
- 1再说机器学习
- 2个人笔记:chatterbot聊天机器人(一)——chatterbot安装与训练
- 3sklearn feature extraction_sklearn.feature_extraction
- 4P8709 [蓝桥杯 2020 省 A1] 超级胶水
- 5爬虫工作量由小到大的思维转变---<第六十七章 > Scrapy异常处理中的核心异常类型
- 6基于关键点的车道线检测_基于关键点检测的车道线检测模型
- 7基于ChatGLM2和OpenVINO™打造中文聊天助手_openvino中文聊天助手
- 8Self-Consistency Improves Chain of Thought Reasoning in Language Models阅读笔记
- 9ffmpeg播放及回放rtsp视频流_ffmpeg mp4 rtsp linux
- 10php 任务框架,计划任务的使用 ThinkCMF内容管理框架,做最简约的ThinkPHP开源软件...
多模态机器学习入门——文献阅读(一)Multimodal Machine Learning: A Survey and Taxonomy_multimodal machine learning:a survey and taxonomy
赞
踩
说明
- 这篇文章是对之前上课内容的一个更加具体的总结,并加上了相关的文献。
- 其实这个文献是2017年的,我认为还是比较老的,后来又找到一篇2022年的,这里还是翻译了最新篇的文章。
论文阅读
Abstract
- 我们对于世界的认知是多模态的,我们看见不同的事物,听到不同的声音,感受不同的肌理,闻不同的气味,品尝各色各样的美味。模态就是我们认识了解外界的一种方式,如果一种研究是包含多种模态的,那么这个研究就是多模态的。对于人工智能而言,如果要更好地理解世界,就需要能够同时处理多中模态中的信息。由此衍生出多模态机器学习,这个学科是一个多学科交叉的领域,并且变得越来越重要。与专注于某一领域的应用相反,我们这篇文章将会调查多模态研究的最新进展,并将之进行分类,除此之外,我们还总结出多模态中经常遇到的物种核心挑战,分别是:repersentation(表示),translaltion(转换),fusion(融合),alignment(对齐),和co-learning(共同学习)。这种分类有助于研究者更好理解多模态领域的最新技术和未来研究方向。
Introduction
-
围绕我们的世界有很多模态,我们看事物,听声音,感受肌理,闻气味等。一般来说,模态就是事物发生方式。大部分人都将之于感官模态进行关联,这些感官模态就是我们进行交流和感觉的主要方式。因此,如果研究或者数据集涉及到多个模态,就会被分为多模态研究。本文仅仅会关注三种模态,用来说或者是写的自然语言,在图片或者视频中表示视觉信号,用来对声音进行编码的音频。
-
为了使人工智能能够更好的理解我们的世界,我们需要将多模态信息进行理解和推理。多模态机器学习的目标就是建造一个能够处理和连接多种模态中的信息的模型。从早期的音视频识别,到最近语言模型和视觉模型的蓬勃发展,多模态机器学习已经变为一个丰富的多学科领域,并且变得越来越重要,具有非凡的潜力。
-
因为多模态的数据具有异构性,所以多模态机器学习对于计算研究人员有很多考验。从多模态数据源中进行学习,使得我们有可能学到模态与模态之间的关联性,对于自然现象理解更加深刻。本文将会列举并探索围绕机器学习的五个核心技术挑战,他们是多模态的核心,也是推进多模态技术进一步发展的核心。我们的分类如下
