
- 1基于IP地址的企业网络资产暴露面普查解决方案_一个真实ip怎么去确定是哪个单位的资产
- 2Java怎么实现几十万条数据插入(30万条数据插入MySQL仅需13秒)_java大量数据快速入库
- 3基于Selenium+Python的自动化测试
- 4python自动化工具之pywinauto_pywinauto自动化操作记事本
- 5Scrapy和Selenium整合(一文搞定)_scrapy selenium
- 6Docker与Docker-Compose详解_docker docker-compose
- 7Java高并发解决方案_java高并发三种解决方法
- 8Windows安装使用docker与docker-compose_windows docker compose
- 9C语言面向对象
- 10C语言实现AES加解密算法_c 使用aes
yolov5行人检测算法_prepare_yolo_data.sh
赞
踩
PaddleDetection/pphuman_mot.md at release/2.6 · PaddlePaddle/PaddleDetection · GitHubObject Detection toolkit based on PaddlePaddle. It supports object detection, instance segmentation, multiple object tracking and real-time multi-person keypoint detection. - PaddleDetection/pphuman_mot.md at release/2.6 · PaddlePaddle/PaddleDetection https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/deploy/pipeline/docs/tutorials/pphuman_mot.mdGitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021) - GitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)https://github.com/JialeCao001/PedSurvey行人检测综述_denghe1122的博客-CSDN博客PART Ifrom: http://www.cnblogs.com/molakejin/p/5708791.html行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。从2005年以来行人检测进入了一个快速的发展阶段,但是也存在很多问题还有待解决,主要还是在性能和速度方面还不能达到一个权衡。近年,以谷歌为首的自动驾驶技术的研发正如火如荼的进行,这也迫
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/deploy/pipeline/docs/tutorials/pphuman_mot.mdGitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021) - GitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)https://github.com/JialeCao001/PedSurvey行人检测综述_denghe1122的博客-CSDN博客PART Ifrom: http://www.cnblogs.com/molakejin/p/5708791.html行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。从2005年以来行人检测进入了一个快速的发展阶段,但是也存在很多问题还有待解决,主要还是在性能和速度方面还不能达到一个权衡。近年,以谷歌为首的自动驾驶技术的研发正如火如荼的进行,这也迫https://blog.csdn.net/denghecsdn/article/details/77987627基于FairMOT实现人流量统计 - 飞桨AI Studio本项目基于PaddleDetection FairMOT实现动态场景和静态场景下的人流量统计,提供从 “模型选择→模型优化→模型部署” 的全流程指导,模型可以直接或经过少量数据微调后用于相关任务。 - 飞桨AI Studio
 https://aistudio.baidu.com/aistudio/projectdetail/2421822?channelType=0&channel=0VOC-COCO-MOT20 - 飞桨AI StudioVOC-COCO-MOT20 - 飞桨AI Studiohttps://aistudio.baidu.com/aistudio/datasetdetail/47128
https://aistudio.baidu.com/aistudio/projectdetail/2421822?channelType=0&channel=0VOC-COCO-MOT20 - 飞桨AI StudioVOC-COCO-MOT20 - 飞桨AI Studiohttps://aistudio.baidu.com/aistudio/datasetdetail/47128
时耕科技-中国领先的商业数智化服务提供商 - 时耕科技时耕科技-中国领先的商业数智化服务提供商https://www.timework.cn/col.jsp?id=157YOLOv5训练自己的数据集(超详细)_yolo数据集_AI追随者的博客-CSDN博客一、准备深度学习环境本人的笔记本电脑系统是:Windows10首先进入YOLOv5开源网址,手动下载zip或是git clone 远程仓库,本人下载的是YOLOv5的5.0版本代码,代码文件夹中会有requirements.txt文件,里面描述了所需要的安装包。本文最终安装的pytorch版本是1.8.1,torchvision版本是0.9.1,python是3.7.10,其他的依赖库按照requirements.txt文件安装即可。...
