
- 1Llama3破防:越狱过程和提示词全解析_llama3 提示词
- 2每日新闻掌握【2024年4月10日 星期三】
- 3Spring 都支持无缝接入各个AL大模型了,你还不知道AL咋用_springai 可台连接哪些语言模型
- 4解决报错ImportError: No module named ‘_sysconfigdata_m‘_importerror: no module named sysconfig
- 5html在线阅读小说网页制作模板 小说书籍网页设计 大学生静态HTML网页源码 dreamweaver网页作业 简单网页课程成品_小说网页设计代码html
- 6【随笔】Git 基础篇 -- 拉取数据 git pull(二十八)
- 7高擎机电12自由度双足机器人pai的算法开源|传统控制篇_桥介数物双足机器人代码如何分析
- 8elasticsearch去重:collapse、cardinality、terms+top_hits实现总结_java elasticsearch collapse
- 9C语言基础——文件_c语言文件
- 10Unity调用API函数对系统桌面和窗口截图_unity中如何调用windows函数
Vision Transformer (ViT)
赞
踩
edited by nrzheng,2021.11.27
参考视频1
参考视频2
参考链接
Vision Transformer (ViT)
1. 回顾Transformer (TRM)
transformer网络结构如下图所示:
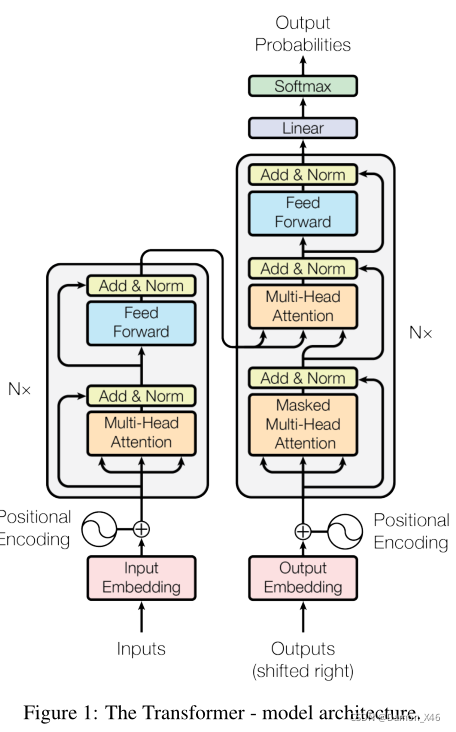
- 左半部分为编码端;右半部分为解码端。(假设汉字翻译成英文)(括号内对应上图操作)。
- 编码端输入汉字。转化为数字 (Inputs),再转化为 token embedding (Input Embedding),也就是词向量。
- 把 token embedding 和对应的 (positional encoding) 相加组成了最终的输入。
- 然后流经多头自注意力层 (MHA) 然后流经前馈神经网络 (FF) 。
- 这个操作是 × \times ×n 的,就是有个一样的块堆叠起来的。
- 解码端也是相同的操作
- 要注意一开始的多头注意力层是有 Masked 的。
- 同时,要注意其中的交互注意力层,Q 来自于Decoder,K、V 来自于 Encoder。
- Decoder 也是 × \times ×n 的。
2. ViT
ViT中用到的只有TRM中的编码端
2.1. 输入处理
现在的问题就是,vision 中输入的是图片,但是 TRM 是用来处理自然语言的,那么要怎么把图片融入到 TRM 的 Encoder 中呢?也就是,图片要怎么处理,才可以当作 TRM 的输入?
最简单的方式,就是把图片转化成 NLP 中一个一个的 token,那么怎么转化呢?