- Repersentation 第一个基本挑战就是,**学习如何使用一种探索了多种模态的互补性和冗余性的方式去表示和总结多模态数据。**因为多模态数据是异构的,所以构建这样一种表示本身就具有挑战性。比如说,语言是象征性的符号,视觉和音频模态是实际的信号。
- Translation **第二个挑战是解决如何将一种模态信息转变为另外一种模态信息。**模态与模态之间不仅是异构的,同时还具有一定的联系,这种联系一般是开放式的或者主观的。比如说,表示一张图片的方式有很多种,但但是没有一种是完美的。
- Alignment **第三个挑战的目标是,识别出不多个模态的元素之间的直接联系。**比如说,我们可能会将一个食谱中的某一步,和一个制作蛋糕的视频进行关联对齐。为了处理这种问题,我们需要测量不同模态之间的相似性,处理可能的长期依赖和随机性。
- Fusion **第四个挑战的目的是,融合多个模态,去完成预测。**比如说,对于音视频识别而言,嘴唇的动作和音频信号进行融合,去预测说出的话。来自不同模态的信息,会有不同的预测力量和噪声结构。
- co-learning **第五个挑战就是在不同模态之间,不同表示之间以及不同预测模型之间,传递知识。**以算法进行举例,比如说,共同训练,概念基础,零样本学习等。共同学习的目的是,探索如何实现将从一个模型中学到的知识,应用到不同模态的模型训练过程。当某一个模态的数据资源是有限时,这个挑战就尤为重要。
-
为了能够更好地帮助读者对于多模态机器学习研究领域中最近的工作有一个结构性的认知,我们将上述五个挑战进行分类,并在各自的类别中进行子分类。本文首先在第二部分介绍多模态机器学习的主要应用,然后讨论五个核心挑战最近的研究进展。
Introduction总结
- 多模态很重要,研究多模态需要掌握五个技术,分别是representation,alignment,fusion,translation和co-learning,具体定义看上半部分加粗的部分。
Applications:A Historical Perspective
AVSR 音视频语音识别
- 多模态机器学习应用很广泛,从音视频语音识别到图片注释生成等领域都有。这部分将会简单介绍一下多模态应用的历史,从最初的音视频语音识别到最近兴起的语音视觉应用。
- 多模态研究领域最早的应用样例,就是音视频语音识别(AVSR),这个是由McGurk效应启发的。当你听着“baba”的音频时,看着‘gaga’的嘴型,你会接收到‘dada’的声音。这个结果启发很多声音领域的研究者,将视觉信息纳入到他们的研究中。鉴于当时的在语音领域隐马尔科夫模型的突出地位,当时很多AVSR的研究都是基于不同**隐马尔科夫模型(HMMs)**的扩展。虽然对于AVSR的研究现在不是很常见,因为已经很成熟了,但是在深度学习领域,这个研究又再度兴起。
- 虽然AVSR的最初版本是以提高任何情况下的语音识别效果为目的,但是实际结果却表明视觉信息仅仅是在语音信息有噪声的情况下有用。换句话说,我们所获得的两个模态之间的连接是附加的,并不是互补的。分别在视频和音频中获得的信息是完全相同的,仅仅会提高多模态模型的鲁棒性,并不会提高在噪声环境下的语音识别性能,使其识别的更快。
- 如果想运行一下对应的项目,看一下效果,可以参见对应的连接。
multimedia content indexing and retrieval多媒体内容索引和检索
