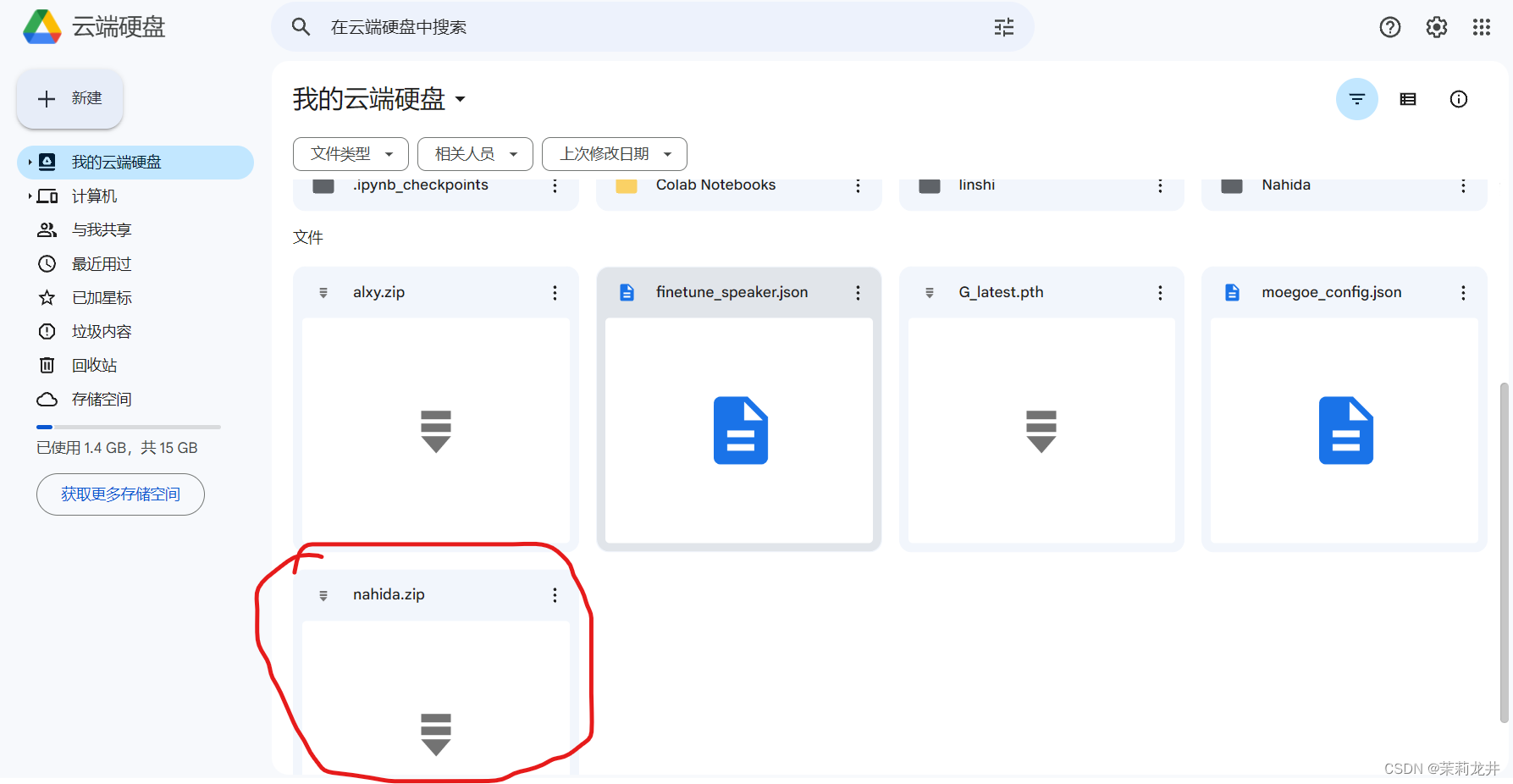
上传完成后,可以看到你上传的压缩包
5、登录谷歌云盘
回到笔记本页面,运行代码块,登录谷歌云盘

登录成功后,可以在左侧看到文件夹目录,根据以下路径可以看到刚刚上传的压缩包
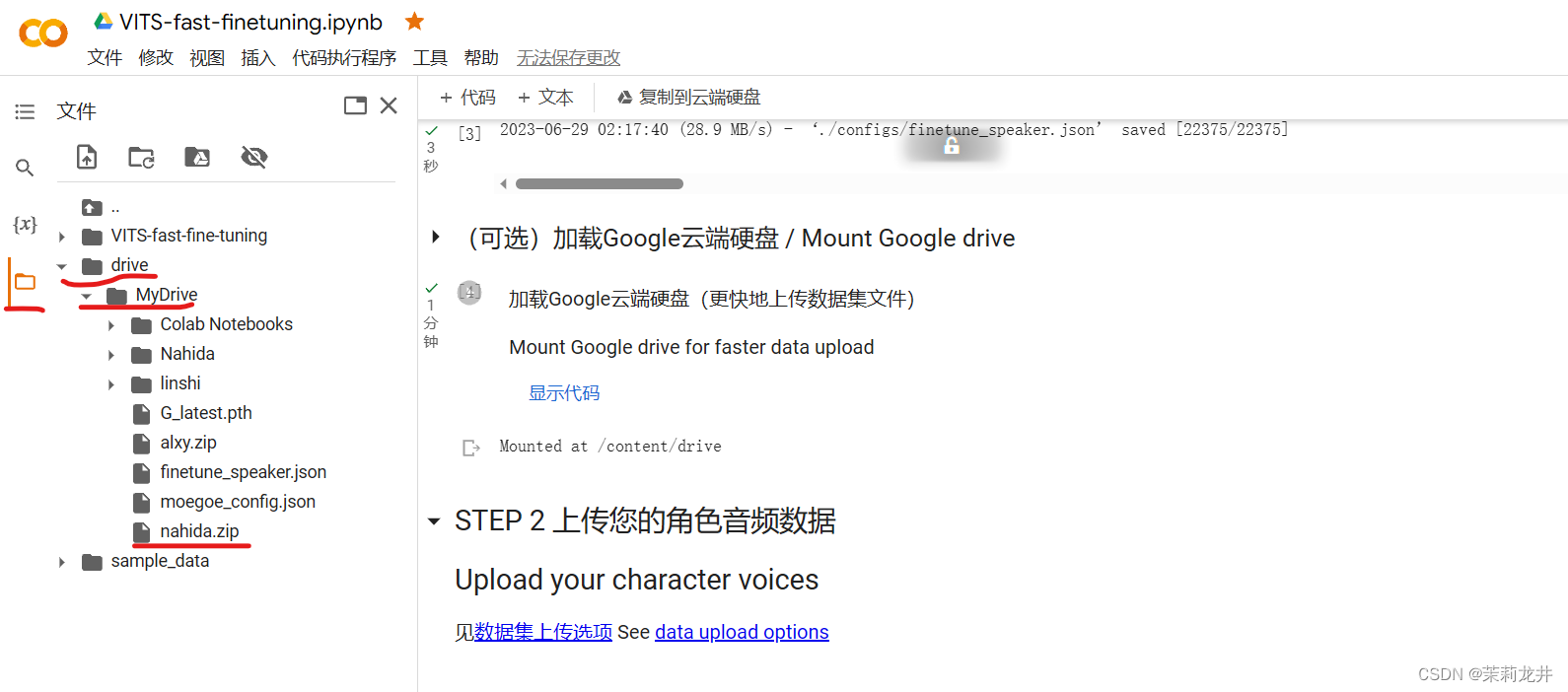
