
- 1为什么mysql没走索引?_mysql不走索引
- 2GitCode使用教程,创建项目仓库并上传代码(git)
- 3Xilinx FPGA平台DDR3设计详解(三):DDR3 介绍_镁光ddr3 丝印
- 4Ubuntu20.04安装Pytorch_ubuntu20 pytorch
- 5【OpenCV+Qt】使用车牌识别系统EasyPR识别车牌号_qt opencv车牌识别
- 6txt文件的编码结构_txt 的字节码前几位是什么
- 7torchtext的简单教程
- 8【包邮送书】HTML5+CSS3从入门到精通
- 9分布式调用链调研(pinpoint、skywalking、jaeger、zipkin等对比)
- 10python中文文本分析_python--文本分析
深度学习入门(3) - CNN
赞
踩
CNN
Convolutional Layer
We use a filter to slide over the image spatially (computing dot products)
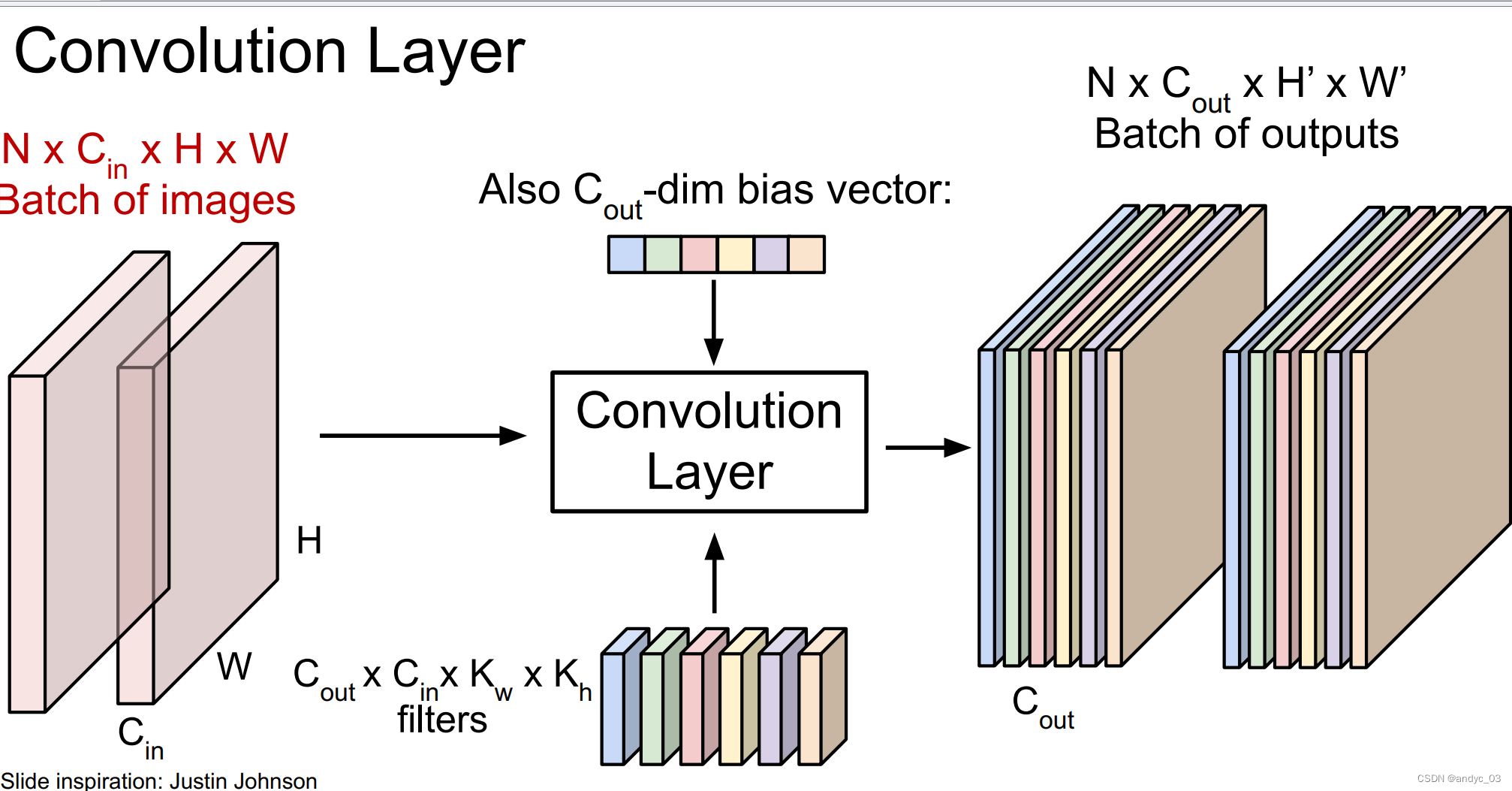
Interspersed with activation function as well
What it learns?
