
- 1MQTT的服务端Mosquitto和Mqttfx客户端安装配置_mqttfx-1.7.1-windows-x64
- 2使用js实现证件照p图,背景扣除和替换,完全开源!!!!_js 抠图
- 3【MindStudio训练营第一季】什么是AscendCL?_5、 基于ascendcl开发基础推理应用时,涉及以下哪几个运行管理资源的申请? a. host
- 4Java学习笔记(三)—— 保存书店交易记录程序_java编程books,recordbooksorder
- 5Vue(简单的目录树组件)---附注释_目录树管理 vue
- 6使用Hbuilder将vue项目封装为移动端安装包(apk)_hbuilderx 鸿蒙
- 7海信电视老出现android是什么意思,海信电视屏幕上显示“智能电视系统启动中,请稍后”是什么意思?怎样处理?- 一起装修网...
- 8第十一节HarmonyOS 常用容器组件2-List和Grid_harmonyos 下面哪些容器组件是可以滚动的
- 9<HarmonyOS第一课>运行Hello World_harmonyos第一课运行hello world
- 10golang 速度限制器ratelimit,web上传下载速度限制_glang gin上传下载文件限速
(9)YOLO-Pose:使用对象关键点相似性损失增强多人姿态估计的增强版YOLO_yolo-pose损失函数
赞
踩
YOLO-Pose:使用对象关键点相似性损失增强多人姿态估计
1. 简介
Time:2022
我们介绍了一种YOLO-Pose,一种新的无热图联合检测方法,以及基于流行的YOLO目标检测框架的图像二维多人姿态估计。现有的基于热图的两阶段方法是次优的,因为它们不是端到端可训练的,训练依赖于替代L1损失,不等于最大化评估度量,即目标对象关键点相似度(OKS)。