
- 1Github 2024-06-26 C开源项目日报 Top10
- 2鸿蒙OS开发实例:【ArkTS类库异步并发简述Promise】_鸿蒙开发[object promise]
- 3小白篇--如何在本地搭建 go环境
- 4Linux系统资源监控nmon工具下载及使用介绍_linux 在线下载 nmon
- 5第七篇:微信小程序的跳转页面_小程序跳转页面
- 6使用supportFragmentManager管理多个fragment切换_the fragment supportrequestmanagerfragment{45c75e5
- 7Linux中永久挂载_linux永久挂载
- 8数电(第一章 数制和码制)_数电第一章
- 9基于STM32单片机智能无人机姿态检测MPU6050陀螺仪角度设计23-179_单片机控制陀螺仪
- 10基于Visual Studio Code搭建Python开发环境_vscode配置python开发环境_visual studio code python
Windows 环境部署 ChatGLM2-6b 入门教程_windows 部署chatglm
赞
踩
介绍
ChatGLM2-6B是智谱AI及清华KEG实验室发布的中英双语对话模型,它是 ChatGLM-6B 的第二代版本。
主要特点:
-
性能提升:ChatGLM2-6B 在初代模型的基础上进行了全面升级,使用了 GLM 的混合目标函数,并经过了 1.4T 中英标识符的预训练与人类偏好对齐训练。在多个数据集上的性能相较于初代模型有了显著提升,例如在 MMLU 上提升了 23%,在 CEval 上提升了 33%,在 GSM8K 上提升了 571%,在 BBH 上提升了 60%。
-
更长的上下文处理能力:利用 FlashAttention 技术,ChatGLM2-6B 的上下文长度从 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度进行训练,这允许了更多轮次的对话。
-
高效的推理速度:基于 Multi-Query Attention 技术,ChatGLM2-6B 拥有更高效的推理速度和更低的显存占用。与初代模型相比,推理速度提升了 42%,在 INT4 量化下,6G 显存支持的对话长度从 1K 提升到了 8K。
-
开放的协议:ChatGLM2-6B 的权重对学术研究完全开放,并在获得官方书面许可后允许商业使用。
-
部署和使用:ChatGLM2-6B 支持在多种硬件和软件环境下部署,包括 GPU 和 CPU 环境。模型也可以通过量化来减少对硬件资源的需求。
-
模型量化:模型提供了不同精度的版本,包括 FP16、INT4 等,以适应不同的部署需求和硬件限制。
-
多卡部署:如果用户有多个 GPU,ChatGLM2-6B 支持模型在多张 GPU 上进行切分和部署,以解决单张 GPU 显存不足的问题。
-
开源社区:ChatGLM2-6B 旨在与开源社区共同推动大模型技术的发展,并鼓励开发者遵守开源协议。
-
模型微调:提供了使用 P-Tuning v2 对 ChatGLM2-6B 进行参数微调的方法,以适应特定的应用场景。
-
模型架构:ChatGLM2-6B 采用了 Prefix Decoder-only 架构,综合了单项注意力和双向注意力的优点。
-
模型容量和多轮对话能力:虽然 ChatGLM2-6B 在多维度上有所提升,但相比于更大容量的模型,其在长答案生成和多轮对话场景下可能存在一定的局限性。
-
模型开源信息:模型的代码和权重已在 GitHub 和 ModelScope 等平台上开源,供学术研究和商业使用。
代码参考
目前在git上已经获星15.5k,算是一款比较火爆的开源中英文对话模型。
git地址:https://github.com/THUDM/ChatGLM2-6B
windows平台搭建部署ChatGLM2-6b过程
-
代码下载:
git clone https://github.com/yanceyxin/ChatGLM2-6B.git -
cd 到 ChatGLM2-6B文件目录,打开README.md,解读配置过程,根据README.md进行部署;
-
激活到自己的配置的conda虚拟环境:
conda activate deeplearning

