
- 1Ambari——大数据平台的搭建利器
- 2从 keynote 大神到语雀画图大神,她是怎么做的?_语雀 甘特图
- 3中文文本情感分析-python包SnowNLP入门_好用的中文情感分析 python包
- 4菜鸟入门Docker_菜鸟docker
- 5Recognize Anything: A Strong Image Tagging Model
- 6Android修改包名 方法二:不修改文件名,自动配置_app只变更包名 但是源文件名不变
- 7Python数据挖掘——决策树_python决策树的最大深度是什么
- 8【数据结构】考点十九:时间复杂度与空间复杂度_常考空间时间复杂度
- 9Python制作【大麦网】自动抢票程序_python大麦抢票_大麦网自动抢票程序
- 10深度学习 - 激活函数
【大数据基础实践】(六)数据仓库Hive的基本操作_熟悉hive的基本操作(2)_hive建数仓实战
赞
踩

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- * [5.2.1 新建一个数据库;](#521__233)
* [5.2.2 新建表](#522__240)
* [5.2.3 添加分区](#523__246)
* [5.2.4 导入grade\_zqc](#524_grade_zqc_270)
* [5.2.5 统计男、女生人数](#525__281)
* [5.2.6 统计每个学生所有科目的总分以及平均分](#526__288)
* [5.2.7 统计每个科目有多少人以及每个科目平均成绩](#527__295)
* [5.2.8 查询chinese科目得分排前两名学生学号和分数;](#528_chinese_300)
* [5.2.9 创建一个新表rank\_zqc保存CS系每个学生信息和科目总分,按成绩降序排序,并查询结果;](#529_rank_zqcCS_302)
* [5.2.10 统计每个系所有科目平均成绩在所有系中的占比。](#5210__318)
* [5.2.11 统计每个系每个科目考试不合格学生的占比。](#5211__332)
* [5.2.12 删除分区,删除表,删除库,退出Hive。(删除操作请谨慎!)](#5212_Hive_338)
