
- 1中国大学生计算机设计大赛—人工智能实践赛赛道—赛后感想_计算机设计大赛人工智能赛道
- 2今日AI:多模态大模型Claude3发布;Gorq API开放申请;ChatGPT新增朗读功能;Stability AI发布SD3技术报告_claude3 下载
- 3使用QT鼠标事件mousePressEvent+opencv在ui上获取任意形状roi感兴趣区域c/c++_qt在图片上绘制roi并且获取其坐标
- 4python实现文本翻译_python语句翻译
- 5【深度学习&NLP】深度学习及NLP模型实现要点(实现一个深度学习NLP模型需要考虑的步骤)_nlp模型搭建
- 6opensll 证书及CRL生成_openssl 生成crl
- 7基于STM32单片机的温控系统(PID算法)_stm32 pid温度控制
- 8SpringCloud微服务架构项目基本实现思路梳理(后续有新的继续更新)_springcloud微服务架构完整流程、设计思路
- 9八. 实战:CUDA-BEVFusion部署分析-学习BEVPool的优化方案_bvefusion实际运用
- 10SpringBoot 项目中 对http调用异常处理_org.springframework.web.client.httpclienterrorexce
对话机器人_pyth会话机器人on用keras中训练
赞
踩
【居然审核不通过……内容低俗,这么高大上的内容,哪里低俗了……】
前面写了一系列的 微信机器人,但还没涉及到自然语言处理(Natural Language Processing, NLP)。今天把这坑填上。本文将基于 Seq2Seq 模型和Little Yellow Chicks 数据集(估计就是这个数据集低俗了),搭建一个简单的对话机器人。
原理
网上介绍 Seq2Seq 的文章太多了,我也不太可能写出更好的讲解,索性就更通俗地介绍吧。
从线性回归说起
先回忆一下线性回归。线性回归是统计学的范畴,关键词是线性和回归。
线性
线性是说两个变量之间的关系是一次函数关系——图像是直线,每个自变量的最高次项为 1。至少在中学的时候,我们就学过一元一次函数,一般写作 y = k x + b y=kx+b y=kx+b,其中 k、b 是常数,且 k ≠ 0 k\neq0 k=0。通常我们称 y 为因变量,x 为自变量(也叫元)。有一元自然有多元;有线性当然也有非线性,这里就不展开了。
回归