- 最容易想到的是,把每个像素点拿出来,每个像素点作为一个 token。然后再转化为 token embedding,再和对应的位置编码相加,这样就解决输入了。
- 但是会有一个很大的问题(就是复杂度的问题),图片很大的,假设图片是 224 × \times × 244,那输入就变成 50176 的大小,太大了。我们知道,在 NLP 中,一般词向量就是 512 长而已,这样图片相当于 NLP 的 100 倍,长度太大了,那么对应的参数量就会太大,计算机没办法承受。
这个问题是它会随着图片的长宽成平方级增长(图片是 h
×
\times
× w 的嘛)。
如何处理复杂度问题?:本质上是去解决随着像素增加,复杂度平方级增长的问题。
有很多种改进方式:
- 局部注意力机制
- 改进 attention 公式
- …
但是上面的方式还是太麻烦,所以一个简单的改进方式:图像化整为零,切分 patch 。
也就是说,原来是一个像素点代表一个 token,现在是一大块的 patch 作为一个 token。
以下就是 ViT 的网络结构:
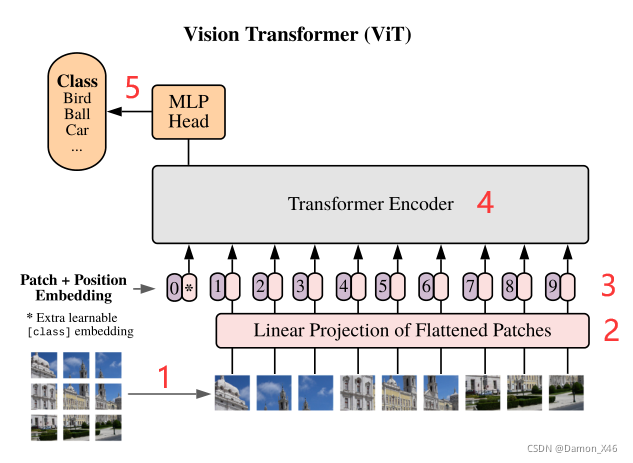
- 图片切分为 patch
- patch 转化为 token embedding
- token embedding 和对应的 position embedding 相加
- 输入到 TRM 模型的 Encoder 中
- CLS 输出做多分类任务
好了,步骤就是这么些步骤了,有问题吗?没有问题。
2.2. patch embedding(结构图的2)
那么问题来了。第二步中,patch 怎么转化成 token embedding 的???
其实第二步又分为两个小步骤:
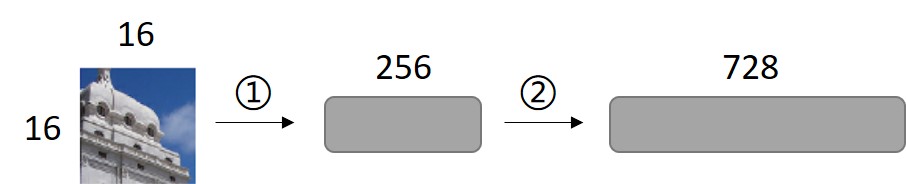
- 假设每个 patch 的大小是 16 × \times × 16,假设TRM 规定的输入维度是728。
- 第一小步就是把每个 patch 展平成 256。
- 但是 256 和TRM规定输入 728 之间是有一个 gap 的。
- 所以第二小步就是这边需要一个 linear 层,把 256 映射到 728。就是把展平的维度映射到规定的输入维度。
重点来咯!
这里 256 映射到 728 用的是 linear 线性层做映射。其实也可以使用一个 16
×
\times
× 16,步长是 16 的卷积来操作这个,只要把卷积核的个数设置为 728,那么输出的维度就是 728。
想象一下(还是假设一个 patch 是 16 × \times × 16)。线性变化是 (256—>728),用卷积操作的话也是 (256—>728),因为一个 patch 是 16 × \times × 16,卷积核大小也是 16 × \times × 16,卷出来就是 1 个数,那么有 728 个卷积核,就是 728 个数了。就相当于把 256 映射到 728 了呗。
(ViT在说的是它不需要使用卷积操作,所以用的是 linear,其实这里用卷积是可以的)
2.3. CLS 和位置编码(结构图的3)
好了,重点又来了!
