
- 1蓝易云 - ROS2错误排查:解决cv_bridge与opencv版本不匹配问题。
- 2WebGL可视化地球和地图引擎:Cesium.js_cesium webgl2
- 3elasticsearch快照生成与恢复
- 4家居建材商城|商家店铺|基于Springboot+Vue实现家居建材商城_vue商城商家端
- 5【OpenStack(Train版)安装部署(十三)】之win7虚拟机创建,指定卷制作,挂载测试_libvirt can't honour user-supplied dev names
- 6Git 仓库中文件名大小写问题_git 大小写
- 7知识图谱-neo4j入门_neo4j图谱分析实战入门门槛
- 8Mysql 并发update死锁_error updating database. cause: com.mysql.cj.jdbc.
- 9【协同任务】基于matlab改进的灰狼算法多无人作战飞机协同航迹规划【含Matlab源码 2470期】_多无人机航迹规划算法代码
- 10JDK8新特性 - Lambda表达式_jdk8有lamda表达式吗
【大模型 知识图谱】ChatKBQA:KBQA知识图谱问答 + 大模型_如何使用知识图谱对大模型答案进行相关性校验
赞
踩
论文:https://arxiv.org/abs/2310.08975
代码:https://github.com/LHRLAB/ChatKBQA
提出背景
用生成再检索代替检索再生成。
传统的KBQA方法是先检索相关信息,然后基于这些信息生成回答。
这种方法效率低下,因为它需要在大量的数据中进行检索。
ChatKBQA改变了这个流程,先通过大型语言模型(LLM)生成一个问题的逻辑形式,再去检索与逻辑形式匹配的具体实体和关系。
这样做提高了检索效率,因为直接生成的逻辑形式更准确地指向了需要检索的信息。
假设用户想知道:“阿司匹林用于治疗哪种疾病?”这是一个典型的知识库问答(KBQA)任务,需要准确地从医学知识库中检索信息。
传统方法处理流程
- 实体识别和链接:首先,系统需要识别“阿司匹林”为药物实体,并尝试将其链接到知识库中的对应实体。
- 关系识别:然后,系统需要理解用户询问的是关于“治疗”这一动作的信息,这需要复杂的自然语言处理技术来识别“治疗”为关系。
- 检索和答案生成:最后,系统根据识别的实体和关系,在知识库中检索相关信息,并生成答案。
ChatKBQA处理流程
-
逻辑形式生成:ChatKBQA利用fine-tuned的LLM直接将问题“阿司匹林用于治疗哪种疾病?”转换为准确的逻辑形式,如“(treats ‘Aspirin’ ?disease)”。
能够精确匹配到问题中的关键实体和时间,提高了检索的准确性和相关知识的覆盖范围。
这个步骤快速准确地缩小了搜索范围。
避免了在庞大的知识库中进行广泛的搜索,直接锁定相关的实体和关系,显著提高了检索效率。
-