回归指的回归分析,是研究自变量与因变量之间数量变化关系的一种分析方法,它主要是通过因变量 y 与影响它的自变量 x 之间的回归模型,衡量自变量 x 对因变量 y 的影响能力的,进而可以用来预测因变量 y 的发展趋势。比如,人的身高和体重一般而已是有对应关系的(胖子别哭),我们便可以通过身高(x)来预测体重(y)。与回归对应还有分类,这里也不展开了。
把前面的线性和回归合起来,便是线性回归了。假设我们通过大量观测,估计出了 y = k x + b y=kx+b y=kx+b 里 k k k 和 b b b,那么,给定一个 x x x,我们将可以预测出一个 y y y;给多个 x x x,便可以预测出多个 y y y;亦即,一一对应的关系。
对于分类,我们也得到一一对应的关系,比如一张图片,我们识别出来要么是狗要么是猫,不存在即是狗又是猫。
这和今天的话题有什么关系呢?好像没啥关系,就是突然想到了……
Seq2Seq
前面提到,无论是回归还是分类,通常我们建立的都是一一对应关系(这里指的是一个输入一个输出)。但对于翻译,一一对应未必是满足需求的了。比如:
| 中文 | 英文 |
|---|---|
| 江枫 | maple-trees near the river |
| 寒山寺 | temple on the Cold Mountain |
在翻译场景下,通常就是输入一串,然后输出一串,而且通常不是一一对应的。Seq2Seq 则很好地满足这种需求。Seq2Seq 指的是 Sequence to Sequence,序列到序列。
编码器解码器结构
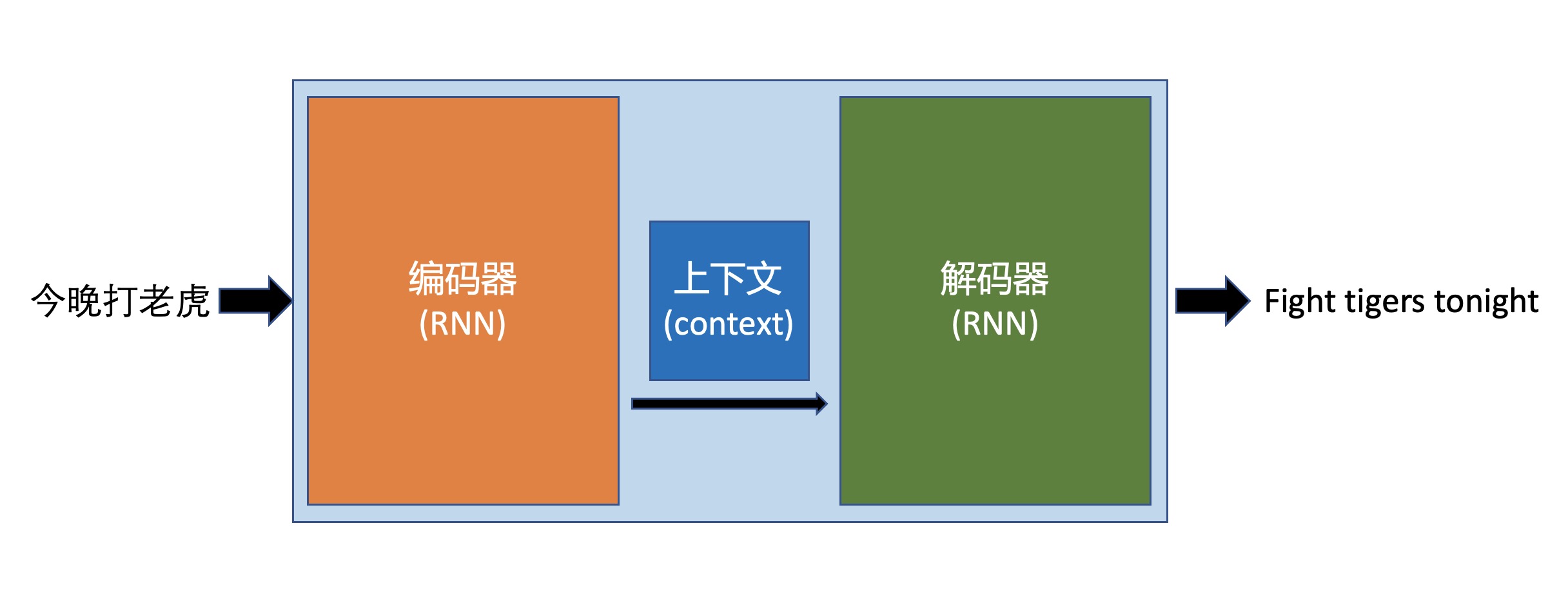
上图很直观地描述了 序列 到 序列(Seq2Seq):今晚打老虎 -> Fight tigers tonight。
一位翻译,他必须先学习本语言(编码器),同时也要学习目标语言(解码器),通过大量学习,他会形成“语感”(Context)。当来了一个翻译任务,他便能翻译出来。
更多细节,可以参考:Sequence to Sequence Learning with Neural Networks。
由翻译到闲聊
上面的翻译原理,应该是比较好理解的。但这跟闲聊有什么关系呢?
我们想想,闲聊是不是问一句,回答一句?同样是一串到一串嘛!所以,我们可以用同样的模型,将翻译语料替换成闲聊语料,便可以训练出一只对话机器人了。为了方便,直接类比翻译,构造一个输入词表一个输出词表;同时与一般的 NLP 处理不同,闲聊机器人的词表制作不需要去掉停用词。
Talk is cheap. Show me the code.