- [5.3 JavaApi进行实验内容](#53_JavaApi_351)
+ [最后](#_414)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1. 数据仓库概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
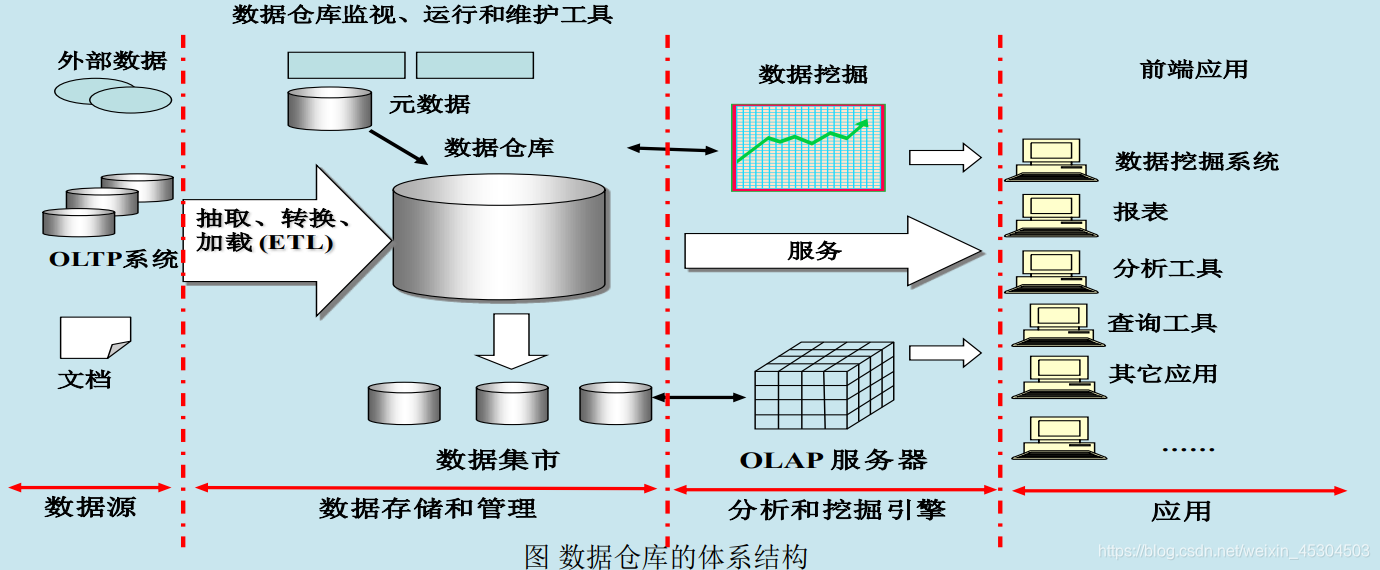
- 数据仓库与传统数据库本质区别
数据仓库中的数据相对稳定,大部分情况下不会发变更,存储大量历史数据;
传统数据库一般只存储某一时刻状态信息,不保存历史数据。
2. Hive简介
2.1 简介
- Hive是一个构建于Hadoop顶层的数据仓库工具
- 依赖分布式文件系统HDFS存储数据,依赖分布式并行计算模型MapReduce处理数据,本身不存储和处理数据(区别:传统数据仓库支持数据存储和处理分析)
- 支持大规模数据存储、分析,具有良好的可扩展性
- 定义了简单的类似SQL 的查询语言——HiveQL/HQL
- 用户可以通过编写的HQL语句运行MapReduce任务
- 可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上
- 是一个可以提供有效、合理、直观组织和使用数据的分析工具
2.2 特性
- 采用批处理方式处理海量数据
- Hive需要把HiveQL语句转换成MapReduce任务进行运行
- 数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
- 提供适合数据仓库操作的工具
- Hive本身提供了一系列对数据进行提取、转换、加载(ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据
- 这些工具能够很好地满足数据仓库各种应用场景
2.3 生态系统
- Hive依赖于HDFS 存储数据、
- Hive依赖于MapReduce 处理数据
- 在某些场景下Pig可以作为Hive的替代工具
- HBase 提供数据的实时访问
- Pig主要用于数据仓库的ETL环节
- Hive主要用于数据仓库海量数据的批处理分析

