
- 1Pycharm配置Copilot一直waiting for github authentication_pycharm copilot一直等待链接
- 2陕西师《c语言程序设计》作业,南开19秋学期(1709、1803、1809、1903、1909)《C语言程序设计》在线作业【满分答案】...
- 3CentOS 7离线安装Keepalived_centos离线安装keepalive
- 4基础篇:Linux 常用命令总结_vv linux
- 5MAC如何安装多版本jdk(以8,17为例)_mac 下载jdk17 多版本
- 6基于轻量级YOLOv5模型开发构建鸟巢检测识别分析系统_yolov5鸟巢
- 7Mastering the JSFL: 利用JSFL进行批处理操作(批量发布,交换元件,修改AS代码等等)_an jsfl
- 8Python3 基础语法:字符串(String)_python3 string
- 9canvas基础
- 10Azure mysql内网_用Azure VM + Azure Database for MySQL搭建Web服务
spaCy:训练神经网络模型_spacy 中文 训练模型
赞
踩
模型的训练和更新
为什么要更新模型?
- 对特定领域有更好的结果
- 对特定问题学习特定的分类类别
- 对文本分类非常必要
- 对命名实体识别非常有用
- 对词性标注和依存关系识别不是很关键
如何训练(1)
- 初始化模型权重使之变为随机值
- 预测几个例子,看看当前权重的表现
- 比较预测结果和真实标注的标签
- 计算如何调整权重来改善预测结果
- 微调模型权重
- 重复步骤 2。
如何训练(2)
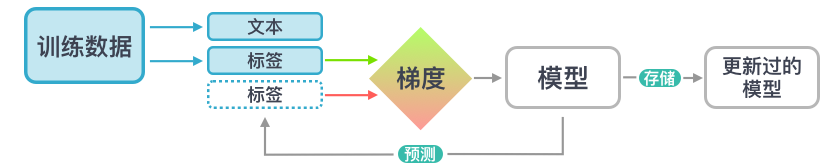
- 训练数据:例子及其标注
- 文本:输入文本,模型会在这些文本上做标签预测。
- 标签:模型需要预测的标签
- 梯度:权重如何微调
举例:训练实体识别器
- 实体识别器可以对词语和短语做基于语境的实体识别
- 每一个词符只能是某一个实体的一部分
- 训练例子需要带有语境
| 1 2 | doc = nlp("iPhone X就要来了") doc.ents = [Span(doc, 0, 8, label="GADGET")] |
- 并非实体的文本部分也非常重要
| 1 2 | doc = nlp("我急需一部新手机,给点建议吧!") doc.ents = [] |
- 目标:让模型学会泛化
训练数据
- 一系列我们希望模型在语境中做出预测的例子
- 更新现有模型:需要几百到几千个例子
- 训练新的类别:需要几千乃至几百万个例子
- spaCy 的中文模型是在 200 万个词语的语料规模上训练的
- 通常需要由标注师人工标注数据
- 也可以是半自动的,比如用 spaCy 的模板匹配器
Matcher!
训练数据 vs 测试数据
- 训练数据:用来更新模型
- 测试数据:
- 模型在训练过程中未见到的数据
- 用来计算模型的准确度
- 代表了模型在生产环境中会遇到的真实数据
生成训练语料(1)
| 1 2 3 4 5 6 7 8 | import spacy nlp = spacy.blank("zh") # 创建一个含有实体span的Doc doc1 = nlp("iPhone X就要来了") doc1.ents = [Span(doc1, 0, 8, label="GADGET")] # 创建另一个没有实体span的Doc doc2 = nlp("我急需一部新手机,给点建议吧!") docs = [doc1, doc2] # 以此类推... |
生成训练语料(2)
- 将数据分割成两份:
- 训练数据:用来更新模型
- 开发数据:用来测试模型
| 1 2 3 | random.shuffle(docs) train_docs = docs[:len(docs) // 2] dev_docs = docs[len(docs) // 2:] |
生成训练语料(3)
DocBin:用来有效存储Doc对象的容器- 可以保存为二进制文件
- 二进制文件可以用来训练模型
| 1 2 3 4 5 6 | # 创建和保存一系列的训练文档 train_docbin = DocBin(docs=train_docs) train_docbin.to_disk("./train.spacy") # 创建和保存一系列的测试文档 dev_docbin = DocBin(docs=dev_docs) dev_docbin.to_disk("./dev.spacy") |
小经验:数据转换
spacy convert可以将语料转换为常见的格式- 支持
.conll,.conllu,.iob以及 spaCy 之前的 JSON 格式。
| 1 | $ python -m spacy convert ./train.gold.conll ./corpus |
创建训练数据
spaCy的基于规则的Matcher可以很好地被用来快速创建一些命名实体模型的训练数据。变量 TEXTS中存储着句子的列表,我们可以将其打印出来做检查。我们想要找到所有对应不同iPhone 型号的文本,所以我们可以创建一些训练数据来教会模型把它们识别为电子产品"GADGET"。
- 编写一个模板,含有两个词符且它们的小写形式可以匹配到
"iphone"和"x"。 - 编写一个模板,含有两个词符,第一个词符的小写形式匹配到
"iphone",第二个词符用"?"运算符匹配到一个数字。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import json import spacy from spacy.matcher import Matcher from spacy.tokens import Span with open("exercises/zh/iphone.json", encoding="utf8") as f: TEXTS = json.loads(f.read()) nlp = spacy.blank("zh") matcher = Matcher(nlp.vocab) # 两个词符,其小写形式匹配到"iphone"和"x"上 pattern1 = [{"LOWER": "iphone"}, {"LOWER": "x"}] # 词符的小写形式匹配到"iphone"和一个数字上 pattern2 = [{"LOWER": "iphone"}, {"IS_DIGIT": True}] # 把模板加入到matcher中,并用匹配到的实体创建docs matcher.add("GADGET", [pattern1, pattern2]) docs = [] for doc in nlp.pipe(TEXTS): matches = matcher(doc) spans = [Span(doc, start, end, label=match_id) for match_id, start, end in matches] print(spans) doc.ents = spans docs.append(doc) |
返回结果如下
| 1 2 3 4 5 6 | [] [] [] [] [] [] |
在为我们的语料创建数据之后,我们需要将其存放在一个后缀为.spacy的文件中。可以参见上一个例子中的代码。
- 使用
docs的列表初始化DocBin。 - 将