代码
数据处理
data_processing.py
# -*- coding: utf-8 -*- import io import json import logging import os import jieba import tensorflow as tf import tensorflow_probability as tfp from tqdm import tqdm def add_flag(w): return "<bos> " + w + " <eos>" class Data(object): def __init__(self, config) -> None: self.config = config self.seq_path = config["data_path"] + config["dataset"] + ".data" self.conv_path = config["data_path"] + config["dataset"] + ".conv" self.conv_size = os.path.getsize(self.conv_path) self.vacab_path_in = config["data_path"] + config["dataset"] + ".vin" self.vacab_path_out = config["data_path"] + config["dataset"] + ".vout" self.max_length = config["max_length"] self.batch_size = config["batch_size"] self.LOG = logging.getLogger("Data") logging.basicConfig(level=logging.INFO) jieba.setLogLevel(logging.INFO) # Disable debug info def create_sequences(self): if os.path.exists(self.seq_path): # Skip if processed data exists return if not os.path.exists(self.conv_path): self.LOG.info("找不到语料文件,请检查路径") exit() self.LOG.info("正在处理语料") with tqdm(total=self.conv_size) as pbar, open(self.conv_path, encoding="utf-8") as fin, open(self.seq_path, "w") as fout: one_conv = "" # 存储一次完整对话 for line in fin: pbar.update(len(line.encode("utf-8"))) line = line.strip("\n") if not line: # Skip empty line continue # Refer to dataset format: E M M if line[0] == self.config["e"]: # E, end of conversation, save it if one_conv: fout.write(one_conv[:-1] + "\n") one_conv = "" elif line[0] == self.config["m"]: # M, question or answer, split them with \t one_conv = one_conv + str(" ".join(jieba.cut(line.split(" ")[1]))) + "\t" def create_vacab(self, lang, vocab_path, vocab_size): if os.path.exists(vocab_path): # Skip if exists return tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=vocab_size, oov_token="<UNK>") tokenizer.fit_on_texts(lang) with open(vocab_path, "w", encoding="utf-8") as f: f.write(tokenizer.to_json(ensure_ascii=False)) self.LOG.info(f"正在保存: {vocab_path}") def create_vacabularies(self): if os.path.exists(self.vacab_path_in) and os.path.exists(self.vacab_path_out): # Skip if exists return self.LOG.info(f"正在创建字典") lines = io.open(self.seq_path, encoding="UTF-8").readlines() word_pairs = [[add_flag(w) for w in l.split("\t")] for l in lines] input, target = zip(*word_pairs) self.create_vacab(input, self.vacab_path_in, self.config["vacab_size_in"]) self.create_vacab(target, self.vacab_path_out, self.config["vacab_size_out"]) def tokenize(self, path): # Load tokenizer from file with open(path, "r", encoding="utf-8") as f: tokenize_config = json.dumps(json.load(f), ensure_ascii=False) tokenizer = tf.keras.preprocessing.text.tokenizer_from_json(tokenize_config) return tokenizer def process(self): self.create_sequences() self.create_vacabularies() def load(self): self.process() # Process dataset if not did before self.LOG.info("正在加载数据") lines = io.open(self.seq_path, encoding="UTF-8").readlines() word_pairs = [[add_flag(w) for w in l.split("\t")] for l in lines] words_in, words_out = zip(*word_pairs) tokenizer_in = self.tokenize(self.vacab_path_in) tokenizer_out = self.tokenize(self.vacab_path_out) tensor_in = tokenizer_in.texts_to_sequences(words_in) tensor_out = tokenizer_out.texts_to_sequences(words_out) tensor_in = tf.keras.preprocessing.sequence.pad_sequences( tensor_in, maxlen=self.max_length, truncating="post", padding="post") tensor_out = tf.keras.preprocessing.sequence.pad_sequences( tensor_out, maxlen=self.max_length, truncating="post", padding="post") self.steps_per_epoch = len(tensor_in) // self.batch_size BUFFER_SIZE = len(tensor_in) dataset = tf.data.Dataset.from_tensor_slices((tensor_in, tensor_out)).shuffle(BUFFER_SIZE) dataset = dataset.batch(self.batch_size, drop_remainder=True) return dataset, tokenizer_in, tokenizer_out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
Seq2Seq 模型