- 多模态应用的第二个重要领域是多媒体内容检索和索引。个人电脑和网络快速发展,使得数字化多媒体内容的数量急剧增加。虽然早期针对视频的检索和索引都是基于关键字的,但是如果你要直接处理视觉信息或者多模态信息的内容时,就会遇到很多问题。故而在多媒体内容分析领域产生了很多新的研究话题,比如说自动镜头边界检测和视频总结等
understanding human multimodal behaviour 理解人类多模态行为
- 第三类应用,是在2000年代初,围绕新兴的多模态交互领域建立的,目标是了解社交交互过程中的人类多模态行为。这个领域最具有标志性的数据库之一就是AMI会议记录语料库,包含了100个小时的会议视频记录,并且全程都有记录和标记。另外一个重要的数据集是SEMAINE语料库,让你能研究说话双方的动态变化。这个数据集是2011年第一届情感视听挑战赛(AVEC)的基础。情感识别和情感计算领域在2010年前后发展火热,是因为自动脸部识别、面部特征检测和面部表情识别的强大技术优势。除此之外,还有应用于健康领域的抑郁症和狂躁症的自动检测。D‘Mello等人发表了关于多模态情感识别的最新进展的重要总结A Review and Meta-Analysis of Multimodal Affect Detection Systems。他们的分析指出,当我们涉及到多中模态时,最近的关于多模态情感识别的很多研究有很多改进,但是当应用到自然表情时,这个改善就会大打折扣。
** media description 多媒体描述**
- 最近新出现的多模态应用都是以语言和视觉为重心:媒体描述生成media description。其中最具有代表性的是图片注释生成,就是根据输入图片生成文字描述。这个主要是为了方便视觉障碍人士生活。这个任务的关键问题就是评估,你并不知道你生成的描述好坏。可视化问答是为了解决一些评估挑战,目标是回答有关图片的特定问题。
- 图片描述生成image captioning的体验链接 ,这个连接可以试一下,自己根据论文进行复现一下
- visual question-answering(VQA)可视化问答的体验连接 ,没怎么做过,可以自己去复习一下
总结
- 为了将我们之前提到的很多应用投入到实际使用中,我们需要解决一些多模态机器学习的技术挑战,我们将那些挑战罗列在表格1中。对重要的挑战之一就是多模态的表示,下部分介绍。
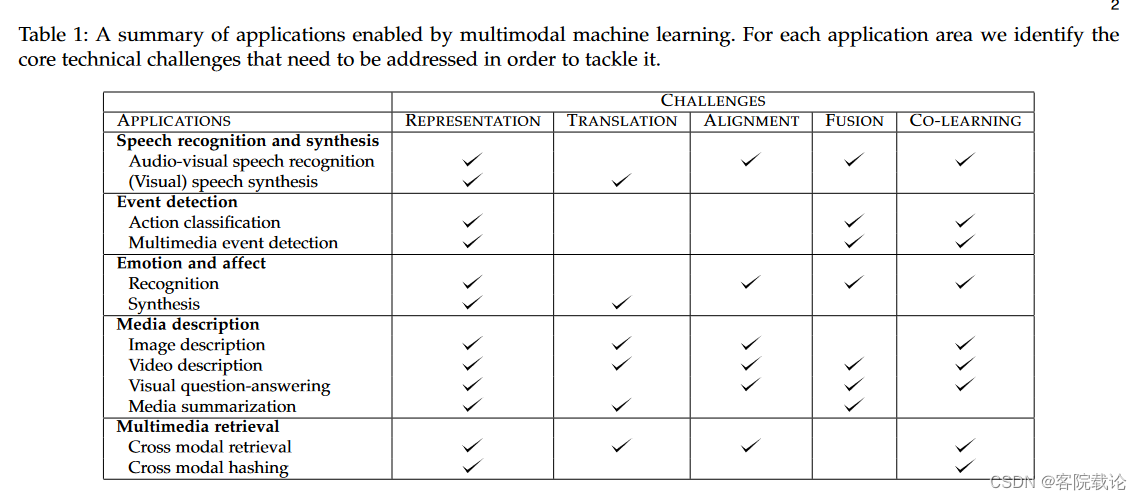
补充与总结
- 总结 这部分讲了多模态机器学习的具体应用,各个方向我也罗列在上面了,然后具体的一些应用连接在各部分都有连接。
- AVSR那里可以找到具体的模型,想去实现一下,重点看一下他们是如何实现将视频信息和语音信息进行融合的,相关的项目和文章都找到了,后续可以去读读看。
3 MULTIMODAL REPRESENTATIONS
- 表示原始数据,并且使得计算模型也能使用,对于机器学习而言,十分困难。按照Bengio的文章,我们将特征和表示两个术语混用,每一个都指一个实体的向量或者张量表示,无论这个实体是图片、音频信息、单词和句子。一个多模态表示是用来同时表示来自这样多个实体中的数据。其中的困难有如下几点:(1)如何将来自异构数据源的数据进行组合;(2)如何处理不同层次的噪声;(3)如何处理不同模态的丢失数据。有效表达数据的能力是多模态问题的关键, 也模型的基础。