我们的框架允许我们端到端训练模型,并优化OKS度量本身。该模型学习了在一次正向传递中联合检测多个人的边界框及其相应的二维姿态,从而引入了自上而下和自下而上两种方法的最佳效果。所提出的方法不需要对自底向上的方法进行后处理,以将检测到的关键点分组到一个骨架中,因为每个边界框都有一个相关的姿态,从而导致关键点的固有分组。与自上而下的方法不同,多个向前通道被取消,因为所有人的姿势都是局部化的。YOLO-pose在COCO验证(90.2%AP50)和测试开发方面取得了新的最先进的结果。
效果如下:
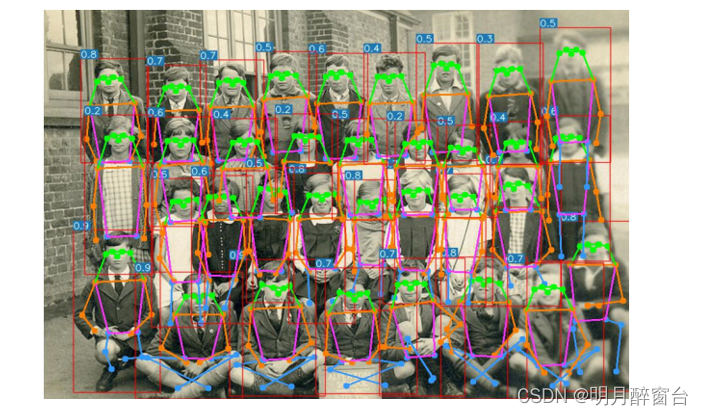
- 从yolov5m6姿态的输出显示了我们的方法的鲁棒性。一个人的关键点永远不会因为固有的分组而与另一个人误解。
论文的主要贡献有:
- 通过目标检测来解决多人姿态估计,因为主要的挑战,如尺度变化和遮挡是共同的。所提方法将直接受益于目标检测领域的任何进展。
- 我们的无热图方法使用标准的OD后处理,而不是复杂的后处理,包括像素级NMS、调整、细化、线积分和各种分组算法。该方法是鲁棒性的,因为端到端训练没有独立的后处理。
- 将IoU损失的思想从盒检测扩展到关键点。对象关键点相似度(OKS)不仅用于评估,还用于训练的损失。OKS损失是尺度不变的,并且给不同的关键点给予不同的权重。
- 我们用~4倍的计算实现SOTA AP50。例如,在coco测试-dev2017上,Yolov5m6-姿态在66.3 GMACS达到AP5089.8,而SOTA DEKR[30]在283.0 GMACS达到AP5089.4。
- 提出了一个联合检测和姿态估计框架。姿态估计几乎是免费的与一个OD网络。
- 提出了我们的模型的低复杂度变体,显著优于实时聚焦模型,如效率HRNet
论文:https://arxiv.org/ftp/arxiv/papers/2204/2204.06806.pdf
