
热门标签
热门文章
- 1C和C++相互调用 error LNK2001: unresolved external symbol_c++unresolved什么意思
- 2利用低代码从0到1开发一款小程序_小程序低代码
- 3Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本_gpt-4的层数和训练参数
- 4使用org.apache.commons.io.FileUtils,IOUtils;工具类操作文件
- 5shell命令-find常用命令_shell find -exec
- 6Gradle 安装和配置教程_gradle-8.3-bin.zip放哪个位置
- 7《最长的一帧》理解01_场景渲染
- 8负载均衡_用户将请求发送给负载均衡
- 9Apriori算法中使用Hash树进行支持度计数_hash树在apriori算法中的作用
- 10glance服务器上传的镜像支持,openstack-理解glance组件和镜像服务
当前位置: article > 正文
NLTK--词性标注_nltk词性标注
作者:繁依Fanyi0 | 2024-04-01 12:49:14
赞
踩
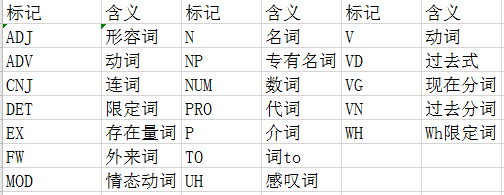
nltk词性标注
tag标注说明
import nltk
from nltk.tag import pos_tag
from nltk.tokenize import word_tokenize
- 1
- 2
- 3
1.词性标注器
text=word_tokenize('And now for something completely different')
print(pos_tag(text))
out:[('And', 'CC'), ('now', 'RB'), ('for', 'IN'), ('something', 'NN'), ('completely', 'RB'), ('different', 'JJ')]
- 1
- 2
- 3
- 4
2.str2tuple()创建标注元组
直接从一个字符串构造一个已标注的标识符的链表。
第一步是对字符串分词以 便能访问单独的词/标记字符串,然后将每一个转换成一个元组(使用 str2tuple())
sent = '''
The/AT grand/JJ jury/NN commented/VBD on/IN a/AT number/NN of/IN
other/AP topics/NNS '''
[nltk.tag.str2tuple(t) for t in sent.split()]
out:[('The', 'AT'),
('grand', 'JJ'),
('jury', 'NN'),
('commented', 'VBD'),
('on', 'IN'),
('a', 'AT'),
('number', 'NN'),
('of', 'IN'),
('other', 'AP'),
('topics', 'NNS')]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
print (nltk.corpus.brown.tagged_words())
[('The', 'AT'), ('Fulton', 'NP-TL'), ...]
#为避免标记的复杂化,可设置tagset为‘universal’
print (nltk.corpus.brown.tagged_words(tagset='universal'))
[('The', 'DET'), ('Fulton', 'NOUN'), ...]
- 1
- 2
- 3
- 4
- 5
3.nltk.bigrams(tokens) 和 nltk.trigrams(tokens) nltk.bigrams(tokens) 和 nltk.trigrams(tokens)
一般如果只是要求穷举双连词或三连词,则可以直接用nltk中的函数bigrams()或trigrams(), 效果如下面代码:
import nltk
str='you are my sunshine, and all of things are so beautiful just for you.'
tokens=nltk.wordpunct_tokenize(str)
bigram=nltk.bigrams(tokens)
bigram
list(bigram)
- 1
- 2
- 3
- 4
- 5
- 6

trigram=nltk.trigrams(tokens)
list(trigram)
- 1
- 2

4.nltk.ngrams(tokens, n)
如果要求穷举四连词甚至更长的多词组,则可以用统一的函数ngrams(tokens, n),其中n表示n词词组, 该函数表达形式较统一,效果如下代码:
nltk.ngrams(tokens, 2)
list(nltk.ngrams(tokens,2))
- 1
- 2

list(nltk.ngrams(tokens,3))
- 1

5.ConditionalFreqDist条件概率分布函数 可以查看每个单词在各新闻语料中出现的次数
brown_news_tagged = brown.tagged_words(categories='news', tagset='universal')
data = nltk.ConditionalFreqDist((word.lower(), tag)
for (word, tag) in brown_news_tagged)
for word in data.conditions():
if len(data[word]) > 3:
tags = data[word].keys()
print (word, ' '.join(tags))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

