
- 1【大道至简】机器学习算法之逻辑回归(Logistic Regression)详解(附代码)---非常通俗易懂!_逻辑回归代码
- 2HarmonyOS App开发之组件布局类_在使用java语言进行harmonyos应用开发时,常用的开发布局有( )
- 3jvm之java类加载机制和类加载器(ClassLoader),方法区结构,堆中实例对象结构的详解...
- 4深度探索 Gradle 自动化构建技术(一、Gradle 核心配置篇)_gradle构建resource
- 5Diffusion Model (扩散生成模型)的基本原理详解(一)Denoising Diffusion Probabilistic Models(DDPM)
- 6Android客户端性能异常类_segv_accerr
- 7Raft对比ZAB协议_raft 对比
- 8环信 IM+AI编程挑战赛开启报名!
- 9【笔记】两台1200PLC进行S7 通信(1)_两个1200做s7通讯
- 10优雅的从HuggingFace下载模型_huggingface上下载模型哪些是必须的
接口自动化测试(四)_完善框架目录_接口自动化框架目录
赞
踩
接口自动化测试(四)~接口自动化测试(五)源码:https://download.csdn.net/download/qq_38175040/20469673
一.接口自动化框架的目录
前三篇只是在学习搭建接口自动化测试框架的基础库request和pytest,现在开始正式搭建接口自动化测试框架。
首先以之前搭建过的关键字驱动的UI自动化测试化框架为例,里面有公用方法文件夹,测试数据,测试用例,日志,测试报告等等:
新建一个项目,并在项目内新建这些文件夹,整个接口自动化测试框架的雏形就搭建好了,接下来要做的就是完善这个框架,填充这些文件夹的内容了。
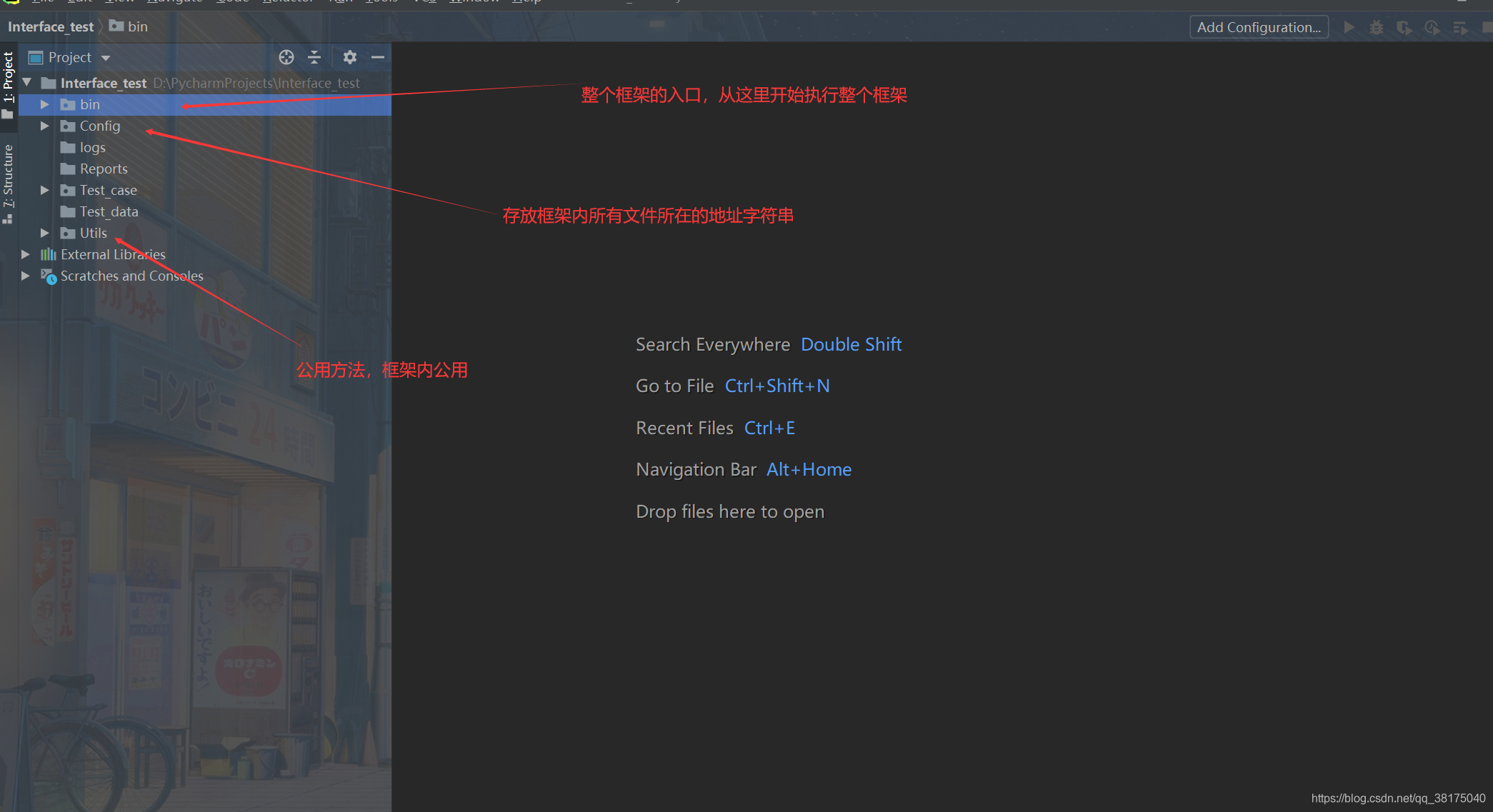
Tips:接口请求中,向接口发送的数据有些是可以随便填的,但有些数据一定是从其他接口那里获得的,比如session,id等等。
二.完善框架
1.test_data
在Test_data目录下新建一个.xlsx文件,用来存放测试数据

暂时先定义这些列吧,视自己情况增减

2.Utils下封装公用方法
记得刚开始搭建UI自动化框架的时候,第一步就是将selenium里的find_element方法封装成公用方法,具体见:https://blog.csdn.net/qq_38175040/article/details/115673920