3. Hive系统架构
- 用户接口模块。包括CLI、HWI、JDBC、ODBC、Thrift Server
- 驱动模块(Driver)。包括编译器、优化器、执行器等,负责把HiveQL语句转换成一系列MapReduce作业
- 元数据存储模块(Metastore)。是一个独立的关系型数据库(自带derby数据库,或MySQL数据库)
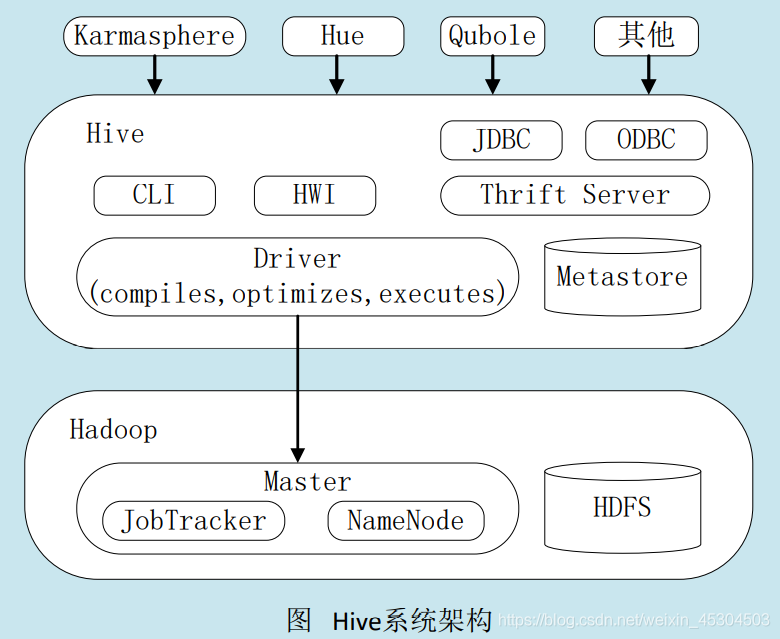
4. HQL转成MapReduce作业的原理
4.1 join的实现原理
select name, orderid from user join order on user.uid=order.uid;
- 1
- 2
