
热门标签
热门文章
- 1经典卷积神经网络---VGG16详解_vgg16网络结构详解
- 2如何利用 Stable Diffusion webui 将图片变得更清晰?全方位对比4种放大方法!_stable diffusion 放大 图 变清晰
- 3shell检验日期格式
- 4Redisson分布式锁解锁异常_java.lang.illegalmonitorstateexception: attempt to
- 5Python库(1)—— Numpy 科学计算库_numpy库
- 6机器学习练手(四):基于SVM 的肥胖风险分类
- 7解决windows上Git密码输入错误无法修改问题以及解决更改Git用户的用户名和密码问题_git for windows密码错误
- 8(五)【平衡小车制作】位置式PID、直立环与速度环概念_平衡小车用位置
- 9期权基础:上证50ETF期权买一手多少钱?_50etf购 行权价
- 10漆包线行业生产管理革新:万界星空科技MES系统解决方案_漆包线 mes
当前位置: article > 正文
LLM-大模型演化分支树、GPT派发展阶段及训练流程图、Infini-Transformer说明_llm的三大流派
作者:笔触狂放9 | 2024-07-29 23:38:06
赞
踩
llm的三大流派
大模型是怎么演进的?
- Encoder Only: 对应粉色分支,即BERT派,典型模型: BERT
- 自编码模型(Autoencoder Model):通过重建句子来进行预训练,通常用于理解任务,如文本分类和阅读理解
- 模型像一个善于分析故事的专家,输入一段文本,能拆解的头头是道,本质上是把高维数据压缩到低维空间,
- Decoder Only: 对应蓝色分支,GPT派, 典型模型: GPT4, LLaMA
- 自回归模型(Autoregressive Model):通过预测序列中的下一个词来进行预训练,通常用于文本生成任务
- 模型像一个会讲故事的专家,给点提示,就能流畅的接着自说自话
- Encoder-Decoder: 对应绿色分支,T5派, 典型模型: T5, ChatGLM
- 序列到序列模型(Sequence to Sequence Model):结合了编码器和解码器,通常用于机器翻译和文本摘要等任务
- 模型像一个“完型填空专家”,是因为它特别擅长处理这种类型的任务。通过将各种NLP任务统一转换为填空问题,T5派能够利用其强大的语言理解和生成能力来预测缺失的文本。这种方法简化了不同任务之间的差异,使得同一个模型可以灵活地应用于多种不同的NLP任务,并且通常能够在多个任务上取得很好的性能

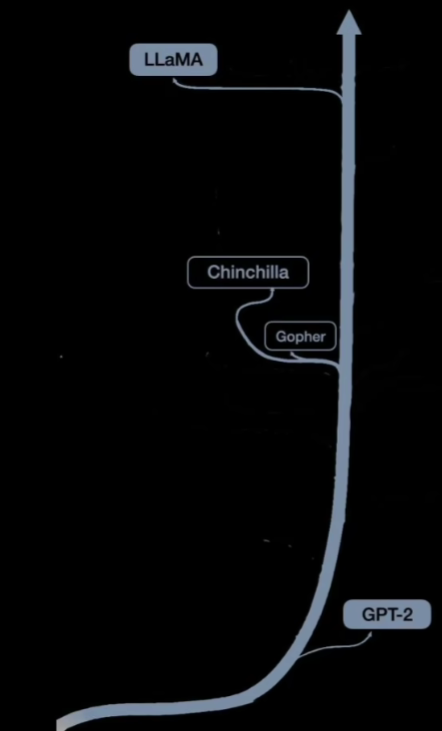
GPT派发展阶段
- GOOGLE 的Gopher验证了通过扩大模型规模,有效处理复杂任务的可行性
- Chinchilla模型 验证了增加数据比增加模型参数更有效
- LLaMA模型:用不到1/10的参数,实现了堪比GPT系列模型的性能,成为当下最流行的开源大模型
大模型训练流程图
- 第一步 预训练是鸿沟,算力占全部的99%以上,【LLaMA 模型开源后,为众多以LLaMA 为基础模型的其它模型节约的成本】
- 数据集: LLaMA 2采用互联网公开数据集,经2万亿token, 每个单词约1.3个token,相当于1.5万亿个单词,约55亿页书,
- 算法:LLaMA 及其子孙模型在传统的解码器架构上,进行了多个改进,
- 输入数据使用了均方层规一化函数 RMSNorm,大大提升了训练的稳定性