- 一个好的模型对于机器学习模型而言,十分重要,最近的语音识别和目标识别的性能飞跃可以证明。Bengio等人指出了一个好的表示应该具有一下特征 :光滑,时间和空间协调,稀疏,和自然聚集等 ,Srivastava和Salakhutdinov 的等人指出了多模态属性的其他理想属性 : (1)表示空间中的相似性,要能反映不同模态对应概念的相似性,(2)即使确实一些模态,这种表示也能很容易获得,(3)能够根据观察到的模态,补全缺失的模态。
- 对于单模态表示的研究已经很广泛了,过去十年之间,表示生成已经由最初的针对特定应用的手工生成,变为有数据驱动自动生成。比如说,2000年代最著名的描述符之一,尺度不变特征转换(SIFT)就是手工设计的,但是现在大部分视觉描述符都是使用想卷积网络的神经网络结构从数据中学到的。相似的,在音频领域也是这样的,当时很牛逼的声音特征MFCC就被语音识别领域的数据驱动的深度神经网络和用于副语分析的递归神经网络取代了。无独有偶,在文字处理领域也是这样的,原来文本特征是用单词出现的次数来表示的,后来就用数据驱动的,能够包含上下文信息的单词嵌入(word embedding)表示。虽然现在关于单模态的表示研究工作已经很多了,但是直到现在,大部分多模态表示都是对单模态表示的简单串联,不过未来一定会快速发展。
- 为了能更好地了解多模态研究的宽度,我们将多模态表示分为两类, ** 分别是joint连接和coordinated协调。joint连接就是将两个单模态信号合并到同一个表示空间,协调表示就是分开各自处理单模态信号,然后施加特定的相似约束,通过协调空间连接其中不同的单模态。** 可以通过图一看一下这个差异。
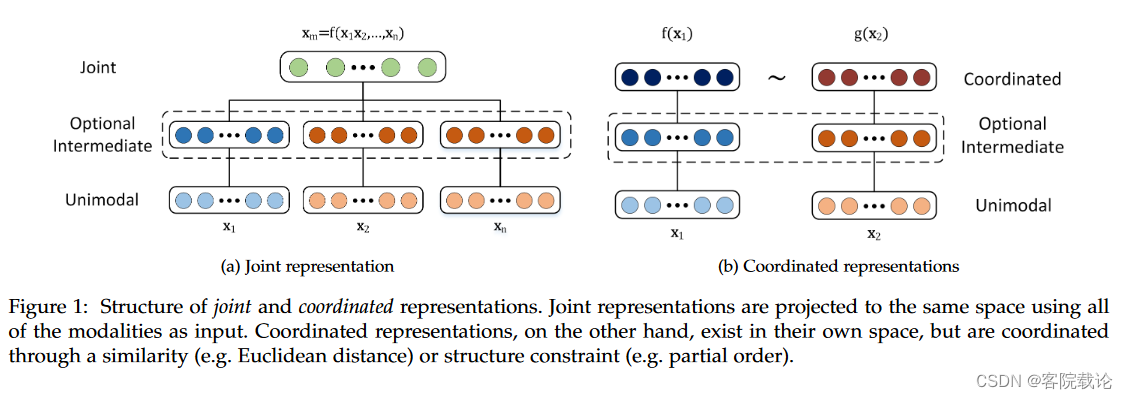
-
从数学上看,连接joint表示可以描述为下述公式,其中Xm是多模态表示,使用函数f(可是深度神经网络,严格限制的玻尔兹曼机,递归神经网络)进行计算的,依赖于输入的单模态信息X1,X2,X3。。。。

- 限制的玻尔兹曼机 :
- 递归神经网络 :
-
协调coordinated可以表示为下述公式,每一个模态都有一个对应的映射函数,比如说g和f,将之匹配到多模态空间中。虽然对于每一个模态而言,投影到多模态空间是独立的,但是最终的空间是对彼此协调的,这个协调包括最小化余弦距离,最大化相关性,在结果空间中施加偏序。
- 最小化余弦距离文章,A. Frome, G. Corrado, and J. Shlens, “DeViSE: A deep visualsemantic embedding model,” NIPS, 2013,相关链接
- 最大化相关系数,G. Andrew, R. Arora, J. Bilmes, and K. Livescu, “Deep canonical correlation analysis,” in ICML, 2013.,相关连接
- 空间中施加偏序,I. Vendrov, R. Kiros, S. Fidler, and R. Urtasun, “OrderEmbeddings of Images and Language,” in ICLR, 2016,
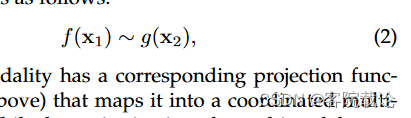
总结
- 多模态表示之所以难,关键在于他要将不同结构的数据进行整合,并且还要面对模态缺失和噪声异构的特点。好的多模态表示应该具有如上的特点,加粗了,自己看。目前多模态研究已经很广泛了,数据驱动的替代了原来手工的,视觉领域,卷积网络替代sift,音频领域,递归网络替代MFCC,自然语言处理领域,Embedding取代了单词次数,但是目前多模态的表示都是对单模态的简单链接发展尚且不够充分。不过这都是2017年的,现在已经有一部分了。