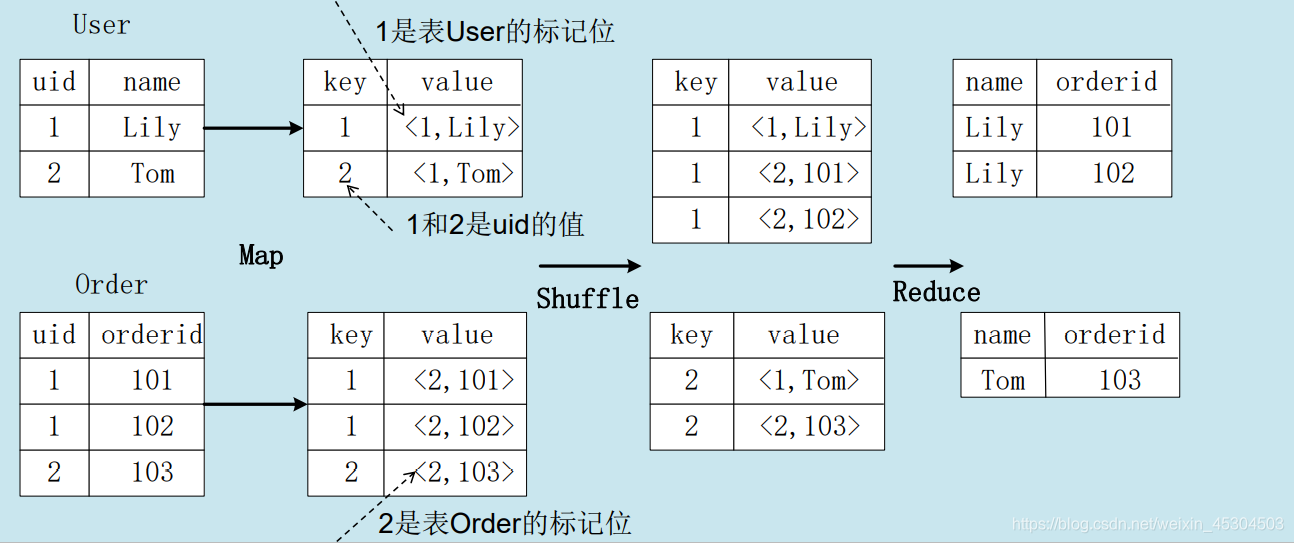
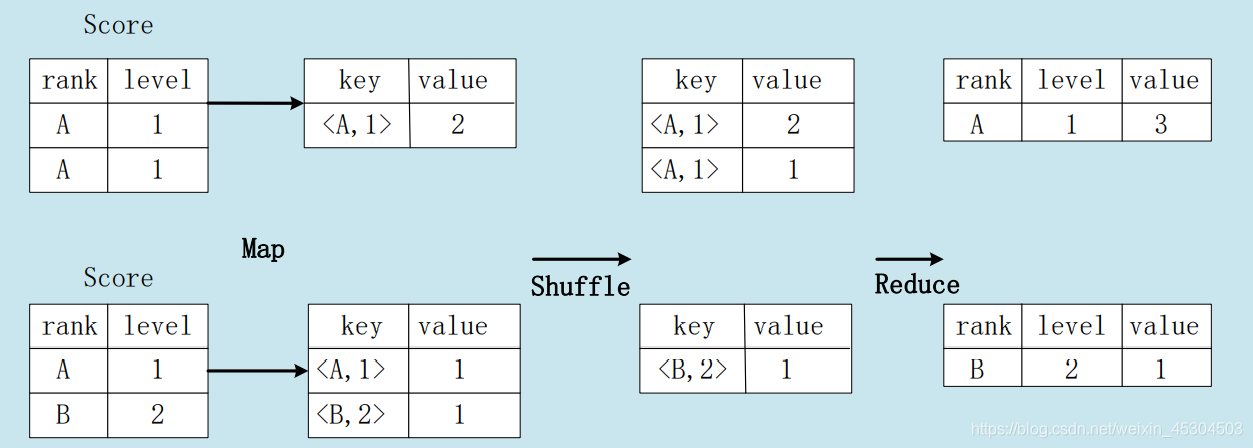
4.2 group by的实现原理
存在一个分组(Group By)操作,其功能是把表Score的不同片段按照rank和level的组合值进行合并,计算不同rank和level的组合值分别有几条记录:
select rank, level ,count(\*) as value from score group by rank, level
- 1
- 2
5. 实验练习
5.1 环境配置
5.1.1 HIVE
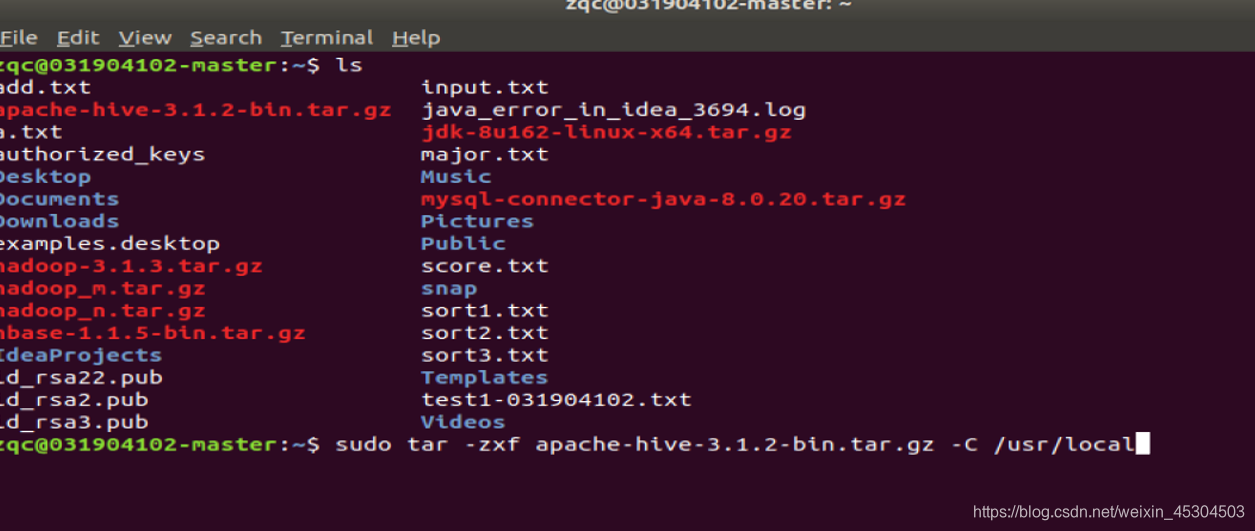
将Hive解压到/usr/local中

