
- 1root后怎么刷回官方,recovery刷入root_root的手机怎么刷回去
- 2用vm虚拟机连接xshell,一把过(超详细图文并茂)_vmware fedora 共享网络 xshell
- 3spark 使用python语言操作(基于pycharm的安装使用)_spark python
- 442个来自《 CSS世界》中的实用技巧
- 5C++ 用单、双链实现链表数据结构,LeetCode题_c c++ 双向链表插入一个节点 leetcode
- 6深度学习 | 关于GRU你必须知道的20个知识_加权gru
- 7“数字直角三角形”的循环简化
- 8uniapp开发H5内嵌APP,使用uni.setClipboardData实现复制功能时,安卓没问题,ios会闪一下(底部弹出弹窗)~踩坑之路_uniapp 复制不弹框
- 9深入 Java 调试体系,第 2 部分
- 10微网双层优化 储能 matlab采用matlab编程对冷热电微网系统进行双层优化
Elasticsearch——2:Elasticsearch 体系结构_elasticsearch 结构
赞
踩
前面讲的索引文档、执行查询等 API 操作已经比较细了。但不足以真正了解 elasticsearch 是如何工作的,这就站在一个较高的层次简单介绍一下它的体系结构。
一,全景视角
elasticsearch 是一个用 Java 基于 Apache Lucene 开发的上手即用地服务器端应用。
(一)输入数据
数据能以多种方式从不同的数据源导入到 elasticsearch 中:
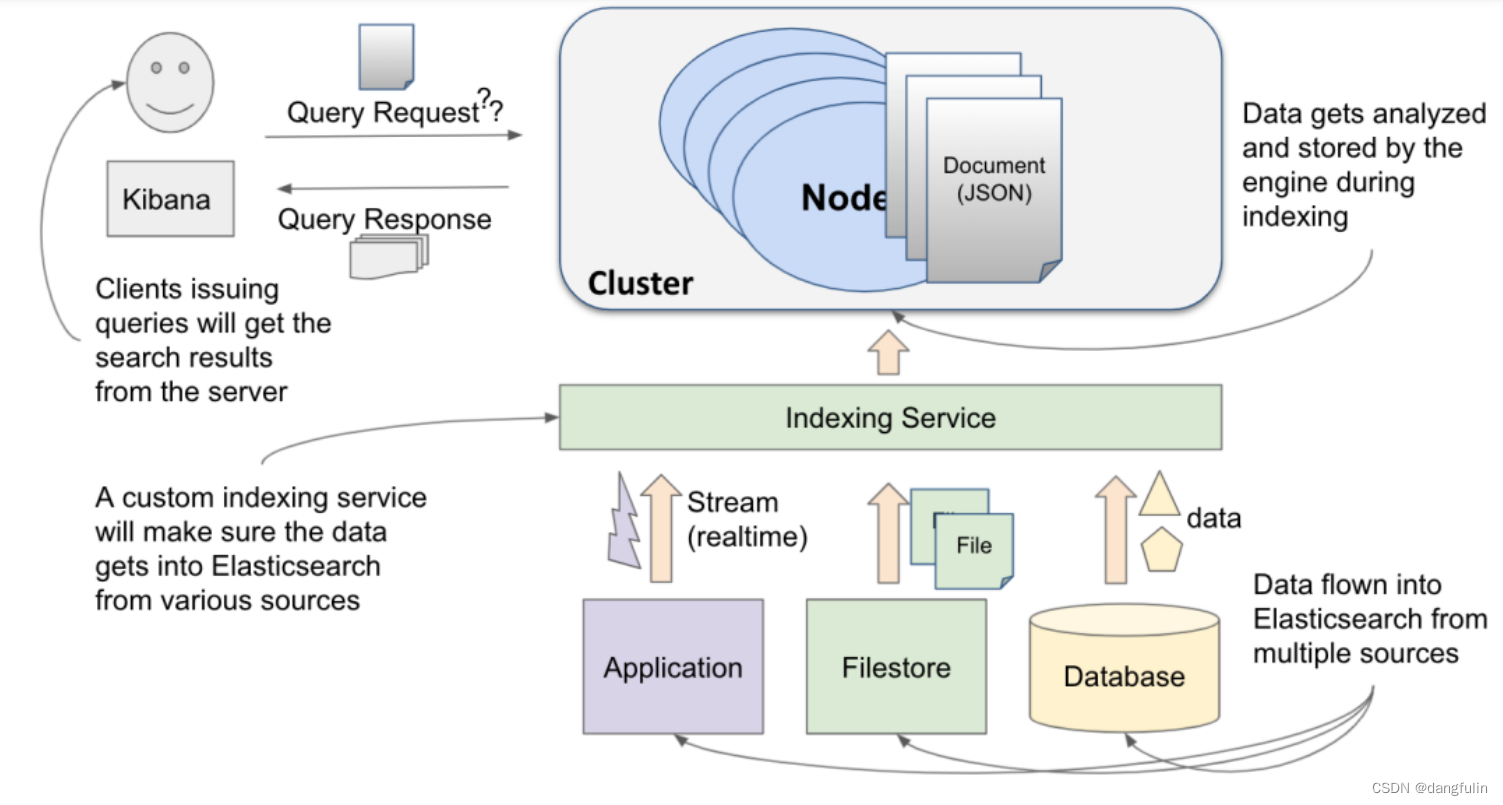
以利于搜索和分析的格式进行的分析过程有助于有效地检索数据。一旦摄取的数据通过 Elasticsearch 存储,就可以快速地进行搜索。
(二)处理数据
在 elasticsearch 中,基本的信息单元由 JSON 文档表示:
{