https://blog.csdn.net/qq_40716944/article/details/118188085
yolov5 训练crowded human 【visible body detection】_yolov5训练crowdh_CV-杨帆的博客-CSDN博客使用yolov5训练crowded human中的head与visible bodyhttps://blog.csdn.net/WhiffeYF/article/details/124502681本项目来源于明厨亮灶这样一个背景的视频监控项目,对厨房中是否存在有人场景做一个识别,打算使用yolov5算法。
1.数据集
目前行人检测的数据集包括coco_person,voc_person,mot20/16、17,CrowdHuman , HIEVE,Caltech Pedestrian,CityPersons, CHUK-SYSU,PRW,ETHZ。
2.数据处理
采用coco-voc-mot20数据集,一共是41856张图,其中训练数据37736张图,验证数据3282张图,测试数据838张。
2.1 将上述数据中的train/val/test转成包含图片的txt。
- # coding:utf-8
-
- import os
- import random
- import argparse
-
- parser = argparse.ArgumentParser()
- # xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
- parser.add_argument('--xml_path', default='/home/imcs/local_disk/D0011/Annotations', type=str, help='input xml label path')
- # 数据集的划分,地址选择自己数据下的ImageSets/Main
- parser.add_argument('--txt_path', default='dataSet', type=str, help='output txt label path')
- opt = parser.parse_args([])
-
- trainval_percent = 0.98 # 剩下的0.02就是测试集
- train_percent = 0.9
- xmlfilepath = opt.xml_path
- txtsavepath = opt.txt_path
- total_xml = os.listdir(xmlfilepath)
- if not os.path.exists(txtsavepath):
- os.makedirs(txtsavepath)
-
- num = len(total_xml)
- list_index = range(num)
- tv = int(num * trainval_percent)
- tr = int(tv * train_percent)
- trainval = random.sample(list_index, tv)
- train = random.sample(trainval, tr)
-
- file_trainval = open(txtsavepath + '/trainval.txt', 'w')
- file_test = open(txtsavepath + '/test.txt', 'w')
- file_train = open(txtsavepath + '/train.txt', 'w')
- file_val = open(txtsavepath + '/val.txt', 'w')
-
- for i in tqdm(list_index):
- # import pdb;pdb.set_trace()
- name = Path(total_xml[i]).stem + '\n'
-
- if i in trainval:
- file_trainval.write(name)
- if i in train:
- file_train.write(name)
- else:
- file_val.write(name)
- else:
- file_test.write(name)
-
- file_trainval.close()
- file_train.close()
- file_val.close()
- file_test.close()

2.2 将xml数据转成yolo数据格式
- sets = ['train', 'val', 'test']
- classes = ["person"] # 改成自己的类别
- abs_path = os.getcwd()
- print(abs_path)
-
- def convert(size, box):
- dw = 1. / (size[0])
- dh = 1. / (size[1])
- x = (box[0] + box[1]) / 2.0 - 1
- y = (box[2] + box[3]) / 2.0 - 1
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x * dw
- w = w * dw
- y = y * dh
- h = h * dh
- return x, y, w, h
-
- def convert_annotation(image_id):
- in_file = open(abs_path+'/Annotations/%s.xml' % (image_id), encoding='UTF-8')
- out_file = open(abs_path+'/Yolo/%s.txt' % (image_id), 'w')
- tree = ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
- for obj in root.iter('object'):
- # difficult = obj.find('difficult').text
- try:
- difficult = obj.find('Difficult').text
- except:
- difficult = 0
- cls = obj.find('name').text
- if cls not in classes or int(difficult) == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
- float(xmlbox.find('ymax').text))
- b1, b2, b3, b4 = b
- # 标注越界修正
- if b2 > w:
- b2 = w
- if b4 > h:
- b4 = h
- b = (b1, b2, b3, b4)
- bb = convert((w, h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
-
-
- wd = getcwd()
- for image_set in tqdm(sets):
- image_ids = [line.strip() for line in open('./dataSet/%s.txt' % (image_set)).readlines()]
- list_file = open('%s_yolo.txt' % (image_set), 'w')
- for image_id in image_ids:
- try:
- list_file.write(abs_path + '/JPEGImages/%s.jpg\n' % (image_id))
-
- convert_annotation(image_id)
- except:
- continue
- list_file.close()
2.3 更改数据集名称
../datasets/coco128/images/im0.jpg # image ../datasets/coco128/labels/im0.txt # label
yolo会自动的把image换成labels,去找标签名,因此数据集名称要换成labels和images。
2.5 crownhuman数据
使用YOLOv5-Tools中的CrowHuman2YOLO中代码
bash ./prepare_data.sh 608x608
生成了crownhuman-608x608,里面已经是yolo格式了,但是添加到上面的数据集里,还需要一些操作。这其中图片数据:19370,文本数据:19370,其中test数据:4370,train数据:15000.