源码:https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose
2. 相关工作
2.1 自上而下的方法
- 自上而下或两阶段方法首先使用像快速RCNN[21]这样的重型人检测器进行人体检测,然后估计每个被检测到的人的2d姿态,计算复杂度随人数呈线性增加。
- 主要侧重于网络架构的设计。Mask-RCNN检测关键点作为分割掩码。Simple Baseline提出了一个简单的架构,具有较深的主干和几个反卷积层,以扩大输出特性的分辨率。
- 上述方法具备尺度不变性,但在处理遮挡问题上表现很差
2.1 自底而上的方法
- 自底向上的方法是在一个镜头中找出一个图像中所有的人的无身份关键点,然后将他们分组到个人实例中。
- 该方法用于一种称为热图的概率映射,它估计包含特定关键点的每个像素的概率。关键点的确切位置是通过NMS找到的热图的局部极大值。
- 复杂性较低,并且具有恒定运行时的优势。然而,与自上而下的方法相比,准确性有了大幅下降。
- OpenPose构建了一个模型,其中包含两个分支来预测关键点热图和部分亲和字段,它们是建模关节之间关联的二维向量。在分组过程中使用了零件亲和关系字段。
- disentangled keypoint representation(DEKR),一种使用偏移映射的直接回归方法。提出了一种利用自适应卷积来回归相应关键点的偏移量的k个分支结构。这种方法需要关键点热图和后处理中的各种NMS操作的中心热图。尽管后处理没有任何分组,但它并不像我们的那样简单。
3. YOLO-Pose
关键点+检测框相结合:it associates all keypoints of a person with anchors.
3.1 概述
