
热门标签
热门文章
- 1base64 显示图片和pdf_image展示base64 pdf
- 2【Unity】【FBX】如何将FBX模型导入Unity_unity打开fbx文件
- 3连接云-边-端,构建火山引擎边缘云网技术体系_边缘云如何与平台对接,到时是拉跨省专线过来
- 4数值分析复习:Newton插值
- 5python编程语言单词,python基本语句大全_哪里可以看到python所有语句
- 6android判断是否是华为或鸿蒙系统_android 判断鸿蒙机型
- 7使用Python+TensorFlow2构建基于卷积神经网络(CNN)的ECG心电信号识别分类(一)_心拍信号自动分类算法
- 815个android框架,Android常用的15个框架总结
- 9你想要的Android FloatingActionButton悬浮按钮哪去了?_android studio悬浮按钮
- 10Sora技术报告——Video generation models as world simulators
当前位置: article > 正文
为什么要使用多GPU并行训练,单卡和多卡训练,bs和lr的关系_多卡训练和单卡训练效果
作者:笔触狂放9 | 2024-03-18 08:05:25
赞
踩
多卡训练和单卡训练效果
参考
https://jishuin.proginn.com/p/763bfbd63d50
理解
为什么要使用多GPU并行训练
简单来说,有两种原因:第一种是模型在一块GPU上放不下,两块或多块GPU上就能运行完整的模型(如早期的AlexNet)。第二种是多块GPU并行计算可以达到加速训练的效果。想要成为“炼丹大师“,多GPU并行训练是不可或缺的技能。
常见的多GPU训练方法:
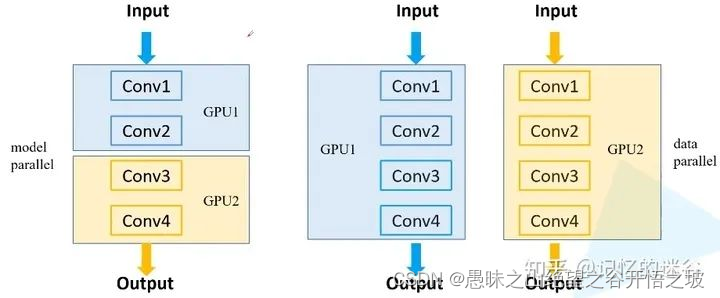
1.模型并行方式:如果模型特别大,GPU显存不够,无法将一个显存放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。(下图左半部分)
2.数据并行方式:将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播。相当于加大了batch_size。(下图右半部分)
单卡和多大训练,bs和lr的关系
众所周知,learning rate的设置应和batch_size的设置成正比,即所谓的线性缩放原则(linear scaling rule)。但是为什么会有这样的关系呢?这里就Accurate Large Minibatch SGD: Training ImageNet in 1 Hour这篇论文来深入探讨一下其中的原理,以及深度学习模型在分布式训练中需要注意的事情。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/261558
推荐阅读
相关标签