更改名字

更改hive目录所有者和所在用户组

环境配置

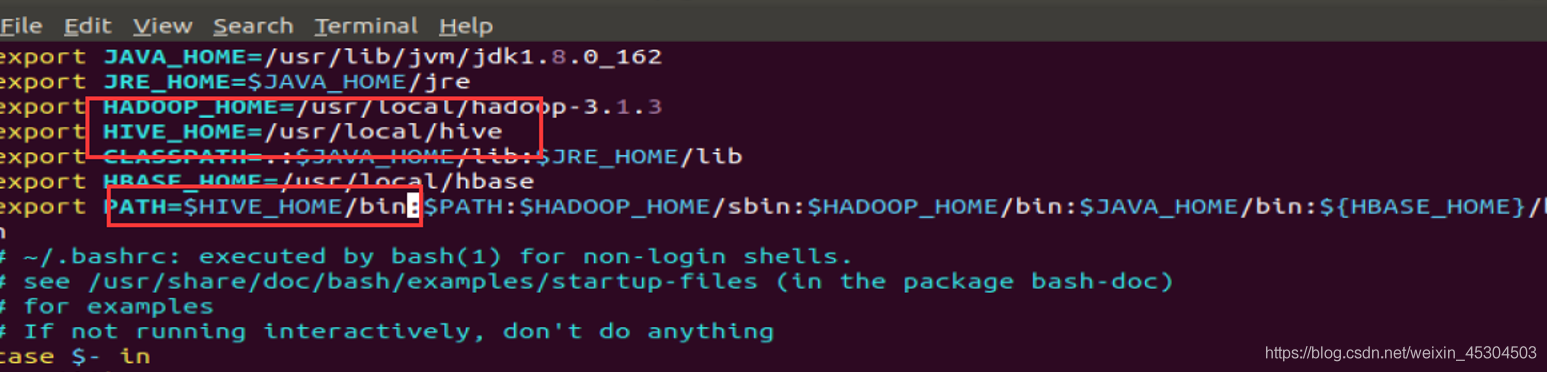
使环境生效

5.1.2 MYSQL
更新软件源
安装mysql-server
安装成功
确定mysql服务是否打开

启动和关闭mysql服务
- 关闭
service mysql stop
- 1
- 2
- 启动
service mysql start
- 1
- 2
5.1.3 配置MySql为hive元数据存储数据库
进入mysql shell
sudo mysql 或 sudo mysql –u root –p 命令,回车后会提示输入密码,前者输入当前系统用户密码,后者是输入 mysql root 用户密码一般为空,回车进入 mysql 命令行。这里 root是 mysql 安装时默认创建的用户,不是 Ubuntu 系统的 root 用户。
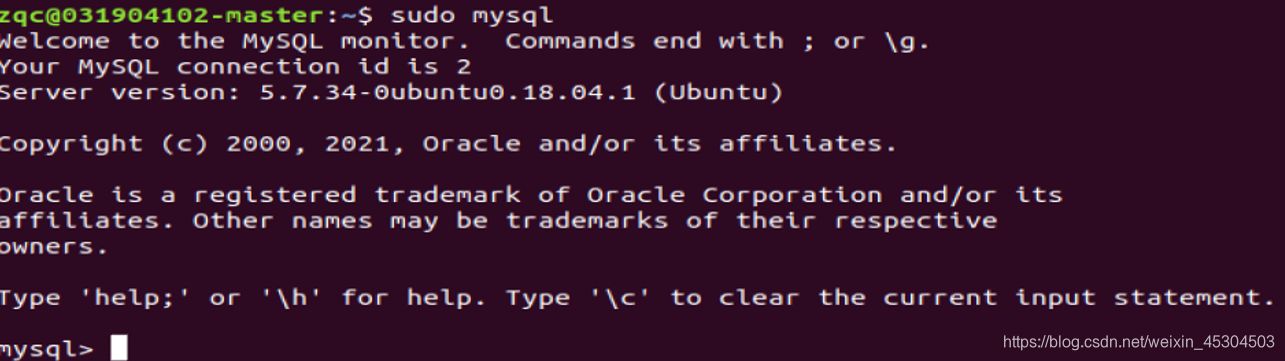
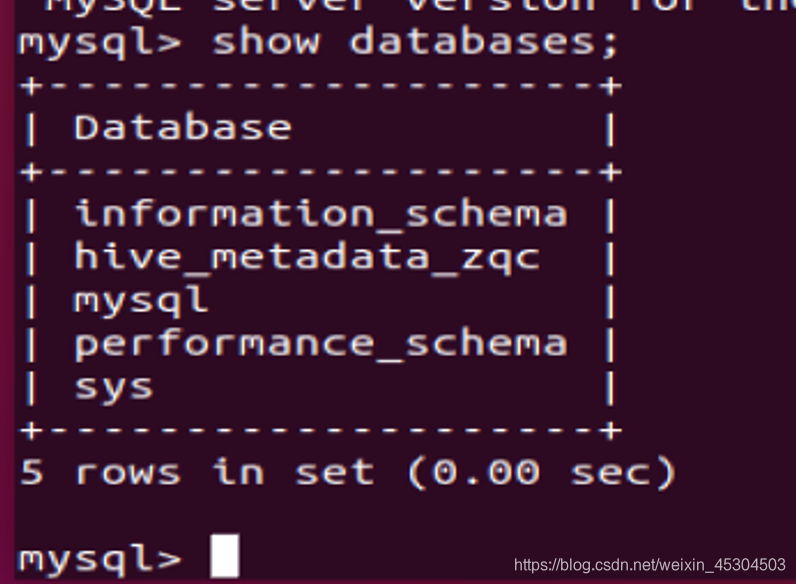
新建一个数据库用来保存hive元数据(hive_metadata_zqc)