- 这部分通过公式解释了joint和coordinated。joint就是一个函数,将所有的单模态信息统一映射到多模态中,具体的样例就是深度神经网络,深度玻尔兹曼机和递归神经网络都能。coordinate是一个映射函数,将不同的模态映射到一个协调空间中,各自相互不影响,具体样例就是最下化欧氏距离,最大化相关性和在结果空间中施加偏移。
- 有空的话可以了解一下这几篇文章, 因为可以直观地了解对应原理实现过程
Joint Repersentations(1)
- 我们开始讨论连接表示,之前在公式一中提到,多模态是将两种独立的单模态映射到一个空间中。连接表示主要应用在多模态数据同时在训练和推理阶段出现的任务中。连接表示最简单的样例就是直接将独立的单模态进行串联。在这部分,我们将讨论更加先进的多模态表示的创建方式,分别是神经网络、图形化模型、递归神经网络,相应的工作在表格2中可见。
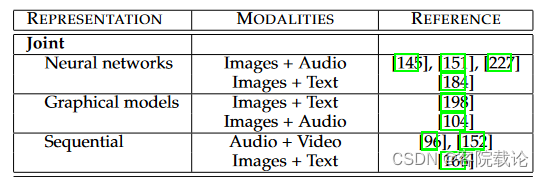
-
Neural networks神经网络 神经网络在单模态数据表示生成中已经很普遍了,过去主要用于表示视觉信息,音频信息和文本数据,现在也越来越多应用于多模态领域。这部分,我们主要讲解神经网络是如何构建连接多模态表示、如何进行训练以及他的长处是什么。
-
通俗的讲,神经网络是由连续的内积构建块和非线性激活函数构成。如果你想使用神经网络去表示数据,首先需要被训练,用来执行特定的任务(识别图像中的目标等)。因为神经网络的多层性质,每一个连续的层都假定以一种抽象的方式来表示数据,因此一般是使用最后一层或者倒数第二层作为数据表示的形式。为了使用神经网络创建一个多模态表示,每一个模态首先会单独跟一个神经层,然后共同接入一个隐藏层,将所有的模态映射到一个空间中。联合多模态就是通过隐藏层获得,或者直接用来预测。 这样的模型可以用来进行端到端的训练,学习表示数据和指定特定的任务。当你使用神经网络进行训练时,将会造成多模态表示学习和多模态融合具有很近的关系。(补充:多模态融合可以理解成是执行特定的任务,多模态表示可以理解成前面一个中间过程,中间就是查了一小步,倒数第二成和最后一层的区别。)
-
因为神经网络需要很多带标记的训练数据,所以一般来说会使用自动编码器在无监督的数据上,预训练这样的表示。(说实话,这部分没看懂,自动编码器???)Mgiam等人提出的模型,是将自动编码器扩展到了多模态领域。他们使用堆叠式的降噪自动编码器去单独表示每一种模态,然后使用另外一个自动编码层将之融合到一个多模态表示空间中。就手边的特定任务,去微调最终表示,这种操作很常见,因为自动编码器是通用的,对于特定的任务而言,并不一定是最优的。
-
基于连接表示的神经网络的主要优势是来自于他们本身优越的性能,和使用无人监督的方式去与训练表示的能力。但是性能增益是来自于数据的数量。这种方法的缺点也是来自于模型本身,不能处理自然缺失的数据,虽然有方法缓解这个问题。虽然深度学习模型很难训练,但是这个领域已经更好的训练技术上取得了进展。
-
多模态领域的自动编码器:J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal Deep Learning,” ICML, 2011.