那么在这里也是一样的,自动化里面会有很多接口,不可能每个接口都单独处理,所以我们将request库里的一些常用请求方法封装成公用方法。

然后把request这个公用方法具体写一下:
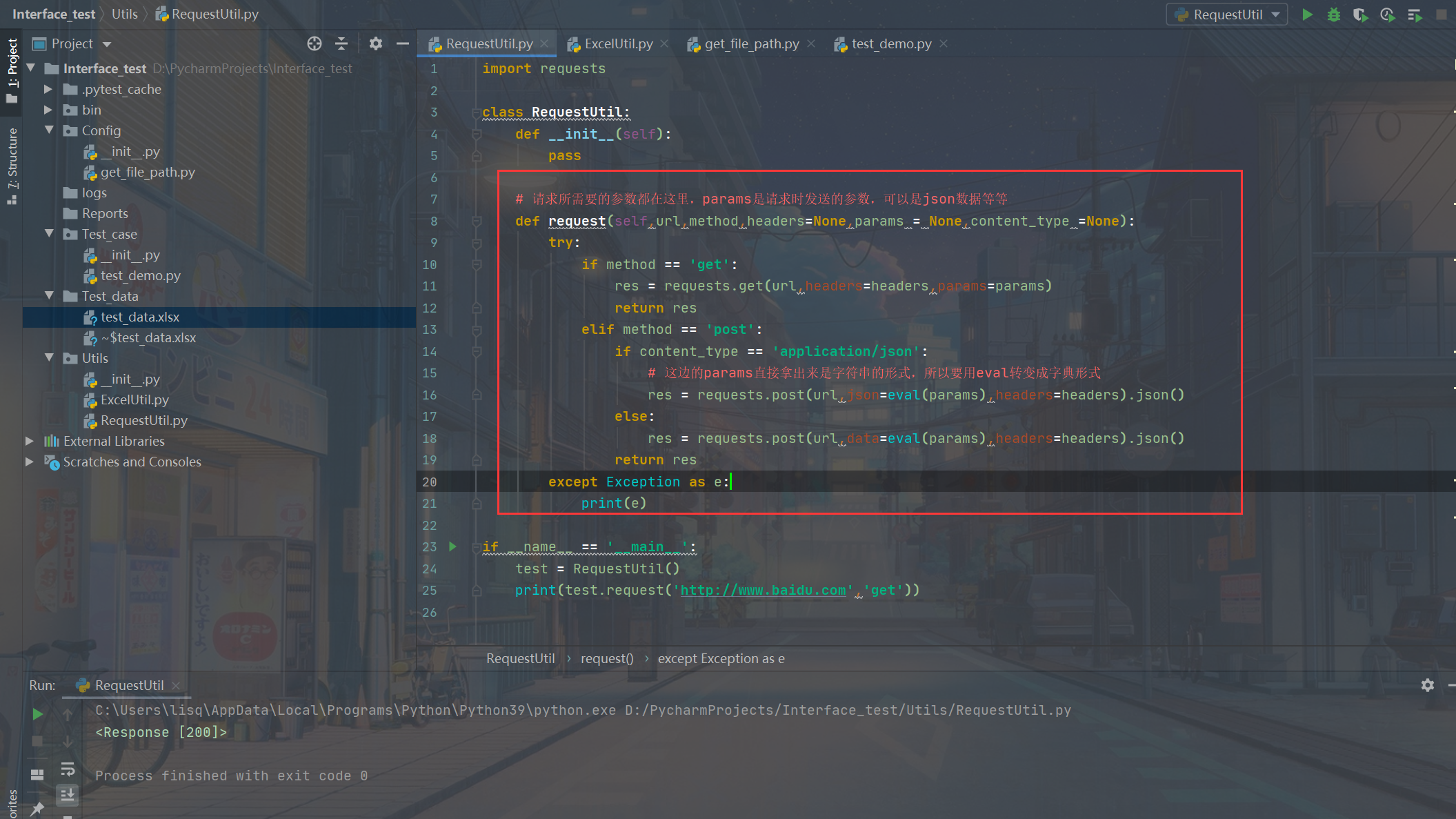
贴一下源代码:
import requests
class RequestUtil:
def __init__(self):
pass
# 请求所需要的参数都在这里,params是请求时发送的参数,可以是json数据等等
def request(self,url,method,headers=None,params = None,content_type =None):
try:
if method == 'get':
res = requests.get(url,headers=headers,params=params)
return res
elif method == 'post':
if content_type == 'application/json':
