
热门标签
热门文章
- 1torchtext0.14 实践手册(0.12版本同理)
- 2Copilot插件使用介绍_copilot怎么用插件
- 3springboot项目:订单生成和沙箱支付_spring boot mysql 怎么储存多种订单号生成规则
- 4Sketchup模型与ArcGIS进行数据交互的方法_arcgis pro skp
- 5狂追ChatGPT:开源社区的“平替”热潮_chatglm 联互联网
- 6面试自我介绍范文(30篇)_面试自我介绍csdn
- 7iMX6ULL 软件定制应用笔记 -9个知识点讲解_imx6u pl2303
- 8Homebrew命令详解_brew命令详细解释
- 9批量免费AI写作工具,批量免费AI写作软件
- 10centos7 后台启动jar包
当前位置: article > 正文
机器学习 - 聚类 - k_means
作者:笔触狂放9 | 2024-04-01 06:58:25
赞
踩
机器学习 - 聚类 - k_means
一、下载数据集
https://archive.ics.uci.edu/ml/datasets/ 这个库提供了大量的机器学习数据集
Iris数据集:这是一个经典的小型数据集,包含了150个样本,分为三类,每类50个样本。每个样本有四个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。这个数据集非常适合初学者用来理解和实践聚类算法 。
二、使用pandas对数据进行处理
因为下载的数据是 .data为后缀名,要转换成 .csv文件,那么就需要使用数据分析的包,pandas。
第一次使用需要下载: pip install pandas
- import pandas as pd
-
-
- data_file_path = 'iris.data'
- csv_file_path = 'iris.csv'
-
- # 读取.data文件到pandas DataFrame
- # 注意:这里的分隔符是逗号,需要根据实际情况进行调整
- df = pd.read_csv(data_file_path, sep=',')
-
- # 假设你需要进行一些数据清洗和转换
- # 例如,重命名列名
- df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
- # 根据你的.data文件内容替换这些列名
-
- # 将清洗后的DataFrame保存为.csv文件
- df.to_csv(csv_file_path, index=False) # index=False表示不保存行索引到CSV文件中