- 配置mysql允许hive接入

将所有数据库的所有表的所有权限赋给新建的hive_zqc用户,hive_zqc、'hive’是后续操作中要对 hive-site.xml 文件配置的连接到 MySQL 数据库的用户名、密码,由你自己定义;
刷新mysql系统权限关系表

exit 退出
2. 配置hive
下载mysql jdbc包https://dev.mysql.com/downloads/connector/j/ ;


解压jdbc包后,将其中的jar包拷贝至hive安装目录下lib文件夹中

进入/usr/local/hive/conf 目录。将hive-default.xml.template 重命名为hive-default.xml 保存着各个配置参数的默认值。

新建一个hive-site.xml 配置文件,并添加如下内容,该文件内容会覆盖原默认值

箭头标记处说明:hive_metadata_zqc 是前面步骤 MySQL 里新建的 database、hive_zqc和 hive 是连接数据库的用户名以及密码;

<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_metadata_zqc?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive_zqc</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 初始化元数据库,启动 Hive,进入 Hive 运行时环境
初始化元数据库,不然有可能会报错。

可能出现错误

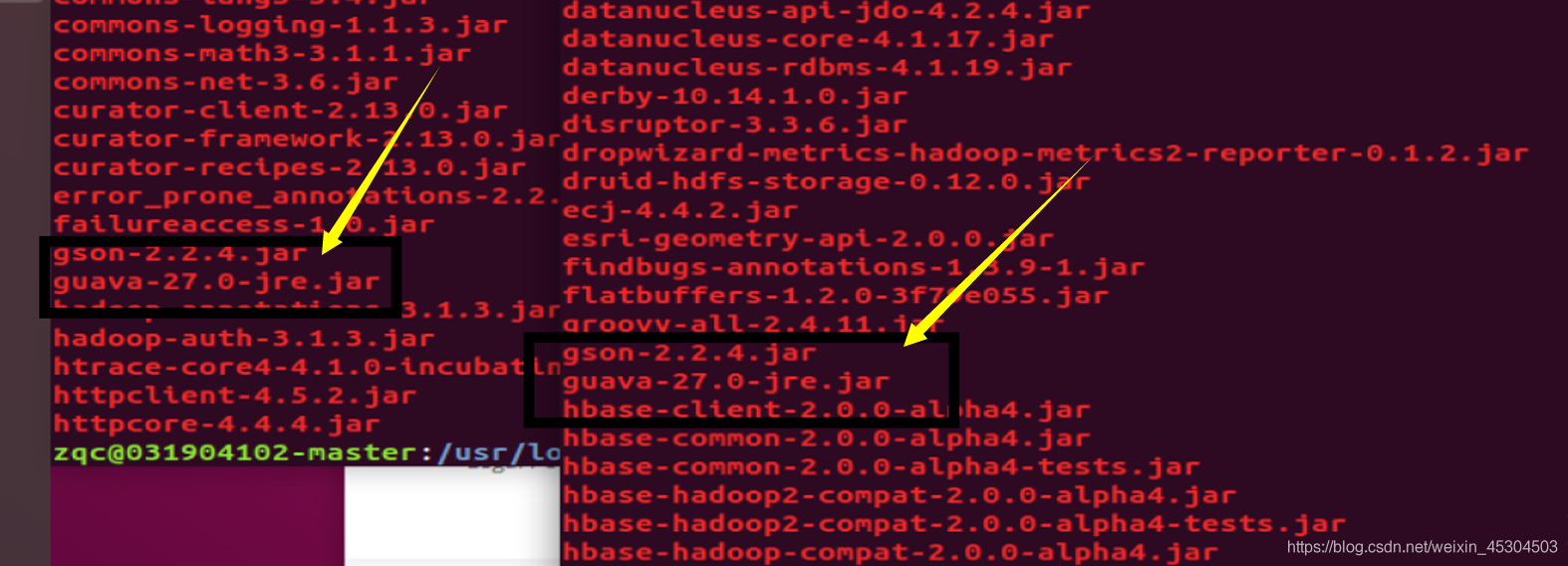
原因:com.google.common.base.Preconditions.checkArgument 这是因为 hive 内依赖的 guava.jar 和hadoop内的版本不一致造成的。
解决方法:查看hadoop安装目录下 share/hadoop/common/lib 内 guava.jar 版本,查看 hive安装目录下lib内guava.jar的版本,如果两者不一致,删除版本低的,并拷贝高版本的。