DocBin存储到一个名为train.spacy的文件中。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import json import spacy from spacy.matcher import Matcher from spacy.tokens import Span, DocBin with open("exercises/zh/iphone.json", encoding="utf8") as f: TEXTS = json.loads(f.read()) nlp = spacy.blank("zh") matcher = Matcher(nlp.vocab) # 将pattern加入mattcher中 pattern1 = [{"LOWER": "iphone"}, {"LOWER": "x"}] pattern2 = [{"LOWER": "iphone"}, {"IS_DIGIT": True}] matcher.add("GADGET", [pattern1, pattern2]) docs = [] for doc in nlp.pipe(TEXTS): matches = matcher(doc) spans = [Span(doc, start, end, label=match_id) for match_id, start, end in matches] doc.ents = spans docs.append(doc) doc_bin = DocBin(docs=docs) doc_bin.to_disk("./train.spacy") |
配置和运行训练流程
训练配置(1)
- 所有设定的唯一真理来源
- 通常被叫做
config.cfg - 定义了如何初始化
nlp对象 - 包含了关于流程组件和模型实现的所有设定
- 配置了训练过程和超参数
- 使我们的训练过程可复现
训练配置(2)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | [nlp] lang = "zh" pipeline = ["tok2vec", "ner"] batch_size = 1000 [nlp.tokenizer] @tokenizers = "spacy.zh.ChineseTokenizer" segmenter = "char" [components] [components.ner] factory = "ner" [components.ner.model] @architectures = "spacy.TransitionBasedParser.v2" hidden_width = 64 # 以此类推 |
生成一个配置文件
- spaCy可以自动生成一个默认的配置文件
- 文档中有可交互的快速上手插件
- 作用于CLI的
init config命令
| 1 | $ python -m spacy init config ./config.cfg --lang zh --pipeline ner |
init config: 要运行的命令config.cfg: 生成的配置文档的输出路径--lang: 流程的语言类,比如中文是zh--pipeline: 用逗号分隔的流程组件名称
训练流程(1)
- 我们需要的只是
config.cfg和训练与测试数据 - 配置的设定可以在命令行中被覆盖
| 1 | $ python -m spacy train ./config.cfg --output ./output --paths.train train.spacy --paths.dev dev.spacy |
train: 要运行的命令config.cfg: 配置文档的路径--output: 保存训练流程的输出路径--paths.train: 覆盖训练数据的路径--paths.dev: 覆盖测试数据的路径
训练流程(2)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | ============================ Training pipeline ============================ ℹ Pipeline: ['tok2vec', 'ner'] ℹ Initial learn rate: 0.001 E # LOSS TOK2VEC LOSS NER ENTS_F ENTS_P ENTS_R SCORE --- ------ ------------ -------- ------ ------ ------ ------ 0 0 0.00 26.50 0.73 0.39 5.43 0.01 0 200 33.58 847.68 10.88 44.44 6.20 0.11 1 400 70.88 267.65 33.50 45.95 26.36 0.33 2 600 67.56 156.63 45.32 62.16 35.66 0.45 3 800 138.28 134.12 48.17 74.19 35.66 0.48 4 1000 177.95 109.77 51.43 66.67 41.86 0.51 6 1200 94.95 52.13 54.63 67.82 45.74 0.55 8 1400 126.85 66.19 56.00 65.62 48.84 0.56 10 1600 38.34 24.16 51.96 70.67 41.09 0.52 13 1800 105.14 23.23 56.88 69.66 48.06 0.57 ✔ Saved pipeline to output directory /path/to/output/model-last |
读取已经训练好的流程
- 训练后的输出是一个正常的可读取的spaCy流程
model-last: 最后训练出的流程model-best: 表现最好的训练流程
- 用
spacy.load读取流程
| 1 2 3 4 | import spacy nlp = spacy.load("/path/to/output/model-best") doc = nlp("iPhone 11 vs iPhone 8: 到底有什么区别?") print(doc.ents) |
小经验:将流程打包
spacy package: 创建一个包含我们流程的可安装的Python包- 方便版本控制和部署
| 1 | $ python -m spacy package /path/to/output/model-best ./packages --name my_pipeline --version 1.0.0 |
| 1 2 | $ cd ./packages/zh_my_pipeline-1.0.0 $ pip install dist/zh_my_pipeline-1.0.0.tar.gz |
安装后读取和使用流程:
| 1 | nlp = spacy.load("zh_my_pipeline") |
生成一个配置文件
init config命令 自动生成一个使用默认设定的训练配置文件。 我们想要训练一个命名实体识别器,所以我们要生成一个含有一个流程组件ner的配置文件。 因为我们在本课程中是在Jupyter环境中运行命令,所以加上前缀!。 如果是在本地终端中运行则不需要加这个前缀。