- 对于人类姿态估计,它归结为一个单一类的人检测问题,每个人有17个相关的关键点,每个关键点再次识别一个位置和可信度:
{x,y,conf}..因此,与一个锚点关联的17个关键点总共有51个元素。因此,对于每个锚点,关键点头预测51个元素,盒子头预测6个元素。对于具有n个关键点的 anchor,总体预测向量定义为:
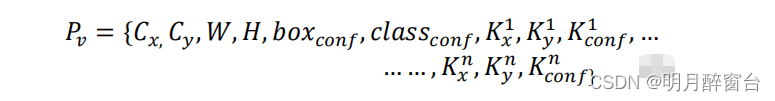
- 关键点置信度是基于该关键点的可见性标志进行训练的。如果一个关键点是可见的或被遮挡的,则被置为1,如果在视场之外,则置信度设置为零。
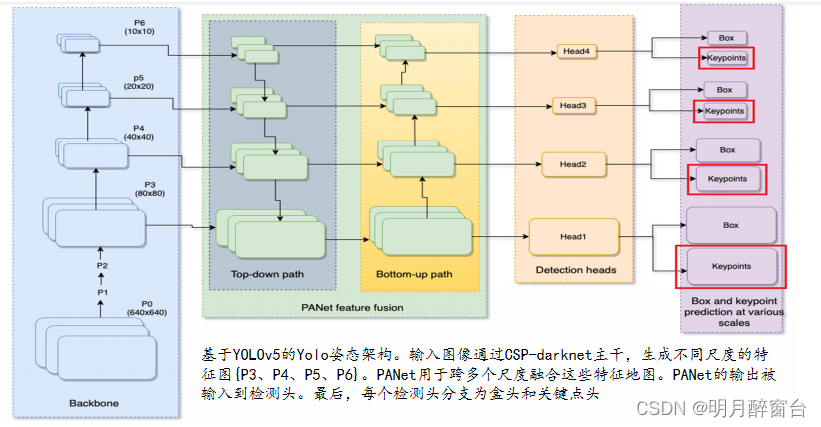
- YOLO-Pose使用CSP-darknet作为主干,而PANet来融合来自主干的不同尺度的特征。接下来是四个不同尺度的探测头。最后,有两个解耦的头用于预测盒子和关键点
3.2 基于多人姿态的anchor
对于每幅图像,一个预测框将包含每个人的2D姿态及pose的外接矩形,box 坐标转换为anchor,而 box 尺寸根据 anchor 的高度和宽度标准化。同样,关键点位置将w.r.t转换为anchor中心。然而,关键点并没有与anchor 的高度和宽度进行标准化。关键点和盒子都被预测到anchor的中心w.r.t。由于我们的增强独立于锚的宽度和高度,它可以很容易地扩展到无锚的目标检测方法,如YOLOX,FCOS。
3.3 基于IoU的Bounding-box 损失函数
大多数现代目标探测器优化了IoU损失的高级变体,如GIoU、DIoU或CIoU损失,而不是基于距离的box检测损失,因为这些损失是尺度不变的,并直接优化了评估度量本身。我们使用CIoU损失来进行边界盒监督。对于与位置(i,j)和比例s上的第k锚点匹配的地面真实边界框,损失定义为:
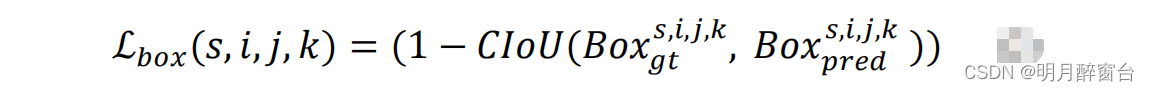