无监督检索:然后,ChatKBQA使用先进的无监督检索技术,如SimCSE,直接在知识库中寻找符合逻辑形式的实体和关系,无需复杂的实体和关系识别步骤。
-
答案生成:最后,基于检索到的准确信息,ChatKBQA生成答案,如“心脏病”。
生成的SPARQL查询不仅精确反映了用户的查询需求,还能通过知识图谱的查询路径提供清晰的解释性,如通过查询路径展示两者的直接关联。
用户不仅得到了准确的答案,还能理解答案的来源和逻辑,减少了对答案的疑惑,提高了用户的信任度。
对比优势
- 效率:ChatKBQA通过直接生成逻辑形式和利用无监督检索技术,大大简化了查询过程,提高了检索效率,而传统方法需要经过多步骤的实体和关系识别,效率较低。
- 准确性:ChatKBQA利用LLMs的强大语义理解能力,能更准确地理解用户的查询意图,并通过无监督检索精确地匹配知识库中的信息,减少了因实体和关系识别错误导致的误检。
- 可解释性:ChatKBQA生成的答案是基于明确的逻辑形式和知识库查询路径的,这为用户提供了答案来源的透明度和可解释性,而传统方法可能因复杂的中间处理步骤而难以追踪答案来源。
ChatKBQA在处理效率、准确性和可解释性方面相较于传统KBQA方法的显著优势。
ChatKBQA能够更直接、准确地理解和回答复杂的医学查询,是利用最新NLP技术优化知识库问答系统的一个典范。
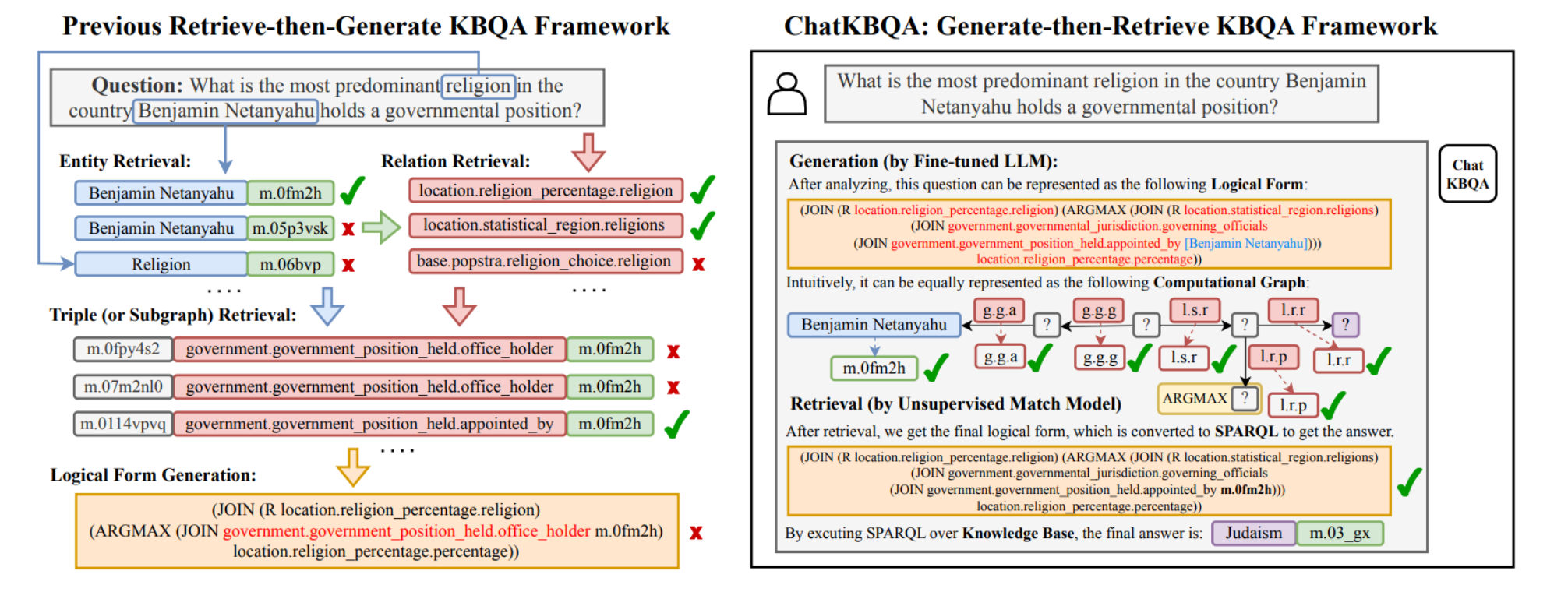
这图展示了传统的“检索-然后-生成”知识库问答(KBQA)框架与ChatKBQA的“生成-然后-检索”框架之间的对比。
左侧:传统的检索-然后-生成框架
- 展示了处理一个问题(例如,Benjamin Netanyahu在哪个国家担任政府职位的宗教信仰是什么?)的传统步骤:
- 实体检索:首先尝试找到与问题相关的实体标识符(如Benjamin Netanyahu)。
- 关系检索:接着检索与问题相关的关系(如政府职位或宗教信仰)。
- 三元组/子图检索:然后检索相关的三元组或子图。
- 逻辑形式生成:最后根据检索结果生成逻辑形式,这可能会包含错误,因为是基于不完全准确的检索结果。
右侧:ChatKBQA的生成-然后-检索框架
- 显示了ChatKBQA框架的步骤:
- 生成:首先,使用fine-tuned的LLM根据问题直接生成逻辑形式。
- 直观计算图:然后构建一个直观的计算图表示,这有助于理解如何从问题到逻辑形式的转换过程。
- 无监督匹配模型检索:使用无监督的方法检索与生成的逻辑形式相匹配的实体和关系。
- 最终逻辑形式:基于检索到的信息更新逻辑形式,并转换为SPARQL查询以获取答案。
这两个框架的主要区别在于处理的顺序和方法。
ChatKBQA采用先生成逻辑形式再进行检索的方法,而传统方法是先检索实体和关系再生成逻辑形式。
ChatKBQA的方法可以减少因错误检索信息而导致的逻辑形式生成错误的可能性,并且能够更直接地利用LLMs的强大语义理解能力。
总结
ChatKBQA 为什么被拆解成这些特定的子解法?