6 、导入素材压缩包
在如图所示位置填写压缩包路径和压缩包名称,然后点击按钮运行代码块,开始上传
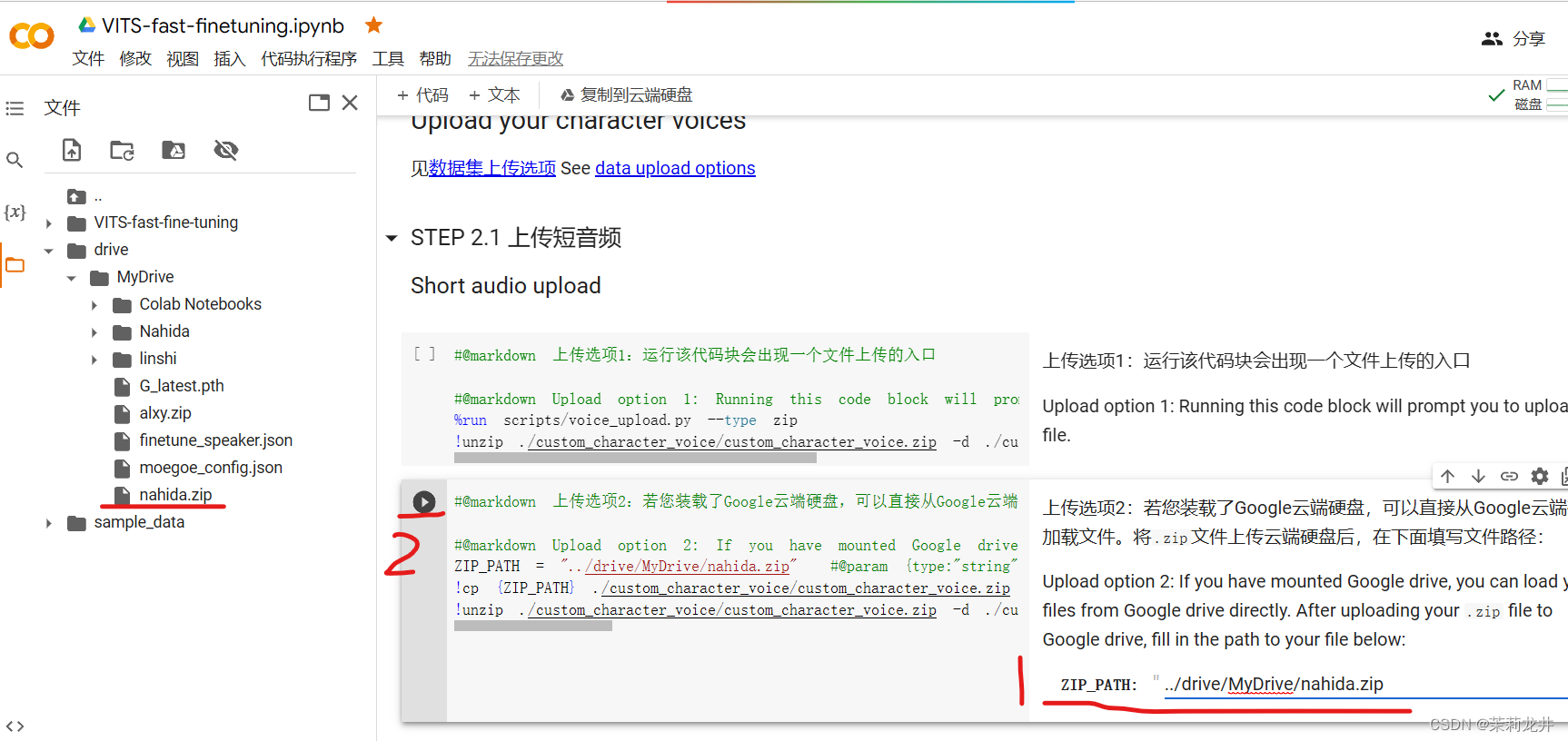
7、来到 STEP 3 ,自动处理数据
直接运行代码块,时间可以比较长,用于识别语音