-
-
- # 打印聚类结果的前几行
- print(iris_df.head())

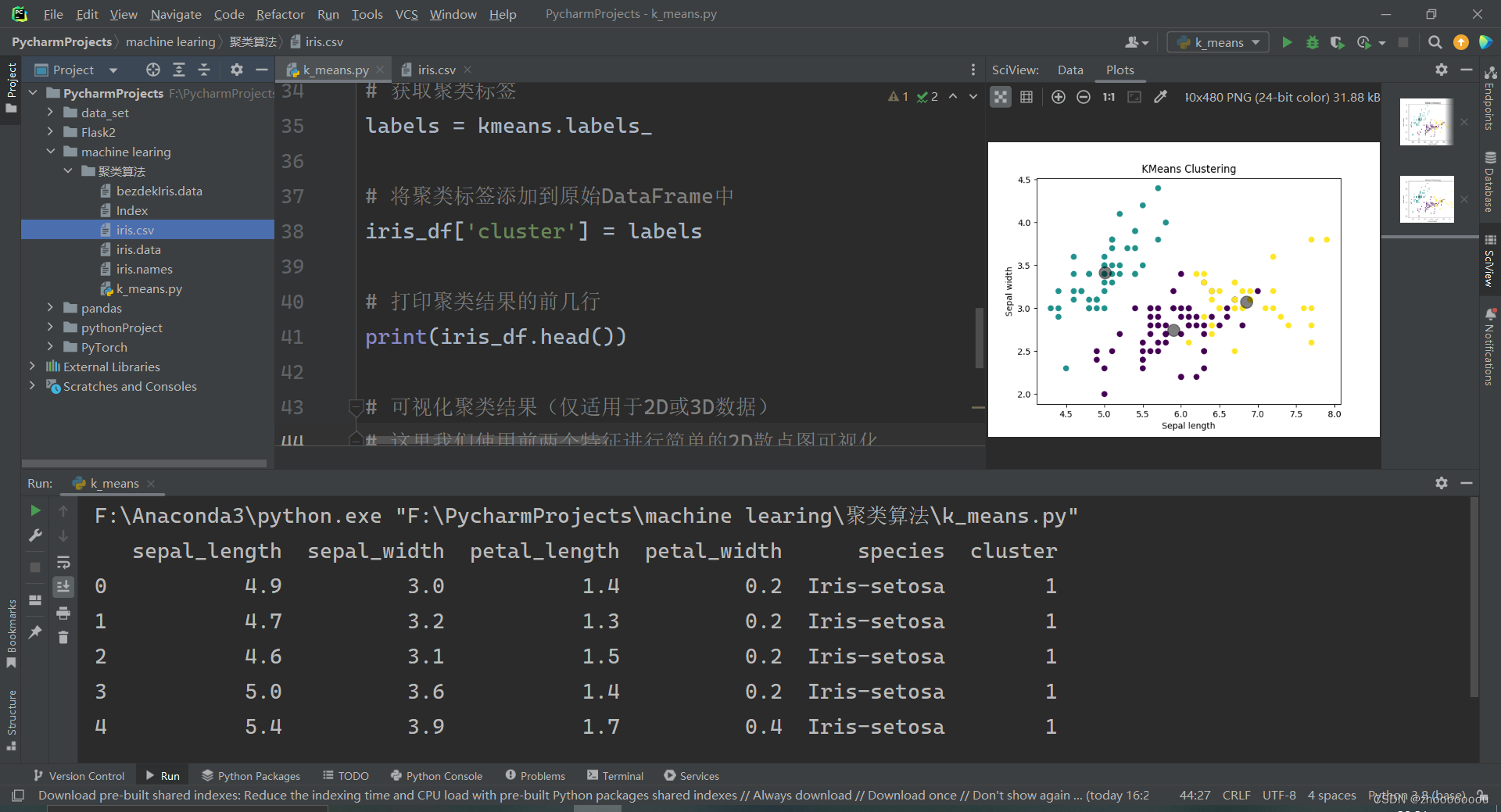
三、实现 k_means 聚类算法
代码实现
- # 加载CSV文件
- iris_df = pd.read_csv('iris.csv')
-
- # 假设CSV文件中有'sepal_length', 'sepal_width', 'petal_length', 'petal_width'和'species'这些列
- # 我们将使用前四个特征列进行聚类,'species'列用于比较聚类结果(如果需要的话)
- X = iris_df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
-
- # 设置KMeans聚类器,这里我们假设类别数为3(与iris数据集的实际类别数相同)
- kmeans = KMeans(n_clusters=3, random_state=42)
-
- # 对数据进行聚类
- kmeans.fit(X)
-
- # 获取聚类标签
- labels = kmeans.labels_
-
- # 将聚类标签添加到原始DataFrame中
- iris_df['cluster'] = labels
-
- # 打印聚类结果的前几行
- print(iris_df.head())
-
- # 可视化聚类结果(仅适用于2D或3D数据)
- # 这里我们使用前两个特征进行简单的2D散点图可视化
- plt.scatter(X['sepal_length'], X['sepal_width'], c=labels, cmap='viridis')
- centers = kmeans.cluster_centers_
- plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5)
- plt.xlabel('Sepal length')
- plt.ylabel('Sepal width')
- plt.title('KMeans Clustering')
- plt.show()
通过matplotlib实现数据可视化
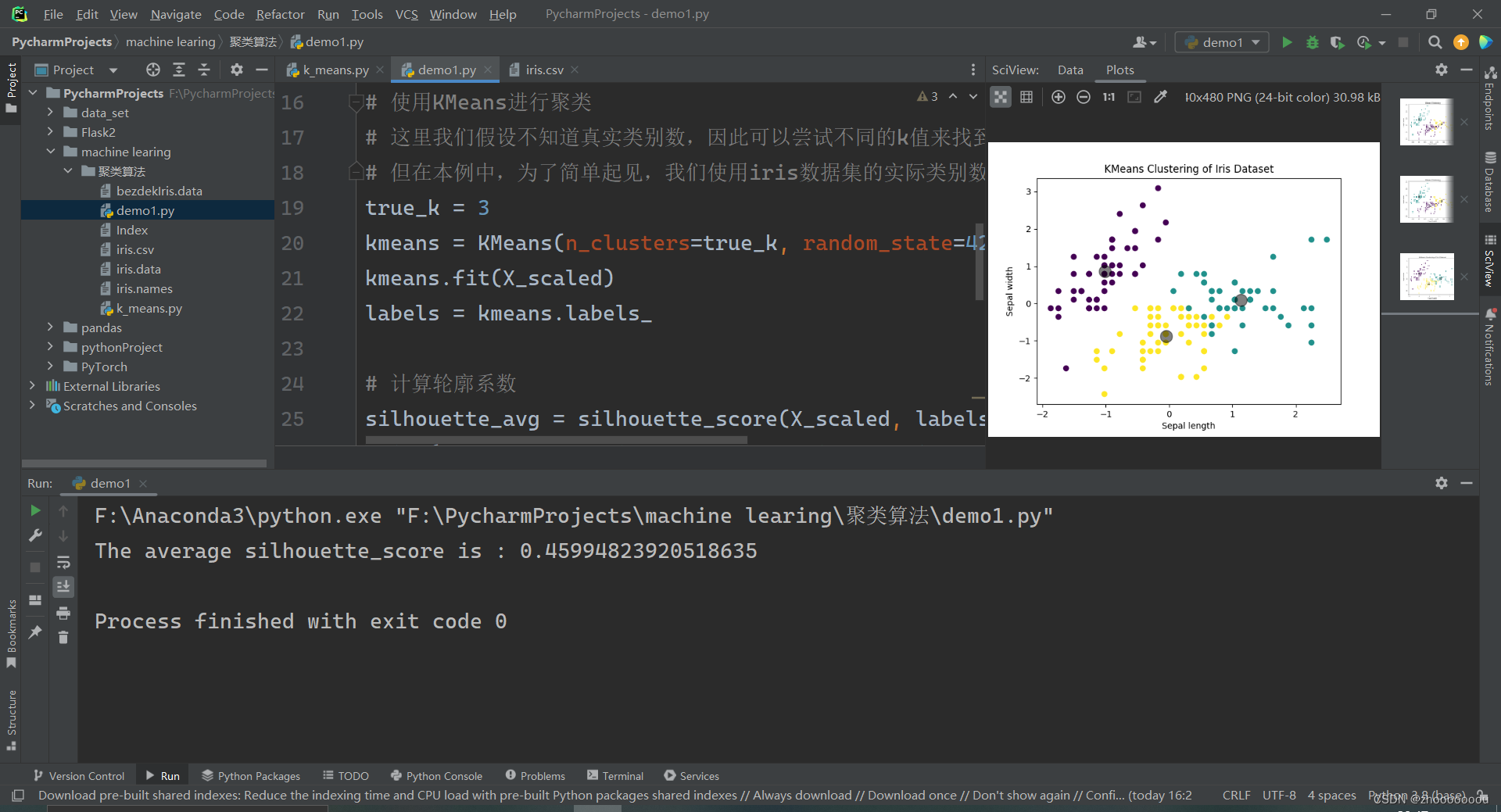
四、sc聚类评价指标
首先,你需要加载iris数据集,然后应用聚类算法(比如KMeans),最后计算并打印轮廓系数。
- from sklearn import datasets
- from sklearn.cluster import KMeans