seq2seq.py
# -*- coding: utf-8 -*- import logging import os os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3" # Disable Tensorflow debug message import jieba import tensorflow as tf from tqdm import tqdm from data_processing import Data, add_flag class Encoder(tf.keras.Model): def __init__(self, vocab_size, embedding_dim, enc_units, batch_size): super(Encoder, self).__init__() self.enc_units = enc_units self.batch_size = batch_size self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim) self.gru = tf.keras.layers.GRU(self.enc_units, return_sequences=True, return_state=True) def call(self, X): X = self.embedding(X) output, state = self.gru(X) return output, state class Decoder(tf.keras.Model): def __init__(self, vocab_size, embedding_dim, dec_units, batch_size): super(Decoder, self).__init__() self.batch_size = batch_size self.dec_units = dec_units self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim) self.gru = tf.keras.layers.GRU(self.dec_units, return_sequences=True, return_state=True) self.fc = tf.keras.layers.Dense(vocab_size) def call(self, X, state, **kwargs): X = self.embedding(X) context = tf.reshape(tf.repeat(state, repeats=X.shape[1], axis=0), (X.shape[0], X.shape[1], -1)) X_and_context = tf.concat((X, context), axis=2) output, state = self.gru(X_and_context) output = tf.reshape(output, (-1, output.shape[2])) X = self.fc(output) return X, state def initialize_hidden_state(self): return tf.zeros((self.batch_size, self.dec_units)) class Seq2Seq(object): def __init__(self, config): self.config = config vacab_size_in = config["vacab_size_in"] vacab_size_out = config["vacab_size_out"] embedding_dim = config["embedding_dim"] self.units = config["layer_size"] self.batch_size = config["batch_size"] self.encoder = Encoder(vacab_size_in, embedding_dim, self.units, self.batch_size) self.decoder = Decoder(vacab_size_out, embedding_dim, self.units, self.batch_size) self.optimizer = tf.keras.optimizers.Adam() self.checkpoint = tf.train.Checkpoint(optimizer=self.optimizer, encoder=self.encoder, decoder=self.decoder) self.ckpt_dir = self.config["model_data"] logging.basicConfig(level=logging.INFO) self.LOG = logging.getLogger("Seq2Seq") if tf.io.gfile.listdir(self.ckpt_dir): self.LOG.info("正在加载模型") self.checkpoint.restore(tf.train.latest_checkpoint(self.ckpt_dir)) data = Data(config) self.dataset, self.tokenizer_in, self.tokenizer_out = data.load() def loss_function(self, real, pred): loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) mask = tf.math.logical_not(tf.math.equal(real, 0)) loss_ = loss_object(real, pred) mask = tf.cast(mask, dtype=loss_.dtype) loss_ *= mask return tf.reduce_mean(loss_) @tf.function def training_step(self, src, tgt, tgt_lang): loss = 0 with tf.GradientTape() as tape: enc_output, enc_hidden = self.encoder(src) dec_hidden = enc_hidden dec_input = tf.expand_dims([tgt_lang.word_index["bos"]] * self.batch_size, 1) for t in range(1, tgt.shape[1]): predictions, dec_hidden = self.decoder(dec_input, dec_hidden) loss += self.loss_function(tgt[:, t], predictions) dec_input = tf.expand_dims(tgt[:, t], 1) step_loss = (loss / int(tgt.shape[1])) variables = self.encoder.trainable_variables + self.decoder.trainable_variables gradients = tape.gradient(loss, variables) self.optimizer.apply_gradients(zip(gradients, variables)) return