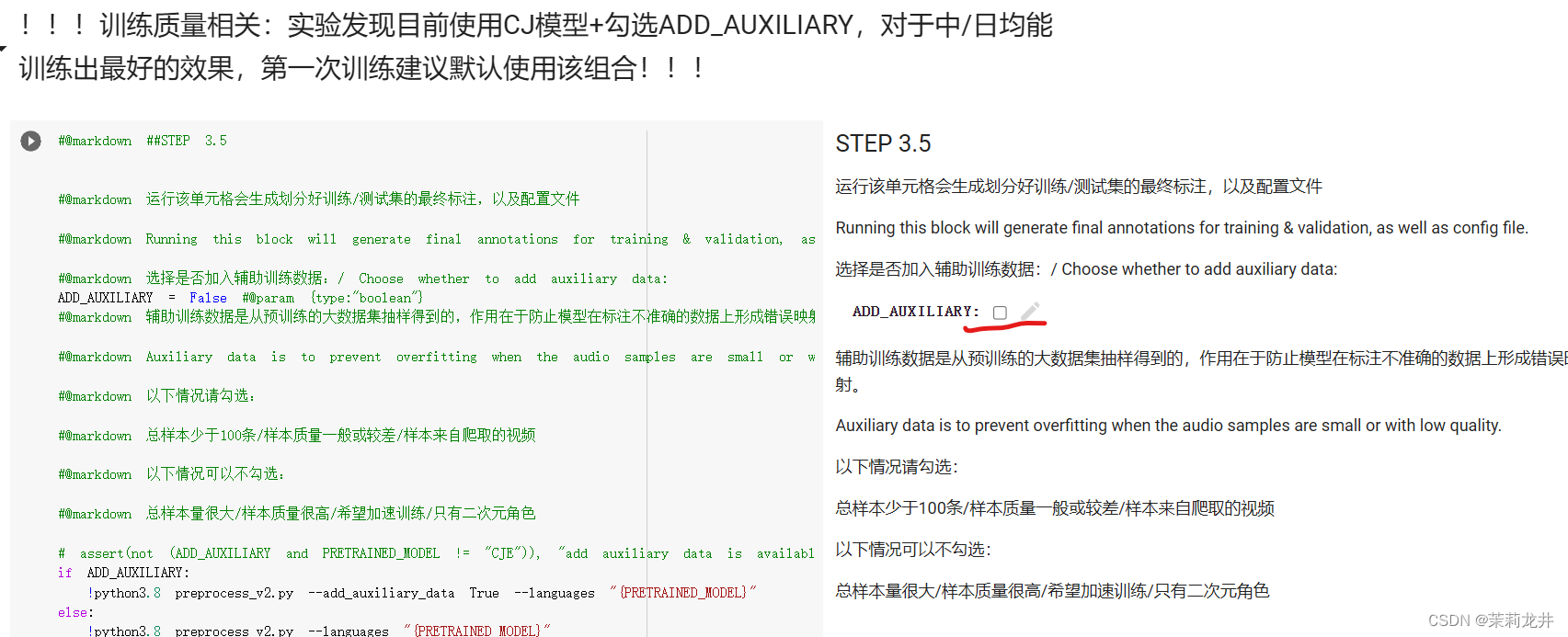
8、选择是否辅助训练数据
中日双语模型可勾选,质量更佳;具体可以看绿字说明
9、开始训练(俗称炼丹)
复制一个用于装载训练模型的文件夹的路径,没有就创建一个
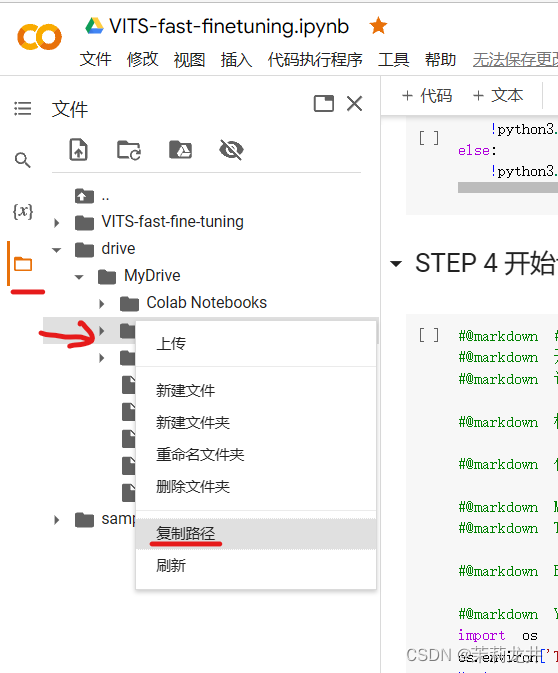