"title":"Is Remote Working the New Norm?",
"author":"John Doe",
"synopsis":"Covid changed lives. It changed the way we work..",
"publish_date":"2021-01-01",
"number_of_words":3500
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
为了容纳数据,elasticsearch 根据不同类型的数据创建一组存储桶,比如新闻文章就被存在自定义的被叫做新闻的桶中,这些文章就是文档,而这些桶就是索引。也就是说,索引就是文档的逻辑集合。
- 用 RDBMS 类比的话,索引就是数据库中的数据表,文档就是表中一行行的记录。
出于性能考虑,可以将索引拆分到集群中不同节点上的分片之中,统一由主分片进行管理,由副分片做数据备份。
具体点来说,文档中的数据字段有不同的类型,通过一个叫做映射的过程将 JSON 格式的文档转为 elasticsearch 可处理的类型,正是这个过程定义了 elasticsearch 如何处理我们的数据字段。
在索引文档期间,elasticsearch 就根据映射的定义来分析数据字段,其中对全文本字段的分析就是构建 elasticsearch 高效搜索的关键。
这个文本分析过程包含两个过程:分词(tokenization)和规范化(normalization)。
分词过程通过一系列规则来拆分文本,通常是拆分为单个的字(token)或者词组——具体由分词器(tokenizers)决定,比如:

分词后用户就能使用 API 进行文本搜索操作了,但分词结果本身并不会持久化,为了提供更高效的搜索,还需要将结果规范化。
规范化会围绕分词结果创建额外的数据来提供良好的用户体验,比如:

规范化之后的内容会存储在成为**倒排索引**的高级数据结构中。