总结和附加(一)
-
这部分主要是讲连接表示的三种实现方式,分别是神经网络、图模型和递归神经网络。对于神经网络主要是讲神经网络是如何构建连接多模态表示、如何进行训练以及他的长处是什么。
-
神经网络在多模态领域中的应用,对应的三篇论文
- 151神经网络在人体姿态估计上的实现情况:W. Ouyang, X. Chu, and X. Wang, “Multi-source Deep Learning for Human Pose Estimation,” in CVPR, 2014
- 156多模态深度学习:J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal Deep Learning,” ICML, 2011.
- 217多模态哈希:D. Wang, P. Cui, M. Ou, and W. Zhu, “Deep Multimodal Hashing with Orthogonal Regularization,” in IJCAI, 2015.
-
自动编码器对无监督数据,预训练对应的模型结构:G. Hinton and R. S. Zemel, “Autoencoders, minimum description length and Helmoltz free energy,” in NIPS, 1993.
Joint Repersentations(2)
-
Probabilistic graphic models : 概率图形模型是通过使用潜在随机变量创建表示。在这部分我们将会描述概率图形模型如何用来表示单模态和多模态数据
-
基于表示的图形模型的最常见的方法深度玻尔兹曼机(DBM deep Boltzmann machines),这个深度玻尔兹曼机是将严格限制的玻尔兹曼机作为构建模块进行堆叠的。与神经网络相同,一个DBM的连续层的输出是使用以一种更加抽象的层次表示数据。DBMs的优点是建立在他们并不需要监督数据去训练。因为他们是图形模型,数据的表示是概率型的,但是也有可能将之转变为确定的神经网络,但是这将是去这个模型生成性的优点。
- DBM深度玻尔兹曼机 :R. Salakhutdinov and G. E. Hinton, “Deep Boltzmann Machines,” in International conference on artificial intelligence and statistics, 2009. 这个可以好好了解一下。
-
Srivastava和Salakhutdinov的研究工作中引入了多模态深度信任网络作为多模态表示。Kim等人对单模态使用深度信任网络进行处理,然后在将之合并成联合表示,用来处理音视频情感识别问题。Huang和Kingsbury等人使用相似的模型去解决AVSR问题,WU等人使用这些模型去解决基于音频和骨架关节的手势识别。
- 多模态深度信任模型:N. Srivastava and R. Salakhutdinov, “Learning Representations for Multimodal Data with Deep Belief Nets,” in ICML, 2012.
- Kim音视频情感识别:Y. Kim, H. Lee, and E. M. Provost, “Deep Learning for Robust Feature Generation in Audiovisual Emotion Recognition,” in ICASSP, 2013
- 基于视频和骨关节的动作识别:D. Wu and L. Shao, “Multimodal Dynamic Networks for Gesture Recognition,” in ACMMM, 2014.
-
Srivastava和Salakhutdinov已经把多模态深度信任网络扩展到多模态DBMs,多模态DBMs能够通过在两个或则多个无向图上使用隐藏单元的二进制层进行合并,从多个模态中学习联合表示。因为模型无向图的本质,在经过联合训练之后,每一个模态的低层次表达能够相互影响。
- 多模态深度信任网络扩展到的DBMs:N. Srivastava and R. R. Salakhutdinov, “Multimodal Learning with Deep Boltzmann Machines,” in NIPS, 2012
-
Ouyang等人尝试探索使用多模态DBMs从多视角数据出发,完成人类姿态估计的任务。他们认为数据整合应该在比较靠后的阶段,应该在单模态数据进行非线性变换之后,这对于模型有好处。相似的,Suk等人使用多模态DBM表示去实现从正电子图像和核磁共振图像中,对奥茨海默综合征的分类
- Ouyang等人的研究: W. Ouyang, X. Chu, and X. Wang, “Multi-source Deep Learning for Human Pose Estimation,” in CVPR, 2014.