# 这边的params直接拿出来是字符串的形式,所以要用eval转变成字典形式
res = requests.post(url,json=eval(params),headers=headers).json()
else:
res = requests.post(url,data=eval(params),headers=headers).json()
return res
except Exception as e:
print(e)
if __name__ == '__main__':
test = RequestUtil()
print(test.request('http://www.baidu.com','get'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
插句题外话,我们这里的接口都是用postman工具搭建的mock接口,对于请求可以返回我们期望的响应内容,postman搭建mock server可以参考下:https://blog.csdn.net/qq_38175040/article/details/118928412
3.读取excel的接口数据
将excel里的数据补全一下

在Util下新建一个公用方法,对excel进行操作(这个方法在之前搭建关键字驱动的UI自动化测试框架的时候就写过)
当然,首先得在config里面新建个文件来获取excel文件的地址
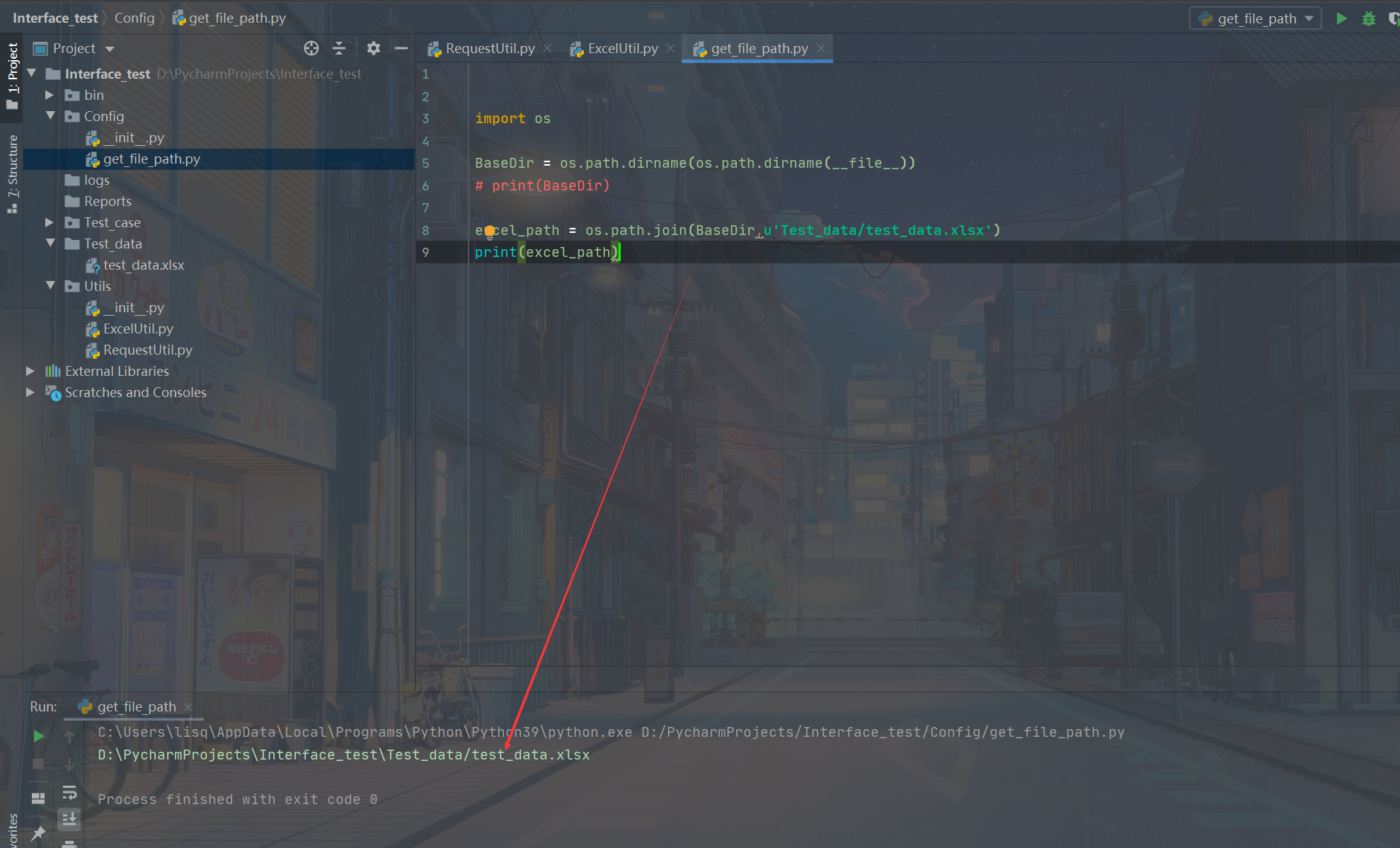 然后再在Util里创建文件ExcelUtil.py,还是像关键字驱动测试框架里那样,使用openpyxl这个库来获取excel表里的内容
然后再在Util里创建文件ExcelUtil.py,还是像关键字驱动测试框架里那样,使用openpyxl这个库来获取excel表里的内容
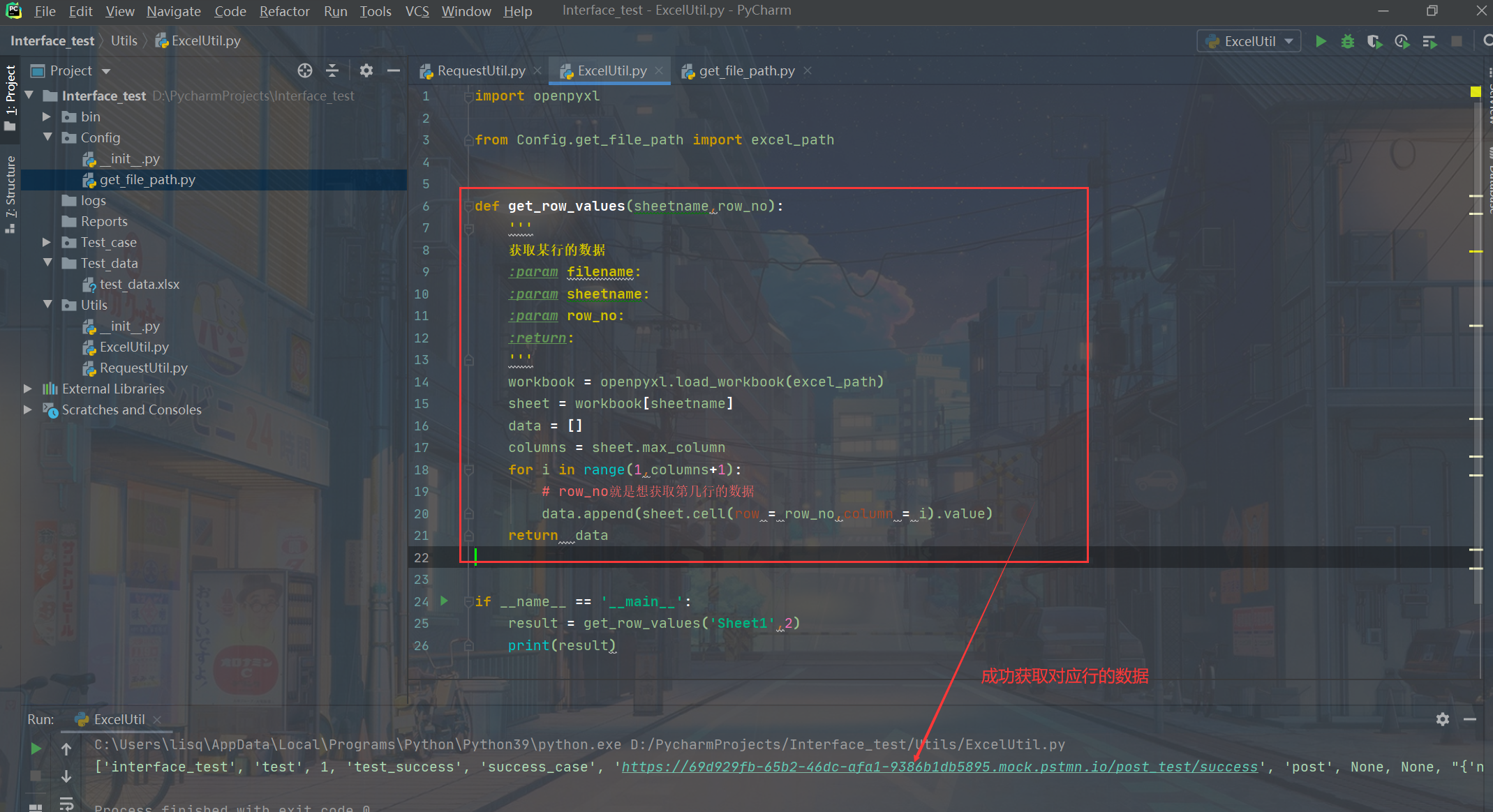
再完善一下这个公用文件,再写一个获取excel除首行外,所有其他行构成的一个集合

贴一下代码:
import openpyxl
from Config.get_file_path import excel_path
def get_row_values(sheetname,row_no):
'''
获取某行的数据
:param filename:
:param sheetname:
:param row_no:
:return:
'''
workbook = openpyxl.load_workbook(excel_path)
