
- 1so文件反编译_安卓攻防so模块自动化修复实战
- 2筛斗数据:数据提取技术,构建智慧企业的基石
- 3iOS 封装下载网络文件工具_ios 下载器封装
- 4qemu前后端features协商过程分析(vhost_user后端)_前后端协商的feature
- 5机器学习实战(三)—K均值聚类算法_离散隐变量
- 6mybatis oracle数据库批量新增、更新_mybatis oracle 批量更新
- 7无人机航电系统技术详解
- 8Flink任务调度原理之TaskManager 与Slots_flink的slot 和taskmanager
- 9BFS算法笔记_flood fill 路径
- 10接口自动化常见面试题_接口自动化面试必会6题经典
从零实现诗词GPT大模型:数据集介绍和预处理_诗词数据集
赞
踩
专栏规划: https://qibin.blog.csdn.net/article/details/137728228
本章将介绍该系列文章中使用的数据集,并且编写预处理代码,处理成咱们需要的格式。
一、数据集介绍
咱们使用的数据集名称是chinese-poetry,是一个在github上开源的中文诗词数据集,根据仓库中readme.md中的介绍,该数据集是最全的中华古典文集数据库,包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。
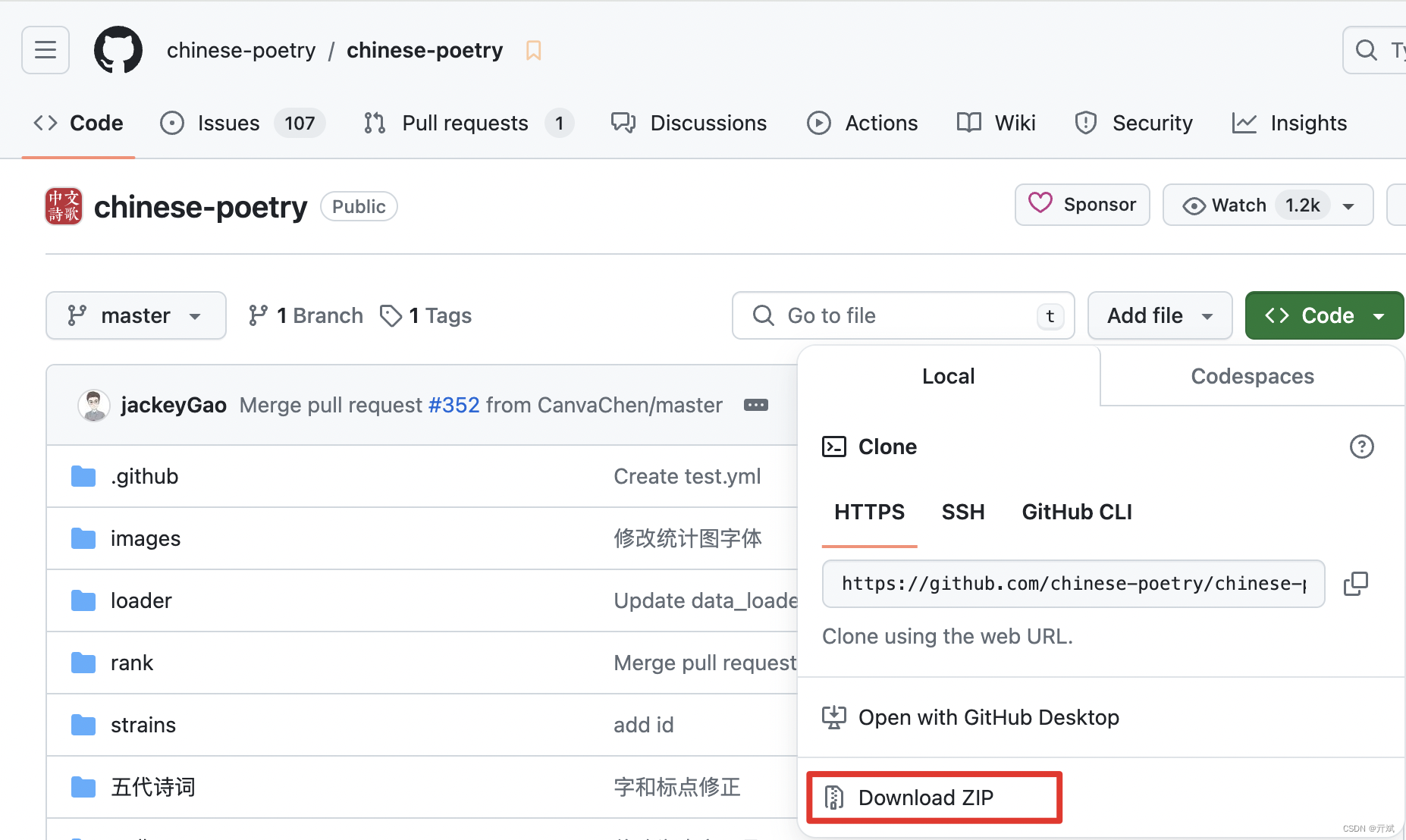
数据集的下载地址:https://github.com/chinese-poetry/chinese-poetry?tab=readme-ov-file,大家可以点击Code按钮,选择Download ZIP将该数据集下载到本地,如下图:
当然,作者收集数据也不易,大家可以顺手点一下star鼓励一下作者,如图:

如果你按照上面的步骤,把数据集下载到你本地了,解压后你可以看到如下图所示的目录结构
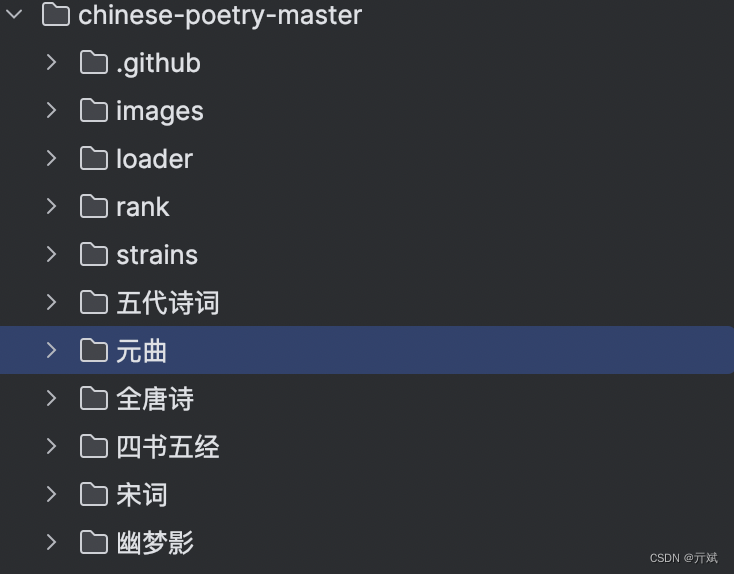
作者按照不同诗词类型进行了分类,并且在每个分类下提供了1个到多个的json文件,json文件里按照结构化数据组织了每一个诗词的信息,如下图

二、数据集预处理
上面咱们详细介绍了chinese-poetry数据集的下载方式和作者组织的结构,下面我们将提取每个诗词的标题和内容作为我们需要的部分,并聚合到一个文件中,以方便我们后续训练模型使用。
首先,我们需要把作者提供的诗词类目整理到一个数组中,方便我们后续进行目录的变量
classes = ['五代诗词', '元曲', '全唐诗', '四书五经', '宋词', '幽梦影', '御定全唐詩', '曹操诗集', '楚辞', '水墨唐诗',
'纳兰性德', '蒙学', '论语', '诗经']
- 1
- 2
然后,我们可以遍历该数组,拼接一个目录,遍历目录中中的文件,再进行文件处理
for cls in classes:
dir = base_dir + cls
files = os.listdir(dir)
for f in files:
f = f'{dir}/{f}'
if os.path.isdir(f):
if 'error' in f:
continue
for ff in os.listdir(f):
process_json(f'{f}/{ff}')
else:
process_json(f)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上面代码中,我们遍历每个类别的目录后,会列出该类别中所有的文件,文件如果是一个目录,则继续遍历这个目录,因为作者提供的目录结构会存在二级目录的情况。