step_loss def train(self): writer = tf.summary.create_file_writer(self.config["log_dir"]) self.LOG.info(f"数据目录: {self.config['data_path']}") epoch = 0 train_epoch = self.config["epochs"] while epoch < train_epoch: total_loss = 0 iter_data = tqdm(self.dataset) for batch, (src, tgt) in enumerate(iter_data): batch_loss = self.training_step(src, tgt, self.tokenizer_out) total_loss += batch_loss iter_data.set_postfix_str(f"batch_loss: {batch_loss:.4f}") self.checkpoint.save(file_prefix=os.path.join(self.ckpt_dir, "ckpt")) epoch = epoch + 1 self.LOG.info(f"Epoch: {epoch}/{train_epoch} Loss: {total_loss:.4f}") with writer.as_default(): tf.summary.scalar("loss", total_loss, step=epoch) def predict(self, sentence): max_length = self.config["max_length"] sentence = " ".join(jieba.cut(sentence)) sentence = add_flag(sentence) inputs = self.tokenizer_in.texts_to_sequences([sentence]) inputs = [[x for x in inputs[0] if x if not None]] # Remove None. TODO: Why there're None??? inputs = tf.keras.preprocessing.sequence.pad_sequences(inputs, maxlen=max_length, padding="post") inputs = tf.convert_to_tensor(inputs) enc_out, enc_hidden = self.encoder(inputs) dec_hidden = enc_hidden dec_input = tf.expand_dims([self.tokenizer_out.word_index["bos"]], 0) result = "" for _ in range(max_length): predictions, dec_hidden = self.decoder(dec_input, dec_hidden) predicted_id = tf.argmax(predictions[0]).numpy() if self.tokenizer_out.index_word[predicted_id] == "eos": break result += str(self.tokenizer_out.index_word[predicted_id]) dec_input = tf.expand_dims([predicted_id], 0) return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
程序入口
main.py
#! /usr/bin/env python3 # -*- coding: utf-8 -*- import argparse from seq2seq import Seq2Seq if __name__ == "__main__": import argparse parser = argparse.ArgumentParser() parser.add_argument("--mode", "-m", type=str, default="serve", help="Train or Serve") parser.add_argument("--data_path", "-p", type=str, default="dataset/", help="dataset path") parser.add_argument("--log_dir", type=str, default="logs/", help="dataset path") parser.add_argument("--model_data", type=str, default="model_data", help="mode output path") parser.add_argument("--dataset", "-n", type=str, default="xiaohuangji50w", help="Train or Serve") parser.add_argument("--e", type=str, default="E", help="start flag of conversation") parser.add_argument("--m", type=str, default="M", help="start flag of conversation") parser.add_argument("--vacab_size_in", "-i", type=int, default=20000, help="vacabulary input size") parser.add_argument("--vacab_size_out", "-o", type=int, default=20000, help="vacabulary output size") parser.add_argument("--layer_size", type=int, default=256, help="layer size") parser.add_argument("--batch_size", type=int, default=128, help="batch size") parser.add_argument("--layers", type=int, default=2, help="layers") parser.add_argument("--embedding_dim", type=int, default=64, help="embedding dimention") parser.add_argument("--epochs", type=int, default=10, help="epochs") parser.add_argument("--max_length", type=int, default=32, help="max length of input") args, _ = parser.parse_known_args() config = vars(args) seq2seq = Seq2Seq(config) if args.mode.lower() == "train": seq2seq.train() else: while True: msg = input(">>> ") rsp = seq2seq.predict(msg) print(rsp)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
效果
训练
python main.py -m train
- 1
闲聊
python main.py
- 1
训练了 20 个 epochs,就这水平:

提升方向
上面的结果比较一般,一方面因为语料不多;另一方面,现在这模型也比较粗糙,后续可以从以下几方面进行提升:
- 使用更多的语料
- 使用 Bi-LSTM 构造 Encoder
- 引入 Attention