填入到代码块的这个地方,用于防止出现意外,训练中止又无法保存模型,填入后会边训练边保存节点模型,不用担心文件太多导致谷歌云盘容量不足,达到一定的阈值会自动帮你删除前面保存的模型
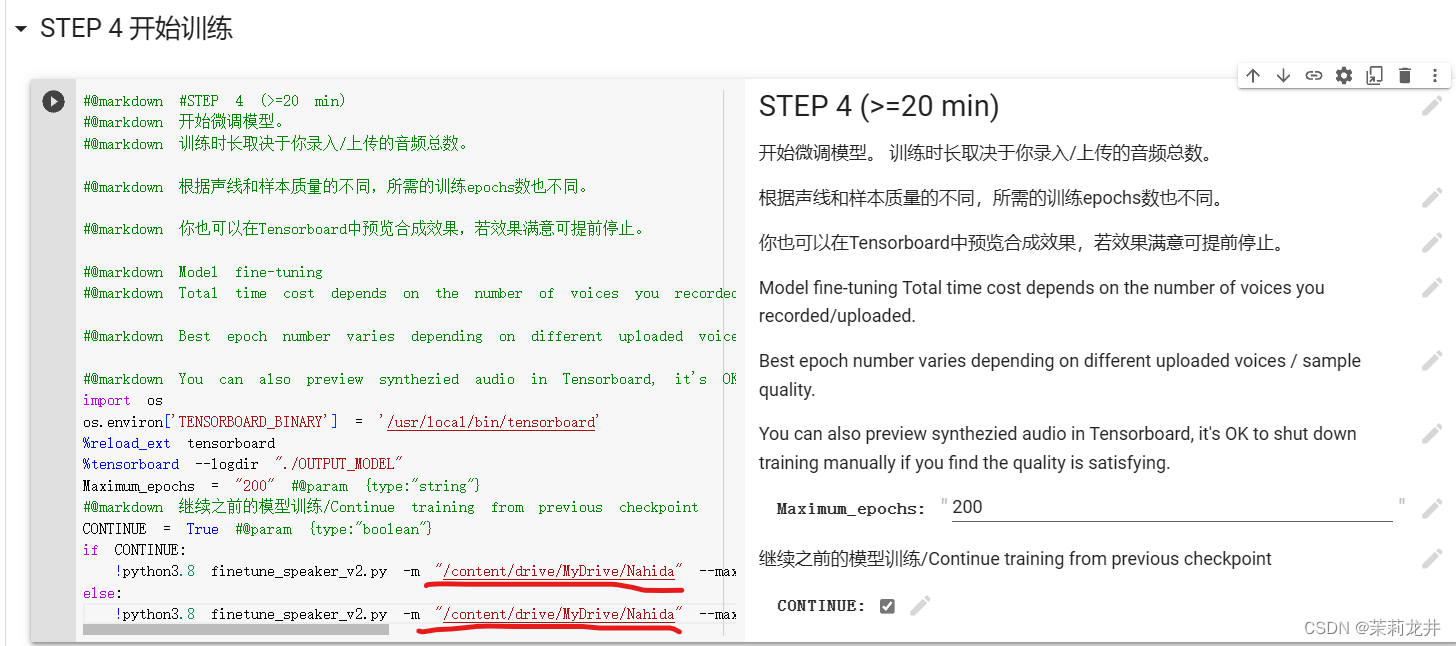
设置训练步数,100条短语音一般设置200~300步,不是越多越好,多了会造成过拟化,起到反作用。