sheet = workbook[sheetname]
data = []
columns = sheet.max_column
for i in range(1,columns+1):
# row_no就是想获取第几行的数据
data.append(sheet.cell(row = row_no,column = i).value)
return data
def get_all_rows(sheetname):
'''
获取所有行,以[[],[],[],[]]的形式保存
:return:
'''
data = []
workbook = openpyxl.load_workbook(excel_path)
sheet = workbook[sheetname]
rows = sheet.max_row
for i in range(2,rows+1):
data.append(get_row_values(sheetname,i))
return data
if __name__ == '__main__':
result = get_row_values('Sheet1',2)
print(result)
res = get_all_rows('Sheet1')
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
4.在TestCase里创建文件,正式开始测试接口
先在测试用例文件里面调用一下上部分的内容,获取excel里的数据
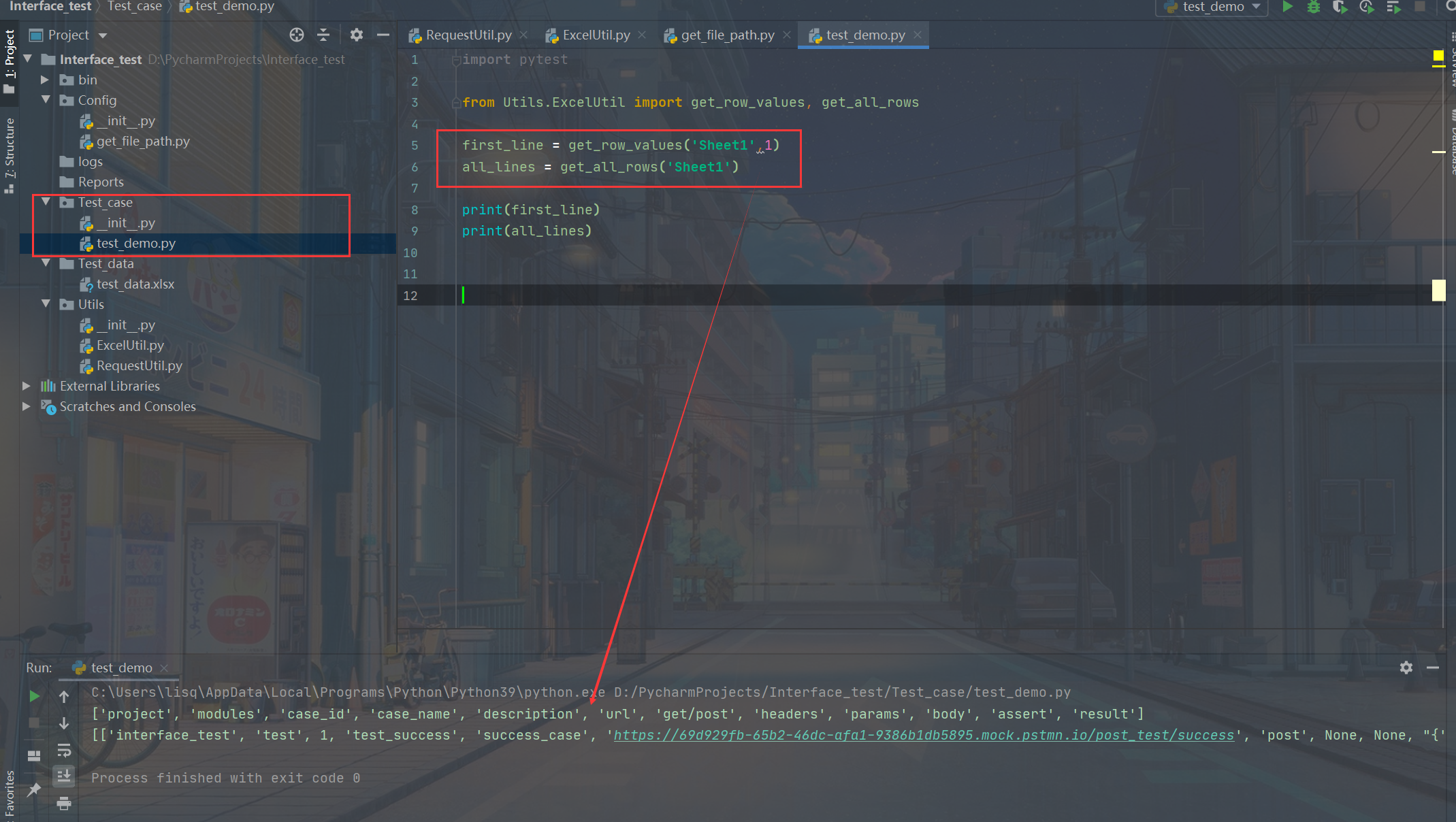
然后用pytest的parmatrize方法,将excel里的第一行作为参数传入测试用例(注意如果用到paramtrize来传参,那创建的每个参数都必须传入测试用例内,即使用不到。如果有参数被paramtrize创建但是没有被传入测试用例就会报错。)
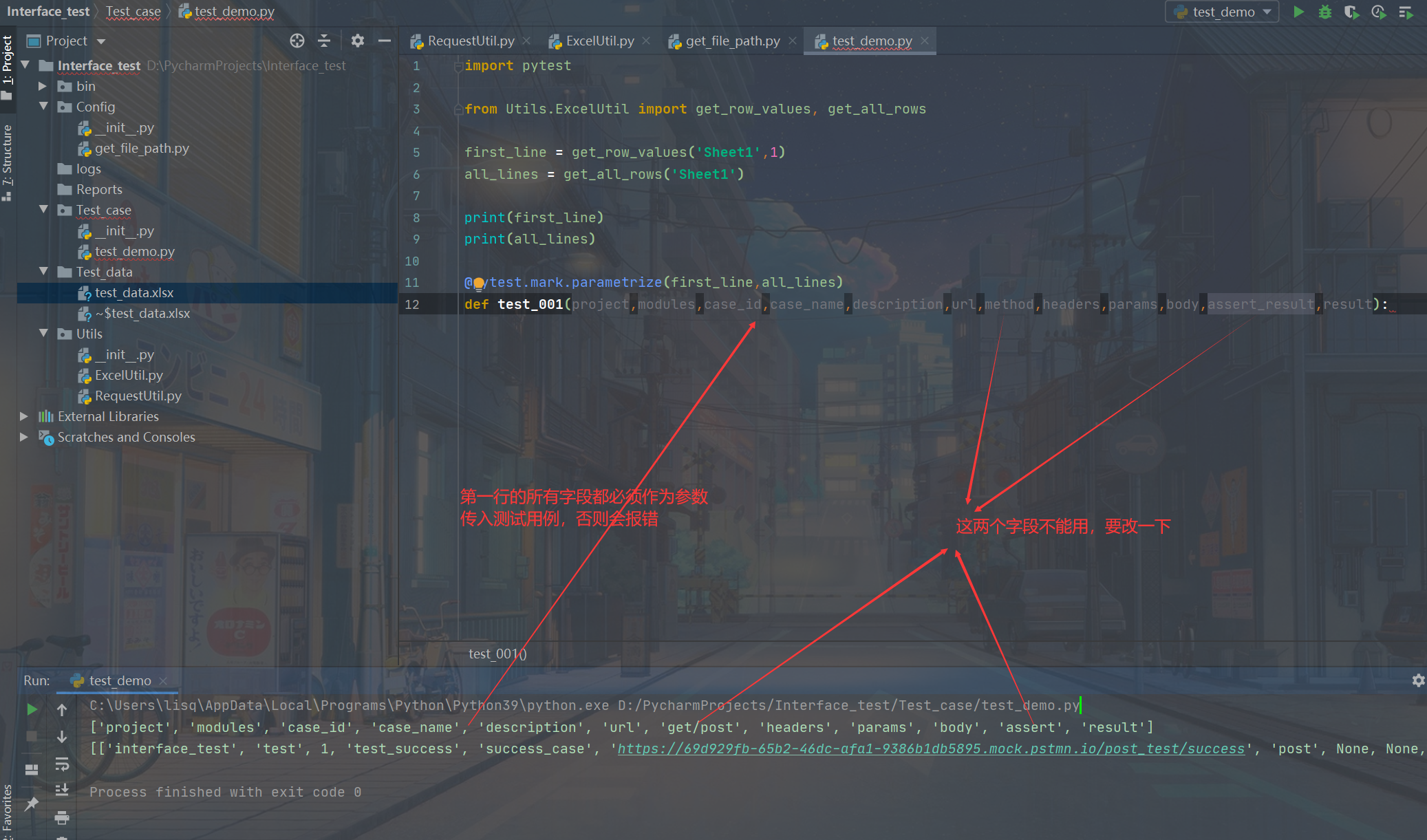
接下来大致写一下这个测试用例,三个用例运行成功,暂时还没做断言:
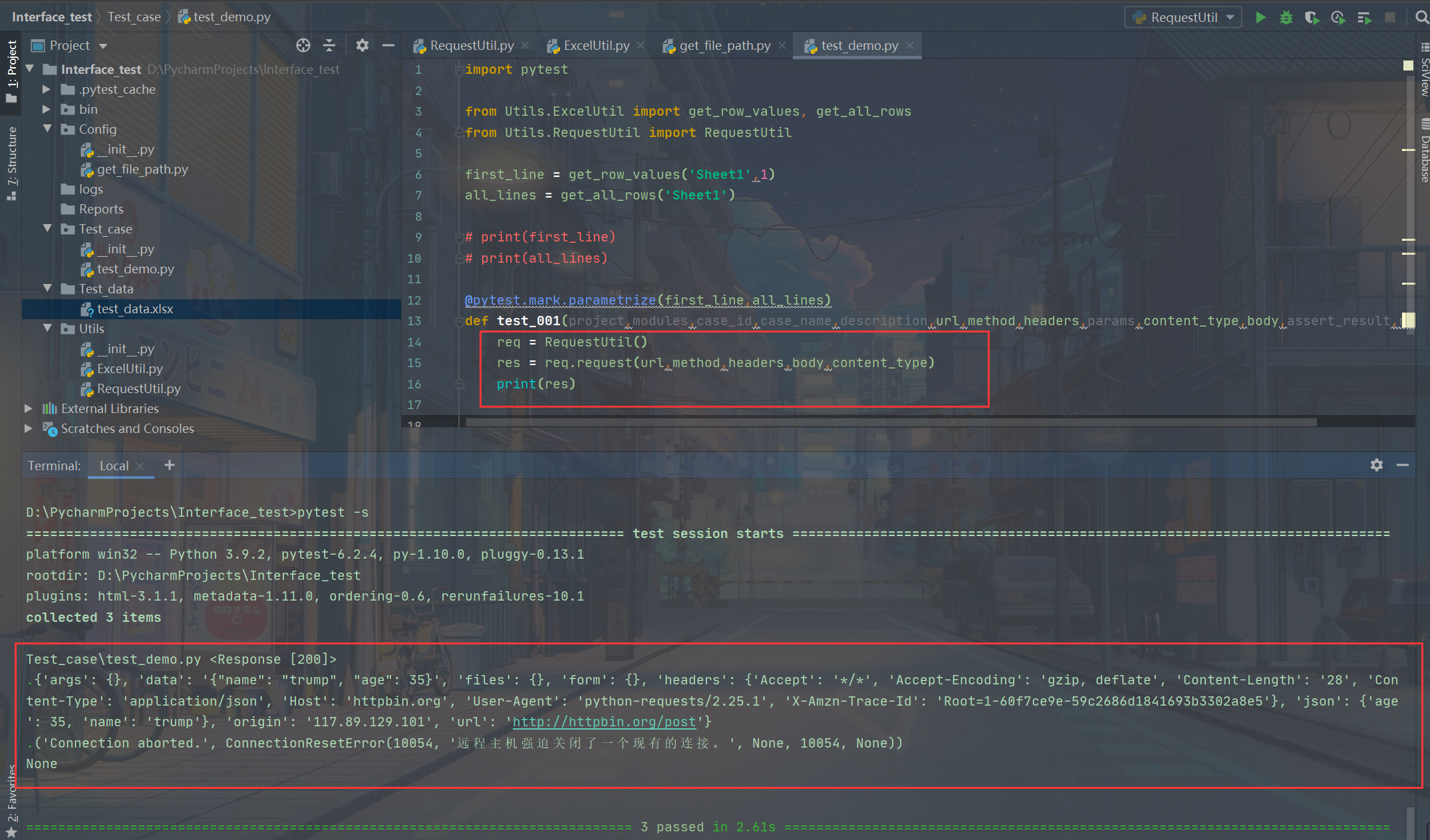
可以看到上面我两个post请求的返回不太正常哈,一个是httpbin这个网站(返回不太正常),一个拒绝访问了。事实上一个正常的post在接受到request请求后,他的response响应应该如下:

先写到这里,接下来就是对response里的响应code进行断言了,先把到这一步为止的代码贴一下吧
import pytest
from Utils.ExcelUtil import get_row_values, get_all_rows
from Utils.RequestUtil import RequestUtil
first_line = get_row_values('Sheet1',1)
all_lines = get_all_rows('Sheet1')
# print(first_line)
# print(all_lines)
@pytest.mark.parametrize(first_line,all_lines)
def test_001(project,modules,case_id,case_name,description,url,method,headers,params,content_type,body,assert_result,result):
req = RequestUtil()
res = req.request(url,method,headers,body,content_type)
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