First-layer conv filters: local image templates (Often learns oriented edges, opposing colors)
Problems:
- For large images, we need many layers to get information about the whole image
Solution: Downsample inside the network
-
Feature map shrinks with each layer
Solution: Padding : adding zeros around the input
Pooling layer
-> downsampling
Without parameters that needs to be learnt.
ex:
max pooling
Aver pooling
…
FC layer(Fully Connected)
The last layer should always be a FC layer.
Batch normalization
we need to force inputs to be nicely scaled at each layer so that we can do the optimization more easily.
Usually inserted after FC layer / Convolutional layer, before non-linearity
Pros:
make the network easier to train
robust to initialization
Cons:
behaves differently during training and testing

Architechtures (History of ImageNet Challenge)
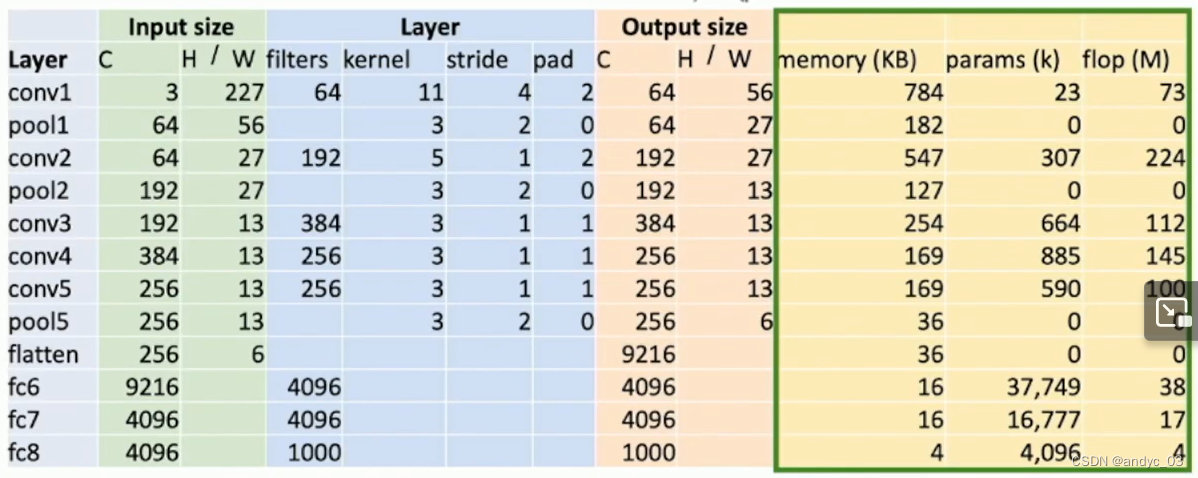
AlexNet
Input 3 * 277 * 277
Layer filters 64 kernel 11 stride 4 pad 2
We need to pay attention to the Memory, pramas, flop size
ZFNet
larger AlexNet
VGG
Rules:
- All conv 3*3 stride 1 pad 1
- max pool 2*2 stride 2
- after pool double channels
Stages:
conv-conv-pool
conv-conv-pool
conv-conv-pool
conv-conv-[conv]-pool
conv-conv-[conv]-pool
GoogLeNet
Stem network: aggressively downsamples input