注意CONTINUE要保持勾选。然后运行代码块
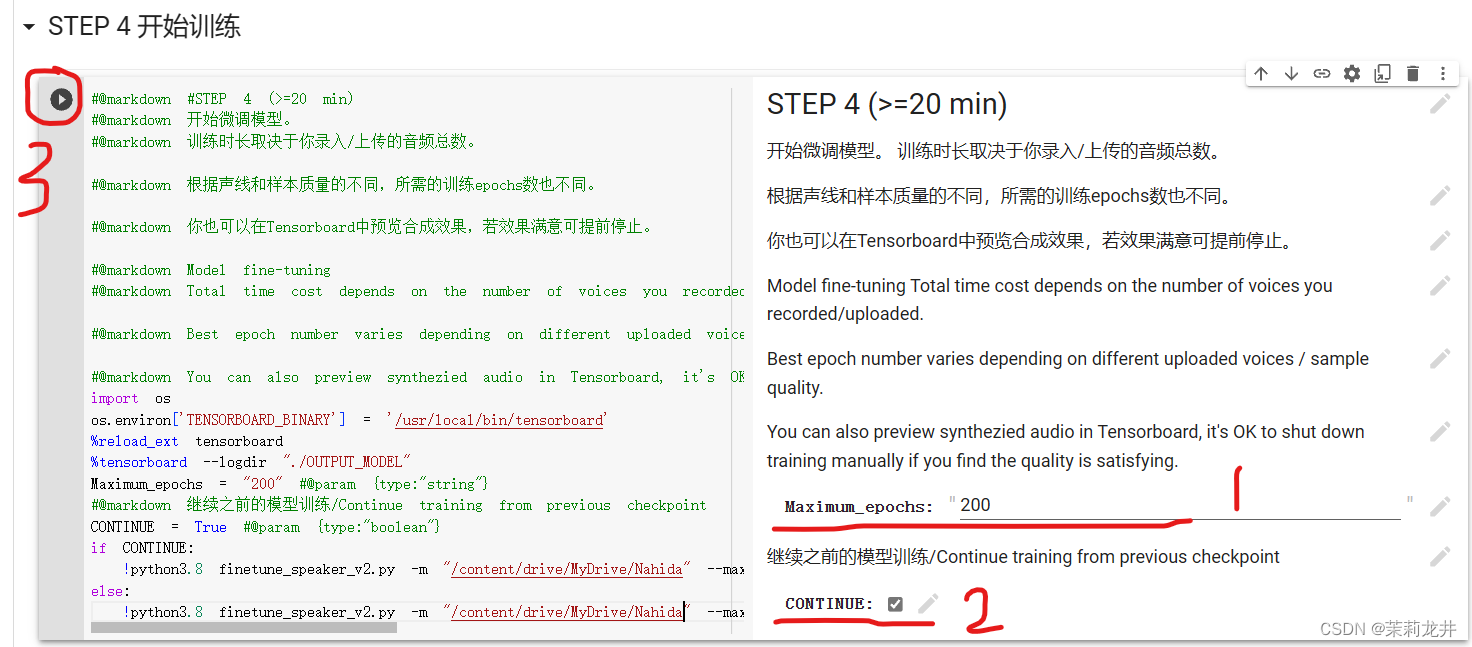
等待训练完成,一般时间较长,可以在谷歌云盘下载训练节点中的模型测试
10、下载模型
可选下载到本地、保存到谷歌云盘,如果在训练开始前在代码块里填入了装载模型的文件夹路径,这部可以不做,直接在谷歌云盘下载。