(三)输出数据
数据经过输入与处理后,就可以通过搜索或者查询获得。
当客户端发出一个搜索请求时,如果该字段是一个全文本字段,那么它将在服务器端经历一个与索引该字段期间所执行的类似的分析阶段,然后在倒排索引中搜索和匹配各自的 token,并将匹配的结果转发回客户端。
二,组件
与任何应用程序一样,Elasticsearch 有一堆的组件来组成搜索引擎,包括文档、索引、分片等。
(一)文档
文档是由 Elasticsearch 存储数据 、建立索引信息的基本单元。类似于 RDBMS 中的行记录。
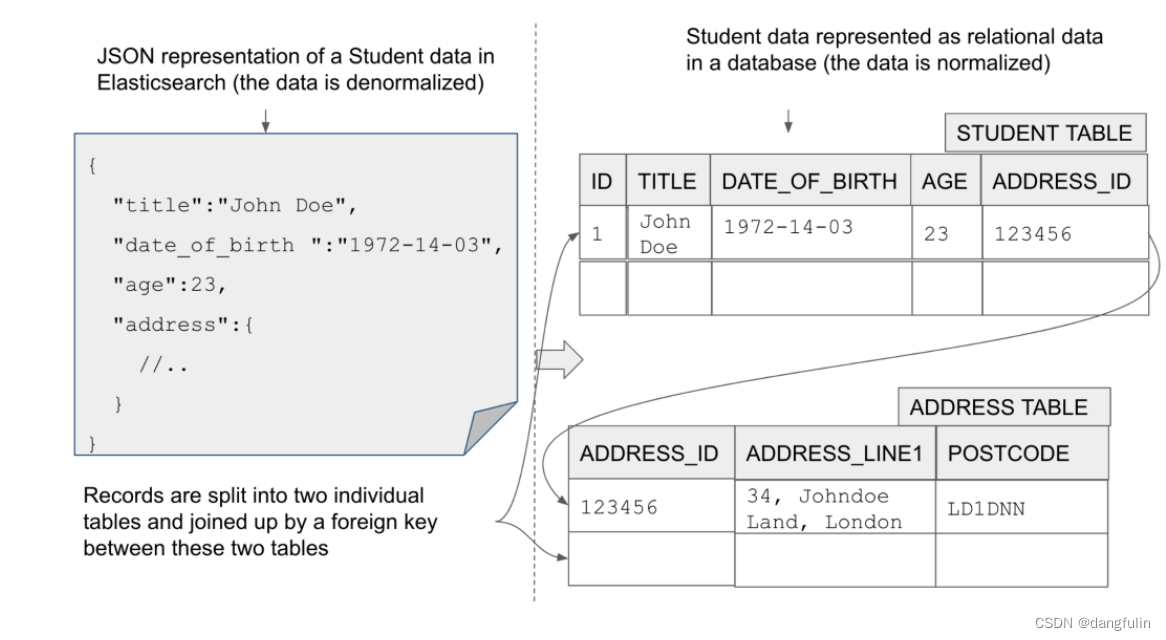
(二)移除关系与产生关系
在 RDBMS 中,“关系”表示数据表之间的关联关系,比如学生表会关联到课程表。
但在 ES 的文档中保存的数据,将“关系”扁平化——各算各的,互不影响。学生文档就放在保存学生“类型”的索引中,有点 RDBMS 中数据表的概的意思。
在 ES 5.X 之前,确实是允许在同一个索引中保存不同类型的文档的,比如汽车索引中,可以保存汽车信息文档、汽车用户文档、甚至汽车销售订单文档等不同类型的文档,比如 cars/carinfo/ 、cars/caruser/ 等。
但从构成 ES 的基石 Lucene 的角度来说,直接基于倒排序索引对文档进行查询本就是干脆直接的,文档类型的存在反倒减慢搜索速度,所以在 ES 7.X 中就完全移除了类型这一概念,用 carinfo/_doc、caruser/_doc 的形式完全扁平化文档,这样做有一些好处:
- 索引过程是快速和无锁的。
- 搜索过程是快速和无锁的。
- 因为每个文档相互都是独立的,大规模数据可以在多个节点上进行分布。

和其它文档数据库一样,ES 文档是否匹配搜索请求取决于它是否包含所有的所需信息。除非有很强的理由,否则总是应该以扁平化的方式建模数据以方便将数据保存为文档,尽量避免数据间产生关系。