In our case, there are three anchors at each location and prediction happens at four scales.
3.4.人体姿势损失函数公式
- 我们是回归的关键点直接ancho中心
w.r.t,我们可以优化评估度量本身,而不是一个代理损失函数。我们将借据损失的概念从盒子扩展到关键点。在出现关键点的情况下,对象关键点相似度(OKS)被视为IOU。OKS损失本质上是尺度不变的,比某些关键点更重要。 - 对应于每个bounding box,我们存储整个姿态信息。因此,如果一个地面真实边界框在位置
(i,j)和尺度s上与anchor匹配,我们将预测相对于anchor中心的关键点。对每个关键点分别计算OKS,然后求和,给出最终的OKS损失或关键点IOU损失。
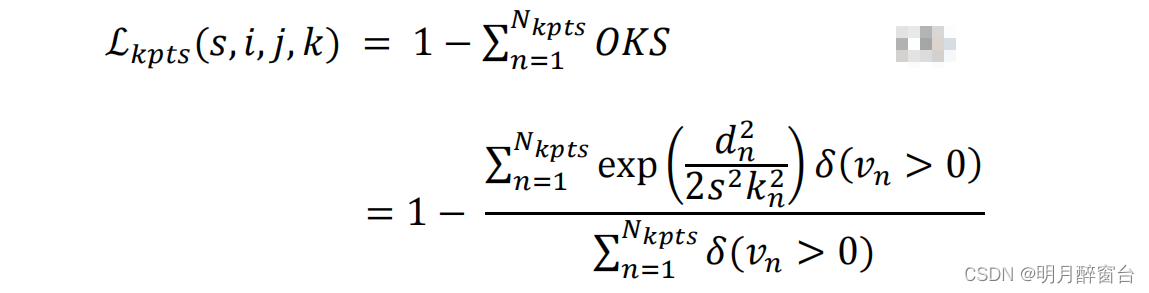
其中,dn是指第n个关键点的预测位置与场景中的真实位置之间的欧氏距离;kn指的是关键点的权重;s指目标对象的尺度; δ \delta δ 指的是每个关键点的可视标志。 - 对每个关键点,我们学习一个置信参数,显示那个人是否存在一个关键点。在这里,关键点的可见性标志被用作地面真相。
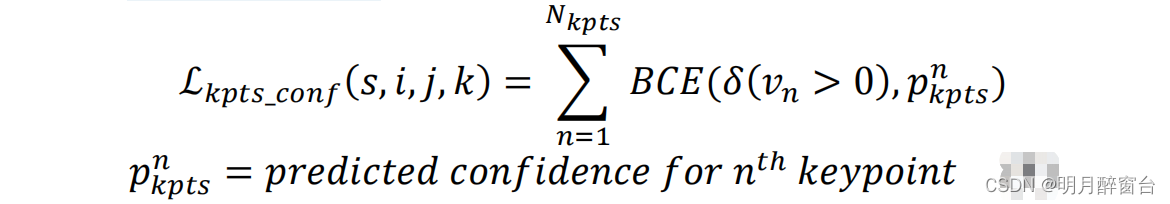
- 如果一个真实边界框与 anchor (预测)相匹配,那么在位置
(i,j)上的损失是有效的。最后,对所有尺度、anchor和位置的总损失进行总结:
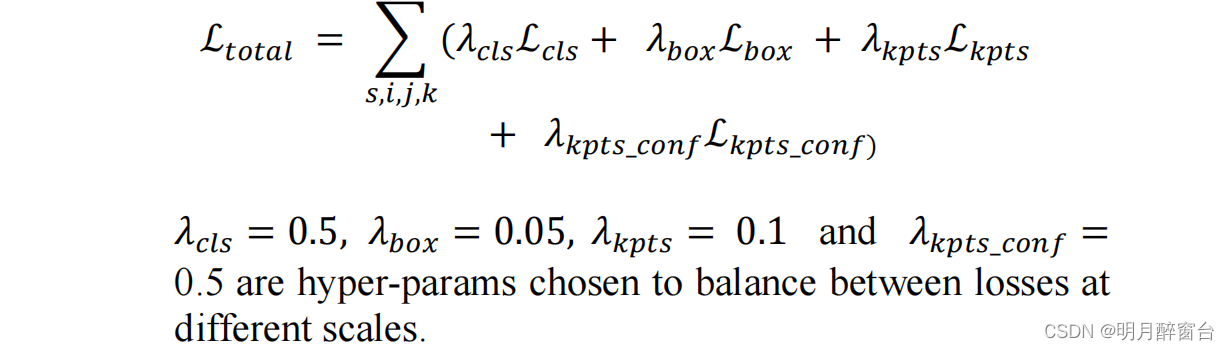
3.5 测试时间调整
所有的姿态估计的SOTA方法都依赖于测试时间增强(TTA)来提高性能。翻转试验和多尺度试验是两种常用的技术。翻转测试增加了2倍,而多尺度测试在三个尺度{0.5X,1X,2X}上运行推理,增加了复杂性。