最后,拿到每个json文件后,会调用process_json()函数处理对应的json文件。下面我们开始介绍process_json()函数。
process_json()函数会对上面代码中拿到的每个json文件进行处理,并且从json文件中提取我们需要的信息(诗词的标题和内容),重新组织结构,写入到一个新文件中;该函数还会根据一个简单的策略划分出训练集和测试集(训练集用来训练我们的模型,测试集用来在训练过程中测试模型的性能)。整体代码如下
def process_json(file): if not file.endswith('.json'): return with open(file, 'r') as f: json_content = f.read() array = json.loads(json_content) if type(array) != list: return if len(array) > 100: train_array = array[:-1] test_array = array[-1:] else: train_array = array test_array = None for item in train_array: if 'title' not in item.keys() or 'paragraphs' not in item.keys(): continue write_file(item, dst_train_file) if test_array is not None: for item in test_array: if 'title' not in item.keys() or 'paragraphs' not in item.keys(): continue write_file(item, dst_test_file)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
在代码中,首先会打开该json文件,并读取json文件中的内容;读到内容后,通过json.loads()函数将它解码成在python中可以识别的数据结构。
接下来,我们根据该分类下诗词的数据决定是否要划分出测试集,策略很简单,如果个数大于100,我们就把最后一个作为测试集的一部分,当然这个策略可以根据你的需求进行调整。
最后,我们从json中拿到title和paragraphs属性通过一个write_file()函数写到我们的新文件中。
write_file()函数的实现也很简单,作用就是拿到title和paragraphs,组织好结构写入到一个新文件中;我们预处理后的文件不会像原数据集那样提供多个文件,而是全部写到同一个文件中,所以,此时就得考虑一个问题:所有的诗词在一个文件中,怎么标识出一首诗结束了呢?办法很简单,我们在没首诗结束的时候添加一个<|endoftext|>特殊标识,该标识很重要,因为在后面我们训练模型的时候,该标识也会根据此标识学习一首诗到哪结束了(不需要结束,咱们模型就无止境的输出了)。
def write_file(item, dst_file):
global error_count
title = item['title']
paragraphs = item['paragraphs']
content = f'\n{title}'
for p in paragraphs:
content = f'{content}\n{p}'
content = converter.convert(content)
if '声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/815390Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