- 激活函数用swiGLU替换了ReLU,提升了非线性的表征能力
- 不再使用位置嵌入,而是在网络每层增加了旋转嵌入RoPE,速度更快,效果更好
- 输入数据使用了均方层规一化函数 RMSNorm,大大提升了训练的稳定性
- 奖励建模和强化学习都是基于人类反馈强化学习RLHF【Reinforcement Learning from Human Feedback】
- 先训一个二元分类器,给出奖励,判断人类的偏好,
- 然后再训一个强大学习算法,最大化奖励,并据此进一步微调模型,
- SFT Model【Supervised Fine-Tuning Model】

Infini-Transformer架构
4月10日,为解决大模型(LLMs)在处理超长输入序列时遇到的内存限制问题, Google发布下一代Transformer模型Infini-Transformer
详见论文:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
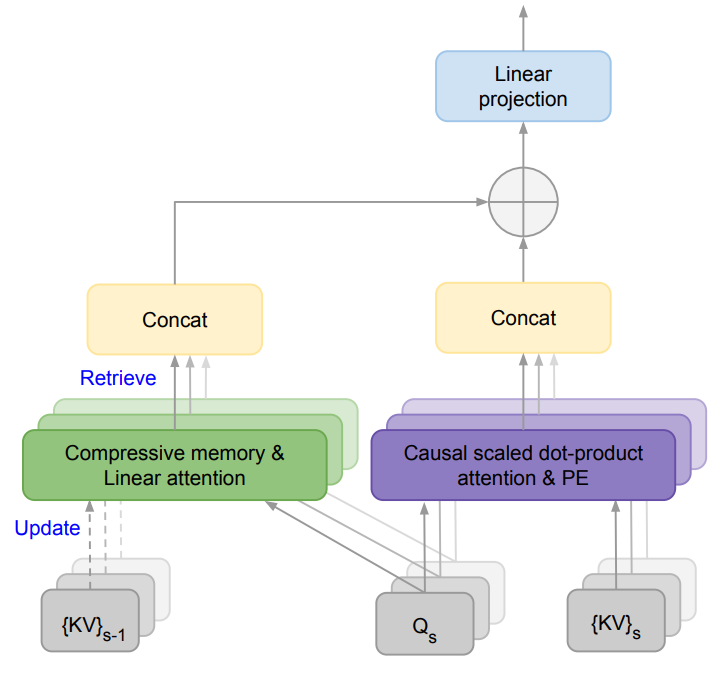
Infini-Transformer是一种为了扩展基于Transformer的大型语言模型(LLMs)以处理无限长输入而设计的高效方法。其核心技术是Infini-attention,这是一种新的注意力机制,它通过将压缩记忆(compressive memory)整合到传统的注意力机制中,从而实现了对长序列数据的有效处理。
Infini-Attention机制
Infini-attention机制包含以下几个关键组件:
- 局部注意力(Local Attention):在每个输入段(segment)内,Infini-Transformer计算标准的因果点积注意力(causal dot-product attention)。这种局部注意力确保了在处理每个段时,模型仅关注当前段内的token。
- 压缩记忆(Compressive Memory):Infini-attention通过重用点积注意力计算中的关键(key)、值(value)和查询(query)状态,将它们存储在压缩记忆中。这种记忆允许模型在处理后续序列时,通过查询状态从记忆中检索值,从而保持对之前上下文的长期记忆。
- 长期线性注意力(Long-term Linear Attention):Infini-attention引入了一种线性注意力机制,它使用关联矩阵(associative matrix)来存储和检索信息。这种机制使得模型能够在保持固定数量参数的同时,处理任意长度的序列。
长期上下文建模
Infini-Transformer通过以下步骤实现长期上下文建模:
- 记忆检索(Memory Retrieval):在处理新的输入段时,Infini-attention使用当前的查询状态从压缩记忆中检索与之前上下文相关的信息。
- 记忆更新(Memory Update):随着新信息的加入,压缩记忆会被更新以反映最新的上下文信息。这个过程涉及到将新的键值对与记忆矩阵相结合,同时保持记忆的压缩性质。
- 上下文注入(Context Injection):Infini-attention通过学习门控标量(gating scalar)β来平衡局部注意力状态和从记忆中检索到的内容,将它们融合到最终的上下文表示中。
实验结果
在长上下文语言建模、1M长度的密钥上下文块检索和500K长度的书籍摘要任务中,Infini-Transformer展示了其有效性。实验结果表明,Infini-Transformer在长上下文任务上的性能超过了基线模型,并且在内存大小方面实现了114倍的压缩比。
总结
Infini-Transformer通过引入Infini-attention机制,使得Transformer LLMs能够有效地处理无限长的输入序列,同时保持有界的内存占用和计算资源。这种方法通过在单个Transformer块中结合局部注意力和长期线性注意力机制,实现了对长距离依赖关系的高效建模。Infini-Transformer的提出,为长序列数据的处理提供了一种新的解决方案,具有重要的理论和实践意义。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