3.6 关键点外接矩形
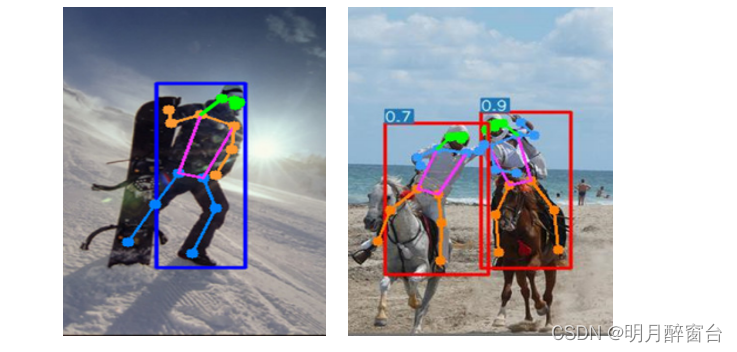
YOLO-Pose方法的优点之一是对关键点在预测的边界框内没有约束。因此,如果关键点由于遮挡而位于边界框之外,那么它们仍然可以被正确识别。然而,在自上而下的方法中,如果人的检测不正确,姿态估计也会失败。在我们的方法中,遮挡和错误的盒子检测的这些挑战都在一定程度上得到了缓解,如图所示。
4. 实验结果
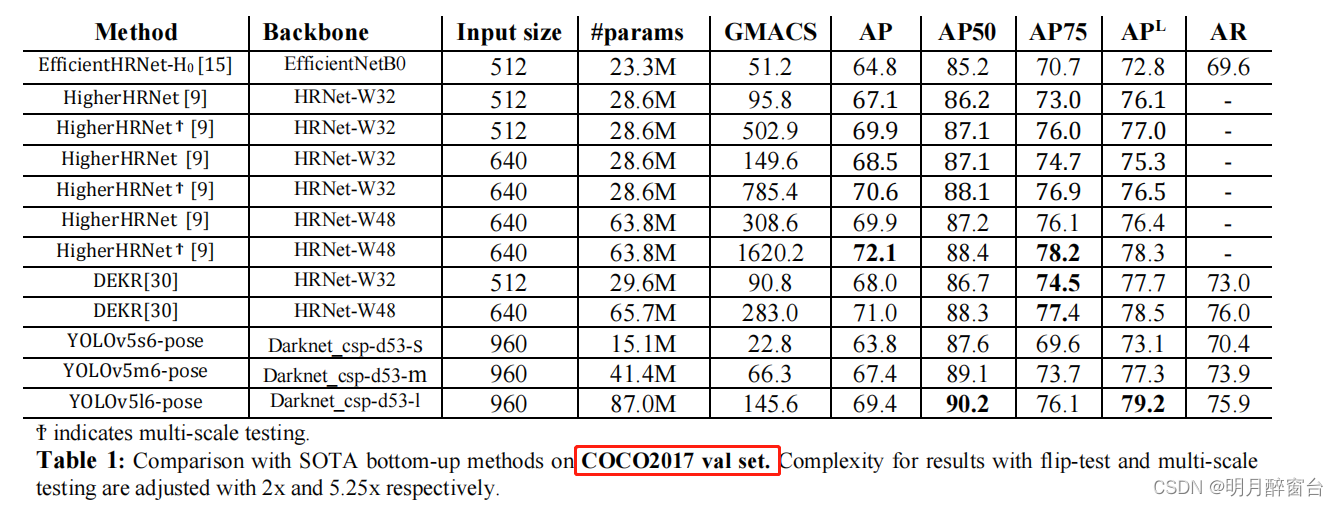

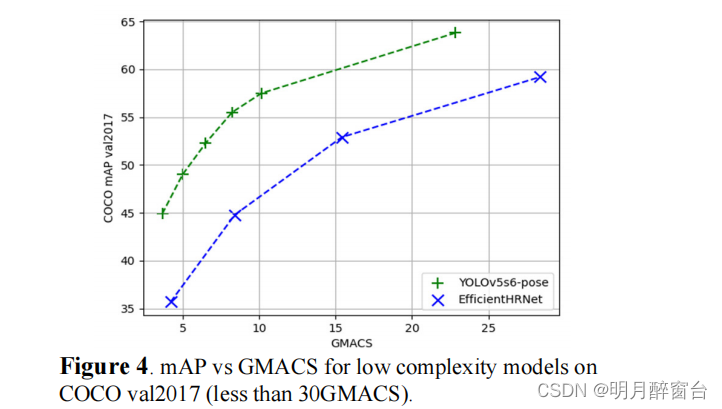
- 在较低的分辨率下,YOLOv5s6姿态的表现明显比现有的最先进的低复杂度模型,如COCO上的高效HRNet
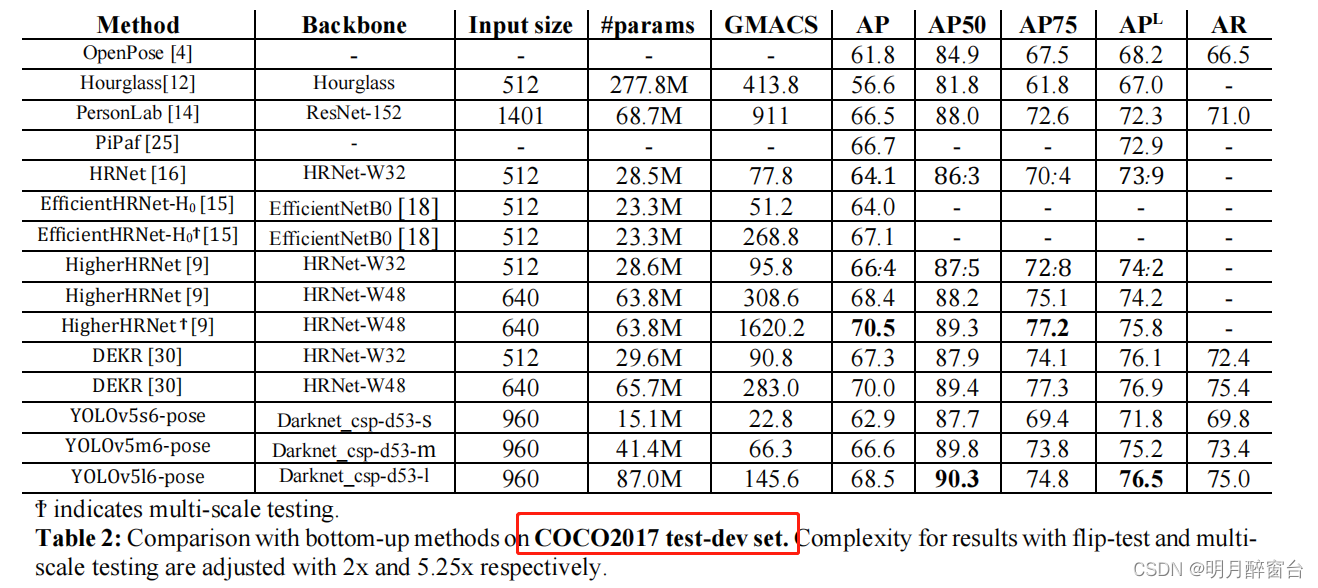
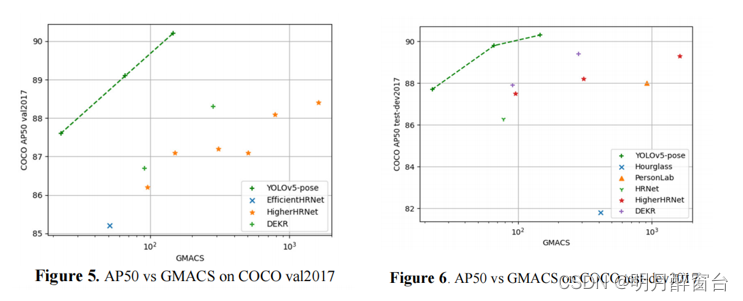
- 在计算方面,YOLOv5m6-Pose比AP50的复杂度高了4倍的模型。图5和图6提供了AP50的简单比较。
5. 结论
- 提出了一个基于端到端YOLOv5的联合检测和多人姿态估计框架。已经证明,我们的模型在显著降低复杂性的情况下优于现有的自底向上方法。
- 我们的工作是统一目标检测和人体姿态估计领域的第一步。到目前为止,姿态估计的大部分进展都是作为一个不同的问题独立发生的。我们相信,我们的SOTA研究结果将进一步鼓励研究界探索共同解决这两项任务的潜力。
- 我们工作背后的主要动机是将目标检测的所有好处传递给人类的姿态估计,因为我们已经见证了目标检测领域的快速进展。我们对将该方法扩展到YOLOX对象检测框架进行了初步实验,取得了较好的结果。我们也将把这一想法扩展到其他对象检测框架,并进一步推动有效的人体姿态估计的极限。