Inception module:
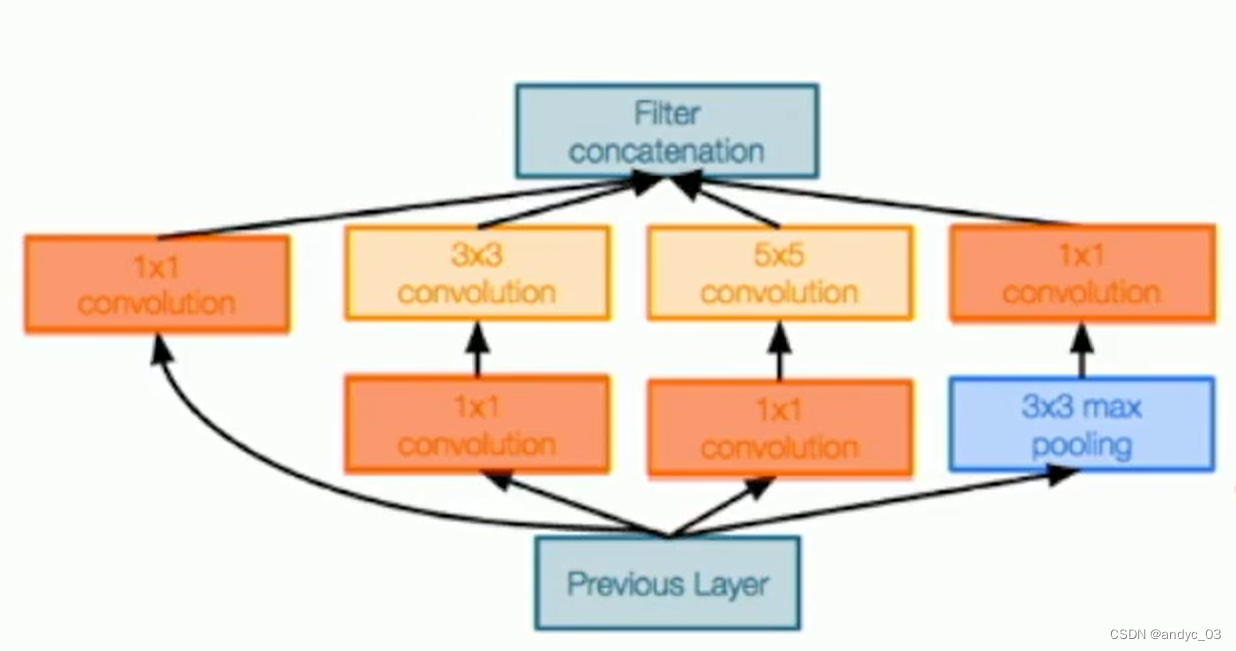
Use such local unit with different kernal size
Use 1*1 Bottleneck to reduce channel dimensions
At the end, rather than flatting to destroy the spatial information with giant parameters
GoogLeNet use average pooling: 7 * 7 * 1024 -> 1024
There is only on FClayer at the last.
找到瓶颈位置,尽可能降低需要学习的参数数量/内存占用
Auxiliary Classifiers:
To help the deep network converge (batch normalization was not invented then): Auxiliary classification outputs to inject additional gradient at lower layers
Residual Networks
We find out that, somtimes we make the net deeper but it turns out to be underfitted.
Deeper network should strictly have the capability to do whatever a shallow one can, but it’s hard to learn the parameters.
So we need the residual network!

This can help learning Identity, with all the parameters to be 0.
The still imitate VGG with its sat b
ResNeXt
Adding grops improves preforamance with same computational complexity.
MobileNets
reduce cost to make it affordable on mobile devices
Transfer learning
We can pretrain the model on a dataset.
When applying it to a new dataset, just finetune/Use linear classifier on the top layers.
Froze the main body of the net.
有一定争议,不需要预训练也能在2-3x的时间达到近似的效果