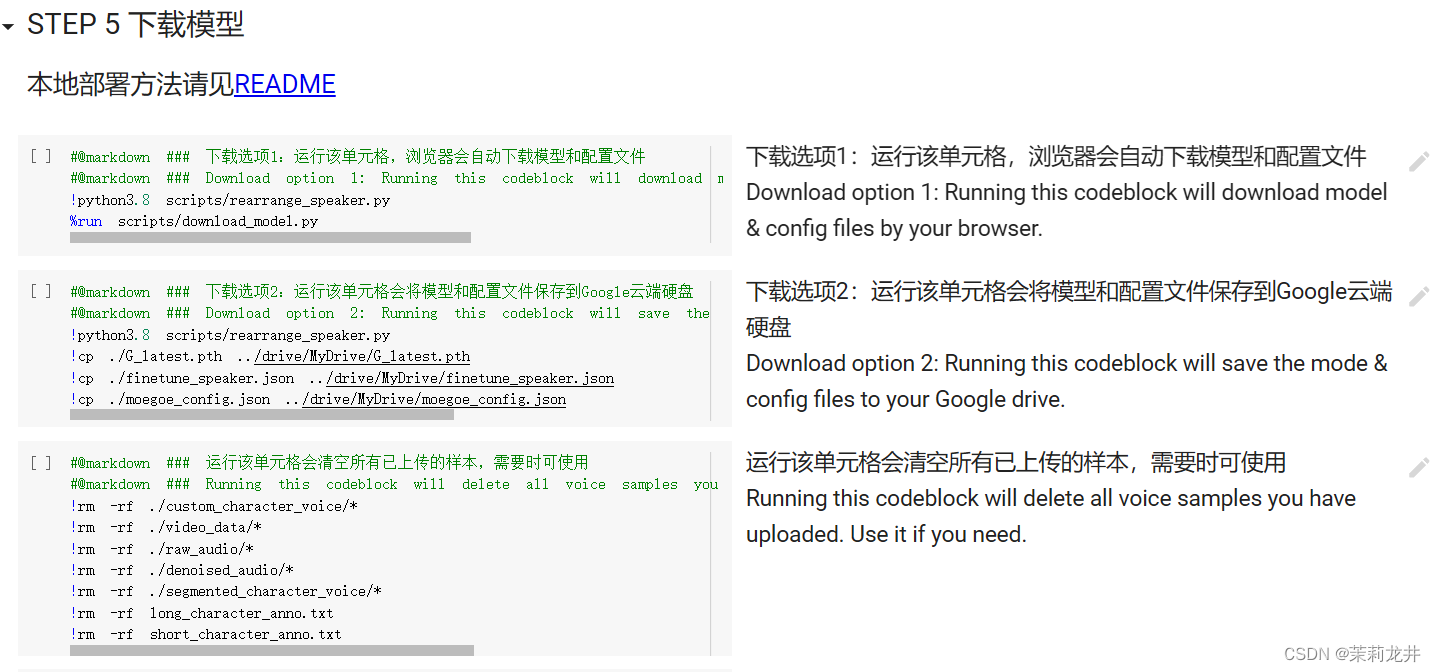
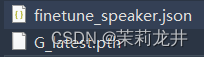
我们至少需要下载两个文件,一个 config.json 配置文件,一个或多个以 .pth 结尾的模型文件

至此,模型训练篇完结