2.5.1 将image和txt分别提取
- import os
- import shutil
-
- # 源文件夹路径
- source_folder = "/home/imcs/local_disk/crownhuman/crowdhuman-608x608/"
- # 目标文件夹路径
- target_folder = "/home/imcs/local_disk/crownhuman/images"
-
- # 遍历源文件夹中的所有文件
- for filename in os.listdir(source_folder):
- file_path = os.path.join(source_folder, filename)
- # 如果这是一张图片,则迁移该图片到目标文件夹
- if os.path.isfile(file_path) and filename.lower().endswith(('.jpg', '.jpeg', '.png', '.gif')):
- shutil.move(file_path, target_folder)
- print('Moved image:', file_path)
-
-
- import os
- import shutil
-
- # 源文件夹路径
- source_folder = "/home/imcs/local_disk/crownhuman/crowdhuman-608x608/"
- # 目标文件夹路径
- target_folder = "/home/imcs/local_disk/crownhuman/labels"
-
- # 遍历源文件夹中的所有文件
- for filename in os.listdir(source_folder):
- file_path = os.path.join(source_folder, filename)
- # 如果这是一个txt文件,则迁移该文件到目标文件夹
- if os.path.isfile(file_path) and filename.lower().endswith('.txt'):
- shutil.move(file_path, target_folder)
- # print('Moved txt file:', file_path)
2.5.2 对路径进行更新
- import os
-
- # 源 txt 文件路径
- source_file = "/home/imcs/local_disk/crownhuman/train.txt"
- # 目标 txt 文件路径
- target_file = "/home/imcs/local_disk/crownhuman/train_yolo.txt"
-
- # 图片路径前缀(例如:原图路径为 "/path/to/image.jpg",更新后的路径为 "/new_path/to/image.jpg")
- prefix = "/home/imcs/local_disk/crownhuman/images"
-
- # 打开源 txt 文件和目标 txt 文件
- with open(source_file, 'r') as f, open(target_file, 'w') as t:
- # import pdb;pdb.set_trace()
- # 逐行读取源 txt 文件中的内容
- for line in f:
- # 删除每行末尾的换行符
- line = line.strip()
- # 如果该行内容是一个图片路径,则更新该路径并写入目标 txt 文件
- if line.lower().endswith(('.jpg', '.jpeg', '.png', '.gif')):
- new_line = os.path.join(prefix, os.path.basename(line))
- t.write(new_line + '\n')
- print('Updated image path:', line, '->', new_line)
- else:
- t.write(line + '\n')
2.5.3 对labels中的0标签进行修改,0 表示head,1表示person
- import os
-
- input_dir_path = '/home/imcs/local_disk/crownhuman/labels_all'
- output_dir_path = '/home/imcs/local_disk/crownhuman/labels'
-
- for filename in os.listdir(input_dir_path):
- if not filename.endswith('.txt'):
- continue
-
- input_file_path = os.path.join(input_dir_path, filename)
- # output_file_path = os.path.join(output_dir_path, filename.replace('.txt', '_processed.txt'))
- output_file_path = os.path.join(output_dir_path, filename)
-
- with open(input_file_path) as input_file, open(output_file_path, 'w') as output_file:
- for line in input_file:
- row = line.strip().split()
- label = int(row[0])
- if label == 1:
- output_file.write(' '.join([row[0].replace("1","0")]+row[1:]) + '\n')
- print('Done!')