- 使用spaCy的
init config命令来自动生成一个中文流程的配置。 - 将配置保存到文件
config.cfg中。 - 使用
--pipeline参数指明一个流程组件ner。
| 1 | !python -m spacy init config ./config.cfg --lang zh --pipeline ner |
返回结果如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | ⚠ To generate a more effective transformer-based config (GPU-only), install the spacy-transformers package and re-run this command. The config generated now does not use transformers. ℹ Generated config template specific for your use case - Language: zh - Pipeline: ner - Optimize for: efficiency - Hardware: CPU - Transformer: None ✔ Auto-filled config with all values ✔ Saved config config.cfg You can now add your data and train your pipeline: python -m spacy train config.cfg --paths.train ./train.spacy --paths.dev ./dev.spacy |
我们来看看spaCy刚刚生成的配置文件! 我们可以运行下面的命令将配置打印到屏幕上。
| 1 | !cat ./config.cfg |
返回结果如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 | [paths] train = null dev = null vectors = null init_tok2vec = null [system] gpu_allocator = null seed = 0 [nlp] lang = "zh" pipeline = ["tok2vec","ner"] batch_size = 1000 disabled = [] before_creation = null after_creation = null after_pipeline_creation = null [nlp.tokenizer] @tokenizers = "spacy.zh.ChineseTokenizer" segmenter = "char" [components] [components.ner] factory = "ner" incorrect_spans_key = null moves = null update_with_oracle_cut_size = 100 [components.ner.model] @architectures = "spacy.TransitionBasedParser.v2" state_type = "ner" extra_state_tokens = false hidden_width = 64 maxout_pieces = 2 use_upper = true nO = null [components.ner.model.tok2vec] @architectures = "spacy.Tok2VecListener.v1" width = ${components.tok2vec.model.encode.width} upstream = "*" [components.tok2vec] factory = "tok2vec" [components.tok2vec.model] @architectures = "spacy.Tok2Vec.v2" [components.tok2vec.model.embed] @architectures = "spacy.MultiHashEmbed.v2" width = ${components.tok2vec.model.encode.width} attrs = ["ORTH","SHAPE"] rows = [5000,2500] include_static_vectors = false [components.tok2vec.model.encode] @architectures = "spacy.MaxoutWindowEncoder.v2" width = 96 depth = 4 window_size = 1 maxout_pieces = 3 [corpora] [corpora.dev] @readers = "spacy.Corpus.v1" path = ${paths.dev} max_length = 0 gold_preproc = false limit = 0 augmenter = null [corpora.train] @readers = "spacy.Corpus.v1" path = ${paths.train} max_length = 0 gold_preproc = false limit = 0 augmenter = null [training] dev_corpus = "corpora.dev" train_corpus = "corpora.train" seed = ${system.seed} gpu_allocator = ${system.gpu_allocator} dropout = 0.1 accumulate_gradient = 1 patience = 1600 max_epochs = 0 max_steps = 20000 eval_frequency = 200 frozen_components = [] annotating_components = [] before_to_disk = null [training.batcher] @batchers = "spacy.batch_by_words.v1" discard_oversize = false tolerance = 0.2 get_length = null [training.batcher.size] @schedules = "compounding.v1" start = 100 stop = 1000 compound = 1.001 t = 0.0 [training.logger] @loggers = "spacy.ConsoleLogger.v1" progress_bar = false [training.optimizer] @optimizers = "Adam.v1" beta1 = 0.9 beta2 = 0.999 L2_is_weight_decay = true L2 = 0.01 grad_clip = 1.0 use_averages = false eps = 0.00000001 learn_rate = 0.001 [training.score_weights] ents_f = 1.0 ents_p = 0.0 ents_r = 0.0 ents_per_type = null [pretraining] [initialize] vectors = ${paths.vectors} init_tok2vec = ${paths.init_tok2vec} vocab_data = null lookups = null before_init = null after_init = null [initialize.components] [initialize.tokenizer] pkuseg_model = null pkuseg_user_dict = "default" |