两个版本一样了
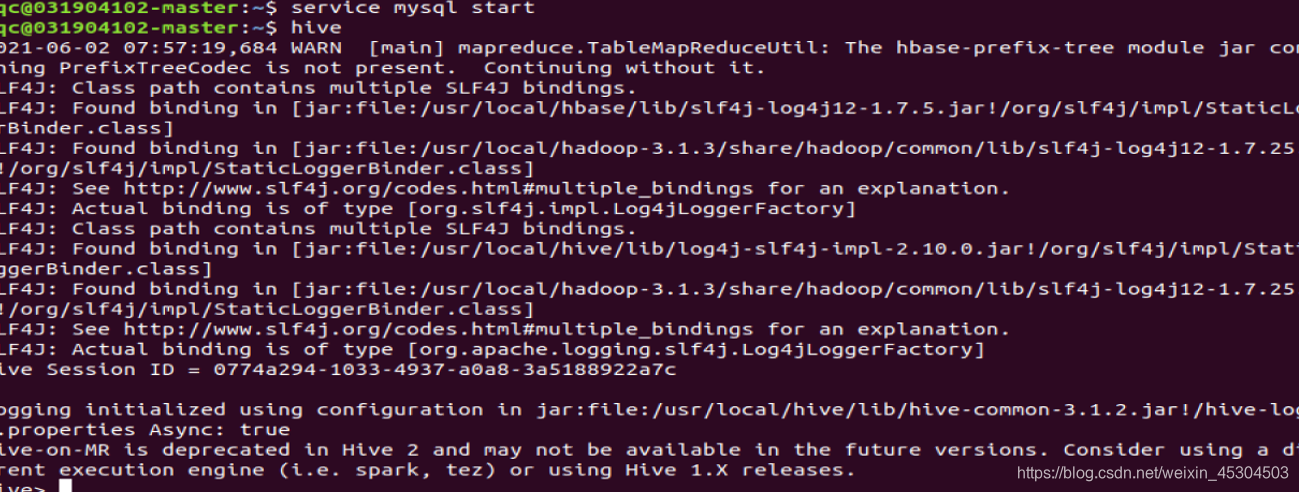
在进行一次初始化元数据库

成功了!
4. 启动Hive
启动hive 之前,请先启动hadoop集群(start-dfs.sh)和确保MySQL服务正常运行。“hive”命令启动 hive。
启动hadoop集群