二、本地推理篇
1.下载vits项目到本地
2.把模型和配置文件放入到vits项目根目录中,配置文件名改成 finetune_speaker.json
3、运行项目,转换文字
运行项目,等待一会,它会自己打开浏览器。选择说话人,选择语言,点击右边的Generatel按钮开始转换
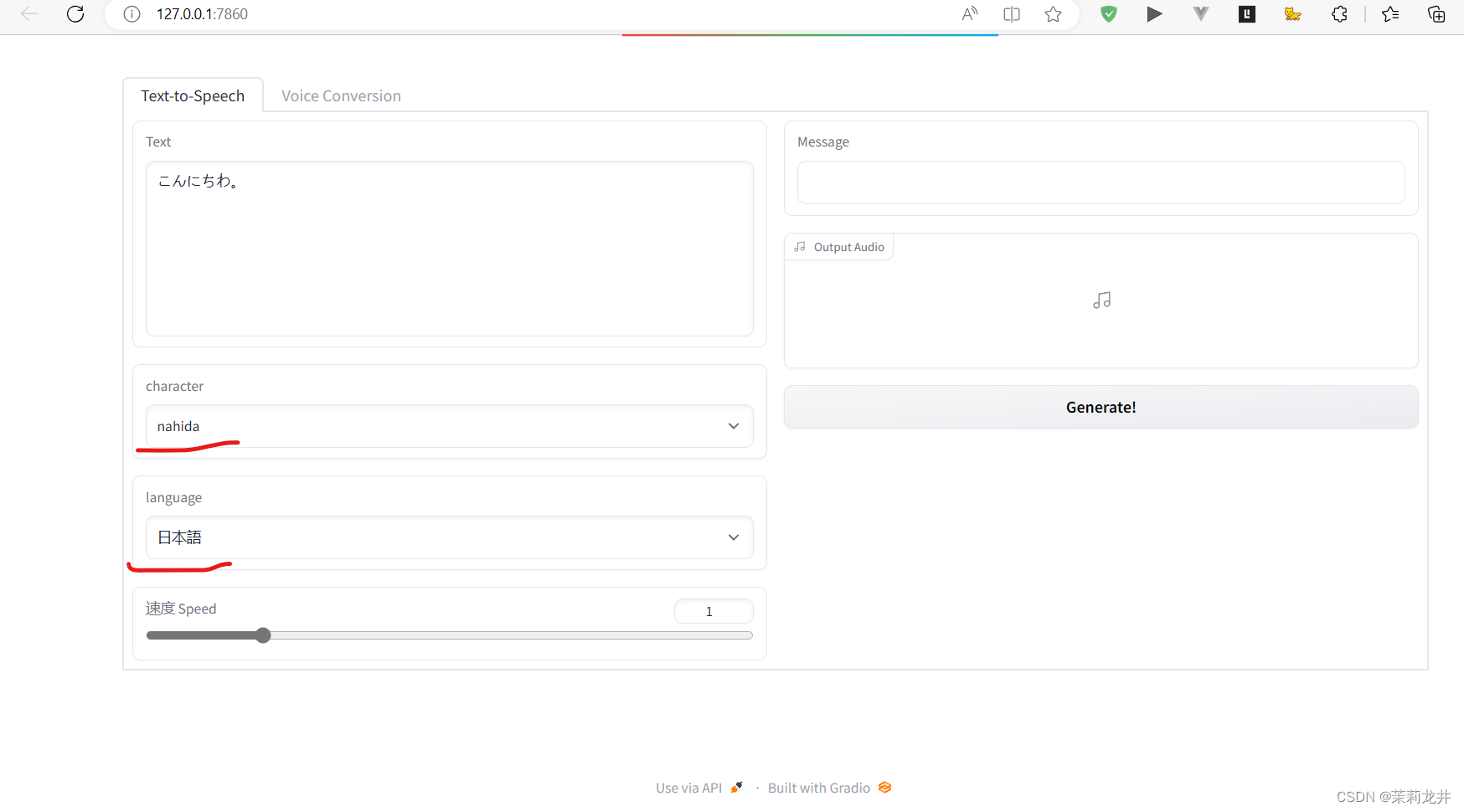