使用训练客户端
使用train 命令来调取训练配置文件来训练一个模型。 一个名为config_gadget.cfg的文件已经在exercise/zh中了, 同时还有一个名为train_gadget.spacy的文件包含了一些训练数据,dec_gadget.spacy文件包含了测试数据。 因为我们在本课程中是在Jupyter环境中运行命令,所以加上前缀!。 如果是在本地终端中运行则不需要加这个前缀。
- 在文件
exercises/zh/config_gadget.cfg上面运行train命令。 - 将训练好的流程保存在
output文件夹中。 - 传入路径
exercises/zh/train_gadget.spacy和exercises/zh/dev_gadget.spacy
| 1 | !python -m spacy train ./exercises/zh/config_gadget.cfg --output ./output --paths.train ./exercises/zh/train_gadget.spacy --paths.dev ./exercises/zh/dev_gadget.spacy |
返回结果如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | ✔ Created output directory: output ℹ Saving to output directory: output ℹ Using CPU =========================== Initializing pipeline =========================== Traceback (most recent call last): File "/srv/conda/envs/notebook/lib/python3.10/runpy.py", line 196, in _run_module_as_main return _run_code(code, main_globals, None, File "/srv/conda/envs/notebook/lib/python3.10/runpy.py", line 86, in _run_code exec(code, run_globals) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/__main__.py", line 4, in <module> setup_cli() File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/cli/_util.py", line 71, in setup_cli command(prog_name=COMMAND) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/click/core.py", line 1130, in __call__ return self.main(*args, **kwargs) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/click/core.py", line 1055, in main rv = self.invoke(ctx) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/click/core.py", line 1657, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/click/core.py", line 1404, in invoke return ctx.invoke(self.callback, **ctx.params) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/click/core.py", line 760, in invoke return __callback(*args, **kwargs) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/typer/main.py", line 532, in wrapper return callback(**use_params) # type: ignore File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/cli/train.py", line 45, in train_cli train(config_path, output_path, use_gpu=use_gpu, overrides=overrides) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/cli/train.py", line 72, in train nlp = init_nlp(config, use_gpu=use_gpu) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/training/initialize.py", line 41, in init_nlp nlp = load_model_from_config(raw_config, auto_fill=True) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/util.py", line 454, in load_model_from_config nlp = lang_cls.from_config( File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/language.py", line 1763, in from_config nlp.add_pipe( File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/language.py", line 787, in add_pipe pipe_component = self.create_pipe( File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/language.py", line 670, in