启动mysql

启动hive
5.2 Shell进行实验内容
表1 student_zqc:
| Name | Sex | Birth | Dept | Uid |
|---|---|---|---|---|
| Liuyi | F | 2002/11/26 | CS | 180301 |
| Chener | F | 2001/6/11 | CS | 180302 |
| Zhangsan | M | 2002/9/21 | CS | 180303 |
| Lisi | F | 2001/1/26 | SE | 180201 |
表2 grade_zqc:
| Uid | Course | Grade |
|---|---|---|
| 180301 | Chinese | 90 |
| 180301 | Math | 58 |
| 180301 | English | 39 |
| 180302 | Chinese | 91 |
| 180302 | Math | 95 |
| 180302 | English | 75 |
| 180303 | Chinese | 60 |
| 180303 | Math | 58 |
| 180303 | English | 53 |
| 180201 | Chinese | 62 |
| 180201 | Math | 43 |
| 180201 | English | 74 |
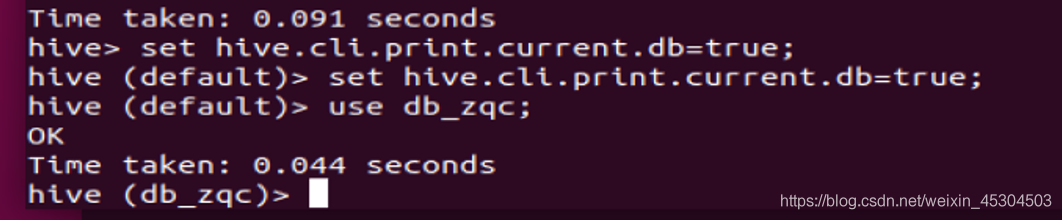
5.2.1 新建一个数据库;
新建一个数据库db_xxx,添加扩展参数:日期、学号、姓名;使用该数据库做后续操作;设置命令行显示当前使用的数据库,请保证后续操作都能显示。
创建的时候添加了日期,学号,姓名,以及存放路径

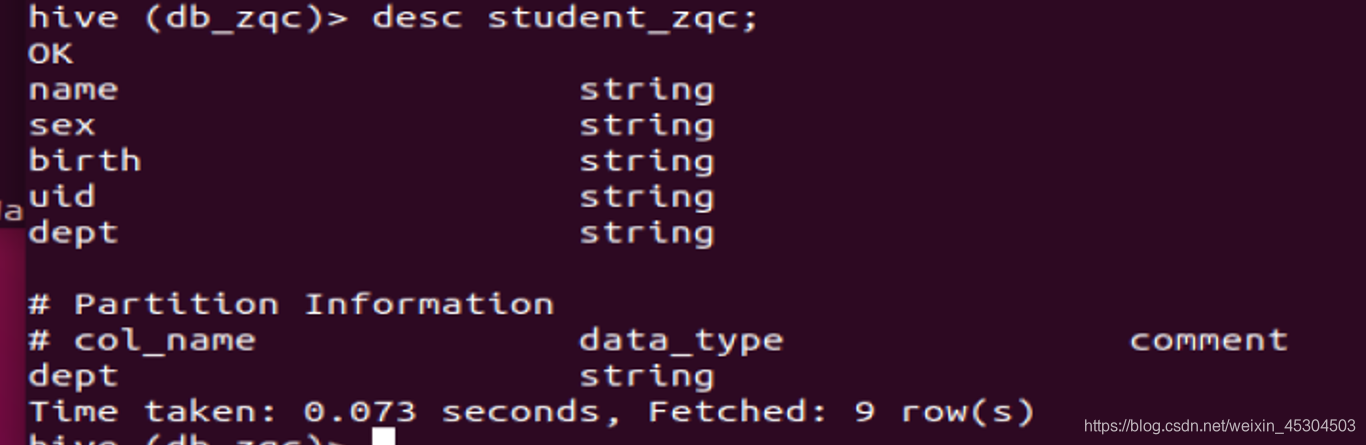
5.2.2 新建表
新建student_xxx分区表(分区字段Dept)和grade_xxx内部表,分别查看表结构和存储路径;(字段类型自定义)


5.2.3 添加分区
在表student_zqc中添加两个分区Dept=’CS’和Dept=’SE’,从本地导入数据到student_xxx表的两个分区中,分别查看两个分区所有记录,查看表数据存储目录;

从文件中加载数据,load data
语法 :
   **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)** F,t_70) 从文件中加载数据,load data 语法 :
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
[外链图片转存中…(img-K13CpJKT-1715711505849)]
[外链图片转存中…(img-Kaz8V6oC-1715711505850)]
[外链图片转存中…(img-tUk4GfRF-1715711505850)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