整个解题步骤是:从理解问题到找到答案,再到解释答案的过程。
-
逻辑形式生成(直接语义映射):首先,我们需要理解用户的问题。
这就像是读懂一个复杂问题的第一步,把它翻译成一种计算机能理解的“逻辑形式”。
这一步骤跳过了传统的实体和关系识别过程,直接利用大型语言模型的能力将问题转化为结构化的查询,就像是用直接的方式把问题翻译成计算机语言。
-
无监督实体和关系检索(无监督语义检索):有了这个“逻辑形式”,我们接下来要在知识库中找到匹配的信息。
这一步就像是在图书馆里根据索引卡找到你需要的书一样,但是更高级,因为它用的是无监督学习的技术,可以在没有明确指导的情况下找到正确的信息。
-
参数高效的微调(精细化参数调优):为了确保这个过程既准确又高效,我们还需要确保我们的工具(即大型语言模型)针对这个特定任务是最佳状态。
这就像是调整你的搜索工具,确保它既不会错过重要信息,也不会浪费时间在不相关的信息上。
-
GQoT 可解释的查询执行:最后,当我们找到了答案,我们还需要能够解释我们是怎么得到这个答案的。
这就像是不仅给你答案,还要告诉你答案的来源,让整个过程对用户来说是透明的,增加了用户对答案的信任。
ChatKBQA框架概览
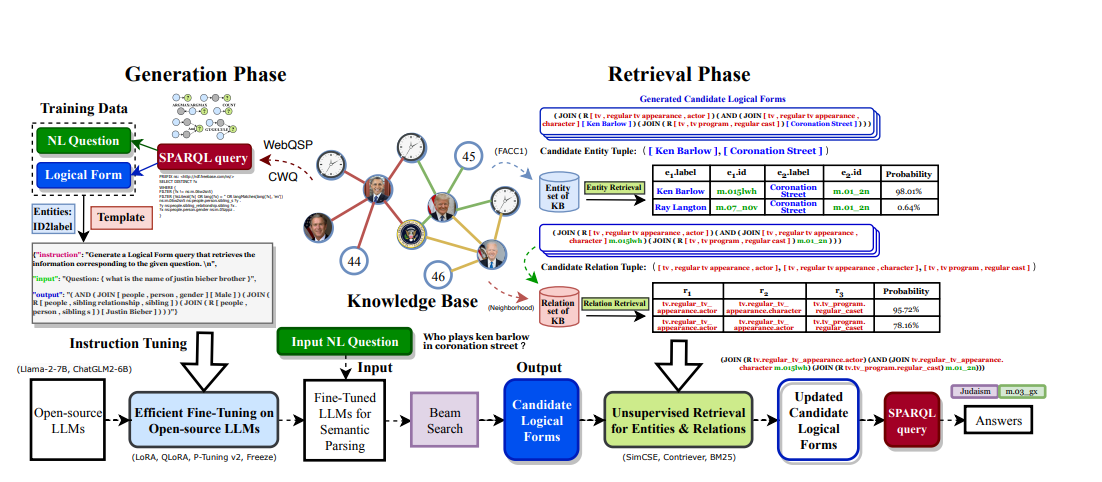
生成阶段
- 说明了ChatKBQA如何使用训练数据(自然语言问题与对应的逻辑形式)通过指令调优来fine-tune开源LLMs。
- 展示了输入的自然语言问题是如何经过fine-tuned的LLM和beam search来生成候选的逻辑形式。
检索阶段
- 展示了如何从知识库中检索与候选逻辑形式相匹配的实体和关系。
- 介绍了无监督检索的使用,如SimCSE、Contriever和BM25,来优化逻辑形式,并最终生成可以执行的SPARQL查询。
这张图提供了一个整体的流程图,说明了从用户输入问题到获取答案的整个过程,包括使用LLMs生成逻辑形式,以及后续的无监督检索步骤,最后形成可执行的查询以提供答案。
特征1:逻辑形式生成
- 描述:使用大型语言模型(LLM)将自然语言问题转换成逻辑形式。这个过程利用了LLM的语义理解能力,通过指令调优(Instruction Tuning),训练模型能够理解问题并生成一个精确的逻辑形式表达,如S-expression或其他结构化表示。
- 方法名称:语义解析优化(Semantic Parsing Optimization)
- 新方法:如果传统方法主要依赖手工规则或复杂的算法转换,ChatKBQA则使用直接的语言模型生成,我们可以称之为“直接语义映射(Direct Semantic Mapping)”。