6.搜查看跟随词的词性标记: 查看‘often’后面跟随的词的词性分布
brown_lrnd_tagged = nltk.corpus.brown.tagged_words(tagset='universal')
tags = [b[1] for (a, b) in list(nltk.bigrams(brown_lrnd_tagged)) if a[0] == 'often']
fd = nltk.FreqDist(tags)
fd.tabulate()
out:
VERB ADJ ADP . DET ADV NOUN PRT CONJ PRON
209 32 31 23 21 21 4 3 3 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7.自动标注器
from nltk.corpus import brown
brown_tagger_sents=brown.tagged_sents(categories='news')
brown_sents=brown.sents(categories='news')
tags=[tag for (word,tag) in brown.tagged_words(categories='news')]
nltk.FreqDist(tags).max()
out:'NN'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
8.默认标注器
raw = 'I do not like green eggs and ham, I do not like them Sam I am!'
tokens = nltk.word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')
default_tagger.tag(tokens)
- 1
- 2
- 3
- 4

"NN"出现的次数最多,设置"NN"为默认的词性, 但是效果不佳
9.正则表达式标注器
patterns = [
(r'.*ing$', 'VBG'), # gerunds
(r'.*ed$', 'VBD'), # simple past
(r'.*es$', 'VBZ'), # 3rd singular present
(r'.*ould$', 'MD'), # modals
(r'.*\'s$', 'NN$'), # possessive nouns
(r'.*s$', 'NNS'), # plural nouns
(r'^-?[0-9]+(.[0-9]+)?$', 'CD'), # cardinal numbers
(r'.*', 'NN') # nouns (default)
]
regexp_tagger = nltk.RegexpTagger(patterns)
print(regexp_tagger.tag(brown.sents()[3]))
regexp_tagger.evaluate(brown.tagged_sents(categories='news'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
 10.查询标注器
10.查询标注器
from nltk.corpus import brown
fd = nltk.FreqDist(brown.words(categories='news'))
cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news'))
most_freq_words = fd.most_common()[:100]
likely_tags = dict((word, cfd[word].max()) for (word,freq) in most_freq_words)
baseline_tagger = nltk.UnigramTagger(model=likely_tags)
baseline_tagger.evaluate(brown.tagged_sents(categories='news'))
out:0.45578495136941344
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
sent = brown.sents(categories='news')[3]
baseline_tagger.tag(sent)
- 1
- 2

11.N-gram标注
#一元模型
from nltk.corpus import brown
brown_tagged_sents = brown.tagged_sents(categories='news')
brown_sents = brown.sents(categories='news')
unigram_tagger = nltk.UnigramTagger(brown_tagged_sents)
print (unigram_tagger.tag(brown_sents[2007]))
print (unigram_tagger.evaluate(brown_tagged_sents))
- 1
- 2
- 3
- 4
- 5
- 6
- 7

#分离训练与测试数据
size = int(len(brown_tagged_sents) * 0.9)
print (size)
train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size:]
unigram_tagger = nltk.UnigramTagger(train_sents)
unigram_tagger.evaluate(test_sents)
out:
4160
0.8121200039868434
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
#一般N-gram标注
bigram_tagger = nltk.BigramTagger(train_sents)
bigram_tagger.tag(brown_sents[2007])
unseen_sent = brown_sents[4203]
bigram_tagger.tag(unseen_sent)
bigram_tagger.evaluate(test_sents)
out:0.10206319146815508
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
12.储存标注器
from pickle import dump
output = open('t2.pkl','wb')
dump(t2,output,-1)
output.close()
#加载标注器
from pickle import load
input = open('t2.pkl', 'rb')
tagger = load(input)
input.close()
tagger.tag(brown_sents[22])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

13.组合标注器
t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train_sents, backoff=t0)
t2 = nltk.BigramTagger(train_sents, backoff=t1)
t2.evaluate(test_sents)
out:0.8452108043456593
- 1
- 2
- 3
- 4
- 5
- 6
14.跨句子边界标注
brown_tagged_sents = brown.tagged_sents(categories='news')
brown_sents = brown.sents(categories='news')
size = int(len(brown_tagged_sents) * 0.9)
train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size:]
t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train_sents, backoff=t0)
t2 = nltk.BigramTagger(train_sents, backoff=t1)
t2.evaluate(test_sents)
out:0.8452108043456593
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/348938
推荐阅读
相关标签