3.环境安装
python3.7 cuda10.1
pip install -r requirements
torch==1.8.1_cu101
torchvision==0.9.1_cu101
tqdm==4.64.0
thop==0.1.1.post2207130030
matplotlib==3.2.2
numpy==1.18.5
opencv-python==4.1.1
pillow==7.1.2
pyyaml==5.3.1
requests==2.23.0
scipy==1.4.1
tqdm==4.64.0
tensorboard==2.4.1
pandas==1.1.4
seaborn==0.11.0
升级glic/libstdc++.so.6
Downloading https://ultralytics.com/assets/Arial.ttf to /home/imcs/.config/Ultralytics/Arial.ttf
4.模型
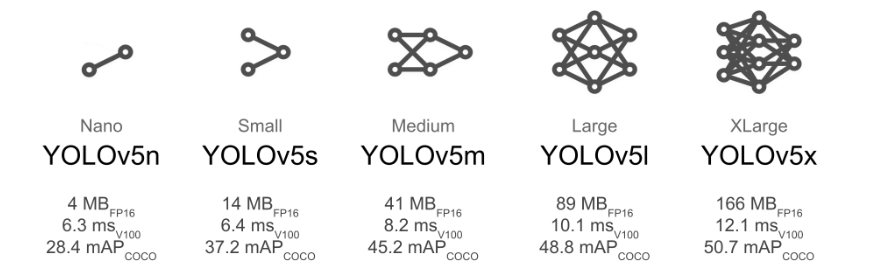
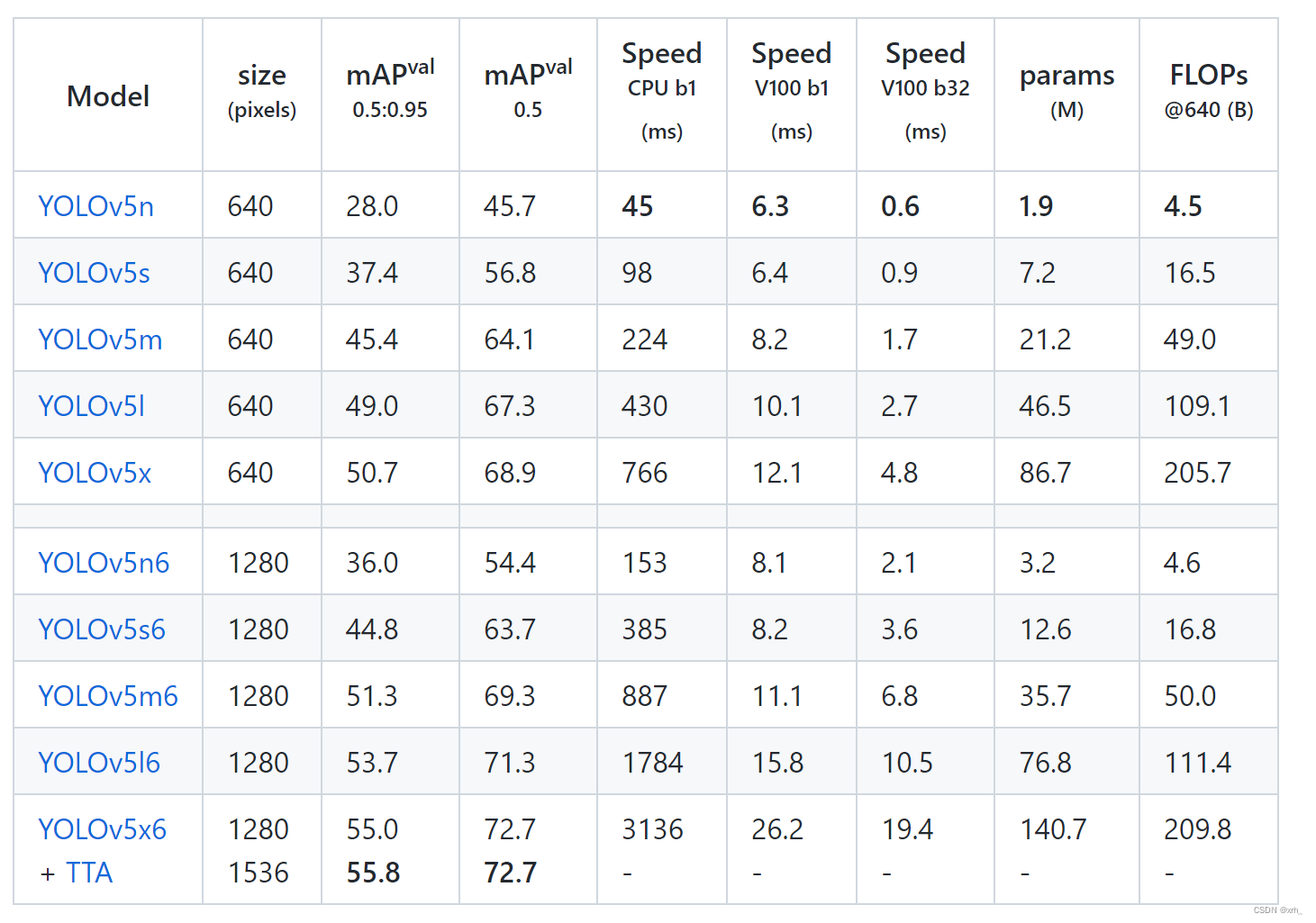
一般考虑在端侧部署的话就用yolov5s,和大模型不少于1b的参数量相比,检测模型的参数量缺少很少。
yolov5代码写的还是很好的,到目前为止,能在k80上分布式DDP无痛跑起来的代码可不多,mm系列都需要稍微改一下。
- main->
- resume->torch.load(last,map_location='cpu')
- DDP->
- device=select_device(device)->
- dist=init_process_group(backend='nccl' if dist.is_nccl_available else 'gloo')->
- train->
- callbacks.run('on_pretrain_routine_start')->
- model=Model(cfg or ckpt['model'].yaml,ch=3,nc=nc,anchors=hyp.get('anchor')),
- to(device)->
- = DetectionModel->model=parse_model(yaml)->
- = initialize_weights()->
- freeze->
- optimizer=smart_optimizer(model,opt.optimizer,hyp['lr0'],hyp['momentum'],
- hyp['weight_decay'])->
- scheduler=lr_scheduler.LambdaLR(optimizer)->
- ema=ModelEMA(model)->
- train_loader,dataset=create_dataloader(train_pathm...)->
- callbacks.run('on_pretrain_routine_end')->
- stopper,stop=EarlyStopping()->
- compute_loss=ComputeLoss(model)->
- callbacks.run('on_train_start')->
- callbacks.run('on_train_epoch_start')->
- model.train()->
- optimizer.zero_grad()->
- callbacks.run('on_train_batch_start')->
- pred=model(imgs)->
- loss,loss_items=compute_loss(pred,target)->
- = tcls,tbox,indices,anchor=build_targets(p,target)->
- loss.backward()->
- callbacks.run('on_train_batch_end')->
- scheduler.step()->
- callbacks.run('on_train_epoch_end')
4.1 在data下新建一个person.yaml
- # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
- path: /home/imcs/local_disk/D0011 # dataset root dir
- train: train_yolo.txt # train images (relative to 'path') 118287 images
- val: val_yolo.txt # val images (relative to 'path') 5000 images