其中的第三个步骤,又要分为几个小步骤,第三个步骤图拿下来:

第三步又可以分为三个小步骤(看图看图看图,注意 * 号 和 0 那一块,不是从第二步来的哦!):
- 生成 CLS 符号的 token embedding(就是那个 * )
- 生成所有序列(所有的 patch 和 *)的位置编码
- token + 位置编码
为什么要加入一个 CLS 符号?
原文中表述如下:
In order to stay as close as possible to the original Transformer model, we made use of an additional [class] token, which is taken as image representation.
简单的意思就是减少对原始 TRM 模型的更改。(不是很懂,好像 BERT 有提到)(后面实验好像表明了,加 CLS 还是不加,效果都是差不多的)
为什么需要位置编码?
transformer 中讲过了。对应到图像中,就是告诉模型,哪个 patch 是在前面的,哪个 patch 是在后面的
- 如果是一维的,就是:1, 2, 3, 4, …
- 如果是二维的,就是:[1, 1], [1, 2], …
- 还有一种相对位置信息(此处略)
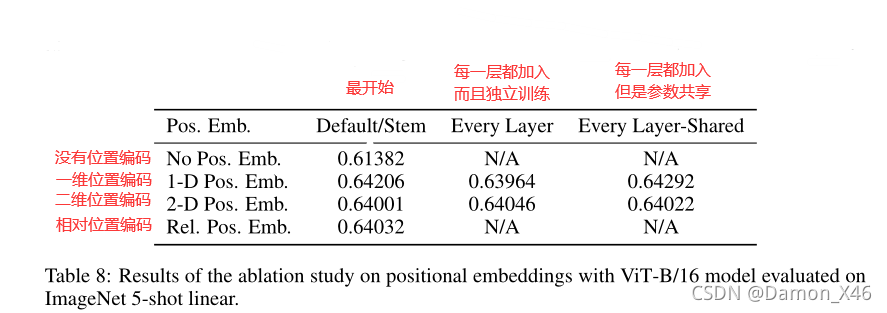
使用的一维位置编码,因为二维跟相对的都比较复杂,一维也没有差很多,所以使用的是一维位置编码。
2.4. Encoder(结构图的4)
ViT 中使用的 Encoder 其实和原始 TRM 中的 Encoder 是不太一样的,ViT中的 Encoder 如下图所示:
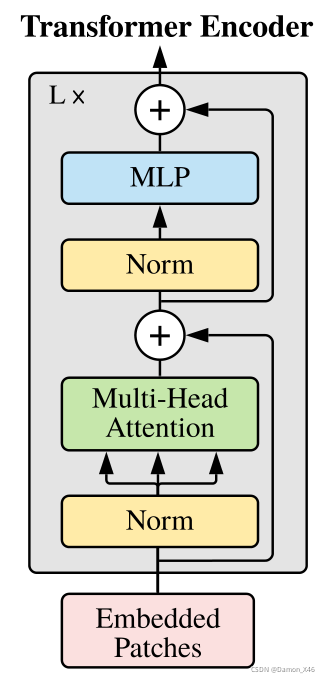
- 把Norm位置提前了
- 没有 pad 符号
这边,如果输入的图像大小是不一样的,可以采用 resize 的方法弄到一样,所以序列的长度会是一样的,也就没有使用 pad 符号了。(没有 pad 符号在实现的时候就很简单了,同时 SoftMax 的时候,不就不需要对 pad 的部分额外操作了吗,就简单了很多)
2.5. 总结
- 分 patch
- 拉平,然后线性映射到 Encoder 需要的输入长度
- 生成 CLS,然后对所有的 patch 和 CLS 都生成位置编码
- 然后把 patch embedding ( token embedding ) 和位置编码相加,得到最终的输入
- 进入 Encoder ( LN—>MHA—> 残差—>LN—>FF—>残差 ) × \times × n
- 最后把 CLS 拿出来做一个多分类任务(就是5)
- 如果前面是没有加 CLS 的话,最后需要用一个 avg_pooling 来做多分类任务

