- 1STM32作业设计
- 2qt creator源码全方面分析(3-1)_qt designer 插件源代码解读
- 3Linux环境项目开发(一)——虚拟机安装与Git配置_虚拟机设置git分支
- 4Word 模板引擎_word 作为模板引擎
- 5未来洞察:Yann LeCun 与 Lex Fridman 深度对话AI的边界
- 6python爬虫之aiohttp多任务异步爬虫
- 7vue 列表内容自动向上滚动_原生JS实现列表内容自动向上滚动效果
- 8解决gitpush远程文件超超过100m,无法push成功,也无法删除问题._gitee 双穿100m失败,文件删除后也不能成功如何清除
- 9开发者新手指南:进入 Web3 前,你需要掌握哪些必备技能?_参与web3开发,中国程序员需要注意什么
- 10一张图说清楚:大模型“大”在哪?ChatGLM模型结构详解
基于Hadoop娄底市租房数据分析系统的设计与实现
赞
踩
编号:2461601
项目+LW(说明书)+任务书(开题报告)
完整项目联系方式在文章最下面
目录
关键技术
数据分析 - Hadoop + HIve
数据爬虫 - Selenium
数据清洗 - Pandas
数据库 - MySQL
后端 - Python | Flask
前端 - HTML | JS | CSS
可视化 - Echarts
部分内容展示
第四章 数据清洗与分析
4.1 数据清洗
数据清洗是数据分析流程中不可或缺的一步。它的目的是提高数据质量,确保后续分析的准确性和可靠性。以下是本项目中数据清洗的步骤和方法。
加载数据:
- import pandas as pd
- data = pd.read_csv('anjuke.csv') # 加载采集到的原始数据
原理:使用Pandas库的read_csv函数加载存储在CSV文件中的数据。
删除重复数据:
data.drop_duplicates(inplace=True) 原理:使用Pandas的drop_duplicates方法去除数据中的重复行,保留唯一数据条目。
处理缺失值:
data.dropna(inplace=True) 原理:使用dropna方法删除含有缺失值的行,确保数据的完整性。
转换数据类型和清理数据:
- data['价格'] = pd.to_numeric(data['价格'], errors='coerce')
- data['平米价'] = data['平米价'].str.replace('元/㎡', '').astype(float)
- data['面积'] = data['面积'].str.replace('㎡', '').astype(float)
原理:转换数据类型以便进行数值分析,例如,将价格从字符串转换为数值类型,并去除单位。使用pd.to_numeric和astype方法进行转换,errors='coerce'参数将无法转换的值设置为NaN。
删除异常值:
data = data[(data['平米价'] > 1000) & (data['平米价'] < 100000)] 原理:基于业务知识或先前的分析结果,去除不合理的数据,如异常的价格或平米价。
清理文本数据:
- data = data.apply(lambda x: x.str.strip() if x.dtype == "object" else x)
- data['房型'] = data['房型'].apply(lambda x: x.replace(' ', '') if isinstance(x, str) else x)
原理:删除文本数据中不必要的空格,保持数据的一致性和清洁性。
保存清洗后的数据:
data.to_csv('cleaned_data.csv', index=False) 原理:将清洗后的数据保存回CSV文件,为后续的数据分析阶段做准备。使用to_csv方法,并设置index=False以防在文件中添加不必要的索引列。
运行截图






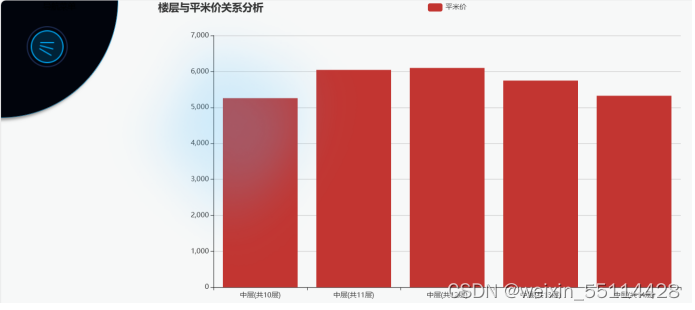
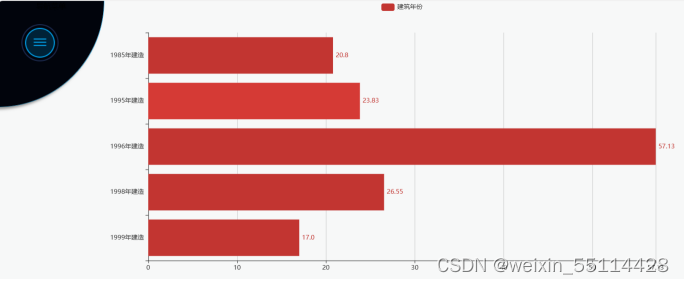
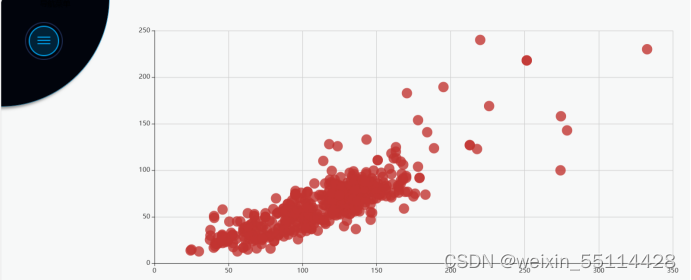

本项目的主要目标是通过分析娄底市房价数据来探索影响房价的关键因素,同时利用现代数据处理和分析技术提出合理的市场预测和建议。
在项目过程中,完成了从数据采集、清洗、分析到结果可视化的全过程。通过使用Selenium、Pandas、MySQL、Hadoop、Hive、Flask 和 Echarts 等工具和技术,处理了大量的房价数据。
V - WeiDaPang_T
Q - 977266623