- Suk等人诊断老年痴呆: H. I. Suk, S.-W. Lee, and D. Shen, “Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis,” NeuroImage, 2014.
-
使用多模态DBMs去学习多模态表示的最大好处之一就是,他们的生成性,这使得他们能够很容易处理丢失的数据,即使数据中某一个模态完全缺失,模型都有自然的方法去复制生成。在一种模态下生成另外一种模态的样例,或者从表示中生成两种模态。与自动编码器相似,可以使用一种无监督的方式训练表示,从而可以使用无监督的数据。DBMs的主要缺点是难训练,计算成本高,需要使用近似变分的方法训练方法。
- 近似变分训练方法:N. Srivastava and R. R. Salakhutdinov, “Multimodal Learning with Deep Boltzmann Machines,” in NIPS, 2012.
总结和附加(二)
- 概率模型图的典型样例:Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” TPAMI, 2013
- 这里对于深度玻尔兹曼机一点都没有认知,需要下功夫了解一下,复现一下。单纯通过论文来看,深度玻尔兹曼机的优点弥补了深度学习的缺点,使其能够有效处理缺失的数据,缺失的模态,可以实现模态之间的相互转换。
- 花点时间,了解一下玻尔兹曼机,或者自己去复现一下,感觉这个还是挺重要的。
Joint Repersentations(3)
- Sequential Representation 迄今为止,我们已经讨论了能够表示定长数据的模型,但是,我们常常需要表示不定长的数据,比如说句子,视频或者音频流。在这部分,我们将描述用来表示这种序列的模型。
- 递归神经网络(Recurrent neural networks RNNs),以及他的长短时间记忆网络(long-short term memory LSTMs),这两种模型最近很流行,因为他们在跨多个任务的序列建模上的成功。迄今,RNNs已经被广泛应用于表示比如说单词,音频,图片的单模态序列,在语言领域取得了很大的成功。与传统神经网络相类似,RNN的隐藏层可以看作是数据的表示,比如说RNN在时间步t的隐藏状态可以看作是该时间步之前序列的总结。这在RNN编码和解码框架中十分明显,其中编码器的任务是以解码器能够重建的方式来表示RNN隐藏状态中的序列。
- 长短时间记忆网络:S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, 1997.
- 递归神经网络:https://zhuanlan.zhihu.com/p/98973617
- RNN编码解码结构:D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation By Jointly Learning To Align and Translate,” ICLR, 2014.
- RNN表示的使用并不仅仅限制在单模态领域,应用RNN构建多模态表示最早的应用是Cosi等人在AVSR音视频语音识别上的应用。他们也被用来表示音视频数据,以进行情感识别。或者表示多视角数据,比如说用于人类行为分析的多视角线索。
- 将RNN应用于AVSR领域:P. Cosi, E. Caldognetto, K. Vagges, G. Mian, M. Contolini, C. per Le Ricerche, and C. di Fonetica, “Bimodal recognition experiments with recurrent neural networks,” in ICASSP, 1994.
- 使用RNN进行情感识别:S. Chen and Q. Jin, “Multi-modal Dimensional Emotion Recognition Using Recurrent Neural Networks,” in Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, 2015.
- 使用RNN进行人类行为分析:S. S. Rajagopalan, L.-P. Morency, T. Baltruˇ saitis, and R. Goecke, “Extending Long Short-Term Memory for Multi-View Structured Learning,” ECCV, 2016.