- test: test_yolo.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
-
- # Classes
- nc: 1 # number of classes
- names: ['person'] # class names
4.2 在models更新yolov5s.yaml中,把nc改成类别。
4.3 分布式训练
改一下代码中的device参数,0,1,2,3
python -m torch.distributed.launch --nproc_per_node 4 train.pybatch_size=32,yolov5的代码这块写的很好,即便在k80上也不需要很大的改动。
在8卡k80上,上面这种写法出现了问题,在4卡k80上没有错,很奇怪。
在train.py中添加:
- import torch.distributed as dist
- dist.init_process_group(backend='gloo', init_method='env://')
在527行注释掉,不让dist初始化两次
# dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
在utils的torch_utils.py中
- @contextmanager
- def torch_distributed_zero_first(local_rank: int):
- """
- Decorator to make all processes in distributed training wait for each local_master to do something.
- """
- if local_rank not in [-1, 0]:
- torch.distributed.barrier()
- yield
- if local_rank == 0:
- torch.distributed.barrier()
换成torch.distibuted.barrier()
最终运行:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=1 --node_rank=0 --master_addr=localhost --master_port=22222 train.py 5. 测试
detect.py
- weights/source(支持视频图片url图片集合)/data/imgsz...->
- device=select_device()->
- model=DetectMultiBackend(weights)->
- imgsz=check_img_size(imgsz,stride)->
- dataset=LoadImages()->
- model.warmup()->
- for path,im,im0s,vid_cap,s in dataset->
- = path=files[count]->
- = cv2.imread/cap_read()->
- = letterbox(img0,img_size,stride,auto)[0]->
- = img=img.transpose((2,0,1))[::-1]->
- = img=np.ascontiguousarray(img)->
- pred=model(im,augment)->
- pred=non_max_suppression(pred,conf_thres,iou_thres,classes,agnostic_nms,max_det)->
- annotator=Annotator()->
- annotator.box_label()->
- annotator.result()
300轮:metrics/precision:0.83757,metrics/recall:0.749,map_0.5:0.84328,map_0.5:0.95:0.56934
6.部署(c++)
windows/linux(x86)/linux(arm)树莓派
libtorch/openvino/ncnn/onnxruntime/rknn
https://github.com/leeguandong/Yolov5_rknnlite2![]() https://github.com/leeguandong/Yolov5_rknnlite2 这是我在paddledetection和rknn官方基础上改的,用yolov5在rk3588,使用rknnlite2部署。
https://github.com/leeguandong/Yolov5_rknnlite2 这是我在paddledetection和rknn官方基础上改的,用yolov5在rk3588,使用rknnlite2部署。