特征2:无监督实体和关系检索
- 描述:在生成逻辑形式后,ChatKBQA采用无监督方法进行实体和关系的检索。这一步骤不依赖于大量标注数据,而是利用现有的知识库结构和内容,通过语义相似性匹配来查找和逻辑形式中相对应的实体和关系。
- 方法名称:高效知识检索(Efficient Knowledge Retrieval)
- 新方法:相较于传统的基于规则或监督学习的检索,这里的“无监督语义检索(Unsupervised Semantic Retrieval)”方法更加灵活和准确。
特征3:参数高效的微调
- 描述:为了适应特定的KBQA任务,ChatKBQA在大型语言模型上进行参数高效的微调。通过技术如LoRA、QLoRA、P-Tuning v2等,只微调模型的一小部分参数,既保持了模型性能,又大幅减少了计算资源的消耗。
- 方法名称:参数高效微调(Parameter-Efficient Fine-Tuning)
- 新方法:这种微调方法比全模型微调(Full Model Fine-Tuning)更加资源高效,可以称为“精细化参数调优(Fine-grained Parameter Optimization)”。
特征4:GQoT 可解释的查询执行
- 描述:将生成的逻辑形式转换成可执行的SPARQL查询,并在知识库上执行,获取答案。这个过程不仅提供了准确的答案,还能通过查询的结构和逻辑提供答案的解释,增加了用户对结果的信任。
- 方法名称:可解释性增强(Enhanced Interpretability)
- 新方法:如果传统KBQA系统往往难以提供答案的详细解释,ChatKBQA的“查询路径可视化(Query Path Visualization)”提供了一种新的可解释性增强方法。
GQoT(Graph Query of Thoughts)是一个新概念,将知识图谱查询看作是大型语言模型思考的过程。
这意味着模型生成的查询不仅仅是用于检索数据,而是反映了模型对问题的理解和解答思路。
通过这种方式,结合LLM和知识图谱(KG)的优势,实现了一种新的协同推理问答模式,不仅能给出答案,还能提供推理路径,增强了答案的可解释性。
特征5:错误减少和避免
- 描述:利用LLM生成的逻辑形式和无监督检索减少了因实体识别错误或关系映射不准确导致的错误。此外,通过可解释的查询执行,用户可以更容易地验证答案的正确性。
- 方法名称:错误减少机制(Error Reduction Mechanism)
- 新方法:与传统方法相比,这里的“动态错误校正(Dynamic Error Correction)”为ChatKBQA特有,强调在整个KBQA流程中动态减少和校正潜在的错误。