- from sklearn.metrics import silhouette_score
- from sklearn.preprocessing import StandardScaler
- import matplotlib.pyplot as plt
-
- # 加载iris数据集
- iris = datasets.load_iris()
- X = iris.data
- y = iris.target # 真实标签,对于聚类分析我们实际上不需要它,但为了评估可以保留
-
- # 数据标准化
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 使用KMeans进行聚类
- # 这里我们假设不知道真实类别数,因此可以尝试不同的k值来找到最佳的簇数
- # 但在本例中,为了简单起见,我们使用iris数据集的实际类别数3
- true_k = 3
- kmeans = KMeans(n_clusters=true_k, random_state=42)
- kmeans.fit(X_scaled)
- labels = kmeans.labels_
-
- # 计算轮廓系数
- silhouette_avg = silhouette_score(X_scaled, labels)
- print("The average silhouette_score is :", silhouette_avg)
-
- # 可视化聚类结果(对于二维或三维数据)
- # 由于iris数据集有四维特征,我们不能直接可视化。但是,我们可以选择两个特征进行可视化。
- plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=labels, cmap='viridis')
- centers = kmeans.cluster_centers_
- plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5)
- plt.title("KMeans Clustering of Iris Dataset")
- plt.xlabel("Sepal length")
- plt.ylabel("Sepal width")
- plt.show()
-
- # 注意:这里我们只选择了前两个特征进行可视化,因此可能无法完全反映聚类的效果。
- # 在实际分析中,你应该考虑所有特征,并可能需要使用其他评估方法来全面评估聚类结果。
结果可视化
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