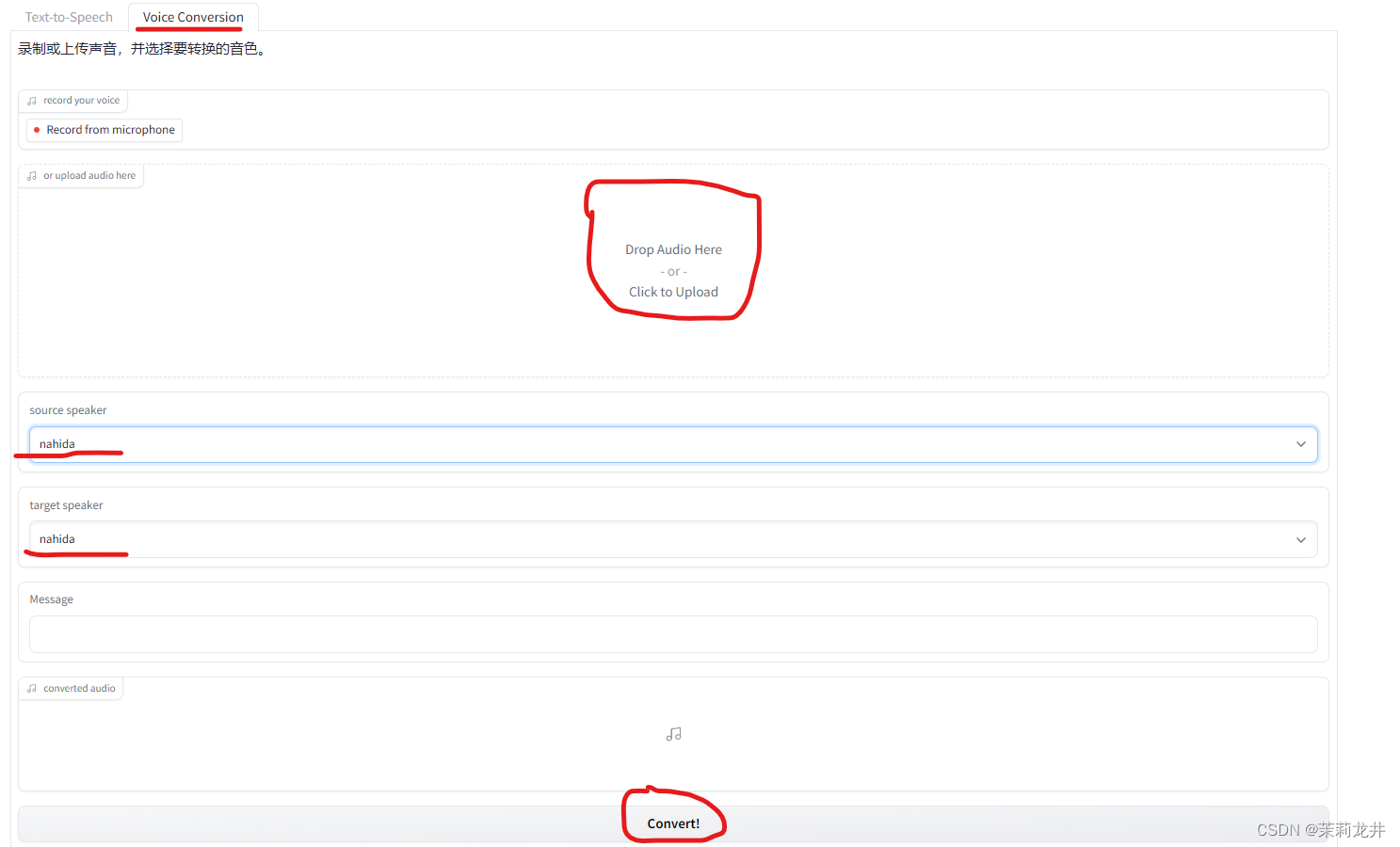
4.转换语音文件
点击右边选项卡,可以录音,可以上传语音文件;选择说话人,点击转换即可
欢迎学习和交流!!!在这里提醒大家,声音也属于肖像权,具有法律效应,请勿商用,更不要用来做一些违法的事情!!!