create_pipe resolved = registry.resolve(cfg, validate=validate) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/thinc/config.py", line 746, in resolve resolved, _ = cls._make( File "/srv/conda/envs/notebook/lib/python3.10/site-packages/thinc/config.py", line 795, in _make filled, _, resolved = cls._fill( File "/srv/conda/envs/notebook/lib/python3.10/site-packages/thinc/config.py", line 850, in _fill filled[key], validation[v_key], final[key] = cls._fill( File "/srv/conda/envs/notebook/lib/python3.10/site-packages/thinc/config.py", line 849, in _fill promise_schema = cls.make_promise_schema(value, resolve=resolve) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/thinc/config.py", line 1040, in make_promise_schema func = cls.get(reg_name, func_name) File "/srv/conda/envs/notebook/lib/python3.10/site-packages/spacy/util.py", line 126, in get raise RegistryError(Errors.E892.format(name=registry_name, available=names)) catalogue.RegistryError: [E892] Unknown function registry: 'scorers'. Available names: architectures, augmenters, batchers, callbacks, cli, datasets, displacy_colors, factories, initializers, languages, layers, lemmatizers, loggers, lookups, losses, misc, models, ops, optimizers, readers, schedules, tokenizers |
训练spaCy模型的最佳实践
问题一:模型“忘记”了东西
- 已有的模型可能会在新数据上过拟合
- 举个例子:如果我们只是想给模型更新一个
"WEBSITE"的类别,模型有可能会“忘记” 之前"PERSON"这个类别。
- 举个例子:如果我们只是想给模型更新一个
- 这也被称为“灾难性遗忘”的问题。
解决方法一:将之前的正确预测结果混合进来
- 举个例子,我们要训练
"WEBSITE",但我们也把"PERSON"的例子加进来。 - 在数据上跑已有的spaCy模型然后抽取所有其它相关的实体。
问题二:模型不能学会所有东西
- spaCy的模型基于本地语境作出预测。
- 如果基于语境本身就很难做出判断,那模型也很难学得会
- 标签种类最好前后一致,也不要过于特殊
- 比如,
"CLOTHING"这个类别就要比"ADULT_CLOTHING"和"CHILDRENS_CLOTHING"更 好。
- 比如,
解决方法二:仔细计划标签种类
- 选择那些能从本地语境中反映出来的类别
- 更通用的标签要好过更特定的标签
- 我们可以用规则把通用标签转化为特定种类
不好的做法:
| 1 | LABELS = ["ADULT_SHOES", "CHILDRENS_SHOES", "BANDS_I_LIKE"] |
好的做法:
| 1 | LABELS = ["CLOTHING", "BAND"] |
训练多个标签
完成数据中所有"WEBSITE"实体的位置参数。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import spacy from spacy.tokens import Span nlp = spacy.blank("zh") doc1 = nlp("哔哩哔哩与阿里巴巴合作为博主们建立社群") doc1.ents = [ Span(doc1, 0, 4, label="WEBSITE"), Span(doc1, 5, 9, label="WEBSITE"), ] doc2 = nlp("李子柒打破了Youtube的记录") doc2.ents = [Span(doc2, 6, 13, label="WEBSITE")] doc3 = nlp("阿里巴巴的创始人马云提供了一千万购物优惠券") doc3.ents = [Span(doc3, 0, 4, label="WEBSITE")] |
更新训练数据,加入对"PERSON"实体”李子柒”和”马云”的标注。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import spacy from spacy.tokens import Span nlp = spacy.blank("zh") doc1 = nlp("哔哩哔哩与阿里巴巴合作为博主们建立社群") doc1.ents = [ Span(doc1, 0, 4, label="WEBSITE"), Span(doc1, 5, 9, label="WEBSITE"), ] doc2 = nlp("李子柒打破了Youtube的记录") doc2.ents = [Span(doc2, 0, 3, label="PERSON"), Span(doc2, 6, 13, label="WEBSITE")] doc3 = nlp("阿里巴巴的创始人马云提供了一千万购物优惠券") doc3.ents = [Span(doc3, 0, 4, label="WEBSITE"), Span(doc3, 8, 10, label="PERSON")] |
总结
你的新spaCy技能
- 抽取语言学特征:词性识别,依存关系,命名实体
- 学会使用训练好的的流程
- 用
Matcher和PhraseMatcher来匹配规则寻找目标词汇和短语 - 使用数据结构
Doc、Token、Span、Vocab和Lexeme的最佳实践 - 使用词向量来计算语义相似度
- 编写定制化的流程组件来生成扩展属性
- 规模化你的spaCy流程使其运行速度更快
- 为spaCy的统计模型创建训练数据
- 用新数据训练和更新spaCy的神经网络模型
- 训练和更新其它流程组件
- 词性标注器
- 依存关系解析器
- 文本分类器
- 定制化分词器
- 增加规则和异常来用不同的方法分割文本
- 增加或者改进对其它语种的支持
- 现在支持60+种语言
- 已有语种的支持还有很大改进空间,还有更多语种有待添加支持
- 允许对其它语种训练模型