总结与附加
- 序列表示主要是针对不定长的数据进行处理的,经典是递归神经网络和长短时间记忆网络LSTM两个,主要是在自然语言领域取得了很大的成功,应用也比较广泛。
- 希望具体实现一下这两种模型,还有就是找到具体的实现项目,自己看一下具体的项目。
3.2 Coordinated Representations(1)
-
另外一种表示是协调表示(Coordinated representation),不同于连接表示将所有的模态共同投影到连接空间,**协调表示是单独学习每一个模态的表示,但是通过约束对这些表示进行协调。**首先我们讨论在表示之间强化相似性的协调表示,然后再讨论强化目标空间的结构的协调表示。具体详见表格2.

-
Similarity models 相似性模型,是最小化相似空间中模态之间的距离。比如说,这个模型会让表示狗的单词和一张狗的图片之间的距离小于,狗这个单词和其他图片的之间的距离。协调表示的最早尝试是由Weston等人在使用图片embedding实现网络大规模注释的工作中完成的,其中协调空间是为图片和其注释构建的。WSABIE在图片和文本特征之间构建了一个简单的线性映射,使得相关的注释和图片表示拥有更高的内积,也就是更低的余弦距离,比起那些不相关的图片和注释。
- 单词和图片之间的协调空间:A. Frome, G. Corrado, and J. Shlens, “DeViSE: A deep visualsemantic embedding model,” NIPS, 2013.
- 协调空间的最早尝试:“WSABIE: Scaling up to large vocabulary image annotation,” in IJCAI, 2011. 这个是一个通用的打标签算法,具体的阅读链接
-
最近,因为神经网络有能力学习表示,用其构建协调表示也越来越普遍了。这种方法的长处在于它可以使用一种端到端的方式共同学习协调表示。这种协调表示的样例就是DeViSE,深度视觉语义嵌入。DeViSE和WSABIIE一样,使用相同的内积和和排序损失函数,但是DeViSE使用更加复杂的图片和单词嵌入。这个模型分别被不同的人改良,应用在图像和句子协调,视频和句子的协调,跨模态检索和视频描述任务等。(这部分就是单纯地举例子,并没有具体翻译)
- 深度视觉语义嵌入:A. Frome, G. Corrado, and J. Shlens, “DeViSE: A deep visualsemantic embedding model,” NIPS, 2013. 学习连接
附加与总结(1)
- 这部分讲了相似性模型的协调方式,首先将各个模态进行单独处理,获得其单独的表示空间,然后再将对各自的表示空间进行协调,最小化其对应表示空间的距离。说起来可能有点扯,我认为还是要找一个具体的样例项目,看看代码,知道其具体的原理。
3.2 Coordinated Representations(2)
- 上述的模型是通过对模态之间施加相似性来实现协调空间的,结构协调空间与其不同,他是在不同模态之间的表示施加额外的约束。一般使用的结构类型是基于应用的,对于散列、跨模式检索和图像注释有不同的约束。
- 结构化协调空间通常用于跨模态散列——就是对于相似的对象而言,将具有相似二进制编码的高维数据压缩为紧凑二进制编码。跨模式散列的目的是创建用于跨模式检索的编码。散列对生成的多模态空间施加了特定约束:1)它必须是 N 维汉明空间——具有可控位数的二进制表示; 2)来自不同模态的同一对象必须具有相似的哈希码; 3)空间必须保持相似性。学习如何将数据表示为哈希函数试图强制执行所有这三个要求。
附加与总结(2)
- 说实话,这部分我一点都不了解,所以看着很费劲,因为我没有学过相关的自然语言处理,所以并不了解,所以到这里暂时就停了吧,先把前面的问题解决了,再往下继续阅读
3.3 Discussion
- 在本节中,我们确定了两种主要类型的多模态表示——联合和协调。联合表示将多模态数据投射到一个公共空间中,最适合在推理过程中出现所有模态的情况。它们已广泛用于 AVSR、情感和多模式手势识别。另一方面,协调表示将每个模态投射到一个单独但协调的空间中,使其适用于测试时只有一种模态存在的应用,例如:多模态检索和翻译(第 4 节)、基础(第 7.2 节)和零样本学习(第 7.2 节)。最后,虽然在某些情况下已使用联合表示来构建超过两种模式,到目前为止,协调空间主要限于两种模式。