但关系信息无处不在,博客有评论吧,银行账户有交易记录吧。各自独立的文档之间确实也能产生关系关联,可通过以下方式来实现:
- 在应用层做拼接。
- 这就需要在关系字段上设置指定的字段类型:Join(父子关系文档),Object 和 Nested(两者表示两种文档嵌套关系)。
- 文档冗余存储。
通常我们会选用第一种方式:先将拆分复杂查询,然后者根据结果进行二次查询,最后拼接结果。
(三)索引与分片
再次说明,索引就是文档的逻辑集合,它会被切分到各个节点中被称为分片的控制下:
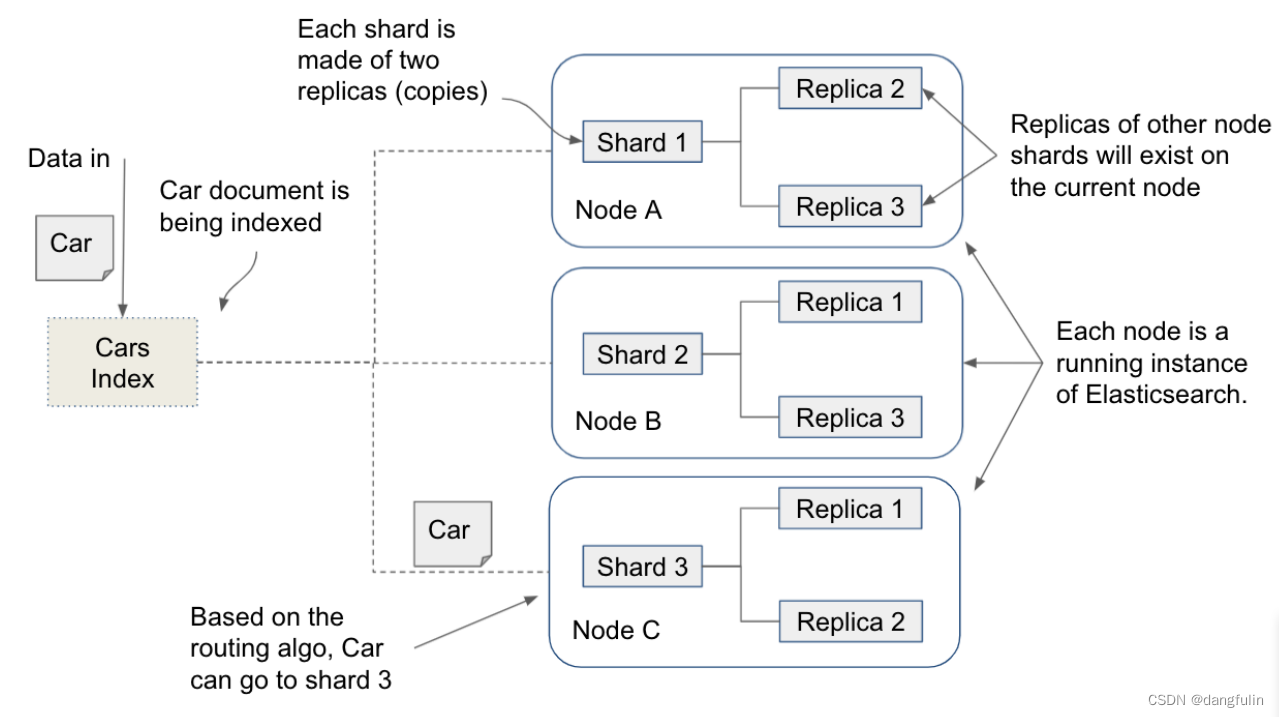
从技术上来说,索引能保存无尽的文档。但从实际存储的角度来说,我们应该将比较大的索引切分为相对较小的分片,而且这些分片能存在于多个节点中,这种分布式的架构设计就是产生 ES 高效查询的原因之一。
- 索引的具体大小应该提前进行讨论以满足当前或者未来的需求。
- 对文分片做备份有利于保持系统健壮性,向上图那样,对一个 500BG 的分片做两个备份,则该节点上就有 1.5TB 的数据。
每个索引都有各自的属性,比如映射(mappings)、配置(settings)、别名(aliases)等。
(四)rollover 与数据流
对于一个日活量比较大的站点来说,各方面数据量的增长是非常快的。
我们可以添加额外的索引来保存数据以应对搜系统所需的数据量的增长。特别是对依赖时间戳的数据,比如日志数据、动态统计数据等随时间增长持续追加存储的数据——时间序列数据——来说,它们可能被存储到不同的索引当中。
但我们的期望是,时序数据不需要周期性地更新到新的索引,而是当原本索引中的数据量达到一个阈值的时候以一种自动切割的方式直接存到新生成的索引当中,这可以通过 rollover 机制来实现:在目标满足滚动条件时将新数据滚动到新索引。
rollover 可处理两类数据:
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