-
在 ChatGLM2-6B文件目录下,使用 pip 安装依赖:
pip install -r requirements.txt,其中transformers库版本推荐为4.30.2,torch推荐使用 2.0 及以上的版本,以获得最佳的推理性能。【该过程相对比较慢,即使设计科学上网也要一段时间】
-
报错了:不能安装“TBB”,查资料解决吧。

查找资料,是给ananconda 升级 mkl 包的错误,删掉Anaconda3\Anaconda3\Lib\site-packages中TBB-0.2-py3.11.egg-info文件,重新pip install -r requirements.txt,即成功;

-
安装成功
-
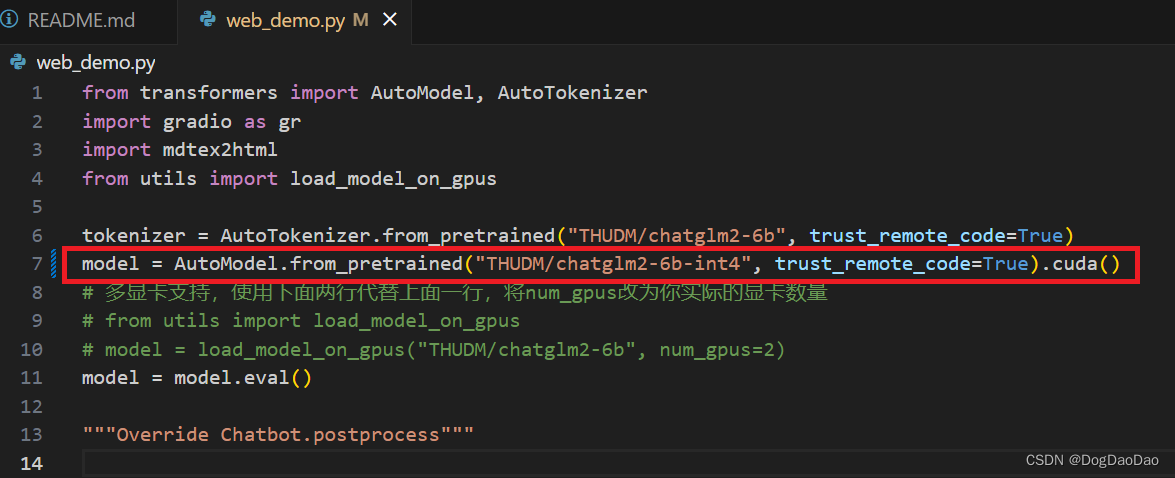
根据自己的设备能力修改demo中模型量化精度,用GPU可以选择低成本模型,修改如下代码为int4精度;
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True).cuda()
-
当前目录下用Python运行
web_demo.py,接近4G数据,又是漫长的下载等待时间,即使科学上网也要相对长的时。放弃,选择手动下载,如步骤8中。
-
建议可以手动下载模型,根据自己本地设备的能力选择相应精度的模型,放到源码相应目录里。网址:https://huggingface.co/THUDM/chatglm2-6b-int4/tree/main

-
在文件目录新建目录
THUDM\chatglm2-6b-int4,将手动下载的模型放到里。

demo使用
命令行版cli_demo.py
(1)打开cli_demo.py文件,修改模型为精度为int4,对应着上一步新建的模型目录。

(2)启动demo,运行:python cli_demo.py;又报错了,提示没有readline。

(3)安装readline:pip install readline,依旧报错,查资料,遇到这个问题是因为尝试在Windows环境中安装readline模块,但readline是一个主要用于Unix-like系统的库,不原生支持Windows。Python在Windows上的标准安装包含一个名为pyreadline的替代模块,该模块旨在模仿readline的一些功能。

(4)安装pyredline: pip install pyreadline,安装成功。

(5)将文件cli_demo.py中readline修改成import pyreadline。

(6)继续启动demo:python cli_demo.py,进行如下图对话,成功
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

